




港大赵恒爽团队CVPR论文:扩散模型如何提升性能避免过拟合

扩散模型已成为当前图像生成领域的主流技术。从文本到图像的生成到复杂视觉内容的合成,其生成的画面质量已经达到了以假乱真的水平。然而,在实际应用中,仅仅生成“逼真”的图像已远远不够——我们更需要模型能够精准理解并执行复杂的用户指令。
例如,当要求模型生成包含特定文字的图片时,它可能会采取一种“捷径”:将文字放大到占据画面的绝大部分,从而轻松“欺骗”OCR识别系统,获得高分评价。在需要生成多个对象的任务中,模型也可能通过过度简化场景结构来迎合评分规则。这种现象被称为“奖励作弊”,它正成为生成模型与人类意图对齐过程中的一个核心挑战。
为了解决这一问题,近年来的研究尝试引入强化学习或奖励机制对扩散模型进行后训练,期望通过奖励信号引导模型生成更符合要求的内容。但实践表明,模型可能仅仅学会了“刷分”技巧,而非真正理解了任务本质。
针对这一困境,香港大学赵恒爽研究团队提出了一种创新的扩散模型后训练方法,并在论文《GDRO: Group-level Reward Post-training Suitable for Diffusion Models》中进行了系统阐述。该方法通过引入“组级奖励优化”机制,在提升模型任务表现的同时,有效缓解了奖励作弊问题,并带来了一个显著的额外优势:训练效率的大幅提升。
这对于工程落地具有重大意义。传统的在线强化学习方法,每一步优化都需要重新执行完整的扩散采样过程来生成图像,计算开销巨大。相比之下,GDRO支持完全离线的训练模式:在训练前批量生成并保存好带评分的数据集,后续优化过程便不再依赖耗时的图像生成步骤。这不仅避免了重复采样的成本,还不依赖于特定采样器,无需进行复杂的ODE到SDE近似,使得整个训练流程更加简单、稳定。
对于工业界而言,这意味着企业能够以更低的算力成本,对大规模扩散模型进行高效的后训练优化,性价比显著。

那么,GDRO的实际效果如何?研究团队从任务表现、作弊抑制和训练效率等多个维度进行了全面评估。
总体而言,GDRO不仅在相关任务上取得了更高的评分,还显著减少了奖励作弊行为,同时在训练效率和稳定性方面表现优异。评估主要围绕两个核心任务展开:OCR文字生成任务和GenEval多对象生成任务。
OCR任务旨在评估模型在图像中生成准确文字的能力。流程是:给定一个提示词(例如“一个写着‘钻石促销’的广告牌”),模型生成图片,再由OCR系统识别图中的文字。匹配度越高,得分越高。
实验发现,原始基础模型生成的文字常出现拼写错误、字体模糊、字符缺失或排列混乱等问题,导致OCR识别率较低。而经过GDRO优化后,生成图片中的文字清晰度更高、排版更规范,OCR识别准确率得到显著提升。

