




商汤开源多模态效率怪兽8B模型性能比肩商用SOTA

当GPT-4o等模型再次成为焦点,业界的关注点也在悄然转变:仅仅“画得好”已经不够了,大家更渴望的是“速度快、效率高、成本低”。
过去很长一段时间里,视觉理解与图像生成,通常被视为两套独立的系统:一个负责“看懂”世界,另一个负责“画出”世界,两者之间需要通过复杂的模块进行衔接。这种底层逻辑上的割裂,恰恰是制约模型整体效率的核心瓶颈。
商汤科技这次带来的思路,是从架构的根源上解决这个问题。
他们刚刚开源了原生理解生成统一模型——SenseNova U1。该模型基于自研的NEO-unify架构,将图像与文本的理解与生成能力统一到同一套体系之中。当“中间商”被拿掉,效率自然得到了大幅提升。
在多项图像理解与生成的基准测试中,SenseNova U1 Lite版本在同量级的开源模型中达到了SOTA水平,并且在多项关键指标上逼近了商业闭源模型的表现。它以8B的参数规模,实现了接近更大模型的能力,堪称一次漂亮的“以小搏大”。
▲高密度信息图(en)
▲高密度信息图(zh)
目前,开发者可以在Hugging Face、GitHub等平台获取其开源模型。同时,商汤的AI办公智能体“办公小浣熊3.0”也即将接入SenseNova U1,届时用户可以直接体验其相关能力。
