




具身智能先锋吴琦谈视觉语言导航挑战与未来

2018年6月,澳大利亚机器人视觉研究中心(ACRV)的一项开创性研究,首次将视觉-语言(VL)技术与当时机器人领域的主流方向——导航——进行了深度融合。这项由博士后研究员吴琦与博士生Peter Anderson共同完成的工作,在CVPR 2018上发表了视觉-语言-导航(VLN)领域的奠基性论文。几乎在同一时期,由Abhishek Das作为第一作者发表的“EmbodiedQA(具身问答)”研究,则让“具身智能”这一前沿概念进入了更广泛研究者的视野。
一个月后,在墨尔本举行的ACL会议上,一场由这三位研究者主讲的“连接语言、视觉与动作”专题教程,正式为视觉-语言-动作(VLA)这一全新交叉领域拉开了序幕。

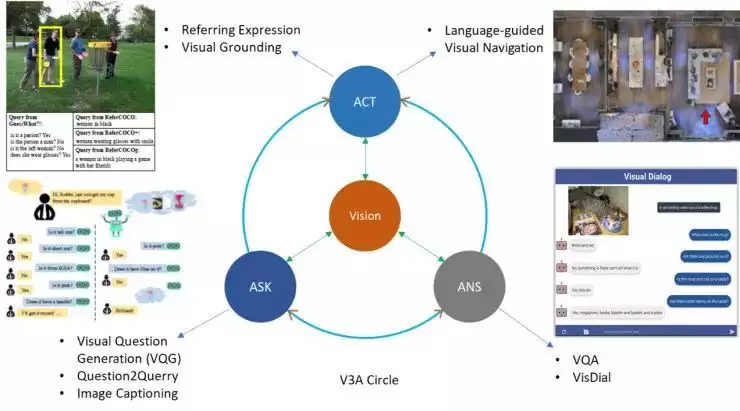
教程现场,众多自然语言处理学者对这一新兴方向表现出浓厚兴趣。除了介绍CNN、RNN等基础模型,三位讲者还深入分享了他们对机器人数据采集、环境仿真器构建以及强化学习应用的前瞻见解。正是对VLN的持续探索,让吴琦深刻认识到,机器要解决现实世界的复杂问题,不仅需要理解和融合多模态信息,还必须具备与物理环境进行有效交互并执行动作的能力。因此,他在经典的VL框架中创新性地加入了“动作(Action)”维度,提出了“V3A”概念,即“视觉(Vision)、提问(Ask)、回答(Answer)与行动(Act)”。
吴琦的学术生涯具有鲜明的国际化背景:本科毕业于中国计量大学,随后在英国巴斯大学取得硕士和博士学位,继而在澳大利亚阿德莱德大学进行为期三年的博士后研究,并于2018年起留校任教。他的学术贡献获得了国际学界的广泛认可,先后荣获澳大利亚科学院颁发的J. G. Russell奖以及南澳大利亚州杰出青年科学家称号,其谷歌学术论文引用量已超过1.4万次。
作为视觉-语言领域的早期开拓者之一,吴琦的研究始终走在学术前沿。在MS COCO数据集推动图像描述任务兴起后,他于2015年迅速跟进并产出成果;随后又在视觉问答(VQA)这一新兴热点方向发表了“Ask Me Anything”等代表性工作;最终在2018年引领并开启了VLA领域的研究。

七年时间过去,VLA已成为当前具身智能领域最受关注的核心方向之一。全球范围内,从英伟达的GROOT N1、Figure AI的Helix,到Physical Intelligence的π0、清华大学的RDT,一系列机器人VLA大模型相继涌现。
作为该领域的奠基人之一,吴琦选择在VLN方向上持续深耕,并从去年开始着力推进一系列真机实验与落地验证。目前,他在澳大利亚阿德莱德大学担任副教授,领导着专注于视觉、语言与动作研究的“V3A Lab”实验室,同时也在澳大利亚机器学习研究中心(AIML)担任视觉与语言研究方向的实验室主任。
谈及具身智能与VLA的未来,吴琦认为VLA的研究范畴不应局限于上半身的操作任务。他指出:“许多人认为导航问题已基本解决,而操作任务因其与产业的紧密结合更易落地。但实际上,视觉语言导航(VLN)仍然存在大量极具挑战且有待突破的科学问题。”
VLA的“七年之痒”:从概念萌芽到产业热潮
问:回顾2018年,您提出了“V3A”概念,在原有的视觉-语言(VL)框架中加入了动作(Action)。当时是受到哪些关键启发,促使您开启了VLA这一全新研究方向?
