




GPT-5.5参数规模真相:10T传闻不实,实际仅1.5T

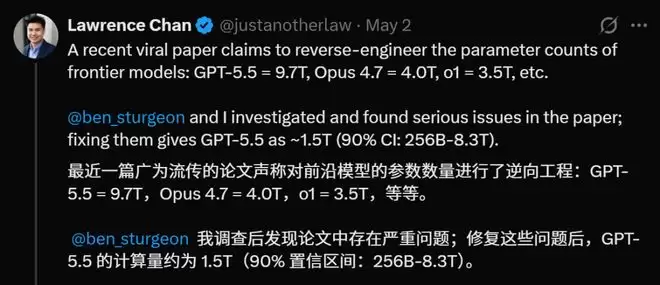
五一假期前夕,AI领域被一则重磅消息引爆:一篇最新论文声称,通过一种创新的“黑盒探测方法”,成功推算出GPT-5.5可能拥有接近10万亿参数的惊人规模。这一数字迅速在技术社区引发热议,因为它比外界普遍推测的GPT-4参数量高出数倍。然而,热度尚未消退,剧情便迎来了反转。

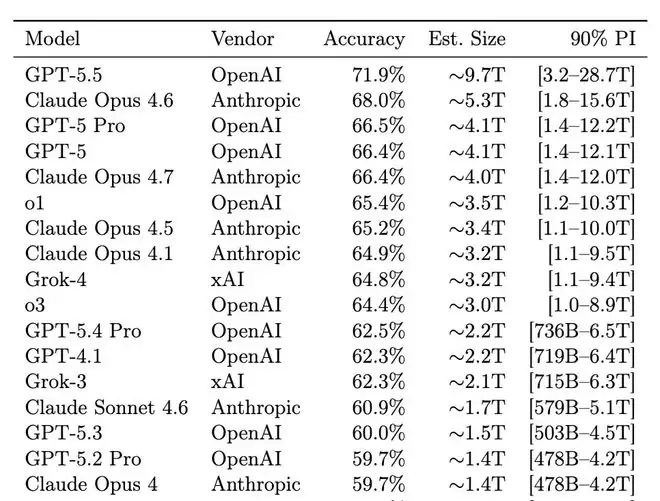
这篇题为《不可压缩知识探针》的论文,由Pine AI首席科学家李博杰发布在预印本平台arXiv上。其公布的估算结果极具冲击力:
- GPT-5.5:9.7万亿参数
- Claude Opus 4.7:4.0万亿参数
- o1:3.5万亿参数

很快,来自加州大学伯克利分校CHAI实验室的Lawrence Chan与英国AISI的研究员Ben Sturgeon对这项研究进行了深入审查。他们发现,论文中存在一些关键的方法论与代码实现偏差。
逻辑的漏洞:从10万亿到1.5万亿的估算缩水内幕
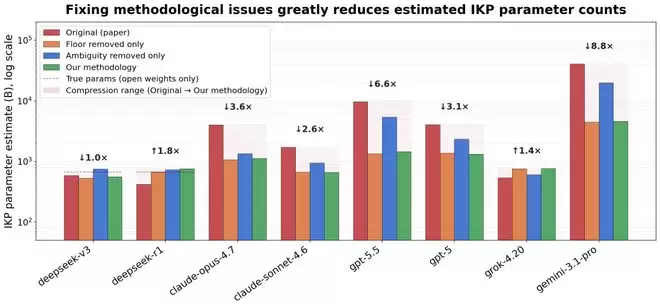
在修正了这些问题后,结论发生了戏剧性变化。最受瞩目的GPT-5.5,其参数估算值从9.7万亿急剧下降至约1.5万亿,并且90%置信区间变得异常宽泛(从2560亿到8.3万亿)。
问题究竟出在哪里?主要集中在以下两个核心环节。
被修饰的拟合曲线
论文作者声称未对模型得分进行“保底处理”,但复现者发现,在计算小型模型得分时,负分被悄然归零了。这一点至关重要:当模型面对完全未知的冷僻知识时,若进行随机猜测,得分很可能为负。移除这一“归零”操作后,小模型的得分显著降低,导致原本陡峭的“得分-参数”拟合曲线趋于平缓,最终使得对大语言模型的参数估算严重高估。