一、不靠堆参数,靠效率取胜:8B模型拿下开源SOTA
本次开源包含两个版本:SenseNova-U1-8B-MoT与SenseNova-U1-A3B-MoT。它们均基于统一的多模态理解、推理与生成架构,面向图文理解、生成及复杂交互任务。
从测评结果来看,SenseNova U1最突出的优势在于整体效率——在理解、生成、推理与图文交错等多个维度上,它用更小的模型规模,跑出了接近甚至比肩商业闭源模型的表现。
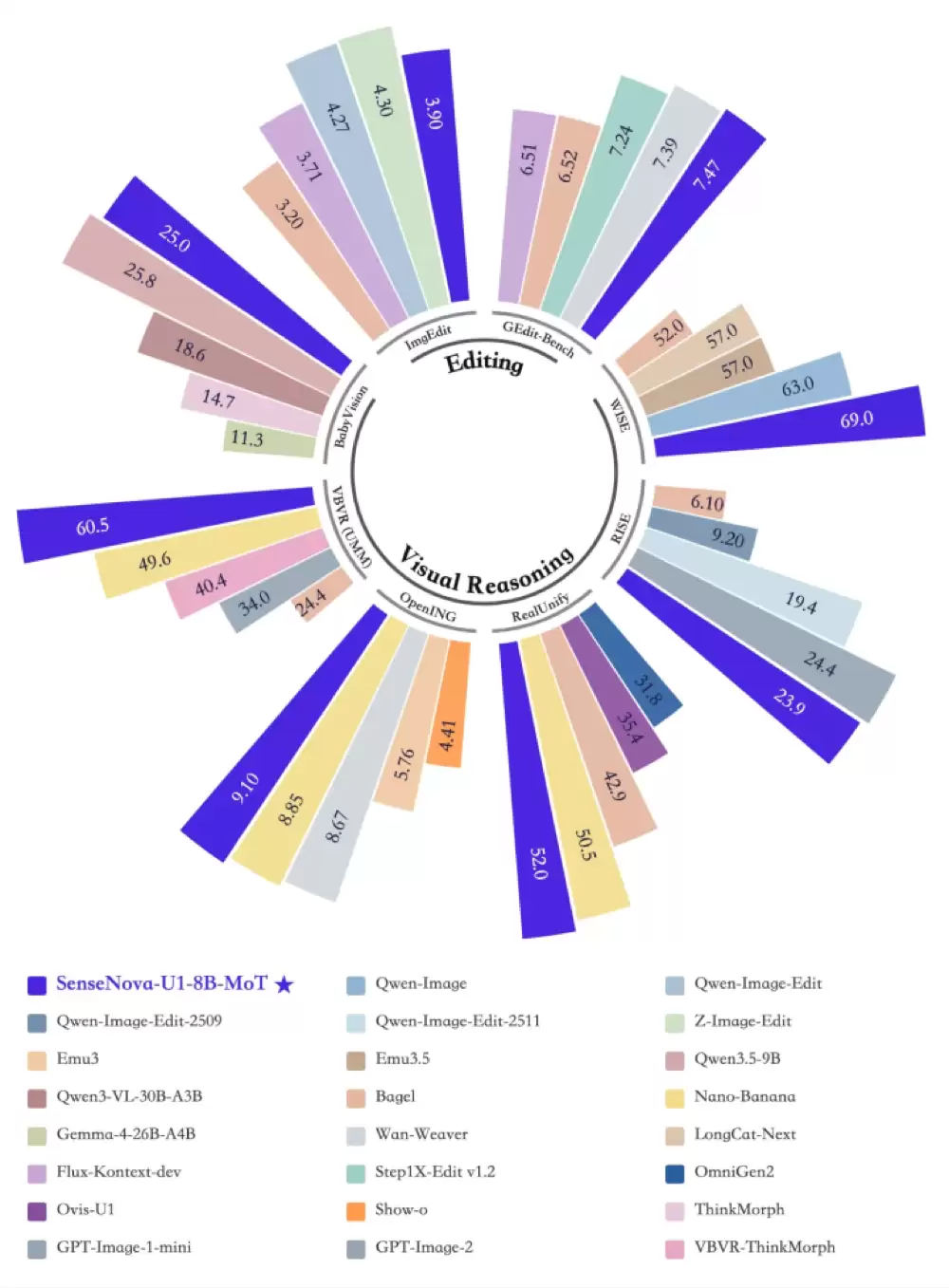
在理解侧,SenseNova-U1-8B-MoT在AI2D、IFBench等基准上均取得领先成绩,例如在AI2D上达到了91.7分。结合空间理解相关测试来看,模型在复杂结构与关系判断等任务中表现稳定,展现出不错的逻辑推理能力。
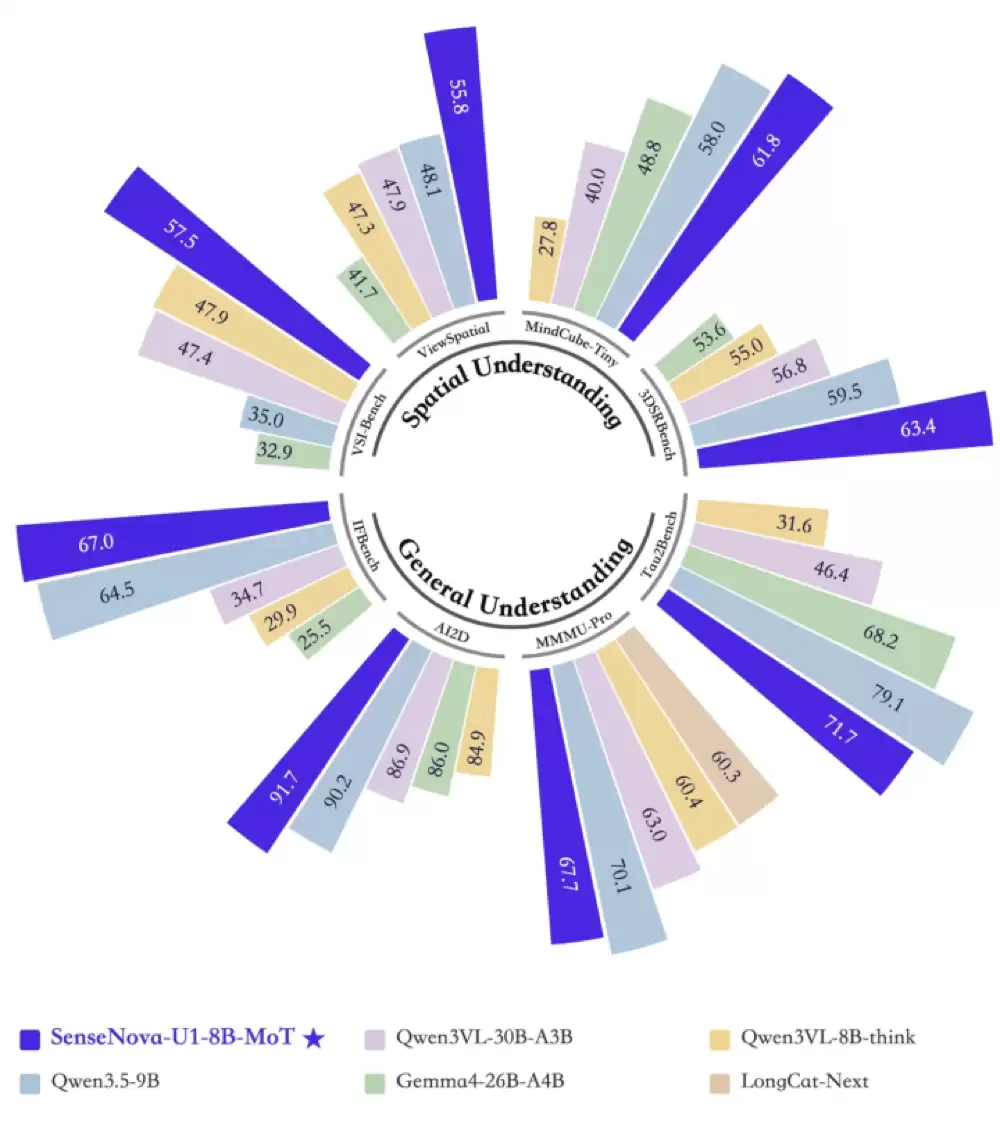
在生成侧,模型在GenEval、OneIG、LongTextBench等任务中表现同样稳健,能够同时兼顾复杂结构生成与文本一致性。尤其是在信息图生成(Infographics)任务中,其平均得分达到50.7,不仅是开源模型中的最强表现,甚至媲美部分闭源商业模型。
