




人大高瓴赵鑫团队提出新方法:重构推理模型训练路径

当大语言模型开始被要求解数学题、写证明、规划任务流程,一个根本性的问题才真正浮出水面:会生成,真的就等于会推理吗?
过去几年,行业将模型规模推至前所未有的高度,并通过RLHF等技术将答案校准得越来越像人类。然而,一个尖锐的现实也随之而来:模型为何有时会一本正经地胡说八道?为何在相同的训练框架下,它时而表现得异常自信却错误,时而又显得畏首畏尾?在人们不断强化学习信号、追求更高分数的同时,一个核心问题始终未被真正解答:正样本与负样本,究竟在模型内部改变了什么。
正是在这样的背景下,来自中国人民大学高瓴人工智能学院的研究团队将目光聚焦于此。他们没有急于提出更大的模型或更复杂的算法,而是选择退后一步,围绕RLVR框架设计了一系列系统性的对照实验:如果只用正样本训练会怎样?只用负样本又会引发何种行为变化?模型是在真正形成推理能力,还是仅仅被奖励函数推着走向某些看似合理的“套路”?更进一步,在一条完整的推理链中,是否存在少数关键的“岔路口”,决定了模型最终是走向正确,还是自信地偏离轨道。
针对这些问题,研究团队完成了论文《A3PO: Adaptive Asymmetric Advantage Shaping for Reasoning Models》,并提出了相应的推理模型训练方法A3PO。