吴琦:最早在CVPR 2018会议上,我与Peter、以及Embodied VQA的作者Abhishek交流后,发现彼此的研究在理念上高度互补,于是决定在即将举行的ACL会议上联合举办一场教程。当时我们意识到,单纯的视觉-语言主题研讨会已较为常见,缺乏新意,因此需要注入新的元素。我们研究的导航和Abhishek研究的问答,本质上都属于“动作”的范畴,因此我们决定策划一个关于视觉、语言和动作三者结合的讲座,这可以看作是VLA概念的早期雏形。
我们首篇关于VLN的工作开辟了这个新领域,但初期主要是提出了R2R数据集和任务定义,学术界的反响相对平淡。真正的转折点出现在第二年,CVPR 2019的最佳学生论文奖授予了王鑫那篇利用模仿学习与强化学习协同解决VLN问题的工作,这才彻底点燃了整个领域的研究热情。
出于对VLA理念的深度认同,我进一步提炼出“V3A”框架。最初的构想是,希望机器人或虚拟智能体能够基于视觉输入来回答问题,这证明了其“理解”能力;而当时视觉问题生成领域的研究认为,主动提问比被动回答需要更强的推理能力;在具备了自然语言对话能力之后,我们最终希望模型能够执行如导航之类的物理动作。为此,我们还专门提出了“远程具身视觉指称表达”任务,即让机器人完成“请帮我找一个勺子”这类基于复杂语言指令的导航与搜索任务。
问:在您看来,2018年前后的那波早期VLA研究与当前具身智能浪潮下的VLA研究,存在哪些本质区别?VLA领域的发展经历了哪几个重要的里程碑阶段?
吴琦:我们最初提出VLA概念时,机器人操作任务还未成为热点。那时的“动作”定义可能更偏向高层抽象指令,距离实体机器人更远,例如理解场景后回答问题,或者规划路径导航到指定位置。此外,当时可用于训练的数据规模与今天相比,存在数量级上的巨大差距。
在Embodied QA出现后,VLA领域经历了一段平台期,部分原因在于其使用的数据存在版权限制,导致其他研究者难以复现和跟进。而VLN在VLA的发展历程中扮演了关键角色,我们的工作最早将VL与动作结合起来,加上王鑫在CVPR 2019的获奖工作,共同让VLN和VLA获得了广泛关注。随后,上海交通大学的卢策吾老师团队将操作任务与具身智能深度结合,提出了许多创新的数据集和评测基准。
接下来是一个至关重要的节点:GPT系列大语言模型的横空出世。在此之前,尽管存在视觉-语言大模型,但在解决许多复杂的视觉问答任务上表现平平。当时的主流观点认为,在VL的基础问题尚未妥善解决之前,引入动作维度是不现实的。而GPT的出现,尤其是在集成多模态能力之后,解决了许多传统VL模型难以处理的任务,其零样本性能甚至超越了当时最大的VL预训练模型。因此,学术界开始形成一种共识:VL的一些基础任务已被有效攻克,是时候引入更高层次的维度,即利用融合后的视觉语言信息来预测和输出具体动作,而不仅仅是停留在难以落地的VQA任务上。
问:在具身智能热潮兴起之前,自动驾驶行业曾备受瞩目。从技术角度看,自动驾驶与机器人分别对VLA提出了怎样独特的要求?如果单纯从导航功能出发,研究人形机器人(双足)的意义有多大?
