




GPT之父破解哈萨比斯难题:知识止于1930年的AI模型如何应对

年初,DeepMind创始人德米斯·哈萨比斯提出了一个堪称“硬核”的AGI判定标准:一个训练数据截止到1911年的模型,能否自行推导出爱因斯坦在1915年提出的广义相对论?这听起来像是一个思想实验,但没想到,真有人动手去尝试了,而且牵头者之一,正是“GPT之父”亚历克·拉德福德。 最近,拉德福德与“
年初,DeepMind创始人德米斯·哈萨比斯提出了一个堪称“硬核”的AGI判定标准:一个训练数据截止到1911年的模型,能否自行推导出爱因斯坦在1915年提出的广义相对论?这听起来像是一个思想实验,但没想到,真有人动手去尝试了,而且牵头者之一,正是“GPT之父”亚历克·拉德福德。
最近,拉德福德与“神经常微分方程”提出者之一、陈天琦的导师大卫·杜文瑙,以及量化专家尼克·莱文,共同启动了一个有趣的项目。他们用1931年以前的全部英文数据,训练了一个130亿参数的模型,命名为“Talkie-1930”。这个模型被彻底切断了与现代知识的联系,成了一个纯粹的“时间胶囊”。

这为研究者提供了一个难得的“纯净”参照系。当你想测试一个AI模型究竟是真正理解了某种能力,还是仅仅在复述训练数据中的答案时,Talkie-1930理论上可以给出诚实的反馈。对于哈萨比斯提出的那个宏大问题,这无疑是一个绝佳的探索起点。
来自1930年的模型,有什么用?
Talkie的训练数据全部来自1931年以前的公共领域英文文本,包括书籍、报纸、期刊、专利和法律文书,总计2600亿个token。选择这个时间点,主要是因为在美国,此前出版的作品已进入公共领域,可以合法使用。
模型训练完成后,研究团队做了一件颇具玩味的事:他们开设了一个24小时直播频道,让Claude Sonnet 4.6全天候地与Talkie-1930聊天,探索这位“古人”的知识边界。对话记录完全公开,任何人都可以一探究竟。
当然,你也可以亲自去和它聊两句。从一些简单的测试来看,它的回答确实带着浓厚的时代印记。