与其说这是一次单纯的方法创新,不如说它首先完成了一次机制上的澄清:正样本主要起到“缩小”策略空间的作用,让模型在已有的正确路径上更加笃定;而负样本则“扩张”策略空间,推动模型跳出旧有模式进行探索。真正决定训练走向的,往往不是整条样本,而是推理过程中那些“冷门却正确”或“自信但错误”的关键决策点。
基于这一认识构建的A3PO方法,将训练重点从整体样本转向这些关键决策点,使得推理模型的学习过程变得更加可解释、也更可控。这一转变意味着,推理大模型的进步路径,或许正从依赖规模和算力,转向对训练机制本身的深入理解。

论文地址:https://arxiv.org/pdf/2512.21625v1
正样本「缩小」vs 负样本「探索」
实验首先对比了正负样本的作用,结果发现它们在训练中扮演的角色截然不同。
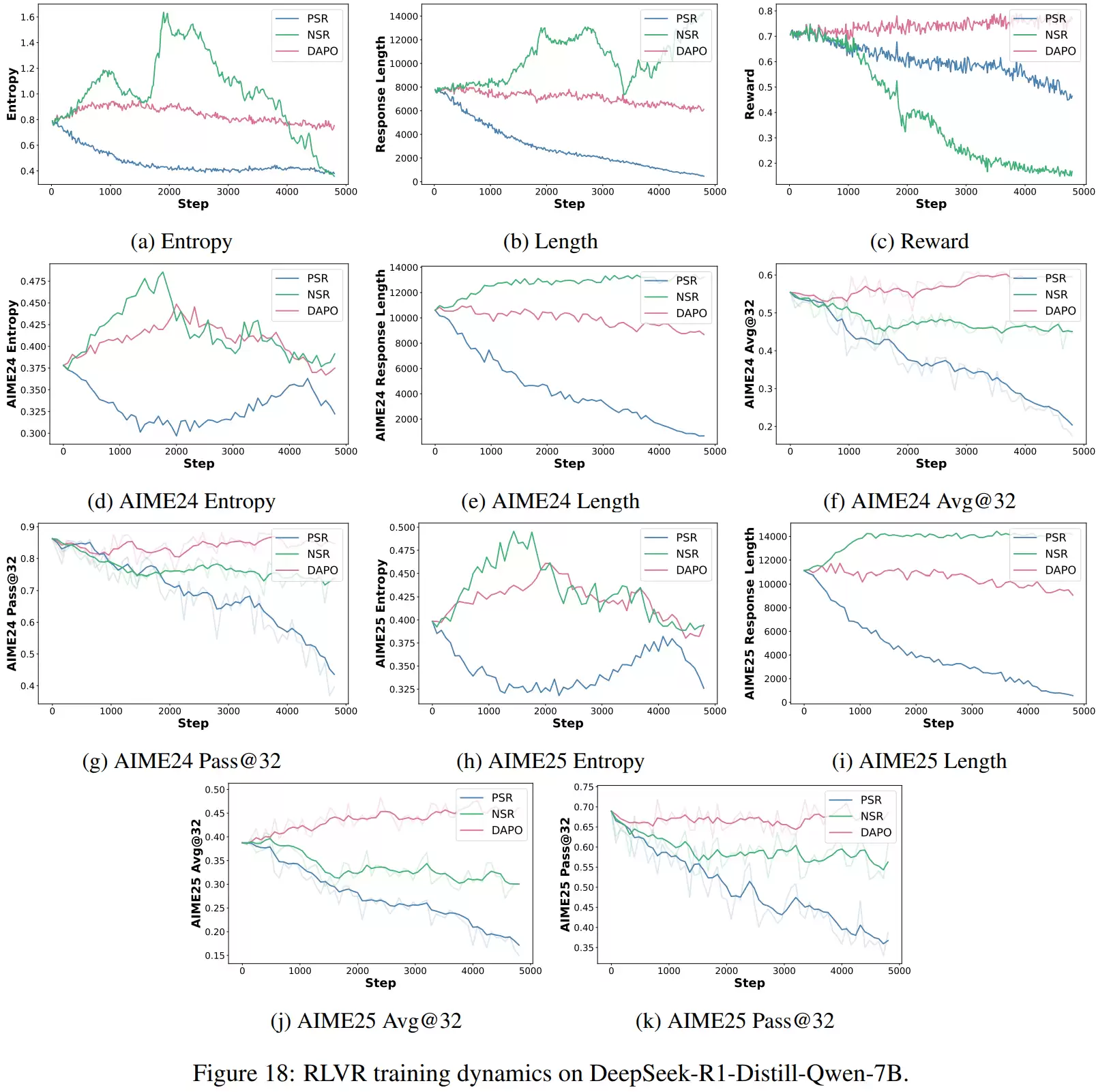
具体来看,当模型仅使用正样本进行训练时,其行为会变得越来越“确定”:输出分布的熵迅速下降,答案分布越来越尖锐,回答长度也明显缩短,常常直接给出结果而省略完整的推理步骤。这说明正样本更像是在强化模型已经掌握的、正确的解题“套路”,同时也会抑制其探索新路径的意愿。
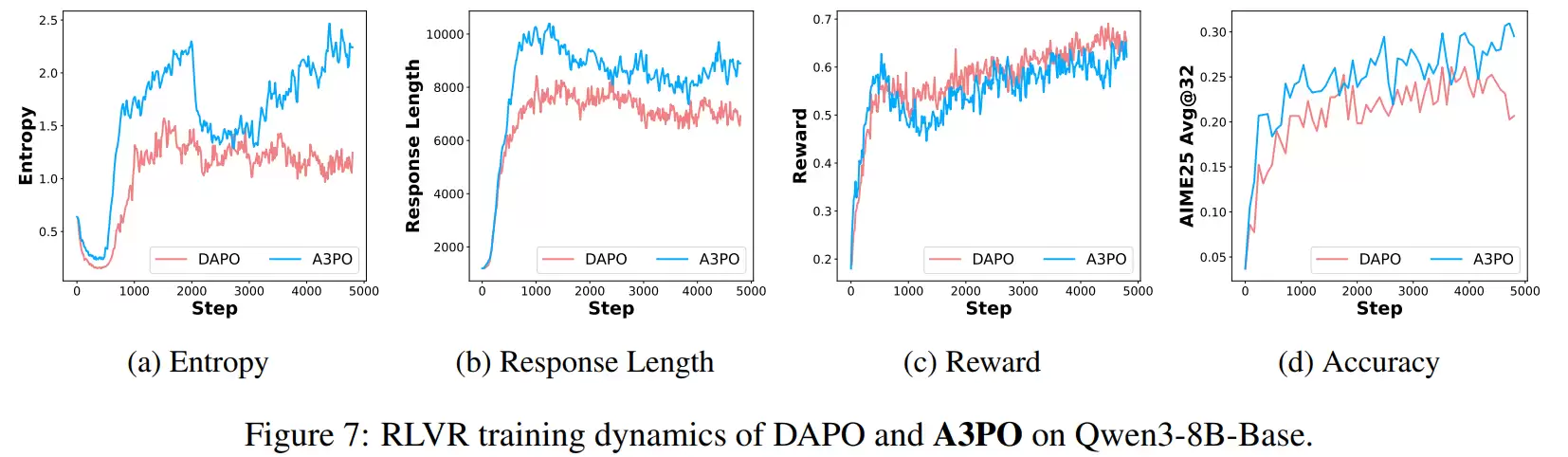