吴琦:自动驾驶在某种意义上也是一种VLA的典型应用:视觉对应复杂的户外道路场景,语言对应乘客或系统的语音/文本指令,动作则对应车辆的操控行为。当然,这里的动作可以细分为车辆本身的控制(如转向、加速),也可以是车载系统的交互操作(如播放音乐、设置导航目的地)。
机器人的VLA则有所不同。除了无人机等特殊形态,大部分机器人应用集中在室内场景。其视觉输入主要针对室内结构化环境和小型物体,而动作则要求精度更高的操作任务(如抓取、装配),或者对移动精度要求更高的导航任务。
我们团队去年基本实现了纯视觉语言导航在实体机器人上的部署与运行,测试平台包括四足机器狗、扫地机器人和轮式机器人。我们认为在双足机器人上部署VLN系统,在技术上也是可行的。因为目前“大脑”(高层决策与路径规划)和“小脑”(底层运动控制)的开发通常是解耦的。只要双足机器人的底层运动控制足够稳定,对于VLN系统而言,其任务是一致的:根据当前的视觉感知和语言指令,输出机器人需要执行的线速度和角速度指令。据我所知,无论是轮式底盘还是足式机器人,其底层控制器通常都能接收这两个参数来完成最终的动作执行。

问:您亲身经历了VLA从默默无闻到如今成为显学的全过程。您如何看待当前产业界和学术界对VLA的空前热情?
吴琦:VLA的兴起本质上是产业实际需求与学术技术发展共同驱动的结果。从产业视角看,任何实际的落地场景都需要处理多模态输入(视觉、语言等),并依赖一个能够进行高层推理的智能模型来辅助完成复杂的规划与决策。人类大脑的工作机制就是最佳例证——通过整合视觉、听觉、触觉等多模态感知信息,经过中枢神经系统处理,最终生成具体的动作指令。这种整合与决策过程在日常场景中不可或缺。
从学术研究趋势看,自然语言处理与计算机视觉领域的许多核心任务(如图像分类、目标检测、机器翻译)已取得显著进展并趋于成熟,研究者们自然将目光投向了更具挑战性的前沿交叉方向。
需要强调的是,VLA领域的研究者需要精准定位应用场景,并深入理解语言在其中扮演的核心角色:它为机器人提供了一种更便捷、自然的人机交互方式。这种交互模式高度灵活,允许用户以随意的口语化方式下达指令,这同时也衍生出一系列全新的技术挑战——不同于传统预设任务的固定模式,VLA面临的任务往往具有显著的临时性和动态性,需要实时响应非预定义的、随时变化的需求。
VLN之于VLA:导航是具身行动的基石
问:您认为导航任务在VLA中的难点和核心重要性体现在哪里?应如何理解VLN与更广义的VLA之间的关系?
吴琦:单纯的基于地图或信标的视觉导航作为任务可能相对简单,但视觉语言导航的挑战则要大得多。
举一个生活化的例子:食物掉到了餐桌下面,你命令现有的扫地机器人去清理。目前的解决方案要么是启动全屋清扫模式,要么手动把机器人搬到餐桌附近让它转圈清扫,或者更智能一些的,能在手机APP上手动划定餐桌区域进行定点清扫。而VLN能够实现的是:你只需下达一个“去餐桌附近清理食物”的自然语言指令,机器人就能利用这个信息,先自主导航到厨房餐桌的位置,再使用视觉传感器找到食物残渣的具体地点,最终只清理那一小块区域。相比过去依赖预设或手动干预的导航方法,VLN更擅长处理这类临时性、突发性的复杂事件。我们最近在扫地机器人平台上已经基本实现了这些功能。
当然,VLA中的“动作”包含很多种类,VLN只是其中一个重要的子集,需要根据具体场景具体分析。有些场景可能并不需要复杂的VLN,比如在工厂、仓库等高度结构化的固定场景下执行分拣或货架盘点任务,机器人往往只需要按照预设的固定轨迹运动即可。
但是,未来如果进入家庭等非结构化、动态的实际应用场景,机器人需要不断移动以适应变化的环境,这时导航问题就变得异常棘手。我和北京大学的王鹤老师也讨论过,室内场景存在诸多挑战,除了环境建模本身的不准确性,还有人员移动、宠物活动、家具位置变动等带来的动态干扰。
问:人员移动或交互这类高度动态的场景,对VLN最大的挑战或技术难点在哪里?目前学术界有哪些可行的探索方向?
