




Kimi K2.6 发布 300 个智能体如何保障应用安全

Kimi K2.6的发布,无疑是一个技术上的里程碑。但这次更新真正值得玩味的地方,或许并不在于模型本身又强了多少,而在于它悄然指向的未来。
4月20日,月之暗面正式推出Kimi K2.6。表面上看,这似乎又是一轮常规的模型迭代:长程代码能力更强了,多模态支持更完整了,256K上下文窗口得以保留,API和开源权重也同步更新。
但如果仅仅把它看作“又一个更强的大模型”,恐怕会错过这次发布背后更关键的信号。官方为K2.6打上的新标签,已经超越了传统的聊天、问答或代码补全,转而聚焦于“长链路编码”、“主动执行”、“持续后台运行”以及“大规模智能体集群(Agent Swarm)编排”。

一个值得警惕的趋势正在显现:开源模型的智能体能力,其竞争焦点正从“能不能做”转向“能做到什么规模”。
根据官方博客和模型卡披露的信息,K2.6能够将复杂任务横向拆解,调度多达300个子智能体(sub-agents),协调超过4000个步骤。模型本身采用1万亿参数的混合专家(MoE)架构,激活参数为320亿,包含384个专家,支持256K上下文,原生支持图像与视频输入,并提供了原生的INT4量化与部署指引。
它带来的,不只是“更会写代码”
K2.6此次升级的核心,并非参数量的简单堆砌,而在于其执行形态的根本性变化。
在新的技术描述中,K2.6被定位为一个原生多模态的、具备智能体特性的模型。其重点能力涵盖了长程代码生成、主动自治执行、智能体集群编排以及持续后台运行。
官方分享了一个内部案例:其强化学习基础设施团队曾利用一个由K2.6驱动的智能体,连续自主运行了5天,处理系统监控、事故响应和运维任务,实现了从告警到处置的完整闭环。这个案例虽然出自官方自述,并非第三方审计结果,但它清晰地传递出一个信号:K2.6瞄准的战场,已不再是“谁更会答题”,而是“谁更像一个可持续、可依赖的执行系统”。
这也正是为什么,评估K2.6的意义不能只看单轮对话的效果。

过去的模型升级,往往比拼的是知识密度、推理深度和代码补全质量。而K2.6似乎在挑战另一件事:一个复杂的任务能否被有效拆解、并行处理、持续执行,并在中途遭遇失败时,依然能够收敛出可用的结果。
一旦这种能力走向成熟,模型的角色将发生根本性转变——从一个“会回答问题的助手”,逐步演变为一个“可以承接并驱动工作流的执行节点”。这一点,在官方对多步工具调用、思考/非思考模式切换、视觉输入理解、后台执行以及智能体场景的着重描述中,已经相当明确。

开源和闭源的差距,确实被拉近了
从官方公布的基准测试结果来看,K2.6在部分关键的智能体任务上表现相当出色。例如,在“HLE-Full with tools”测试中,K2.6得分54.0,高于GPT-5.4的52.1、Claude Opus 4.6的53.0以及Gemini 3.1 Pro的51.4;在“DeepSearchQA”基准上也明显领先;在“SWE-Bench Pro”上,K2.6取得了58.6的成绩,略高于GPT-5.4的57.7和Claude Opus 4.6的53.4。
不过,现在就下“全面超越闭源模型”的结论还为时过早。因为同一份成绩单也显示,K2.6在“BrowseComp”上落后于Gemini 3.1 Pro,在“Toolathlon”和“MCPMark”上不及GPT-5.4,在“APEX-Agents”上也并非榜首。
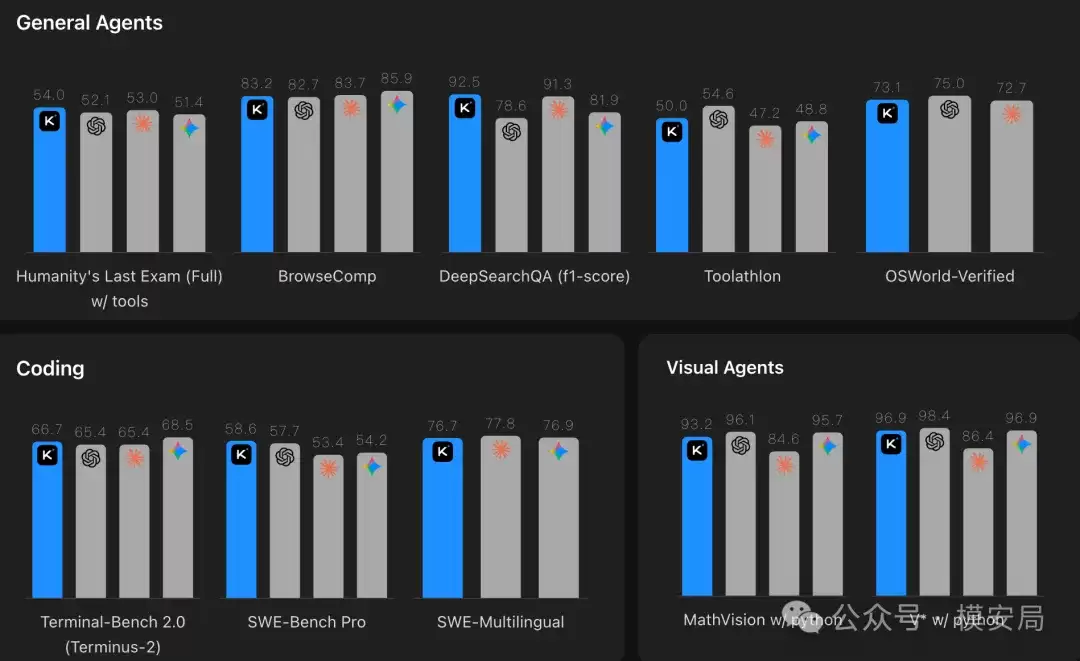
更稳妥的判断或许是:K2.6已经将开源模型在部分核心智能体基准上的上限,推到了与闭源前沿并驾齐驱的位置,甚至在个别点位上实现了反超。但它目前还远非所有智能体指标上的全线领跑者。
真正该追问的,是安全说明去哪了
问题恰恰随之而来:能力被显著抬高了,与之配套的安全披露却没有同步跟上。
截至目前,在可查找到的K2.6官方博客、Hugging Face模型卡以及API文档中,披露的重点几乎全部集中在架构、性能、部署、推理模式和基准测试成绩上。一份独立、完整的安全报告或智能体系统卡片(agent system card)似乎缺席了。
这种“空缺”在K2.5版本时就已经出现。独立研究论文《An Independent Safety Evaluation of Kimi K2.5》在摘要中明确指出:K2.5作为一个在编码、多模态和智能体基准测试上逼近闭源模型的开放权重模型,发布时并未附带系统的安全评估。因此,研究人员不得不自行评估其在CBRNE(化学、生物、放射、核、高爆物)、网络安全、目标失配行为、偏见与无害性等方面的潜在风险。
该论文还指出,K2.5在面对部分CBRNE相关请求时,拒答率较低,存在值得重视的滥用风险,并呼吁开放权重模型的开发者应发布更系统化的安全评估。
到了能力更强的K2.6,这个问题只会更加敏感和紧迫。
原因很简单:当模型仅仅是一个聊天模型时,其风险主要体现为“它说了什么”;而当模型开始调用工具、分派子任务、长时间运行、协调多个智能体时,风险就逐渐转变为“它做了什么”。