与此形成鲜明对比的是,仅使用负样本训练时,模型的熵保持在较高水平甚至有所上升,生成的回答更长,推理步骤更多,表现出更强的尝试和探索倾向。这是因为负样本训练主要削弱了错误token的概率,使得原本集中的概率分布被分散到其他候选路径上,从而激发了模型的探索能力。
当然,两种极端方式都有其弊端:仅用正样本容易导致“奖励黑客”行为,模型只报答案不推理;仅用负样本则训练不稳定,甚至可能生成乱码。综合比较下来,正负样本同时使用的常规方法,其训练曲线更为平稳,泛化能力也最好。
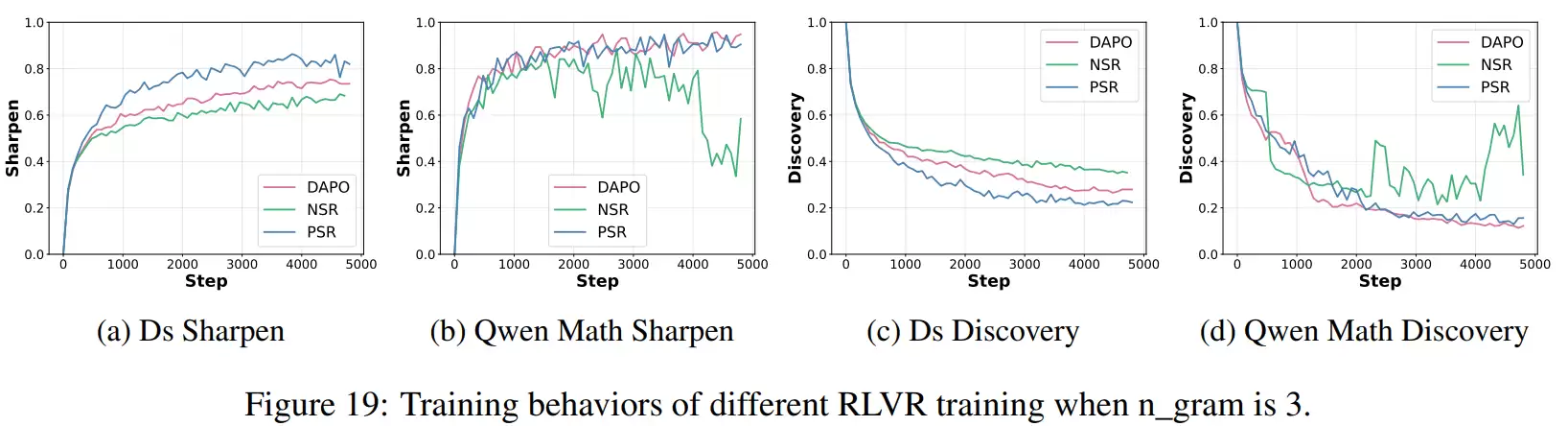
为了更精确地刻画这种变化,研究人员引入了“锐化”和“发现”两个指标。前者衡量模型是否在重复历史正确答案中间出现过的n-gram片段,后者则反映模型是否产生了全新的n-gram。
结果显示,在“锐化”指标上,仅用正样本的训练方式最高,常规方法居中,仅用负样本的方式最低。而在“发现”指标上,顺序则完全相反。这清晰地表明,正样本的作用类似于“磨刀”,让已有的正确模式更熟练、更稳定;而负样本则像在“开路”,推动模型寻找新的推理方式。两者结合,才能既保证稳定性,又拓展能力上限。
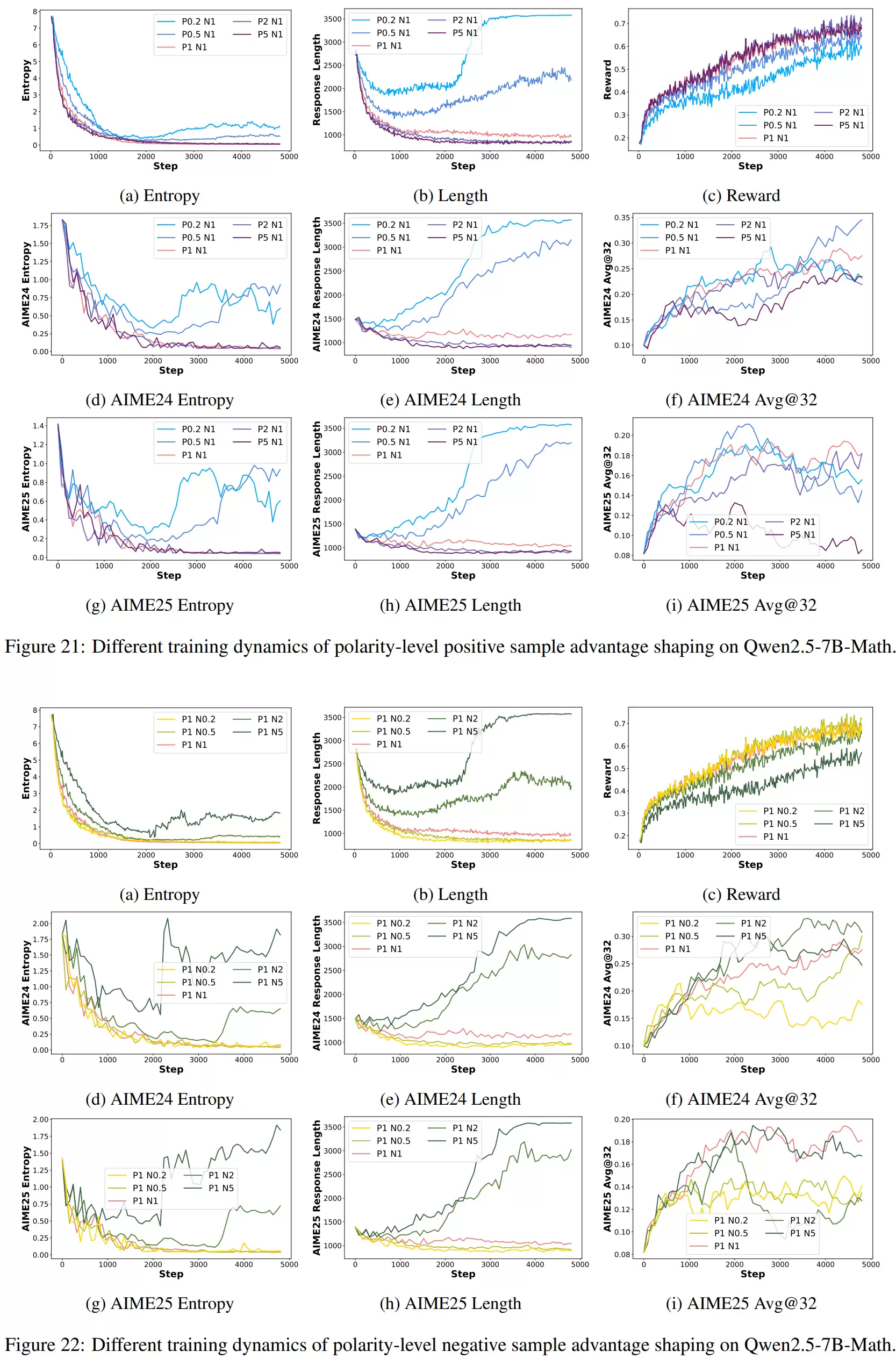