吴琦:动态场景带来的最直接影响,就是之前基于SLAM(同步定位与建图)的静态地图导航方式不再完全适用。提前利用静态地图信息规划好的最优导航路线,很可能因为动态障碍物(如行走的人、临时放置的椅子)的出现而失效。
这个时候就需要VLN这类技术的辅助。其核心思想是利用当前的实时视觉信息以及最初的语言指令,做出短程的导航路径规划,甚至只预测下一步该往哪个方向走。到达下一个位置后,再结合新的感知信息做出新的决策,实现一种“边看边走”的在线规划模式。我们最近也提出了一个新的数据集叫“Obstructed VLN”,专门研究在预设路径被临时遮挡时,机器人如何做出实时调整和重新规划的问题。
问:之前林倞老师团队发表的综述也将VLN列为具身智能的一大关键任务。VLN发展至今已七年,除了开山之作,您认为哪些工作是该领域发展的关键节点?
吴琦:很荣幸我们实验室主导并参与了VLN领域多个关键节点的工作。在提出R2R、RxR、REVERIE这三个基准数据集后,我们相继采用CNN、RNN及注意力机制等方法展开深入研究。
Transformer架构诞生后,我们率先基于该架构提出了“VLN-BERT”,探索用Transformer统一建模VLN任务。2022年CVPR上发表的“Discrete-Continuous-VLN”则首次尝试弥合VLN在离散仿真环境与连续真实环境之间的学习与评估鸿沟。去年推出的NavGPT是首个将大语言模型引入VLN任务的工作。而今年ICRA上的Open-Nav,则首次实现了VLN在真实机器人平台上的大规模落地应用验证。
其他顶尖研究组也做出了许多关键贡献。例如早期Hao Tan在NAACL上提出的EnvDrop,以及Chen Shizhe提出的多个重要模型,比如现在常被用作基准模型的DUET。我们目前保持SOTA的模型ScalVLN也是基于DUET的工作改进的。值得一提的是,Shizhe也曾在我们V3A实验室访问过,是一位非常优秀的研究者。
问:当前具身智能领域对操作任务(如抓取、操纵)热情高涨,但您似乎更持续地关注具身导航?这背后的考量是什么?
吴琦:这可能主要还是出于技术落地导向的考虑。目前很多已落地的场景是工业场景或商业理货场景,大部分时候机器人可以按照预先编程的固定路径,在相对固定的场景中移动。而家用服务机器人场景的落地目前还比较困难,所以很多人尚未充分体会到室内视觉导航在动态家庭环境中的真正挑战。
许多人认为导航问题已经完全解决,室内导航只需建好高精度地图就能让机器人指哪到哪,不像操作任务那么复杂。但事实上,如果将其放在具身智能的完整框架下审视,在复杂、非结构化的室内环境中实现鲁棒、高效的导航,仍需要相当长的时间来攻克。毕竟,机器人只有先安全、准确地移动到正确的位置,才能执行后续的抓取、操作等动作。
如果认为具身行动只与上半身的抓取或操作有关,那可能并没有真正思考清楚什么是具身智能。关于具身智能的众多定义中,我最认同CVPR 2024一场专题讨论中提出的观点:一个真正的具身AI智能体需要具备看、听、说、行动和推理这五项基本能力,并且能够将在模拟环境中学习的解决方案,有效地迁移到真实的机器人和现实世界中。
也就是说,只有把视觉感知、语言理解能力和具体的执行任务(无论是移动导航还是机械臂操作)最终在真实机器人上实现闭环,才能称得上是一项真正的具身智能研究。
问:这与自动驾驶中的导航有哪些本质不同?