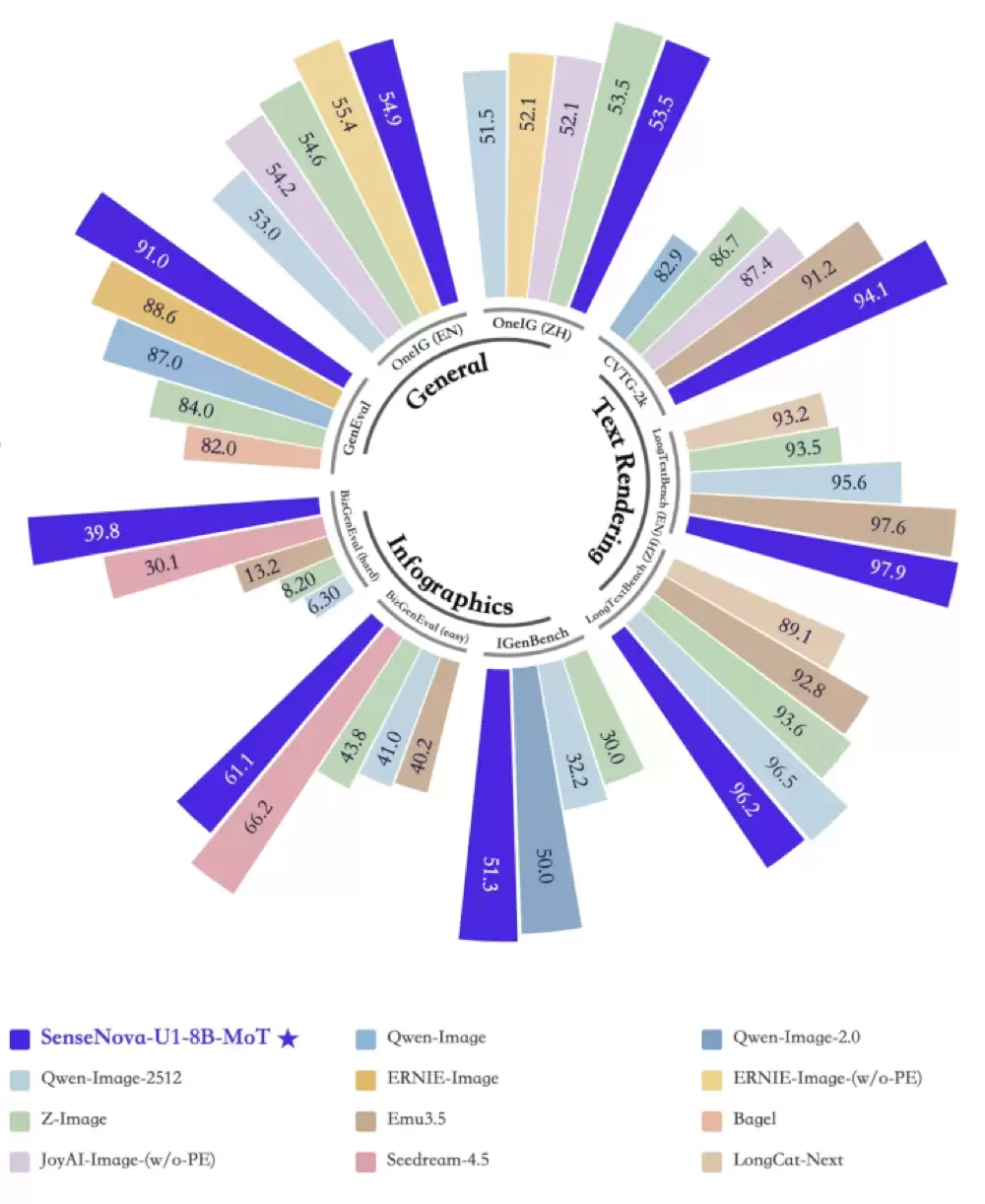
进一步考察其编辑与图文交错能力,在Editing、Visual Reasoning等任务中,SenseNova U1在WISE、VBVR、OpenING、GEdit-Bench等测试中表现突出。例如在OpenING相关任务中达到91分,在视觉推理任务中也明显优于传统的图像生成模型。
不过,相比这些分项成绩,更关键的是它的“性能—效率比”。
对比结果显示,在信息图生成与长文本等任务中,SenseNova U1在约15秒的延迟下即可取得接近60分的平均成绩,整体呈现出“高性能、低延迟”的特点。与Qwen-Image 2.0 Pro、Seedream 4.5等模型相比,其在生成质量接近商业闭源模型的同时,响应速度更快。
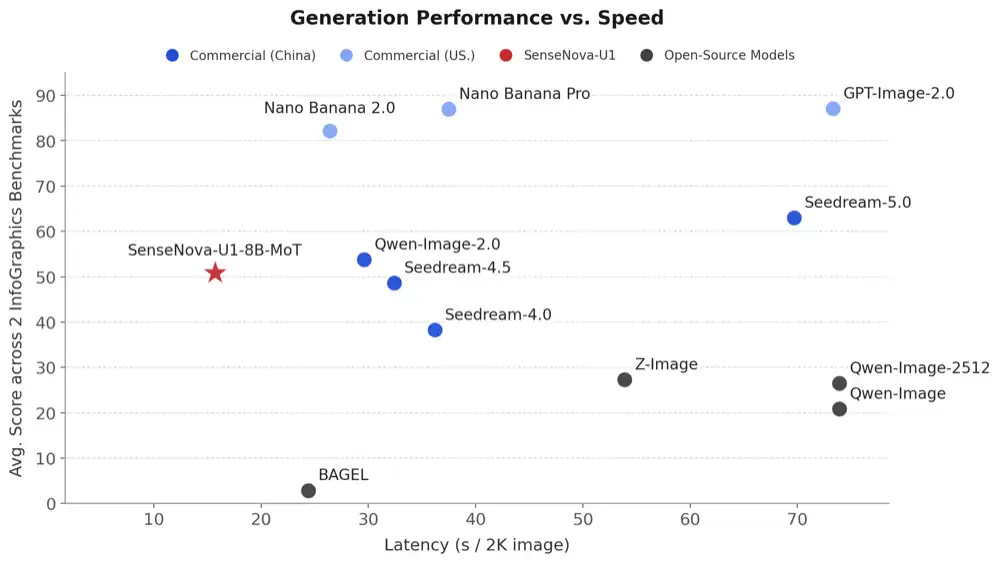
▲Generation Latency vs. A veraging Performance on Infographic Benchmarks, i.e., BizGenEval (Easy, Hard), and IGenBench