研究团队还从宏观的“优势”权重角度分析了正负样本的影响。以Qwen2.5-7B-Math模型为例,当增大正样本权重时,训练奖励上升更快,但熵值明显下降、输出变短,探索能力减弱,权重过大时甚至会过拟合既有模式。反之,当增大负样本权重时,熵和输出长度都更高,探索更充分,但奖励上升速度变慢,模型表现得更加谨慎。
实验表明,决定训练动态的关键并非各自权重的绝对大小,而在于正负样本之间的比例。例如,正负样本比例为2:1和1:0.5(即相对比例相同)时,训练曲线表现非常相似。总体来看,当正负样本的“优势”比例大约在1:2左右时,能够较好地兼顾收敛速度与探索能力。
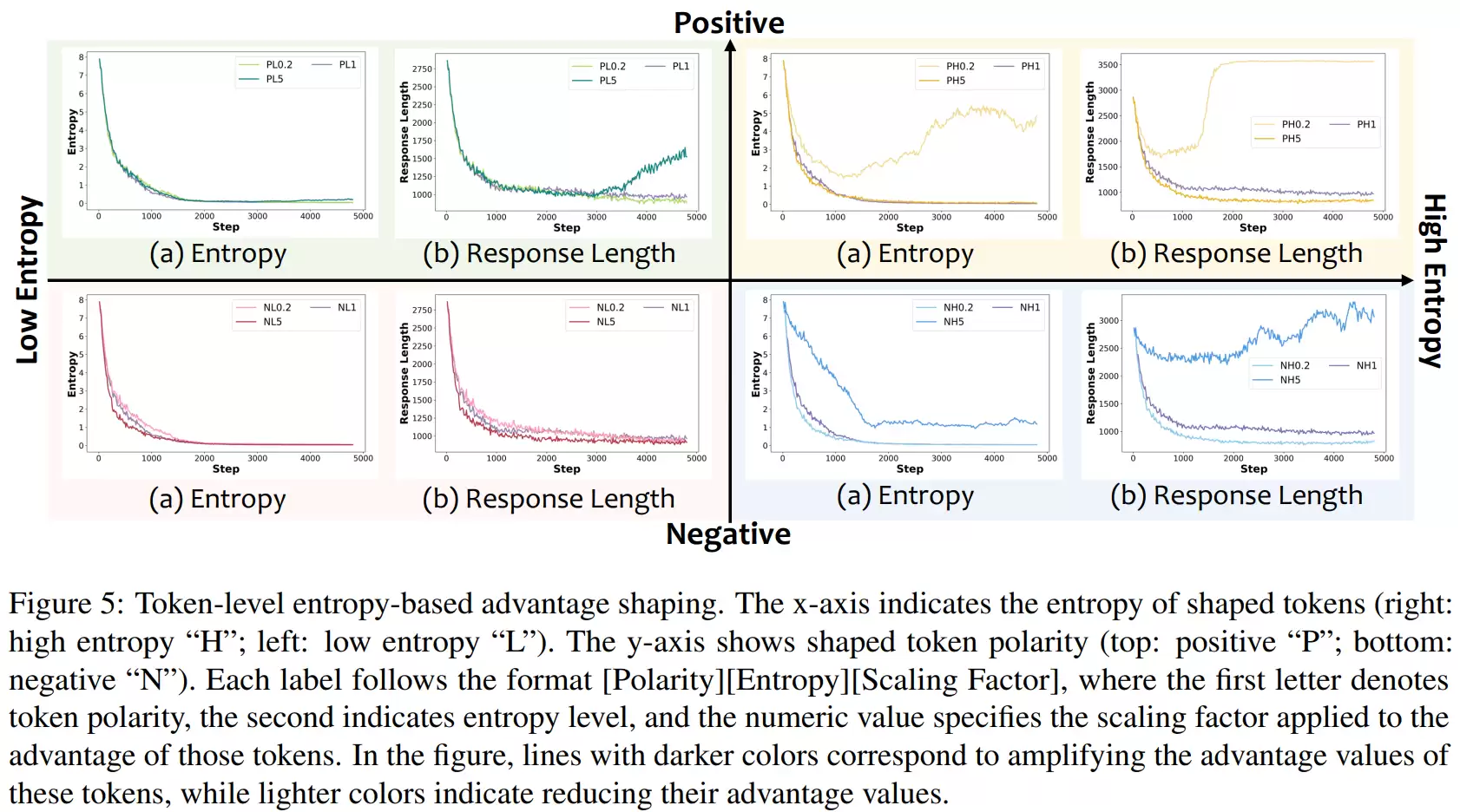
最后,在更细粒度的token级别实验中,研究人员发现了更有趣的现象:并非所有token都同等重要。真正关键的是两类token:一类是正样本中的“低概率token”,即那些模型不太可能选择、但却通向正确答案的冷门推理步骤;另一类是负样本中的“高概率token”,即模型非常自信、但实际上是错误的部分。
前者需要重点奖励,以保留多样但正确的推理路径;后者则需要重点惩罚,防止模型固执地坚持错误答案。新提出的A3PO方法,其设计核心正是围绕这两类关键token进行非对称的加权调整,这一设计也得到了实验数据的支持。
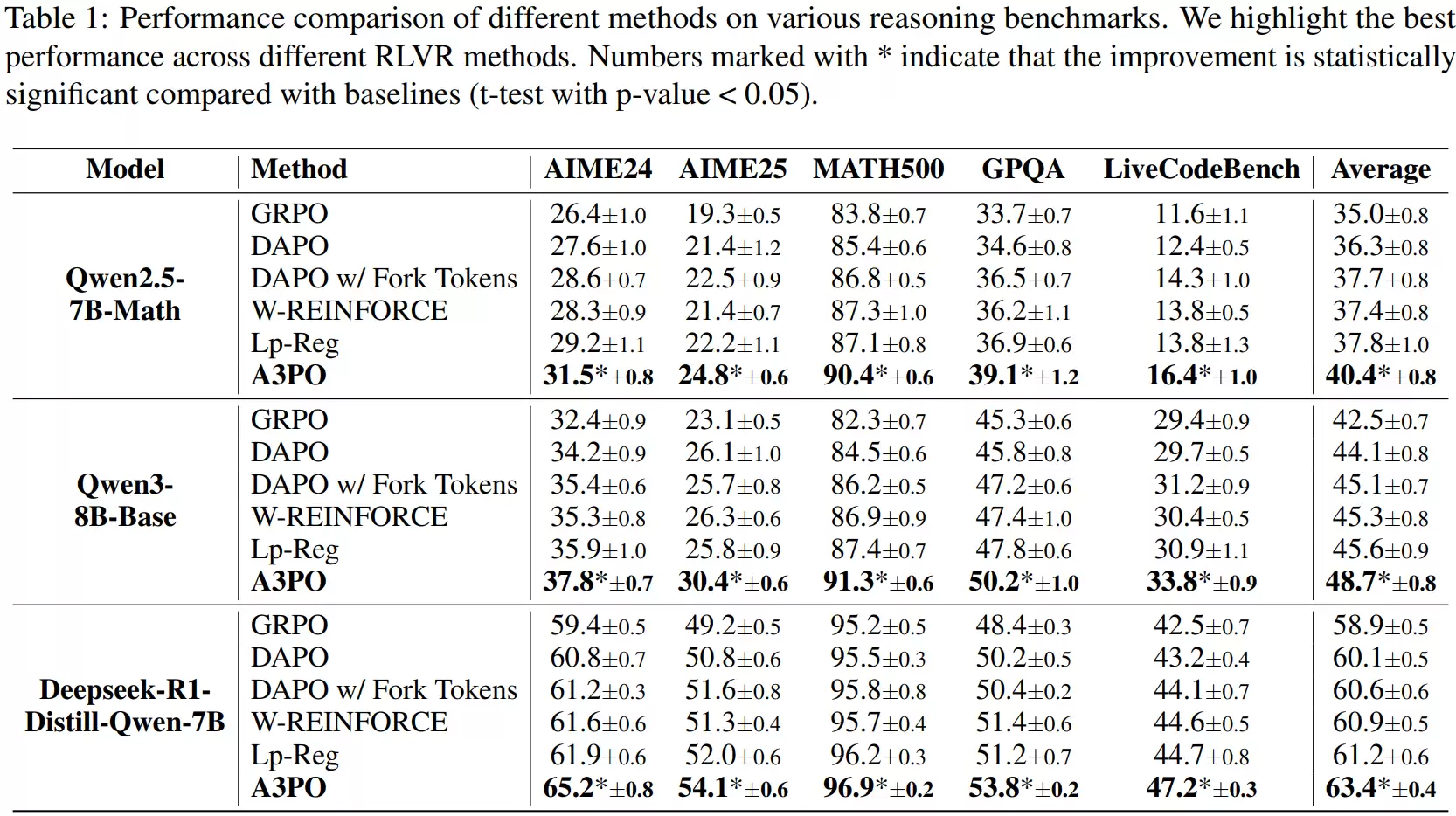