吴琦:自动驾驶的导航属于室外导航,可以利用大量现成的、高精度的先验信息,比如GPS提供全球定位,再结合高精度矢量地图、视觉感知(车道线识别、交通标志检测)以及激光雷达/毫米波雷达系统(实现障碍物检测与规避)。
而我们研究的VLN主要是室内导航,面临诸多限制。由于缺乏GPS信号,且环境信息(如地标、纹理)相对稀疏和重复,无法直接套用室外的成熟方案。早期技术主要依赖视觉SLAM实现环境建图与定位,通过摄像头实时采集数据构建局部地图。但这种方案对环境依赖性很强,常常需要人工预处理(如标记特征点、优化场景纹理)来提升建图精度,难以实现完全自动化。
最大的难点在于数据收集,尤其是大量的、多样化的室内3D环境数据。我们希望获取尽可能真实的3D环境用于训练和仿真,但这类数据本身就非常稀缺,也没有一个特别理想的、通用的室内仿真器。而扫地机器人等设备采集的真实家庭数据又涉及严重的用户隐私问题。我们因此也曾涉足室内设计相关的研究,与装修设计平台酷家乐合作,基于视觉和语言进行装修风格生成。他们所提供的海量3D室内场景数据对我们的研究非常有帮助。
问:室内环境虽然不受天气影响,但也可能在低光照、烟雾等极端感知条件下导致视觉输入失效。是否需要考虑为VLN引入多模态备份方案(如超声波雷达、红外传感)?如何实现多模态传感器信号与语言指令的实时对齐与融合?
吴琦:确实,随着仿真器变得越来越逼真,我们可以模拟出这些复杂情景,也可以考虑引入其他传感器来辅助导航,提升系统的鲁棒性。在这方面,或许可以参考自动驾驶领域的一些成熟解决方案,来实现多模态信息的对齐、融合与互补处理。
卡脖子的数据也最易突破
问:在VLN和VLA领域,您认为当前最亟待解决的三大研究问题或技术瓶颈是什么?
吴琦:目前面临的核心挑战首推数据问题。当前缺乏足够优质、大规模、多样化的数据集来支撑VLN或VLA模型的训练,这与GPT所依赖的互联网海量文本语料形成鲜明对比。具体而言,数据问题可以拆解为三个部分:
第一是高性能物理仿真器的必要性。在与机器人技术结合的场景中,仿真器是进行安全、高效、低成本训练和测试的基础平台,其逼真度和物理准确性直接影响生成数据的质量。这里有很多复杂的物理因素需要考虑,比如材质摩擦力、摩擦系数、环境重力,甚至是热交互等物理特性。我们熟知的物理定律在目前的仿真器中体现得还不够充分。要构建真正的“世界模型”,数字孪生不能只停留在表面几何和纹理,还必须涵盖其内在的物理特性。
第二是高质量3D环境构建的稀缺性。仅有仿真器引擎还不够,还需要在其中构建多样化、高保真的虚拟场景(如不同风格的家庭、工厂、购物中心等)。这类高质量的3D环境不仅稀缺,制作成本也非常高昂。
第三是专用应用数据的独特性。与传统AI数据(如NLP的纯文本、CV的带标签图像)不同,VLA/VLN需要特定任务的动作序列数据(如抓取、操作、导航等)。其数据格式必须整合仿真器、3D环境以及具体应用任务三类要素,缺一不可。因此,构建大规模、复合型、任务驱动的数据集是VLA/VLN发展的关键方向。
第二个挑战是“仿真到现实”(Sim2Real)的迁移鸿沟。模型在仿真器中高效训练后,最终需要部署到真实的机器人和物理环境中。但二者之间存在多重差距,包括环境差异(如光照、纹理、物体物理属性)和机器人硬件差异(如执行器精度、传感器噪声)。如何弥合这些差距是技术能否成功落地的核心难点。
第三个挑战与工程部署相关。VLA/VLN任务涉及复杂的多模态推理和大型模型计算(例如将视觉导航模块与GPT等大语言模型结合),通常依赖高性能GPU。如何在资源受限的机器人终端实现高效的模型压缩、蒸馏或轻量化部署,平衡算力需求与设备的功耗、成本,是亟待突破的工程瓶颈。
问:在这些瓶颈中,哪一个最有可能率先取得突破?