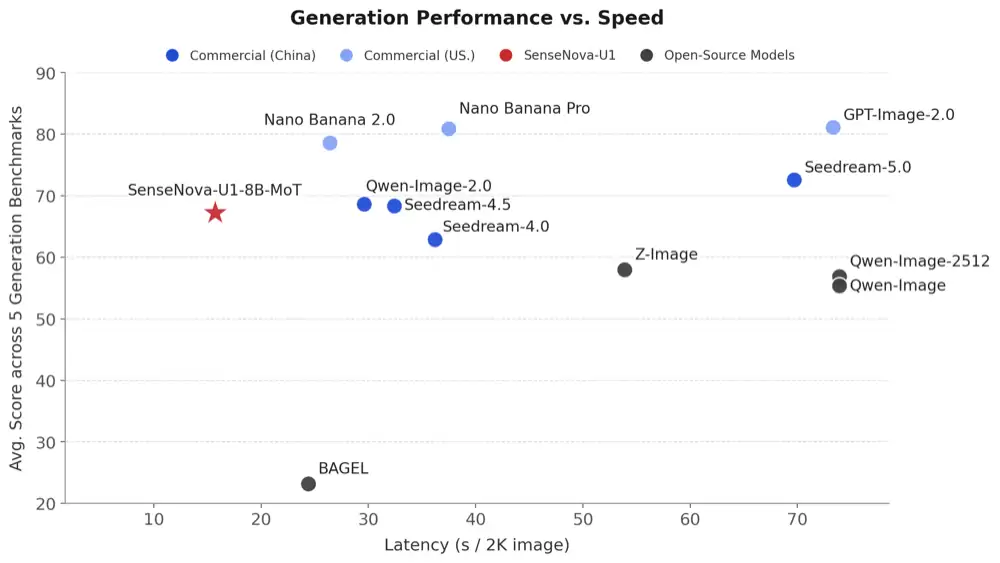
▲Generation Latency vs. A veraging Performance on OneIG (EN, ZH), LongText (EN, ZH), BizGenEval (Easy, Hard), CVTG and IGenBench
这些性能表现的背后,核心驱动力还是来自底层架构的优势。SenseNova U1基于商汤自研的NEO-unify原生统一架构,其设计减少了中间环节带来的信息损耗,因此在数据利用效率和推理开销上更具优势。
最终呈现出来的,便是“以小搏大”的竞争力:仅用8B参数规模,在多个维度达到同量级开源模型的SOTA水平,并在部分任务上逼近商业闭源模型。
从测评数据来看,这种优势已经相当清晰。那么,落到真实使用场景中,SenseNova U1是否同样稳定、好用呢?我们不妨来实测一番。
二、一手实测揭秘:从立体排版到“言出法随”
我们选取了多个不同类型的任务进行测试,覆盖高密度信息图、趣味创意图以及技术流程图等典型场景。