在多项基准测试中,A3PO都展现出了稳定的性能提升。例如,在Qwen2.5-7B-Math上,AIME24与AIME25的得分分别从常规方法的27.6和21.4提升至31.5和24.8;在Qwen3-8B-Base上,也从34.2/26.1提升到37.8/30.4;在DeepSeek-R1蒸馏模型上,则从60.8/50.8提升到65.2/54.1。这些提升并非局限于单一数据集,而是在AIME、MATH500、GPQA等多个推理基准上同时出现,其中多项结果通过了显著性检验。
因此,可以认为A3PO在保持模型较强探索能力的同时,确实带来了明确且泛化性良好的性能提升。
在机制分析基础上构建 A3PO
为了获得全面可靠的结论,研究首先搭建了一套围绕RLVR框架的对照实验体系。其目的不是急于提出新方法,而是先将正样本和负样本的作用拆解开来,分别考察仅用正样本、仅用负样本以及两者并用时模型的具体表现。
实验选择了三种不同类型的大语言模型作为基座:数学能力增强的Qwen2.5-7B-Math、通用预训练模型Qwen3-8B-Base,以及经过推理蒸馏的DeepSeek-R1-Distill-Qwen-7B。训练范式则对比了仅用正样本更新、仅用负样本更新,以及目前较常用的正负样本同时使用的方法。
