




谷歌TPU 8i如何以差异化策略挑战英伟达市场地位

在拉斯维加斯举行的Google Cloud Next大会上,谷歌高级副总裁Amin Vahdat揭晓了其AI芯片战略的重大演进:首次明确区分了训练与推理两大核心任务,并同步推出了专为各自优化的TPU 8t与TPU 8i芯片。这标志着谷歌TPU产品线进入了精细化分工的新纪元。 “随着AI智能体(Age
在拉斯维加斯举行的Google Cloud Next大会上,谷歌高级副总裁Amin Vahdat揭晓了其AI芯片战略的重大演进:首次明确区分了训练与推理两大核心任务,并同步推出了专为各自优化的TPU 8t与TPU 8i芯片。这标志着谷歌TPU产品线进入了精细化分工的新纪元。
“随着AI智能体(Agentic AI)的崛起,我们认为开发者社区将受益于针对训练和服务(推理)需求分别优化的专用芯片。”Amin Vahdat在官方博客中阐述道。这一决策清晰地传递出一个信号:AI算力市场正从通用化走向专业化,以满足下一代AI应用对效率与成本的极致要求。

此次“分家”策略中,专注于推理任务的TPU 8i成为了业界关注的焦点,它被视为谷歌抢占即将爆发的AI智能体时代商业机会的关键筹码。
TPU为什么要分家
谷歌为何要将芯片设计一分为二?核心驱动力在于提升整体效率与经济效益。
AI模型的训练与推理,虽同属计算范畴,但负载特性截然不同。训练过程如同让模型进行高强度、长周期的“深度学习”,追求极致的计算吞吐量与精度,以“大力出奇迹”的方式锻造模型能力。推理过程则如同模型“上岗工作”,需要以极低的延迟、高并发地处理海量实时请求,核心诉求是响应速度快、单次成本低、能效比高。
在AI发展早期,模型规模与应用场景相对有限,采用统一架构兼顾两者尚可平衡研发与使用成本。然而,随着AI智能体时代的到来,这种平衡被打破。智能体能够自主执行复杂任务链,其产生的推理请求量呈指数级增长,对芯片的实时处理能力与成本控制提出了前所未有的挑战。
企业的成本焦虑正从高昂的训练费用,快速转向更为持续的推理开销。从经济学角度看,专为训练设计的芯片通常搭载昂贵的高带宽内存(HBM),其成本占比极高。若用此类芯片处理智能体高频、海量的推理事务,无异于“杀鸡用牛刀”,将导致企业运营成本失控,阻碍AI应用的规模化落地。
“规模化商业化的关键在于,如何在实现最低响应延迟的同时,将每笔交易的成本降至最低。交易量正在激增,而单次成本必须大幅下降。”谷歌云人工智能与计算基础架构副总裁Mark Lohmeyer一语道破天机。
因此,谷歌选择了彻底的架构分离策略。
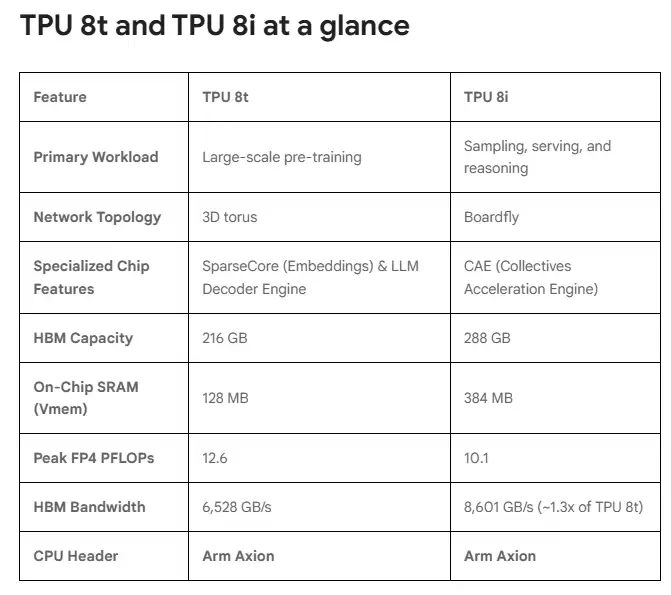
首先是面向训练的“算力巨兽”TPU 8t。其单个超级模块集成了9600颗芯片,提供高达121 exaflops的算力与2PB共享内存,计算性能较前代提升近3倍。全新的Virgo横向扩展架构支持超百万颗TPU芯片组成单一集群,有望将前沿大模型的训练周期从数月缩短至数周。在数据中心电力成为核心瓶颈的背景下,其能效表现尤为突出,实现了性能与每瓦性能的显著跃升。