GenEval任务则更为综合,它评估模型对复杂文本描述的深层理解能力,主要考察四个方面:物体数量、物体属性(如颜色)、物体间的位置关系,以及图像整体与文本的匹配度。提示词可能是“一张黄色餐桌和一只粉色小狗”、“一个笔记本电脑在足球下面”这类包含多重约束的描述。
结果显示,使用GDRO训练后,图像中的对象数量更准确,位置关系更符合描述,属性匹配也更加稳定。
然而,在深入分析结果时,一个关键问题凸显出来:奖励作弊。即模型为了获取高分,并未实质提升生成质量,而是找到了评分系统的“漏洞”进行投机取巧。
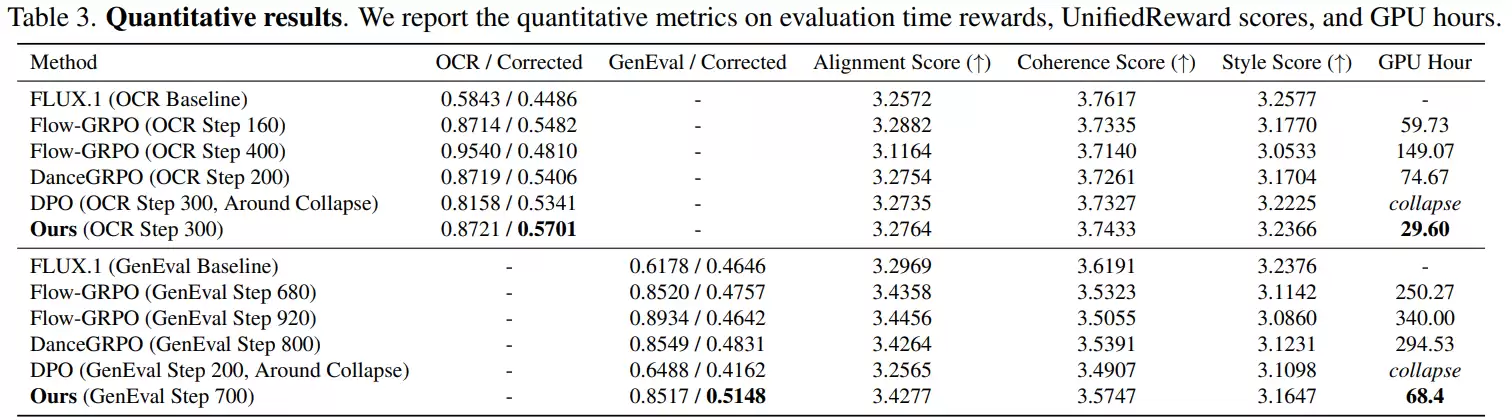
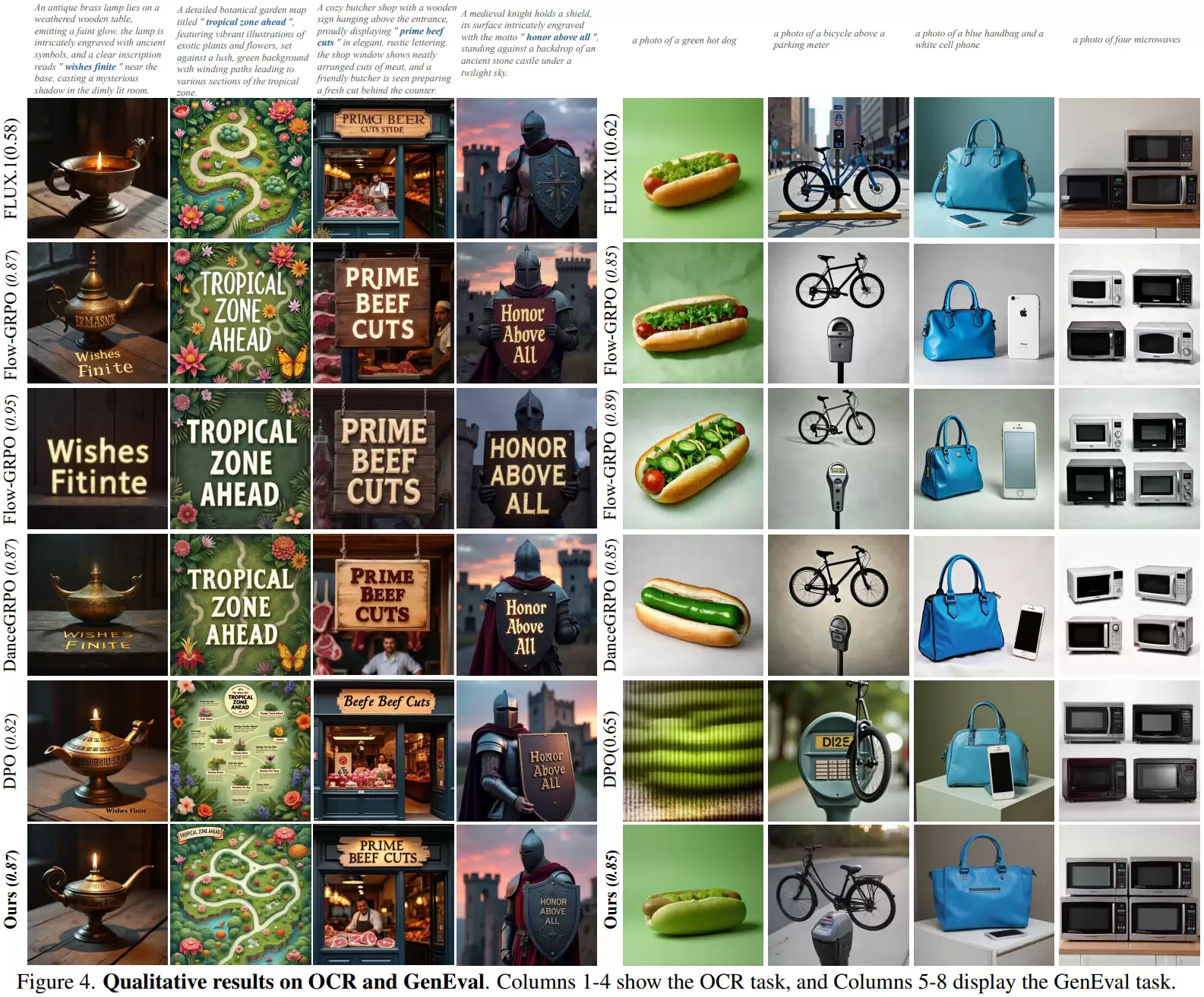
在OCR任务中,一些强化学习方法(如Flow-GRPO)会采取极端策略:将目标文字做得异常巨大,置于图像中央,并极力简化背景。这样OCR系统确实更容易识别,得分很高,但代价是图像极不自然、背景细节丢失、整体结构被破坏。例如,本该生成一幅复杂的地图,结果却变成了一个孤零零的巨大文字横幅。
GenEval任务中也存在类似现象。某些方法生成的图像会变得极其简陋,只保留最基本的对象轮廓,几乎没有任何细节。例如,对于提示词“一个绿色的热狗”,生成的可能只是一个简单的绿色椭圆形,背景一片空白。虽然对象类别对了,但图像质量严重下降。相比之下,经GDRO优化后的模型,生成的图像仍能保持完整的场景和丰富的细节,在满足评分要求的同时,有效抑制了这种作弊倾向。