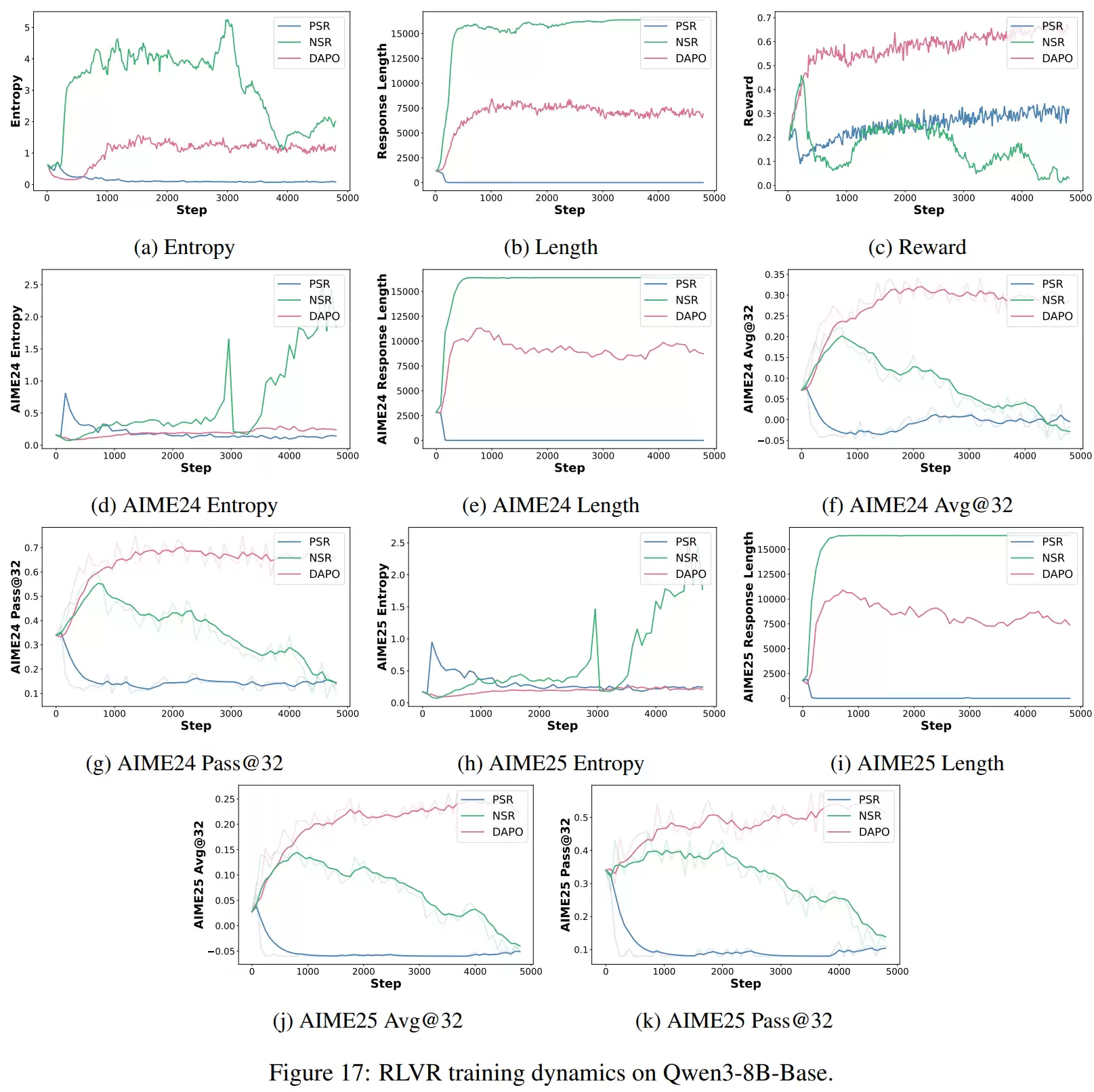
整个训练过程不仅跟踪模型的熵、生成回答长度和奖励值等反映其确定性与探索性的指标,还在验证集上测试了AIME25的A vg@32和Pass@32等指标,以评估真实的推理能力。
在确认正负样本均发挥重要且不同的作用后,研究进入了更精细的参数控制实验阶段,从宏观的“极性”层面调整优势权重。在Qwen2.5-7B-Math上,研究人员将RLVR的损失函数拆分为正样本项和负样本项,通过设置不同的权重组合,系统比较了不同比例下模型的熵、输出长度、训练奖励以及在AIME24上的表现,从而分析整体权重对训练动态的影响。
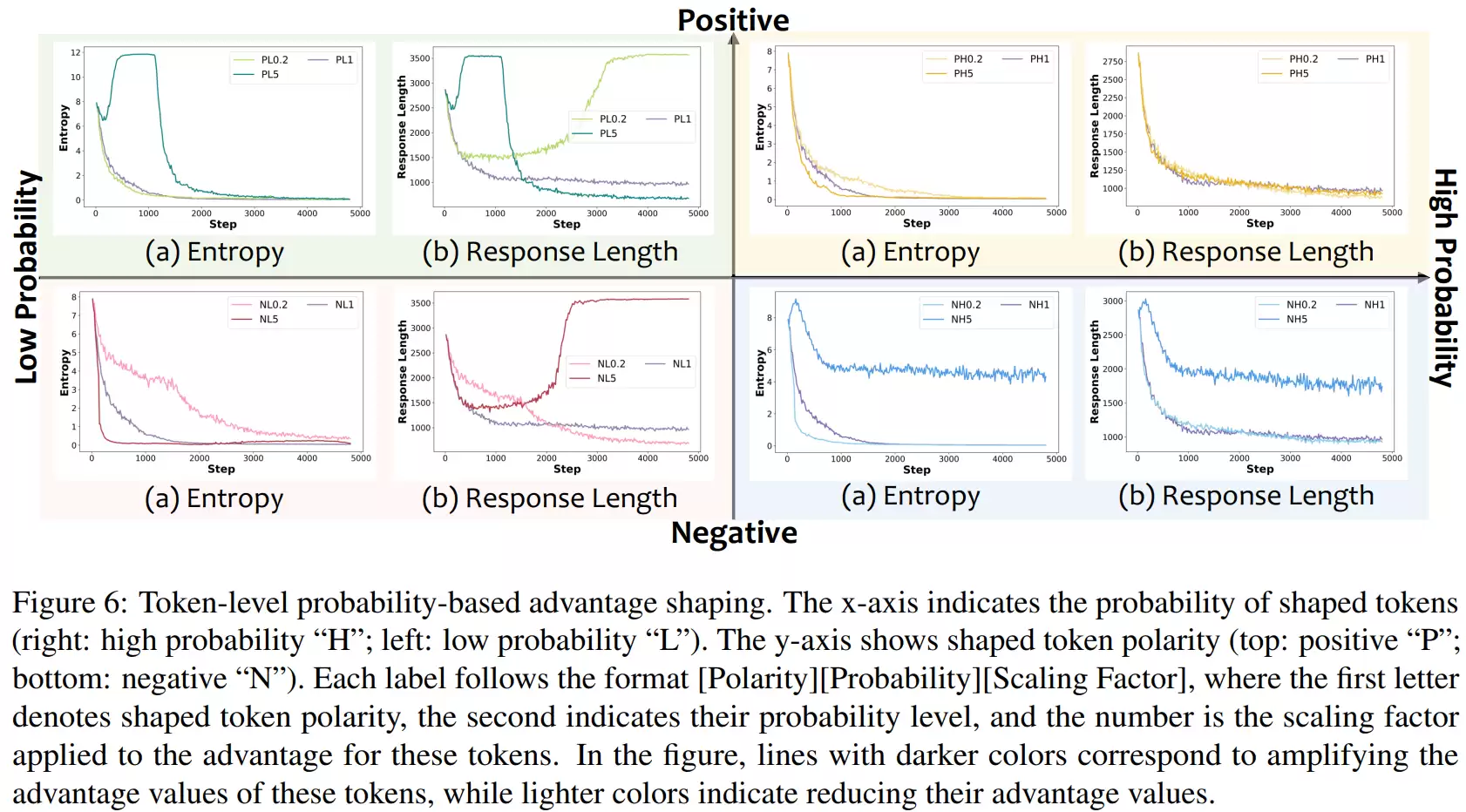
在此基础上,研究的视角被进一步细化到token层面。问题不再是“正负样本整体谁更重要”,而是“一条推理序列内部,哪些token真正关键”。具体做法是根据token的熵和概率两个维度,筛选出正负样本中不同类型(高熵/低熵、高概率/低概率)的token,然后分别对这些token的“优势”进行大幅缩放,观察模型训练曲线与生成行为随之发生的变化,从而定位出对训练最敏感、最关键的决策区域。
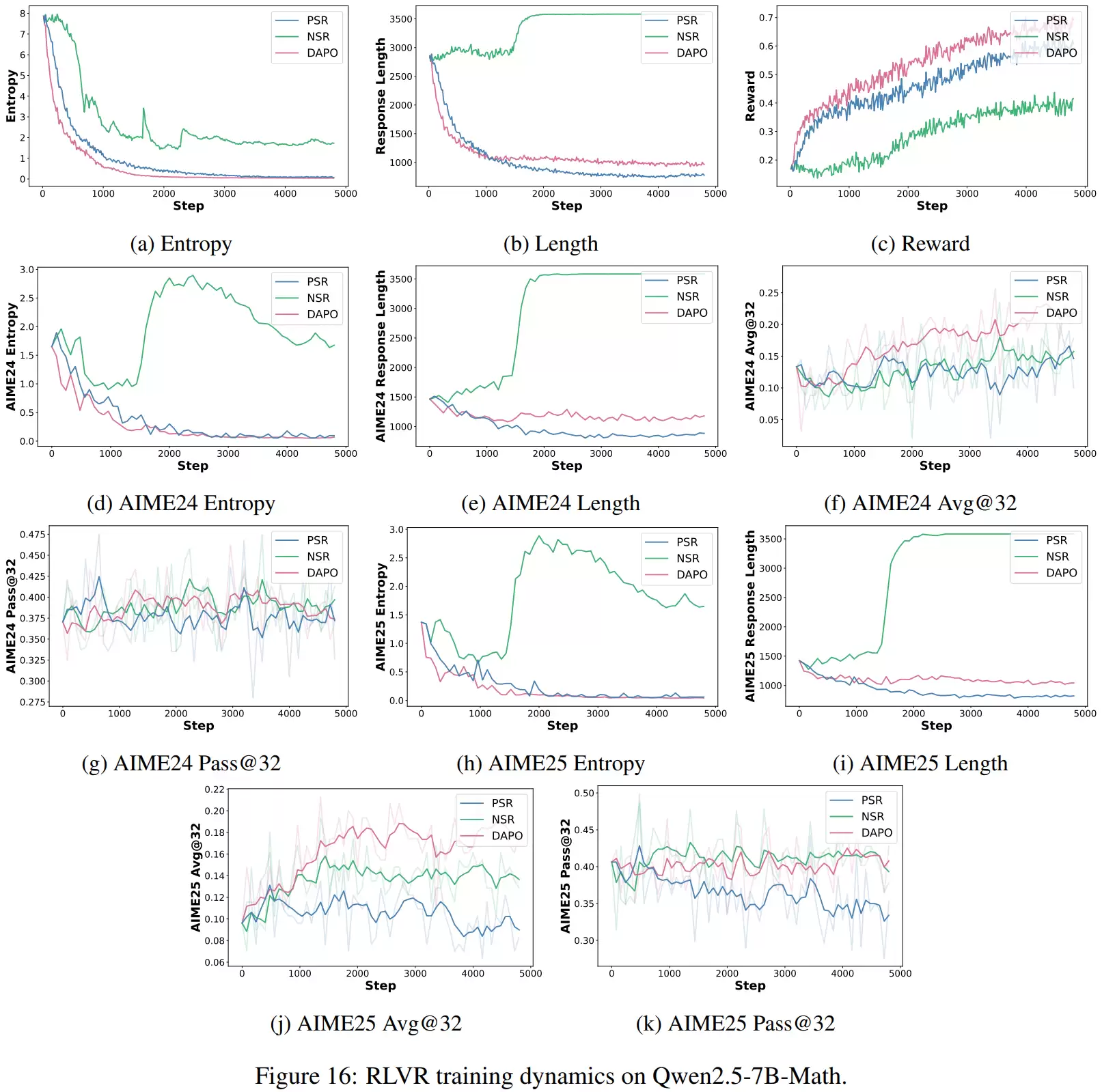