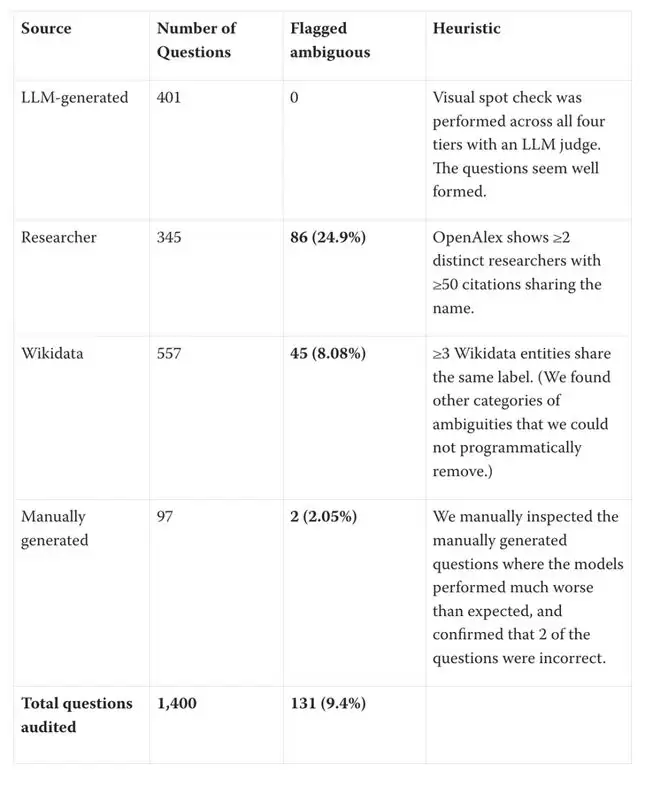
“人工智障”出题:25%的题目本身存在错误
另一个硬伤在于测试数据集的质量。研究者指出,用于探测模型知识容量的那套“冷知识题库”本身质量堪忧。大约四分之一的题目存在歧义(例如研究员姓名重复问题),甚至部分标准答案本身就是错误的。使用这样的数据集来衡量大型语言模型的“知识储备”,其可靠性与准确性自然大打折扣。
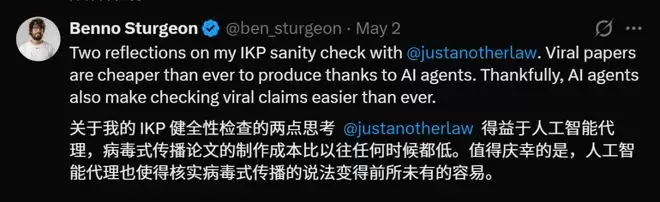
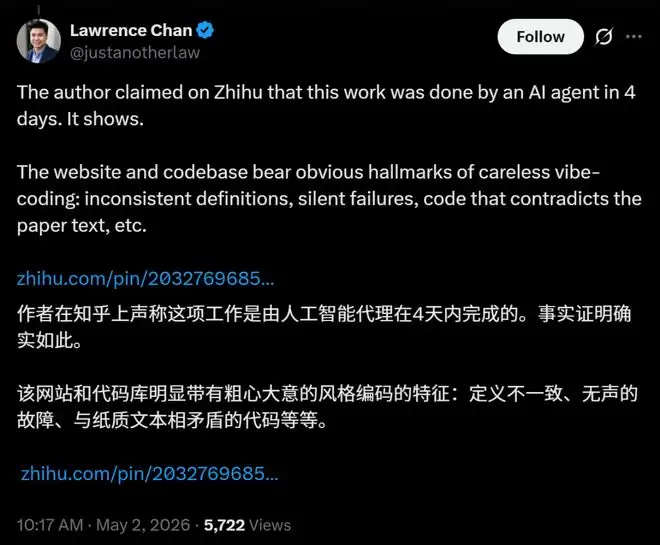
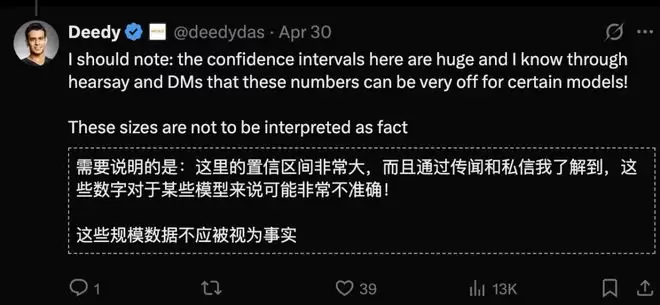
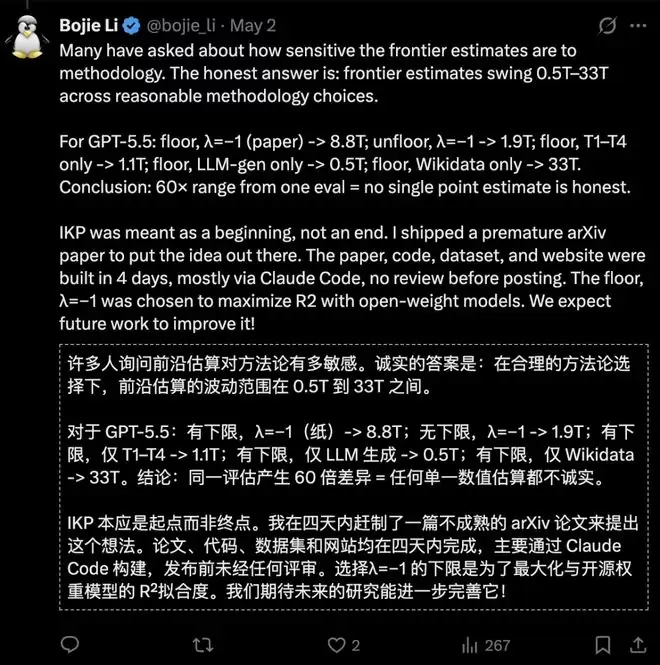
更具戏剧性的是,论文作者李博杰后来坦言,这项研究是在AI智能体的辅助下,仅用4天时间完成的早期探索。这种开发模式被Lawrence Chan戏称为“充满槽点的Vibe-coding”。