创作信息图可以说是最能“精准击中”职场人痛点的一项能力。用户只需输入文章、资料或文字说明,模型就能自动提炼其中的关键信息,并生成一张具备清晰结构、层级和视觉重点的信息图。
在“苏超出圈之路”这一案例中,模型生成了一张多层蛋糕式信息图。不同发展阶段以立体分层的形式呈现,文字随着结构自然分布在不同空间层级中,而非简单的平铺罗列。
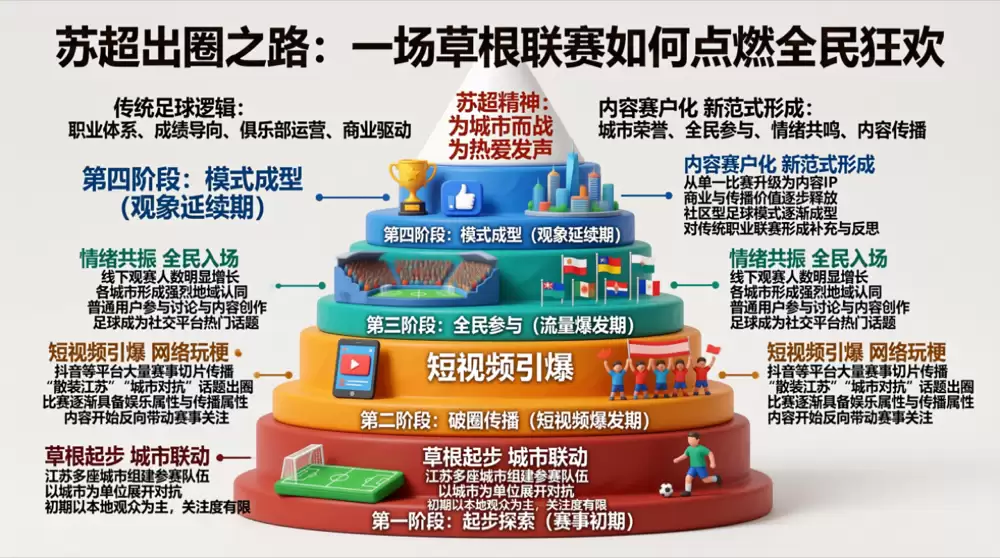
这背后反映的,其实是模型对空间结构的理解能力。更关键的是,在这种复杂的立体排版下,整张图没有出现明显的文字错位、遮挡或渲染错误,整体可读性非常高。
换一个更复杂的文本场景来看,模型对富文本结构的理解能力,体现得更为明显:哪些信息需要突出,哪些适合做成流程,哪些更适合用图表表达,哪些需要用图标辅助理解。
“龙虾使用指南”这个案例,就更能体现其在细节上的处理功力。

这一任务中包含大量中英文混排、不同字号文本以及情绪化表达。模型不仅准确呈现了“禁止模糊指令”“禁止无限重试”等核心文案,还自动匹配了对应的图标和带有情绪的画面,比如龙虾被“压榨”、被“投喂指令”等。
