




DeepSeek多模态技术范式解析视觉原语思考方式

五一假期前夕,AI领域再次迎来突破性进展。DeepSeek正式在GitHub开源了其多模态大模型,并同步发布了详细的技术报告,揭示了其在视觉推理领域的创新方法论。

实际上,在官方正式发布前,已有部分用户在网页端和App上提前体验到了这项能力。随着技术报告的公开,一种开创性的多模态推理范式正式亮相,为解决视觉语言模型的核心难题提供了全新思路。
这篇题为《Thinking with Visual Primitives》(以视觉原语思考)的论文,直指当前多模态大模型的关键瓶颈:模型或许具备视觉感知能力,但在复杂推理任务中往往难以保持精确的思维连贯性。

举例来说,当模型面对一张人群密集的照片被询问“图中有多少人”时,它很可能出现计数错误。或者,当分析一张复杂的电路图并回答“左侧红色电容位于右侧电感的哪一侧”时,模型的回答常常模糊不清甚至自相矛盾。问题的根源何在?这不仅仅是视觉识别精度不足,更本质的是模型在构建语言推理链时,难以将抽象描述精准锚定到具体的视觉对象上。
DeepSeek将这一挑战定义为“指代鸿沟”(Reference Gap),并提出了一套系统性的解决方案。
背景:视觉感知与空间推理的本质差异
要理解这一鸿沟,可以设想这样一个场景:你正通过电话向朋友描述电脑屏幕上的一盘复杂棋局。你说“左边那个棋子要吃掉中间偏右的那个棋子”,电话另一端的人很可能感到困惑,因为他无法确定你具体指的是哪两颗棋子。
这正是当前多模态大模型在视觉推理中面临的困境。它们使用自然语言构建“思维链”,但自然语言本身具有固有的模糊性。“左侧较大的物体”、“靠近中央的红色区域”这类描述,在信息密集的视觉场景中难以实现精确定位。模型的注意力在推理过程中容易发生“漂移”,导致逻辑混乱和最终结论错误。
此前,学术界的主流研究方向集中在提升模型的“视觉感知能力”,例如采用高分辨率切分、动态分块等技术来弥补“感知鸿沟”。然而,这篇论文指出,即使感知能力再强,也无法替代精确的“空间指代能力”。“看到物体”和“能清晰说明正在观察哪个物体”本质上是两个不同层次的问题。
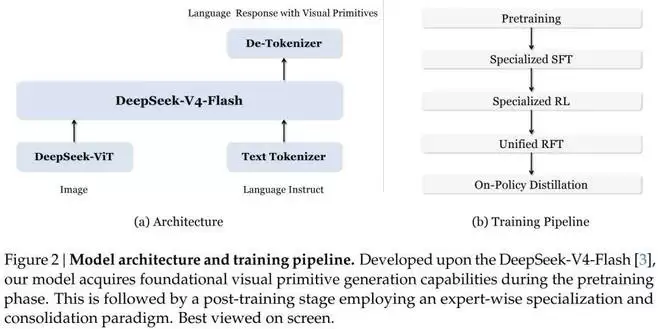
架构基础:基于V4-Flash的强大语言模型
这项研究以DeepSeek最新发布的V4-Flash模型作为语言主干。这是一个总参数量达284B、推理时激活13B参数的混合专家模型。视觉编码部分采用了自研的ViT架构,支持任意分辨率的图像输入,为多模态处理提供了灵活的基础。
团队的核心贡献在于提出了一套创新的“训练哲学”:如何用极少的视觉token,教会模型在推理过程中精确地指代视觉对象,实现从“看到”到“想清楚”的跨越。
核心创新一:将空间坐标转化为思维单元
这项研究最核心的思路可以概括为:将点坐标和边界框(Bounding Box)提升为推理的基本单位,让它们像文字一样自然地融入模型的思维链中。