其次是专攻推理的“成本杀手”TPU 8i。其设计直指推理瓶颈:首先,大幅强化了芯片的片上SRAM(静态随机存储器),容量提升至3倍。这使得芯片能够快速缓存关键数据,减少频繁访问外部HBM的延迟与功耗,有效缓解了AI推理中的“内存墙”问题。结合288GB的大容量HBM,TPU 8i能够流畅处理复杂的多步推理任务。
能效是TPU 8i的另一大杀手锏。其能效比较上一代提升117%,意味着在同等电力消耗下,可支持近乎翻倍的推理服务量。这为AI智能体的大规模、高频率部署提供了坚实的成本基础。行业分析预测,到2026年,近40%的企业应用将嵌入AI智能体,由此催生的市场规模巨大。谷歌的芯片分工战略,正是为了抢占这一未来市场的制高点。
Meta、Anthropic站台,新的算力联盟浮现?
谷歌对算力分工趋势的判断,迅速获得了市场重量级玩家的认可。Meta与Anthropic这两家AI巨头率先宣布成为TPU v8平台的首批重要客户。

AI明星公司Anthropic的联合创始人兼CEO Dario Amodei通过视频确认,其下一代核心模型的早期开发已在TPU 8t集群上运行数月。更为关键的是,Anthropic与谷歌达成了深度合作,计划在未来数年持续采购吉瓦级别的TPU算力,以保障其模型服务能力的弹性扩展。
这种合作超越了简单的硬件采购,形成了深度的“软硬协同”优化。谷歌TPU的光学互联技术与Anthropic模型采用的混合专家(MoE)架构进行了底层适配,从而显著降低了单次推理的Token成本。对Anthropic而言,这增强了其商业产品的成本竞争力;对谷歌而言,这获得了顶尖AI公司的实战验证与生态背书。
几乎同期,Meta被曝与谷歌签署了价值数十亿美元、为期多年的TPU使用协议,此消息一度引发英伟达股价波动。这并非意味着一个纯粹的“反英伟达联盟”成立,而更多是巨头们出于供应链安全与成本优化的“务实选择”。对于Meta和Anthropic而言,在依赖英伟达GPU的同时,引入谷歌TPU作为第二算力来源,能有效分散风险、增强议价能力。
谷歌的算力生意,本质是云生态的入口之争。TPU并不单独出售,而是作为Google Cloud的服务提供。客户使用TPU,往往会逐步融入谷歌的全栈AI云平台,从数据、训练、部署到应用集成。摩根士丹利分析指出,TPU产能的持续扩张将为谷歌带来可观的增量收入,并巩固其在AI云服务市场的地位。
老黄危机?英伟达“泥潭式”护城河
那么,谷歌的双芯片战略是否意味着英伟达的统治地位面临危机?目前来看,结论为时尚早。
谷歌与英伟达的关系呈现竞合交织的态势。在发布TPU 8i的同时,谷歌云明确表示其与英伟达的最新GPU平台是“互补”关系,并持续推进双方在软件与网络层面的合作。
英伟达构筑的护城河异常深厚。首先是以CUDA为核心的软件生态壁垒。全球数百万开发者基于CUDA构建应用,这种巨大的迁移成本构成了强大的用户锁定效应。其次是其惊人的迭代速度,通过垂直整合,其系统性能以远超行业平均水平的速度提升。此外,英伟达通过收购与自研,构建了从GPU、网络(InfiniBand)到软件(AI Enterprise)的完整基础设施栈,形成了封闭而高效的协同体系。
因此,谷歌TPU 8i采取的是一种“差异化切入”的战术。它并不寻求在训练市场全面替代英伟达GPU,而是瞄准了智能体时代爆发的推理市场,主打极致的成本与能效优势。对于那些对推理成本极度敏感、需要处理海量交互的企业客户而言,TPU 8i提供了一个极具吸引力的替代方案。简言之,在“炼模型”的主战场,英伟达地位稳固;但在“跑应用”的广阔腹地,谷歌正试图用TPU 8i切下最丰厚的一块蛋糕。

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:谷歌TPU 8i如何以差异化策略挑战英伟达市场地位要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点腾讯文档AI会议纪要标题应直击执行障碍,用“问题→后果”结构(如“接口文档缺失→后端返工3次”),禁用泛称,字数≤20字,通过自定义提示词触发重写。腾讯文档AI会议纪要功能默认生成的标题常泛泛而谈,比如“项目周会纪要”“部门协调会记录”,无法一眼抓住核心冲突或待解难题,导致后续查阅时找不到重点、推动
国内用户需优化印象AI会议纪要提示词:用“待办事项(负责人+截止时间)”替代“action items”,“会议结论:分三点陈述”替代“key takeaways”,禁用“stakeholder”改写具体部门与人名;强制添加审批栏前缀、分号分层、统一中文日期格式;并加入语音纠错、填充词删除及动词开头
有人用 Cursor 三天搭出了内部数据看板,省下外包报价的三万块;也有人让 AI 生成了 "全套用户管理系统 ",上线后发现数据库地址是 AI 编的,压根连不上。同样是 Vibe Coding,差距在哪?不是模型好不好,是你有没有给 AI 设好边界。这篇文章不讲大道理,直接给你三个可以抄走用的提示词模
Vibe Coding 最经典的一张照片,大概就是走到哪里都要带着自己的电脑。胡彦斌前段时间在小红书发布了一张在路上拿着笔记本电脑的照片,配文说「Vibe Coding 的都懂这个姿势。」我们几乎习惯了用 Agent 就是用电脑,带着安装了 Claude Code、Codex、Cursor、Open
- 日榜
- 周榜
- 月榜
热点快看