核心理论依然坚挺
尽管具体数值遭遇“打假”,但这项研究提出的核心思想——不可压缩知识探针理论——依然获得了学术界的认可。这或许是整个事件中最有价值的收获。

简而言之,IKP理论认为,大语言模型的能力可以拆解为两个部分:
- 程序性能力(如逻辑推理、代码生成):这部分是“可压缩”的。通过模型架构和训练算法的优化,参数量更小的模型完全可能具备更强的推理能力。
- 事实性知识(如历史日期、冷门概念):这部分是“不可压缩”的。你可以将模型视为一个存储设备,记忆一个事实就需要占用一定的“存储空间”。知道就是知道,不知道就是不知道,很难通过压缩或纯粹推理获得。
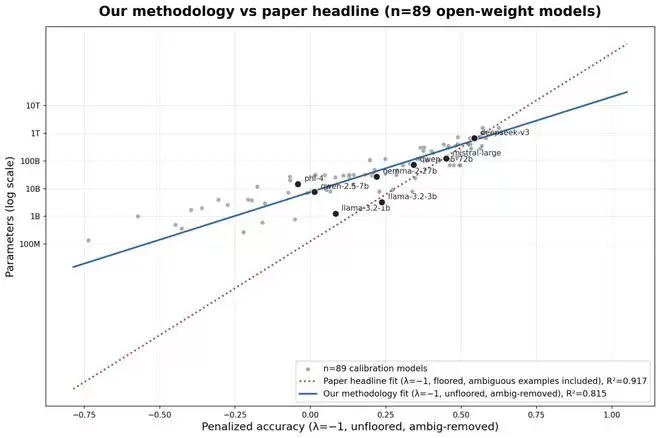
因此,通过测试模型掌握了多少这类“不可压缩”的冷知识,来反推其参数规模,这个方法论的方向本身是成立的。修正偏差后,基于IKP的估算虽然数值变化巨大,但不同模型之间的相对“知识容量”排名依然具有参考意义。
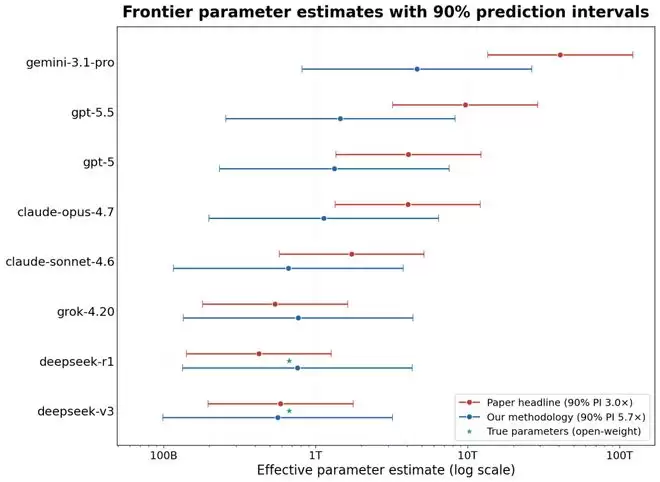
修正后的估算结果显示:
- GPT-5.5:从9.7万亿降至约1.5万亿
- Claude Opus 4.7:从4.0万亿降至约1.1万亿
- DeepSeek R1(实际大小6710亿):从4240亿修正至约7600亿