吴琦:虽然数据是最大的难题,但它其实也是最容易取得突破的环节,尤其是围绕如何构建更好的数据集、仿真器和虚拟环境,并利用它们训练出更强大的VLA模型。
比如我最近在思考利用生成式AI进行环境生成的工作。之前与酷家乐的合作,就是通过输入语言描述来生成三维房间环境,包括房间布局、家具摆放、墙壁颜色、地板材质等。但由于当时模型能力有限,生成效果比较一般。现在,随着多模态大模型和3D生成技术的进步,或许可以重新审视并高效实现这个想法。输入可以是多种模态的,比如对环境的语言描述、现有环境的图片、视频或结构信息。我们希望模型能按照用户需求,快速生成一个精准、符合要求的高保真虚拟环境,再将这个环境导入到“桃源”或NVIDIA Isaac Sim等高级仿真器中,供整个社区进行训练和评估。
问:针对最关键的数据问题,目前学术界和工业界主要有哪几种主流的技术路径?
吴琦:数据构建主要存在三种技术路径。
第一是真人操控采集。通过人工远程或本地控制机器人完成行走、抓取、家具组装等任务,同步记录动作轨迹、传感器数据与环境交互信息,直接用于模型训练。这种方式依赖真实场景操作,数据贴合实际应用,信噪比高,但采集成本极高,难以规模化。
第二是仿真到现实生成。借助高逼真度的物理仿真器(如NVIDIA Isaac Sim、上海人工智能实验室的“桃源”系统)构建虚拟环境,通过算法自动生成机器人执行各类任务的海量数据。这种路径的优势在于能够低成本、大批量、自动化地生产数据——无需真实硬件介入,即可在模拟环境中完成百万次级别的试错训练,训练后的模型经过适当调整可直接部署到真实机器人。
第三是视频数据驱动。聚焦于互联网上的海量公开视频(如第一人称导航、烹饪教学、维修教程等场景),通过视频分析技术提取其中的高层决策逻辑(如任务规划、动作序列)来训练模型。这种路径规避了传统机器人数据采集的繁琐过程,仅关注“做什么”的高层规划,而无需处理机器人“如何执行”的底层控制细节,但如何从被动观察的视频中有效学习可执行的策略仍是一个挑战。
问:您很早就开始进行VLA相关的仿真研究。在您看来,这些年来仿真技术最大的进展是什么?当前最亟待突破的卡点又是什么?
吴琦:确实,当时我们在设计和发布VLN任务时,就为Matterport3D(MP3D)数据集构建了一个配套的MP3D仿真器。但这个仿真器仅仅是为MP3D环境数据和VLN任务服务的,功能相对简单,主要提供基本的场景渲染和导航交互。
随着具身智能的发展,大家越来越关注仿真器的逼真度和物理准确性,从早期Meta发布的Habitat 1.0、2.0,到最近的NVIDIA Isaac Sim。我认为仿真器最好由拥有强大工程能力和资源的大厂来主导开发,因为它更多是一个需要长期投入的工程化系统问题。
对于现代仿真器,我认为有三个方面的特性至关重要:一是场景仿真,即场景看起来要非常真实。这涉及到实时渲染、光线追踪、高精度建模、材质纹理等计算机图形学技术。二是物理仿真,要能够高精度模拟现实世界的物理现象,比如重力、摩擦力、碰撞、形变、流体等。第三,仿真器必须高效,不能因为运行速度慢而拖慢模型训练,尤其是在结合强化学习进行训练时,需要与仿真器进行每秒上万次的频繁交互,其运行效率和并行化能力至关重要。
问:那么,有哪些潜在的方法或思路可以解决Sim2Real鸿沟和工程部署这两大难题呢?