传统方法中,边界框通常是推理结束后的输出结果。模型先完成思考,再告诉你“目标位于图片左上角坐标[100,200,300,400]”。这更像是一种事后标注,而非思考过程的一部分。
DeepSeek采用了截然不同的方法。模型在推理的每一步,只要提及一个视觉对象,就会同步输出其坐标信息。例如,在分析一张图片时,模型的内部推理过程会呈现为:
「扫描图片寻找熊,找到一只 <|ref|> 熊 <|/ref|><|box|>[[452,23,804,411]]<|/box|>,它正在爬树,不在地面上,排除。再往左下看,找到另一只 <|ref|> 熊 <|/ref|><|box|>[[50,447,647,771]]<|/box|>,站在岩石边缘,符合条件。」
这类似于人类在清点物品时会用手指逐一点过去。坐标不再是最终的答案,而是推理过程中用于消除歧义的“空间锚点”。模型的逻辑链被牢牢地固定在图像的物理坐标上,有效避免了注意力漂移问题。
这套机制包含两种“视觉原语”:边界框用于需要精确定位和尺寸信息的对象;点坐标则用于更抽象的空间指代,比如描绘迷宫探索轨迹或追踪曲线路径。
核心创新二:7056倍的视觉信息压缩
另一项令人印象深刻的技术创新体现在架构层面的极致压缩上。
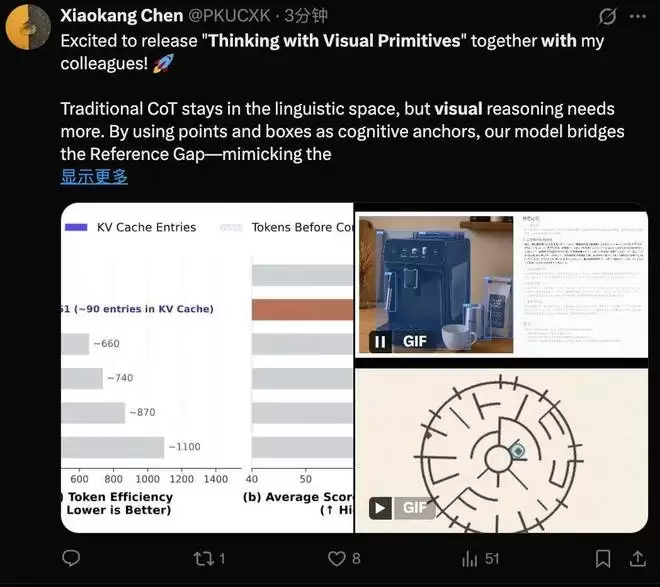
对于一张756×756像素的图片,传统方案需要将大量视觉token输入语言模型。而DeepSeek的处理流程则高效得多:图片首先经过ViT处理,生成2916个图像块token;随后进行3×3的空间压缩,合并为324个token;最后,借助V4-Flash内置的“压缩稀疏注意力”机制,将KV缓存进一步压缩4倍,最终仅剩下81个视觉KV条目。
从原始像素到最终缓存条目,整体压缩比达到了惊人的7056倍。
这意味着,处理一张800×800的图片,该模型仅需约90个KV缓存条目。相比之下,Claude Sonnet 4.6需要约870个,Gemini-3-Flash则需要约1100个。论文的核心论点是:精确的空间指代能力,可以在相当程度上弥补视觉token数量的不足。模型未必需要“看更多细节”,但必须“指更准确位置”。
核心创新三:精心设计的冷启动训练数据
技术创新的第三个维度体现在训练数据的构建策略上。
团队首先爬取了近10万个与目标检测相关的数据集,经过语义和几何质量两轮严格筛选,最终保留了约3.17万个高质量数据源,并生成了超过4000万条训练样本。
在专项的“视觉原语思考”冷启动数据构建上,团队设计了四类核心任务:
第一类是计数任务,分为粗粒度(如图中有多少人)和细粒度(如穿蓝色衣服的有几人)。对于粗粒度计数,模型学习“批量锁定”策略,即一次性框出所有候选对象再统计;对于细粒度计数,则学习逐一扫描、核对属性的策略。这两种策略对应不同的认知负荷,分别进行针对性训练。