不过,比具体表现更有意思的,是这项研究背后的深层动机。研究者提出了一个核心问题:一个只活在过去的模型,能在多大程度上“预感”到未来?
为了量化这一点,他们从《纽约时报》的“历史上的今天”栏目中提取了近5000条历史事件描述,然后测量这些描述对Talkie而言的“惊讶度”——用信息论的话说,就是每字节文本的困惑度。结果符合预期:对于1930年之前的事件,Talkie并不感到意外;而1930年之后的事件,其惊讶度曲线明显攀升,在五六十年代达到顶峰,之后趋于平缓。
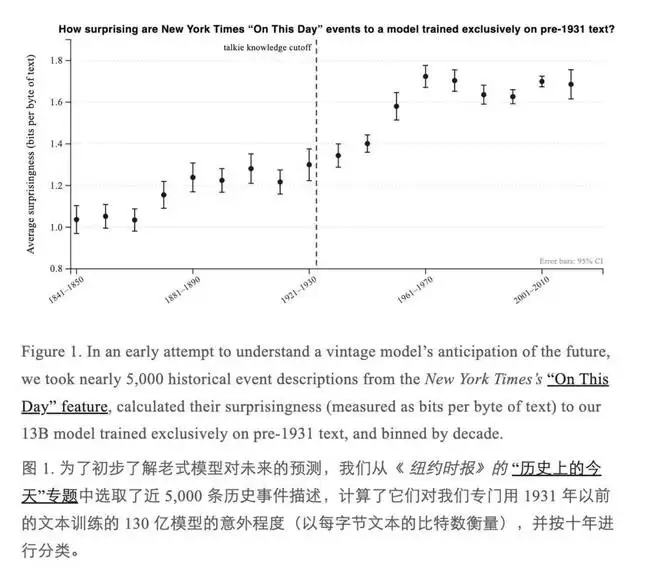
这套方法背后,隐藏着更宏大的设想。研究者们引用了哈萨比斯的问题,并列举了类似案例:西科斯基的直升机专利(1935年)、图灵关于可计算数的论文(1936年)、卡尔森的静电复印专利(1942年)——这些都是Talkie“理论上”无法知晓的知识。但如果模型足够庞大、理解足够深刻,它能否仅凭对已有知识的推演,自行触及这些未来的思想?这个问题目前尚无答案,但足以引发深思。
第二个动机,直指当前大模型评估的核心痛点:数据污染问题。
评估模型能力时,一个长期困扰研究者的难题是:你如何确定模型是真的“会”,而不是在训练数据里恰好见过这道题的答案?由于现代模型的训练数据规模过于庞大,这个问题几乎无解。
Talkie天然绕开了这个困境。它完全不知道Python是什么,也从未见过任何一行现代代码。于是,研究者用它进行了HumanEval标准编程测试。他们给Talkie随机展示几个Python函数作为示例,然后要求它编写一个新函数,并统计其在100次尝试中至少成功一次的比例。
结果是:Talkie确实能学。随着模型规模的扩大,它在这项任务上的表现会缓慢但稳定地提升。
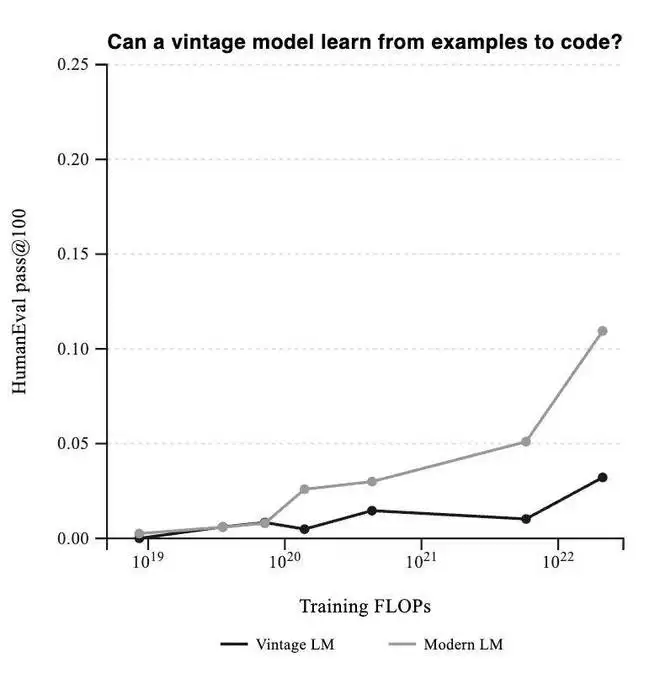
当然,与使用现代网页数据训练的同等规模模型相比,Talkie仍有巨大差距。而且,它答对的题目主要分两类:要么是极其简单的单行程序,要么是对示例程序进行小幅修改。研究者特别提到一个旋转密码解码函数的例子:示例给出了编码函数,Talkie似乎理解了“逆操作”的抽象概念,将加号改为减号,仅此一字之差,便得到了正确答案。这暗示模型可能具备某种程度的抽象理解,而非纯粹的模仿。