不同模块之间的文字大小、间距和布局都处理得相当合理,没有出现拥挤或混乱的情况,其完成度已经达到了可直接商用的水准。
在人物与指令理解方面,“马斯克vs奥特曼”这一案例更具代表性。

在提示词中仅输入“奥特曼”这一昵称,模型直接生成了一个穿西装的“奥特曼形象”,与旁边的马斯克形成鲜明对比,既符合语义又带有明显的趣味性。与此同时,马斯克的表情、动作以及整个对峙氛围也都刻画得比较到位,可见模型在人物理解和场景构建上具备较强的语义对齐能力。
到了技术表达这一步,难度其实更高。在“SenseNova U1技术解读”这一案例中,模型需要生成的是一张逻辑清晰的技术流程图。

从结果来看,整体结构层级清晰,信息分区明确、表达直观,即使对于非技术背景的读者也较为友好。
一轮实测下来,另一个比较直观的感受是速度。这类图像的生成基本都在十几秒内完成,颇有点“言出法随”的意味。
在这样的生成效率下,其应用场景也相当广泛。目前,SenseNova U1可生成信息图谱、专业简历、生活指南、产品说明、百科知识、漫画创作等多种内容。对于营销、办公、设计、商业分析等场景而言,这类能力直接对应着内容生产效率的跃升。
三、告别“缝合”,NEO-unify架构如何成为理解与生成的“通才”?