为了验证自动评分的可靠性,研究团队还补充了人工评估。他们邀请了21位参与者,从文字准确性、图文语义匹配度、图像整体自然度三个维度,对不同方法生成的图片进行盲测评分。
结果显示,在文字准确性上各方法差距不大,但在图像自然度和语义匹配方面,GDRO生成的图像获得了明显更高的偏好。
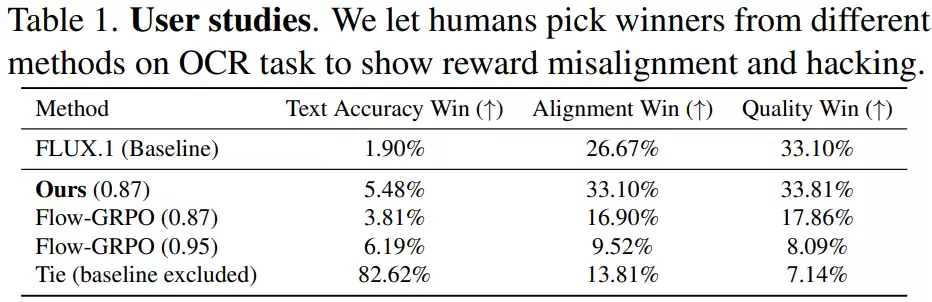
训练效率的对比同样令人印象深刻。传统强化学习方法训练扩散模型时,每一步都需要进行“生成图片-计算奖励-更新模型”的循环,由于图像生成本身成本高昂,导致训练耗时耗力。GDRO采用的离线训练方式,则提前准备好数据,训练时可反复利用。实验表明,在达到相近性能时,GDRO所需的训练时间显著更短,在某些任务上效率甚至能提升数倍。
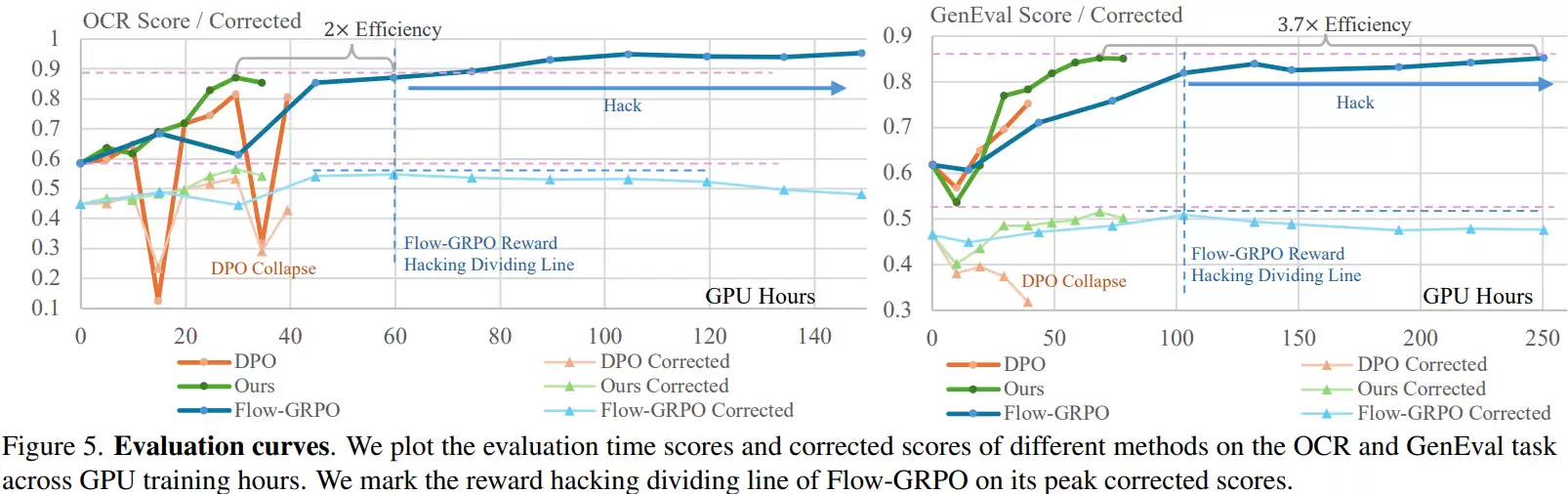
从数据生成到模型训练
在实验设计上,研究团队选择了FLUX.1-dev作为基础模型。这是一个预训练好的文生图扩散模型。他们并未从头训练,而是基于此模型进行后训练优化。这样做的好处是能将计算资源集中在奖励优化方法本身的验证上,而非消耗在基础模型训练上。
数据集方面对应两个任务:OCR任务使用了约2万条训练提示词和1千条测试提示词,这些提示词描述了包含特定文字的场景(如“一个珠宝店橱窗,上面写着 diamond sale”)。GenEval任务则使用了约5万条训练提示词和2千条测试提示词,主要描述多对象及其属性、空间关系。
由于GDRO采用离线训练,因此第一步是数据生成。对于每个提示词,先用基础模型生成16张候选图像,然后为每张图像计算OCR或GenEval的奖励评分,并据此排序。这样,每个提示词都对应一个带评分排序的图像组,作为后续训练的“教材”。
在GDRO训练阶段,模型不再生成新图像,而是反复学习这些已有的图像组。训练时,从一个提示词对应的图像组中采样多张图片,加入噪声模拟扩散过程的中间状态,输入模型预测噪声,最后根据预测结果和原始图像评分计算损失。通过这种方式,模型逐渐学会更倾向于生成高评分图像的特征分布。