完成以上层层递进的分析后,研究团队最终提出了A3PO方法。其核心思想是在RLVR目标中引入一种自适应、非对称的token级优势加权机制:对正样本中那些低概率但正确的token给予更高奖励,以鼓励保留多样化的正确推理路径;对负样本中那些高概率但错误的token给予更强惩罚,以重点纠正模型自信的谬误。同时,这些加权系数会在训练过程中逐步衰减,使得模型能够从前期的强探索自然过渡到后期的稳定收敛。
实验采用了与前述分析相同的三种模型,在DAPO-Math数据集上进行训练,并与GRPO、DAPO等多种基线方法进行了对比。测试任务涵盖了AIME24、AIME25、MATH500、GPQA与LiveCodeBench等多个主流推理基准。
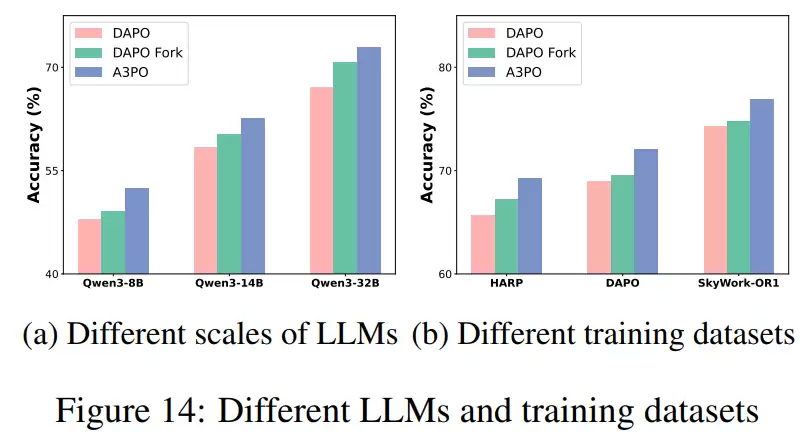
此外,研究还系统评估了A3PO在不同模型规模和不同训练数据集上的泛化能力,并对关键超参数进行了敏感性分析,从而构成了一个完整、严谨的实验设计框架。
正负样本作用边界的重新界定
整体来看,这项研究的核心价值在于,它将原本相对模糊的RLVR训练过程,转化成了一个具有清晰内部机制解释的框架。过去在使用强化学习训练推理模型时,人们虽然知道需要正样本,有时也会用到负样本,但往往难以回答一个根本问题:它们各自究竟在起什么作用?又是如何改变模型学习动力学的?