测评集成绩有优势,实测效果也毫不逊色,这个原生统一框架究竟好在哪里?我们来拆解一下。
过去,多模态模型的工作方式更像是“分工协作”:视觉编码器负责理解图像,变分自编码器负责生成图像。前者看图,后者画图,中间再通过不同的模块完成衔接。
理解与生成更像是两条并行的流水线,能配合,但很难真正融合。所以SenseNova U1这次选择直接推倒重建,从底层架构上改掉这套“拼接式”体系。
其采用的自研NEO-unify架构,不再把语言和视觉当作需要中间转换的两种信号,而是从一开始就把它们当作同一类信息来建模。
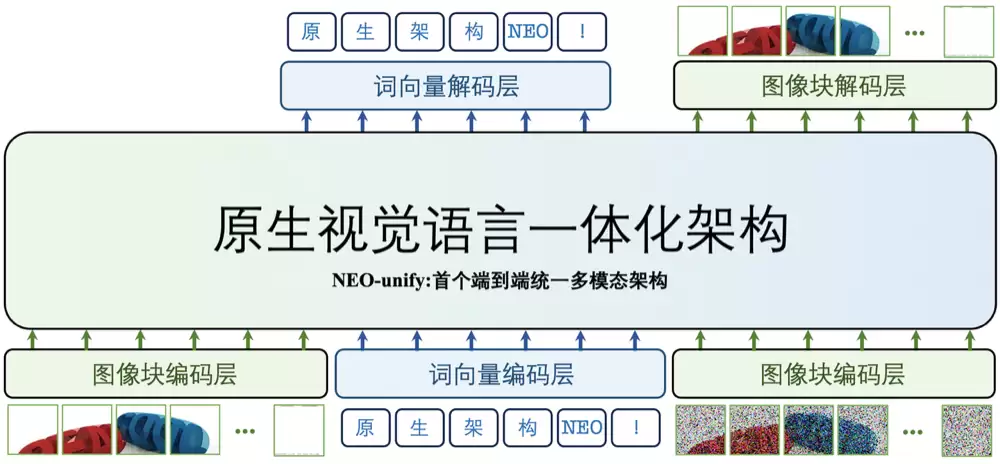
换句话说,语言与视觉不再各走各路,而是在同一套表征体系里共同参与理解、推理和生成。
这种设计本质上回归了“多模态AI的第一性原理”:不同模态之间本来就是内在关联的。
在具体实现上,模型尽量减少中间的压缩与转换环节,直接从接近原始的像素和文本信息中学习,让信息在传递过程中的损耗降到更低。
同时,它的数据和推理效率也更高。这也是SenseNova U1值得关注的地方:它并非单纯依靠堆叠参数规模来换取效果,而是在底层架构上重新梳理了多模态模型的协作方式。
四、当AI学会“带图思考”,展开空间智能更多想象
不同于单纯在图像质量上内卷的模型,SenseNova U1展示了另一种可能:让图像成为逻辑的一部分,并在推理过程中引入对空间结构的理解。
这也是其“连续性图文创作输出”能力的核心。
SenseNova U1是业内首个能够在单一模型上进行连贯图文交错生成的模型。这意味着,在处理复杂任务时,模型可以一边解释逻辑,一边生成对应的示意图、流程图、草图或设计图。
例如在教程编写、绘本创作等场景中,它可以让文字叙事、插图风格、人物事件等保持高度的一致性与连贯性。

同时,SenseNova-U1并非先生成一段完整文字,再去“补图”,而是从材料准备或构图草稿开始,一步步输出关键操作,并同步生成对应的画面。
整个生成过程是连续的:步骤之间有承接关系,图像之间保持风格一致,文字和视觉内容也始终围绕同一上下文展开。这种连贯性,在过去依赖多模型串联的方案中很难稳定实现,往往会出现风格漂移或信息断裂。
本质上,这得益于SenseNova U1所具备的原生图文理解生成能力,它能天然地将图像和文本的底层融合信号完整地保留在上下文中,在统一的表征空间进行高效、连贯的思考。
这也让它与空间智能产生了更直接的联系。空间智能关注的是模型如何理解位置、方向、布局、关系和结构,而这些能力恰恰会在图像生成、高密度信息图排版、流程图构建和场景示意中反复出现。
如果继续往后展望,这类能力也可能成为具身智能的重要基础。机器人要在真实环境中完成任务,不仅要“看见”物体,还要理解物体之间的关系、判断行动路径,并根据任务目标做出连续决策。
从这个角度看,SenseNova U1的意义不只是生成更好看的图,而是在单一模型中尝试打通理解、推理和视觉表达。它距离真正成为机器人的“具身大脑”尚有距离,但这类统一架构,至少提供了一条更接近多模态闭环的技术路径。