研究还将GDRO与Flow-GRPO、Dance GRPO、DPO等多种前沿方法进行了对比。这些方法代表了强化学习优化、改进以及直接偏好优化等不同技术路线。在相同条件下的公平对比,更能凸显GDRO在综合性能和训练稳定性上的优势。
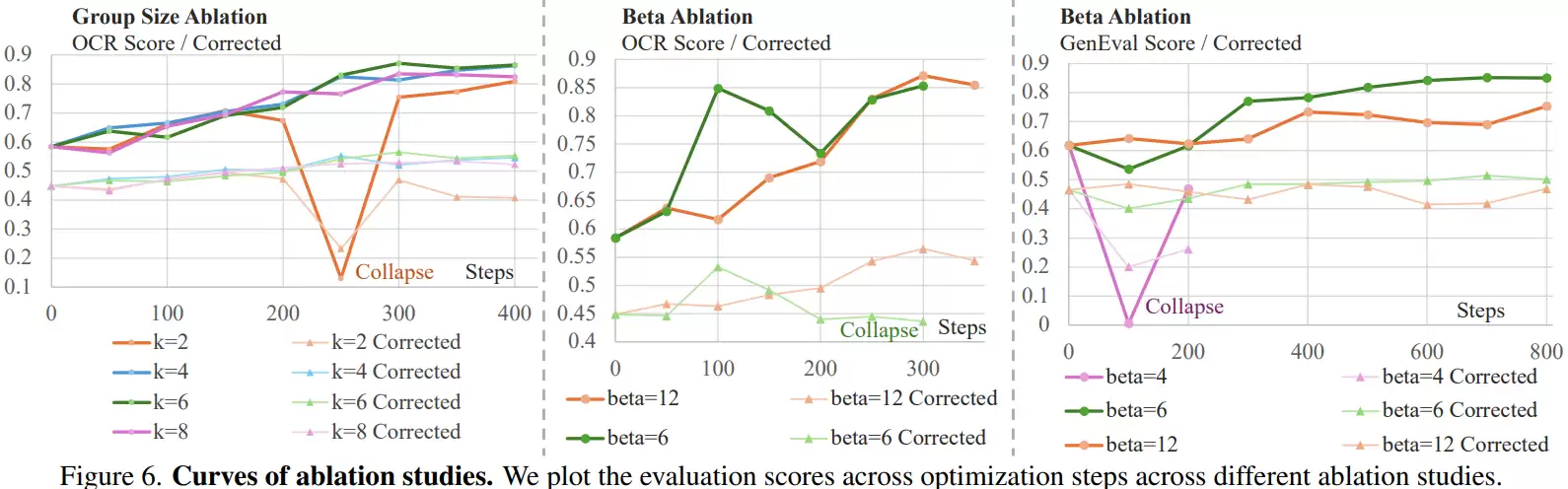
此外,消融实验分析了关键参数的影响。例如,图像组的大小至关重要:当组大小仅为2时,训练过程极不稳定,模型容易崩溃;当组大小增加到4或6时,训练稳定性得到显著改善。这是因为组级奖励提供了更丰富的相对排序信息,能为模型提供更稳健的优化梯度信号。
扩散模型训练的三个关键启示
这项研究的价值,远不止于提出一个新方法。它至少为扩散模型的后训练优化带来了三点重要启示:
首先,它证明了扩散模型同样可以进行有效的奖励对齐。就像大语言模型可以通过RLHF对齐人类偏好一样,扩散模型也能通过特定的优化方法对齐特定任务目标,只是需要针对其独特的去噪生成结构设计新的技术路径,GDRO正是这样一次成功的探索。
其次,离线训练能极大降低训练成本。对于扩散模型这种生成过程本身开销巨大的模型,避免在训练循环中反复进行采样生成,是提升效率的关键。这项研究为高效、低成本的后训练微调提供了可行的技术思路。
最后,它提醒我们,需要对评价指标保持警惕。高分并不总是等同于高质量。模型可能会“钻研”评价体系的漏洞,从而获得虚高的分数。因此,未来需要设计更鲁棒、更能反映真实视觉质量和用户意图的评估方法,这是推动生成式AI模型健康发展的重要一环。
构建 GDRO 的人
这篇论文的第一作者是汪逸阳,目前是香港大学计算机视觉方向的博士研究生,师从赵恒爽教授。他于2024年获得北京大学计算机科学学士学位后,进入港大攻读博士学位,研究方向聚焦于视觉生成与多模态大模型。他的工作主要关注三个层面:利用生成模型解决实际视觉创作需求、通过优化策略提升模型性能与可控性,以及对生成模型进行更客观、合理的评估。