吴琦:如果我们普遍相信AI领域的“规模定律”(Scaling Law)的话,那么解决仿真到现实的鸿沟,本质上就是解决数据规模和质量的问题。
想象一下,如果我们拥有一个非常庞大的、覆盖各种长尾场景的虚拟环境数据集,并且这些场景的视觉外观和物理特性都足够真实,能够导入到高性能仿真器中供我们训练一个足够大的模型,那么我认为是有可能显著缩小这种差距的。我们目前就在与酷家乐合作,利用他们之前积累的大量3D模型资产,通过程序化生成技术,批量生成这类多样化的环境数据。
说到部署,我认为机器人本体公司或核心硬件供应商可以发挥更重要的作用,提供相对易用、标准化的部署工具链和优化套件。这是一个生态问题。英伟达在AI计算领域的成功,关键在于构建了从硬件(GPU)、软件(CUDA)到开发框架(各种SDK)的完整生态,推动了整个行业的发展。机器人硬件公司也应该具备这样的前瞻性,提供好的开发工具,建立开放的软件生态,其硬件才能被更广泛地采用,从而形成良性循环。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

爱彼迎CEO切斯基谈AI时代管理变革:仅管人者将被淘汰
近期,科技行业围绕一个议题展开了广泛讨论:在人工智能浪潮的冲击下,那些仅专注于“人员管理”的管理者,其角色是否正面临挑战? 爱彼迎(Airbnb)首席执行官布莱恩·切斯基近期公开分享了他的见解。他指出,未来,那些仅仅负责人员协调、频繁召开周期性一对一会议的管理者,其生存空间可能受到挤压。“我不认为这

AI生成《黑神话:潘金莲》游戏角色美图 性感风格引热议
当GPT-Image-2这一先进的AI图像生成模型正式发布时,其卓越的视觉创作能力迅速在游戏玩家与开发者社群中成为热议焦点。很快,富有探索精神的创作者们便开始测试其潜力——知名游戏内容创作者op7418率先行动,运用该工具生成了一套以中国古典文学名著《金瓶梅》为故事蓝本的ARPG开放世界游戏概念设定

30万只羊驼数据泄露面临隐私安全风险
Ollama作为一款开源大语言模型本地部署工具,有效解决了数据隐私与成本控制的核心痛点,正成为众多企业与开发者构建AI基础设施的首选方案。然而,其“开箱即用、默认开放”的设计理念,若缺乏相应的安全加固,反而可能将系统暴露于风险之中。 近期,一个被命名为“流血的羊驼”(Bleeding Llama)的

AI模型代码能力排名 Claude表现突出
最近技术群里挺热闹,程序员们又在为哪个AI模型更好用争得面红耳赤。今天,咱们就从写代码、搞前后端开发的实战视角出发,给这些主流模型排个队,看看谁是真“夯”,谁是真“拉”。 评判标准很简单:只看它能不能帮你把活儿干好。下文的分析,综合了个人及身边同事、朋友在真实项目中的使用体验,旨在提供一个务实的参考

2026年AI智能体预算危机真相:企业如何应对三个月耗尽一年成本的挑战
随着推理型模型的崛起,AI正从聊天工具进化为能执行任务的“智能体”,并快速嵌入企业核心流程。真正的竞争不在模型,而在“线束”——即如何为AI配置数据、工具与边界。 引言 具备推理能力的模型,比如OpenAI的o1系列,正推动AI经历一场历史性跨越:从“聊天机器人”转向“行动智能体”。时间来到2026








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