一个对数字计算机一无所知的模型,依然能从示例中摸索出编程的逻辑。这个发现让研究者觉得,这条路值得继续探索。
第三个动机,触及了当前大模型研究的一个根本性隐忧:数据多样性的缺失。
当今所有主流大模型,无论GPT、Claude还是Gemini,其训练数据最终都指向同一个源头:互联网。无论是直接爬取、知识蒸馏还是合成数据,本质上都是同一片信息海洋的产物。这就引出了一个严肃的问题:我们自以为在研究“语言模型的普遍规律”,但实际上,研究的会不会只是“训练在互联网数据上的模型”的特殊性质?这些模型在气质、能力和行为倾向上的相似性,究竟有多少源于人类语言与文化的共性,又有多少仅仅是因为“喝了同一口井里的水”?
Talkie提供了一个宝贵的对照组。通过比较它与现代模型的异同,研究者希望能剥离出哪些特征是语言模型的普遍属性,哪些是“互联网训练”带来的特有产物。
为了更直观地衡量Talkie的能力,研究者还专门训练了一个“现代孪生”模型——架构完全相同,只是将训练数据换成了现代网页数据集FineWeb。两个模型在语言理解、数字计算和知识掌握三个维度上进行了正面较量。
结果是Talkie全面落后。但研究者注意到了一个关键细节:测试集中有大量问题,对于一个只知道1930年以前世界的模型来说,本身就是“超纲”的——它没有理由知道那些事。当把这些题目过滤掉后,两个模型之间的差距大约缩小了一半。
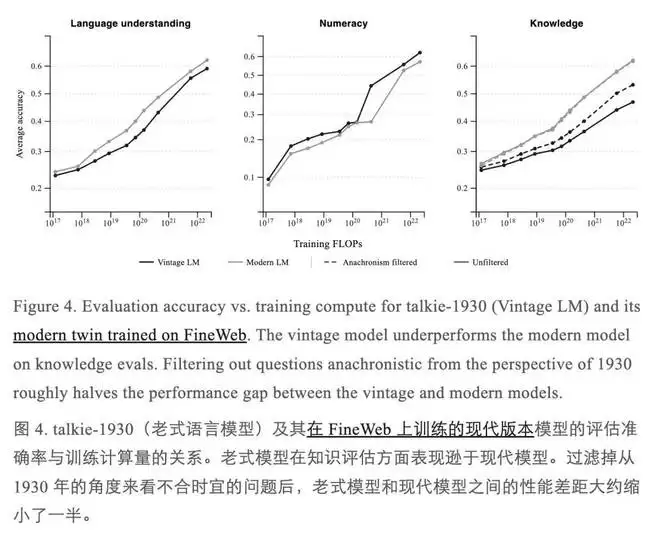
在语言理解和数字计算这两个维度上,Talkie的表现与现代孪生模型已相当接近。研究者认为,剩余的差距很可能源于两个原因:一是历史文本的OCR识别质量较差,二是训练语料的主题分布与现代模型存在较大差异。
训练复古模型,没那么容易
训练一个真正的“复古”模型,远没有听起来那么简单。
最棘手的问题叫做“时间泄漏”。训练数据的截止日期是1930年,但“1930年以前出版”并不等于“内容只涉及1930年以前的事”。一本1920年的书,如果后来重版,编辑可能添加了现代的序言;一份报纸的数字化档案,可能附带着整理者撰写的当代注释。这些内容一旦混入训练集,模型就会在不该知道的地方突然“开窍”。
早期的70亿参数版本就出现过这种状况——当被问及1936年谁是美国总统、签署了哪些重要立法时,它不假思索地答出了罗斯福和新政的细节,甚至还提到了联合国和德国的战后分裂。一个理应只活在1930年的模型,不知从哪条缝隙里窥见了后来的世界。