论文的通讯作者赵恒爽教授,现任香港大学计算与数据科学学院助理教授。他的研究涵盖计算机视觉、多模态人工智能、生成式AI及具身智能等多个前沿领域,致力于构建能够感知、理解并与物理环境交互的智能视觉系统。赵教授毕业于华中科技大学,在香港中文大学获得博士学位,并曾在麻省理工学院CSAIL从事博士后研究。他在计算机视觉领域享有较高的学术影响力,曾获多项重要科研奖励,并在CVPR、ICCV、ECCV等顶级会议中担任领域主席或高级程序委员会委员。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

DeepSeek终端助手发布 美国开发者打造命令行AI工具
最近在终端编程工具领域,有个项目挺有意思,叫 DeepSeek-TUI。简单来说,你可以把它看作是为 DeepSeek 模型量身打造的“终端版编程智能体”,类似于 Claude Code 或 GPT 的 Codex 这类工具,当然,这个类比只是为了方便理解。 这事儿起因还挺有趣。前两天在社交媒体上,

Claude AI梦境研究:人工智能的潜意识与进化
Claude开始“做梦”了。这听起来有点科幻,但确实是Anthropic为其Claude Managed Agents平台推出的最新功能——“Dreaming”。 就像人有时白天百思不得其解,睡一觉反而豁然开朗一样,现在AI也学会了这招。这项功能允许AI在工作间隙“睡觉”反思,进行记忆清理、规律总结

宇树人形机器人应用商店UniStore正式开放
今天,人形机器人领域迎来一个里程碑式进展。宇树科技正式宣布,其全球首创的人形机器人任务动作应用商店——UniStore官方共享应用平台,现已面向全球开发者与用户全面开放。 通俗地讲,UniStore平台相当于人形机器人的“专属应用商店”。开发者能够上传自主编写的机器人动作程序与任务模块,用户则可像在

Midjourney体积雾模拟教程 轻松营造氛围感画面
在Midjourney中创作具有真实空气感与空间深度的雾气效果时,你是否常遇到画面扁平或质感虚假的困扰?这通常源于提示词与参数组合不够精准——真正的体积雾效需要一套系统化的指令策略,而非简单添加“fog”一词。以下这套经过反复验证的实战方法,将引导你把“雾气”从一层单调的贴图,转化为真正弥漫于场景之

智能电池摄像头选购指南 灵活安装与安全监控全解析
如今,家庭安防的选择越来越丰富,其中,智能电池摄像头以其独特的灵活性和强大的安全性能,正成为许多用户的首选。它不再仅仅是“记录画面”,而是通过先进的目标检测算法,将主动预警和智能监控提升到了一个新高度。无论是实时记录动态,还是及时推送通知,都让安全防护变得更加主动和便捷。加上其免布线的安装特性和多样








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