结语:理解与生成走向统一,多模态模型进入分岔口
从底层架构的NEO-unify创新,到应用层面的原生图文交错与高密度信息图生成,商汤的全面开源,不仅是参数规模上的“以小搏大”,更是对多模态第一性原理的深度回归。
当行业还在讨论生图模型的能力边界时,SenseNova U1已经通过理解与生成的统一,为AGI的到来铺就了一条更具效率的路径。
开源的力量将让这种原生多模态能力迅速渗透进每一个垂直行业。我们正在见证的,或许是一个“图文同构、思画合一”的全新时代的开启。
在大模型全球竞赛的下半场,国产模型正在输出属于自己的硬核解法。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

8G显存大模型硬件配置指南与可运行模型推荐
想在本地部署大语言模型,但只有一张8GB显存的显卡?这完全可行。关键在于精准选择模型与量化方案,在有限的硬件资源下实现最优性能。本文将为您详细解析适配8G显存的各类主流模型及其具体部署运行方案。 一、4-bit量化模型部署指南 对于RTX 3060、RTX 4060等主流消费级显卡,4-bit量化是

Canva证书制作教程:培训结业奖状DIY模板免费下载
制作一份兼具专业质感与视觉美感的证书,其实可以非常高效。借助Canva可画这类在线设计平台,即便是零基础的新手,也能轻松完成从模板挑选到成品导出的全流程。接下来,我们将详细解析使用Canva可画制作专业级证书的五个关键步骤。 一、选用专业证书模板 好的开始是成功的一半。在Canva可画,第一步变得异

Perplexity Pages页面不被收录如何检查Robots与SEO设置
许多用户在通过Perplexity Pages发布内容后,常常遇到一个关键问题:页面已经成功发布,但在Google、Bing等主流搜索引擎中却无法被搜索到。这通常并非搜索引擎的延迟,而是页面在技术配置或SEO设置上存在障碍,导致爬虫无法顺利抓取和索引。 简单来说,导致页面无法被收录的核心原因通常集中

Harness 是 AI Agent 的未来还是辅助工具
Harness,作为AI工程化进程中的关键组件,正成为提升大模型实际效能的核心手段。它要解决的核心痛点,是“模型具备潜力,但输出不稳定”。在当前阶段,Harness不可或缺,它能让能力尚不完善的模型可靠地投入生产环境。这好比一副可靠的支架——在腿部力量完全恢复之前,它是行走的必备支持。 近期GitH

千问AI数学解题能力实测 辅导作业实用指南
辅导孩子数学作业时遇到难题怎么办?别担心,现在有一位聪明的“AI家教”可以随时求助——千问AI。它不仅能提供详细的解题步骤,还能解析核心概念、梳理知识脉络,让数学学习过程更加清晰高效。关键在于,你需要掌握与它高效沟通的方法。 一、输入完整题目并明确需求 想要获得AI的精准解答,首先必须提供清晰的“问








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