为此,研究者开发了一套基于n-gram的异常词检测分类器来过滤训练数据,但他们也承认这套方法并不完美。130亿参数的Talkie版本,依然对二战后的某些事件存在模糊的感知。如何彻底堵住这条时间裂缝,仍是一个悬而未决的问题。
另一个麻烦是数据质量。1930年没有数字出版,所有文本都需从纸质原件扫描、识别。传统的OCR系统对付干净的印刷品尚可,但面对版式复杂或保存不善的旧书,识别结果往往惨不忍睹——字母错位、段落混乱、符号乱入。研究者做过对照实验:同样的训练量,使用传统OCR转录文本训练出的模型,性能只有人工转录版本的30%。经过一些正则清洗后,能回升到70%,但差距依然显著。
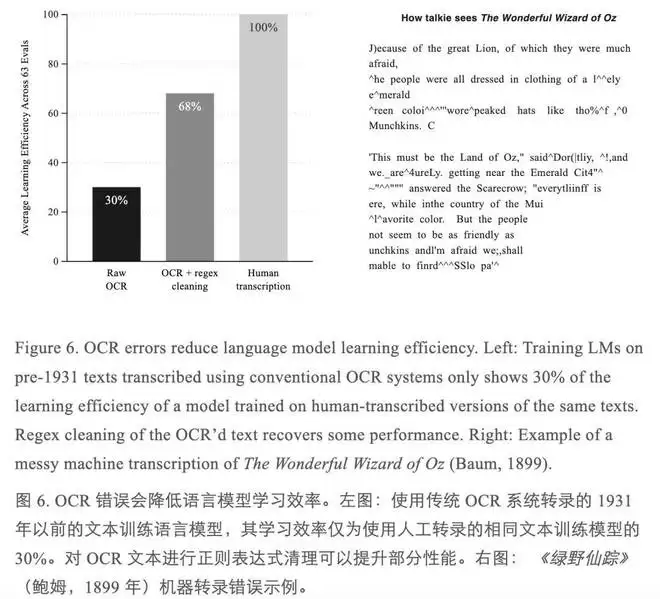
目前,他们正在开发一套专门针对历史文献的OCR系统,希望能补上这个质量缺口。
还有一个挑战在于训练后的“对齐”。现代大模型的指令微调,依赖于大量人工标注的对话数据,但这些数据都带着浓厚的现代世界气息和预设。用它们来微调Talkie,就像把一位维多利亚时代的绅士送去参加企业培训,出来之后满口都是PPT腔调。早期版本的Talkie在强化学习后,有段时间回答全是列表和要点,完全不像一个1930年代的人。
为了解决这个问题,研究者从历史文本本身入手,利用礼仪手册、书信范文、烹饪食谱、百科全书这类结构规整的旧书,生成指令-回复对,从头构建了一套后训练流程。他们让Claude Opus 4.6扮演用户,Talkie扮演助手,生成多轮对话,再用Claude Sonnet 4.6作为裁判,为Talkie的回答打分。训练开始时,裁判平均给2分(满分5分),结束时已升至3.4分。

当然,他们也坦承,用现代AI做裁判,本身就是一种“时代污染”。彻底干净的做法,应该用Talkie的基础模型来评价Talkie的对话——让自己审判自己,完全活在1930年的逻辑里。这是他们下一步希望尝试的方向。
目前,研究团队正在训练一个GPT-3级别的更大模型,并计划在今年夏季发布。初步估算表明,他们可以将历史文本语料库扩展到超过1万亿个token,这足以创建一个性能接近GPT-3.5级别的模型——其功能或许能与最初的ChatGPT相媲美。这个来自过去的“时间胶囊”,正在试图告诉我们,关于智能本质的更多秘密。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:GPT之父破解哈萨比斯难题:知识止于1930年的AI模型如何应对要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点火龙果写作可嵌入Word和WPS,实时标红语病并给出修改建议,每处错误需手动确认,避免误改专业术语。检查完成后可导出带修订痕迹的PDF或Word报告,便于审阅。
使用MasterGoAI生成Dashboard卡片布局时,需采用“分块引导+结构优先”策略:先通过自然语言描述骨架,结合截图与设计稿链接作为参考,生成后校验布局、启用自动布局并精修细节,同时注意图标、背景、数值等细节规范。
新手利用模板库创作时,需先筛选图文故事标签并加载模板,开启角色一致性锚点,通过双击编辑文案、替换图片或批量修改多页内容,完成全页连贯性检查与角色偏移校验,最后导出PNG序列。
稿定设计无法从主题自动推导框架、解析文档或提供术语校验,需借助外部AI工具生成大纲后再美化。真正具备AI生成能力的工具如MedSeeker、Gamma等可直接输入主题或文档,自动生成带专业内容与结构的PPT,节省大量时间。
- 日榜
- 周榜
- 月榜
热点快看