谁才是真正的“知识之王”?
抛开具体的数字争议,这次探测依然揭示了一些关于大模型能力的深刻洞见。
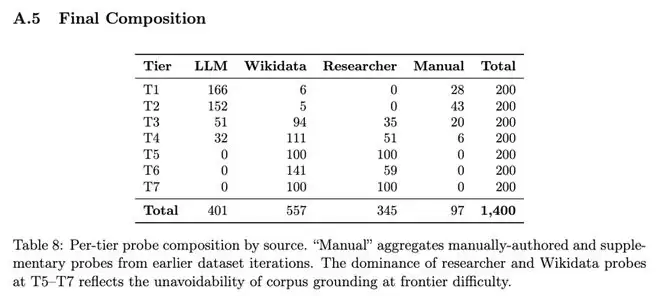
梯队格局: GPT-5.5在超冷门知识(T6级别)的测试表现上依然遥遥领先,稳居第一梯队。Claude Opus 4.7、o1、Grok-4等模型则构成了竞争激烈的第二梯队,其有效知识容量非常接近。
MoE模型的秘密: 研究证实,对于混合专家模型而言,其知识总量取决于模型的总参数量,而非每次推理时激活的参数量。这意味着,若要构建一个知识渊博的AI模型,增加参数总量仍然是无法绕开的硬性条件。
“思考模式”的玄学: 测试还表明,开启“思维链”模式并不能显著增加模型的知识储备。这再次印证了一个直观的道理:深度思考能帮助模型更好地组织和运用已知信息,但无法凭空生成它从未学习过的知识。
Lawrence Chan在总结中略带调侃地指出,这项工作的粗糙风格,确实符合“AI智能体四天速成”项目的典型特征。
Scaling Law失效了吗?
这场“参数神话”的破灭,与其说是一次失败,不如说是一次有益的行业纠偏。它提醒我们:盲目崇拜参数规模的时代正在成为过去。
GPT-5.5的估算参数从10万亿“缩水”到1.5万亿,绝不意味着它能力变弱。恰恰相反,这可能暗示着OpenAI在训练数据质量、模型训练效率和神经网络架构优化上取得了更惊人的突破,能够以更少的参数实现更强大的综合性能。
正如研究者所言,GPT-5.5的确切参数规模我们依然无法确定。但IKP这种方法,为我们窥探那些如同“黑箱”的巨型语言模型的内部结构,开辟了一条新的、颇具潜力的技术路径。它启示我们,在通往通用人工智能的道路上,我们追求的或许不再是单纯的“更大的存储硬盘”,而是“更高效、更智能的数据索引与处理范式”。
原论文作者李博杰也对此保持了开放态度,他承认早期估算存在很大不确定性,并直言“任何单一的点估计都不够诚实”。他将IKP视为一个有价值的研究起点,而非终点,期待后续工作能将其进一步完善。



游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Perplexity Pro订阅用户切换Claude 3.5模型使用指南
作为Perplexity Pro订阅用户,却无法在界面中找到Claude 3 5模型?这通常是由于账户权限同步延迟、浏览器本地缓存未更新或平台临时路由策略调整所致。无需担心,问题通常可以快速解决。本文将为您详细解析五种行之有效的方法,总有一种能帮助您顺利启用Claude 3 5 Sonnet或Hai

Claude 3 Opus隐私优势解析与零样本训练表现对比
对于Perplexity Pro用户而言,若您格外重视数据隐私与模型在全新任务上的直接应用能力,那么深入理解其集成的Claude 3 Opus模型至关重要。该模型在数据处理逻辑与推理架构上具备独特优势,本文将为您详细解析其核心机制。 一、Perplexity Pro 中 Claude 3 Opus

中国科学院瞬悉2.0类脑大模型发布 突破长序列与低耗部署瓶颈
人工智能领域的长文本处理竞赛正进入白热化阶段。无论是深度解析代码仓库、构建智能体的长期记忆,还是处理复杂的多模态交互,都迫切需要模型能够高效处理数十万乃至上百万token的超长序列。 然而,一个根本性的技术瓶颈也随之凸显:基于传统Transformer架构的模型,其推理时的计算复杂度和显存消耗会随着

2026青岛国际车展盛大开幕 千款绿色智能车型引领出行新风尚
4月29日,青岛国际会展中心(崂山馆)人潮涌动,备受瞩目的2026第二十五届青岛国际汽车工业展览会在此盛大启幕。作为山东地区规格最高、参展品牌最全的国际性车展,本届展会以“向上而行,领创未来”为核心主题,吸引了全球88家主流汽车制造商参展,近千款热门与新款车型集中亮相,全面展示了汽车产业的最新科技成

通义万相AI生成桌游素材教程与实用技巧
想用通义万相高效产出专业级桌游美术素材,却总被角色失调、场景混乱或风格不统一困扰?这通常是因为未掌握AI生成桌游图像的核心逻辑。桌游素材不同于普通插画,它更强调主体的高识别度、明确的功能性以及系列作品的视觉统一。下面这套经过实战验证的五步工作流,将系统性地解决这些痛点,帮助你稳定生成可直接投入设计流








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