第二类是空间推理与视觉问答,大量利用GQA(自然场景)和CLEVR工具链(可控合成场景)生成多跳推理样本,迫使模型在每一步推理时都必须用边界框锁定所涉及的对象。

第三类是迷宫导航,共生成46万条样本。团队使用DFS、Prim和Kruskal算法生成了矩形、圆形、六边形三种拓扑结构的迷宫,并专门设计了“表面可解但实际无解”的迷宫来训练模型的鲁棒性。模型需要用点坐标记录每一步探索轨迹,回溯时也需用坐标标记已排除的路径。

第四类是路径追踪,共12.5万条样本。给定一张多条贝塞尔曲线相互交叉的图,要求模型追踪从指定起点到终点的曲线。关键挑战在于“交叉歧义消解”:当两条线交叉时,模型必须判断哪一条才是目标曲线的延续,而不能依赖颜色等取巧特征——团队专门设计了所有曲线颜色相同的测试版本以杜绝模型取巧。

训练流程:分阶段专业化与统一化策略
在后训练阶段,团队采用了“先专家化,后统一”的分阶段策略。
第一步,分别使用边界框数据和点坐标数据训练两个专家模型,避免两种模态在数据量不足时相互干扰。
第二步,对两个专家模型分别进行强化学习,采用GRPO算法。奖励函数设计得非常精细:格式奖励(输出格式是否正确)、质量奖励(由LLM评判思考内容与答案是否一致)、精度奖励(任务特定)三路并行。例如,计数任务采用平滑指数衰减奖励而非简单的对错二值奖励;迷宫任务的奖励则分解为因果探索进度、探索完整性、穿墙惩罚、路径有效性、答案正确性五个子项。这一切都是为了给模型提供密集且信息丰富的学习信号。
第三步,利用两个专家模型产生的数据,对统一模型进行强化微调。为了获得更好的起点,团队甚至从预训练模型重新初始化开始训练。
第四步,采用“在线策略蒸馏”技术,弥合统一模型与专家模型之间的性能差距——让学生模型自己生成推理轨迹,然后最小化其输出分布与专家分布之间的KL散度。
实验结果:在最具挑战性的任务上实现显著超越
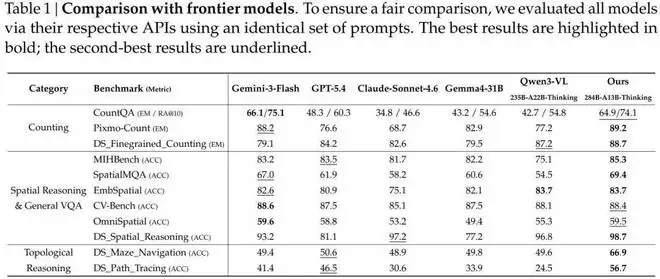
论文在11个基准测试上进行了全面评测,对比模型包括Gemini-3-Flash、GPT-5.4、Claude Sonnet 4.6、Gemma4-31B、Qwen3-VL-235B等主流多模态大模型。
关键结果如下:
在计数任务上,该模型在Pixmo-Count(精确匹配)上得分89.2%,超过Gemini-3-Flash的88.2%,并大幅领先GPT-5.4的76.6%和Claude Sonnet 4.6的68.7%。在细粒度计数任务上,以88.7%的得分超过Qwen3-VL的87.2%,位居第一。
在空间推理的多个基准上,整体表现与头部模型持平或略有超越,在MIHBench和SpatialMQA上均排名第一。
最具代表性的差距出现在拓扑推理任务上。在迷宫导航任务中,该模型得分66.9%,而GPT-5.4为50.6%,Gemini-3-Flash为49.4%,Claude Sonnet 4.6为48.9%——所有前沿模型都只能答对一半左右,而该模型将性能提升了约17个百分点。在路径追踪任务中,该模型以56.7%的得分,领先于GPT-5.4的46.5%和Gemini-3-Flash的41.4%,优势同样明显。
论文也诚实地指出:“所有前沿模型在拓扑推理任务上均表现欠佳,说明多模态大模型的推理能力仍有相当大的提升空间。”
以下是论文展示的几个定性分析示例:



当前局限与未来发展方向
论文并未回避当前模型的几个已知局限性。
首先,模型需要明确的“触发词”才会启用视觉原语机制,尚不能自主判断何时该使用这种“用手指点”的思考方式。其次,受输入分辨率限制,在极细粒度的视觉场景中,视觉原语的位置精度偶尔会不足。团队认为,与现有高分辨率感知方案结合是自然的下一步。最后,利用点坐标解决复杂拓扑推理问题,其跨场景的泛化能力目前仍然有限。
结语:重新定义多模态模型的思考方式
这篇论文的价值,远不止于在几个评测榜单上取得领先。
它提出的核心问题——“推理过程中语言指代的歧义性是多模态模型的根本瓶颈之一”——在此前并非学界的主流叙事。主流努力方向往往是更大的模型规模、更高的分辨率、更多的训练数据。
而这项研究开辟了另一条技术路径:未必需要让模型“看更多细节”,而是要让模型“指更准确位置”。用坐标代替模糊的语言描述,用空间锚点来稳定逻辑链,将视觉信息从被动的感知对象,转变为主动的思考工具。
从这个角度看,《Thinking with Visual Primitives》更像是在为多模态推理增添一种新的“思考范式”。这是一种人类在处理复杂视觉任务时本能就会使用,但AI此前一直缺失的能力:用手指点着思考,用空间坐标锚定逻辑。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Glean使命:提供改变世界的知识与工具
你是否曾感到困惑:在日常生活中,我们总能快速找到所需物品,各类工具也能轻松调用;然而一旦进入工作环境,想要定位一份文件、查询某个数据或回溯一段对话,却往往如同大海捞针,耗费大量时间与精力?这正是Glean创始团队洞察到的核心问题。这支由前谷歌搜索与Facebook工程师组成的团队,凭借深厚的技术积累

Mem.ai团队协作工具:高效组织工作与信息的智能助手
Mem,一个听起来就充满未来感的名字。它被定义为世界上首个由人工智能驱动的个性化工作空间。其核心承诺是:放大您的创造力,将那些日常琐事自动化处理,并让一切自动保持井井有条。 数据评估 从公开的访问数据来看,Mem ai的月均独立访客已达到5,136人次。对于关注网站流量与影响力的用户,可以参考主流数

文心智能体平台AgentBuilder使用指南与功能解析
在AI技术快速落地的今天,如何将大模型的潜力转化为实际的产品能力,是许多开发者和企业面临的关键问题。百度推出的文心智能体平台,正是为此而生。它基于强大的文心大模型,为不同背景的开发者提供了一个灵活、高效的智能体(Agent)构建与分发平台。 通过平台能做什么 这个平台的核心思路是“人人可AI”。它面

NAII人工智能计划使命:引领AI研发前沿,确保技术领先地位
欢迎访问AI gov,这里是美国国家人工智能倡议(NAII)的官方网站,也是您获取联邦政府为巩固其在人工智能领域全球领导地位所开展各项工作的核心信息门户。 该倡议的基石是《2020年国家人工智能倡议法案》。该法案于2021年1月1日正式生效,其核心在于要求联邦政府进行跨部门协调,通过加速人工智能的研

单页灵感:精选优质网站设计案例合集
在网页设计与开发领域,单页网站因其极致的聚焦性和流畅的线性浏览体验而备受青睐。作为该领域的标杆,One Page Love 是一个权威的全球单页网站灵感画廊与资源库,持续收录并展示顶尖的单页网站设计案例、优质模板及实用设计资源。 该平台自身的页面设计就是最佳范例:布局清晰直观,视觉风格现代优雅,确保








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