这项工作通过系统实验给出了明确的答案:正样本主要“缩小”策略空间,使模型已经掌握的正确模式更加集中和稳定;负样本则“扩张”策略空间,迫使模型脱离旧有模式,去探索新的推理路径。更重要的是,研究并未停留在“正样本锐化、负样本探索”这样的概括层面,而是进一步指出,训练质量真正取决于哪些具体的决策点被重点强化。
研究表明,正样本中那些原本选择概率低但通向正确答案的token,以及负样本中那些模型高度自信却指向错误答案的token,对探索与利用的平衡具有决定性影响。
A3PO的设计正是将这一认识具体化为训练原则:在这些关键的“拐点”上进行非对称的优势放大,并让这种偏置随着训练进程逐步衰减。于是,强化学习不再只是简单地增加正确奖励或扣减错误分数,而是转向围绕关键局部决策点,有针对性地塑造策略分布。这样的视角,使得正负样本从被动的数据来源,转变为可被精细调控的优化工具,也将方法研究从经验性的调参,提升到了机制性的设计层面。
从更长远的角度看,这一思路为大模型对齐、多模态推理乃至智能体决策中的强化学习提供了一个共同的方向:即不再平均对待所有行为信号,而是抓住那些对整体策略结构影响最大的关键token或关键状态进行重点塑形。
背后的学术力量
这篇论文的通讯作者为赵鑫,现任中国人民大学高瓴人工智能学院教授、长聘副教授,同时也是国家优秀青年科学基金项目获得者。
赵鑫教授于2014年7月在北京大学取得博士学位,之后便任职于中国人民大学,长期从事信息检索与自然语言处理领域的教学与科研工作。截至目前,他已发表学术论文200余篇,谷歌学术引用量超过1.8万次。
他牵头开发了开源推荐系统工具RecBole(伯乐)和文本生成工具TextBox(妙笔),并组织撰写了《A Survey of Large Language Models》综述论文及中文专著《大语言模型》。
赵鑫教授曾获得吴文俊人工智能优秀青年奖(2020)、ECIR 2021时间检验奖、RecSys 2022最佳学生论文提名、CIKM 2022最佳资源论文提名等荣誉,并入选中国科协青年人才托举工程、北京智源青年科学家和CCF–IEEE CS青年科学家计划。其系列研究成果还荣获了教育部自然科学一等奖、北京市自然科学二等奖及中国计算机学会自然科学二等奖。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

大模型与CodeQL代码审计解决方案、技术栈及前沿方向分析
代码审计的格局,正在被大模型悄然重塑。从最初的辅助分析,到如今的规则自主生成、告警智能过滤,乃至专用模型的构建,大型语言模型(LLM)与CodeQL这类传统静态分析工具的结合,正变得前所未有的紧密和高效。 引言 随着软件系统日益复杂,安全漏洞的检测与修复已成为开发过程中的核心挑战。以CodeQL为代

AI全栈开发实践:基于Harness与SDD的多仓库管理模式详解
Harness思维的核心,是引导AI基于现有范例进行模仿与复刻,而非要求其进行无约束的自由创造。这就像指导一位新同事时,最有效的方式是明确指示:“请参考隔壁团队已上线的XX模块,按照其代码风格和架构实现一个类似功能”,而不是模糊地说“你来处理一下”。前者能显著提升产出代码与团队既有规范和项目整体风格

Claude 迁移至 Codex 技能编排实践与经验总结
从Claude迁移到Codex,本应是一次平滑的技术切换,却意外演变成一场关于智能体工作流实战的深度逻辑考验。这背后揭示的行业趋势,远比一次简单的模型选型更值得深入探讨。 在AI工程实践中,我们常有一种误解:只要大模型足够强大,就能自动理解开发者的复杂意图。然而,当你在生产环境中部署一个多阶段、有状

包车收费模式转变从成果付费到用量付费引争议
曾几何时,我们乐观地认为,AI将沿着成熟SaaS的价值路径演进,最终实现公平合理的按效果付费。如今看来,这一愿景已然破灭。当AI行业发现自己无法复制SaaS那套稳固的商业模式基础时,便果断放弃了最初的承诺,转而投身于另一个早已预设好的商业轨道。 近期的行业动态,想必大家已有感知。多家头部AI公司相继

马斯克宣布xAI并入SpaceX并更名为SpaceXAI
今天科技界迎来重磅战略调整。埃隆·马斯克在其社交平台X上正式宣布,旗下人工智能公司xAI将结束独立运营,全面整合进入SpaceX体系,并更名为SpaceXAI。这一举措标志着AI与航天技术的深度融合迈出关键一步。 此次决策源于马斯克对人工智能未来发展的核心判断。他认为,当前地面数据中心面临日益严峻的








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