此时,单纯强调模型更聪明、更擅长写代码,已经远远不够。用户和开发者更需要知道的是:它的权限边界究竟划在哪里?运行过程中如何被有效监控?任务失败时如何安全中止?工具被滥用时如何回滚操作?多智能体协作时,又如何防止级联式的失效蔓延?遗憾的是,这些问题在当前的公开材料中,尚未得到系统性的解答。
这不只是月之暗面的问题,而是整个 Agent 行业的问题
如果把视角拉得更广一些,你会发现这并非某一家公司的个别疏漏。
麻省理工学院(MIT)发布的《2025年AI智能体指数》直接指出,在13个表现出前沿自治水平的智能体中,只有4个披露了任何形式的智能体安全评估;在纳入统计的30个智能体产品里,25个没有公开内部安全测试结果,23个缺乏第三方测试信息。
换句话说,整个行业似乎都更热衷于谈论能力提升、效率优化和产品功能,而对于系统真实的安全边界,则普遍表现出一种“不愿多谈”的倾向。
这也让K2.6的发布显得格外具有代表性。它让我们清晰地看到一件正在发生的事:开源智能体能力的扩散速度,已经明显快于行业对智能体安全进行公开说明和规范的速度。
一边是300个子智能体、4000个协调步骤、持续后台运行、跨平台编排的诱人前景;另一边却是安全披露稀缺、评估方法不一、责任边界模糊的现状。两者之间的张力正在日益凸显。
开源把能力下放了,也把责任边界冲淡了
对于闭源模型,至少还存在一个相对明确的责任中心:服务提供商需要负责模型的上线、对齐、红队测试、策略拦截以及服务端的全程监控。
而开源模型的责任链条则要复杂和模糊得多。
模型发布方提供基础权重,框架方构建执行层,开发者接入各种工具,企业最终将其部署到真实的业务系统中。一旦出现权限越界、目标劫持、工具滥用、记忆污染、身份冒用或多智能体级联失败,责任会被迅速拆解、分散到各个环节,难以追溯和界定。
开放式Web应用程序安全项目(OWASP)发布的智能体安全框架,已将目标劫持、身份与权限滥用、记忆与上下文污染、级联失败等列为关键风险;思科(Cisco)则将安全智能体的重点放在扫描、沙箱、模型上下文协议检查以及AI资产清点上,其本质也是在弥补“模型本身之外”的系统级安全护栏。

因此,K2.6带来的最大冲击,或许并非“又一个强大的模型开源了”,而是揭示了一个更深层的趋势:高阶智能体能力正在以前所未有的速度民主化,但与之匹配的责任框架、运行时防护机制和公开透明的披露标准,却尚未同步建立起来。这并非一句道德指责,而是一个日益迫切的工程现实问题。
如果你准备把 K2.6 用进生产环境,至少先做这几件事
面对能力与风险并存的现状,在将K2.6这类先进智能体模型引入生产环境前,保持审慎并建立基础防护至关重要。以下几点建议可供参考:
第一,切勿从一开始就将其视为“全自动自治系统”。应将其定位为需要人类监督和干预的增强型工具。
第二,严格控制智能体数量、可调用工具的范围以及外部系统的连接权限。从小规模、低风险的场景开始进行验证和迭代。
第三,务必记录每一次工具调用、子任务派发、跨智能体协作以及上下文写入操作,确保运行过程的可审计性,避免其成为无法追溯的“黑箱”。
第四,将任务中止、操作回滚、安全审计和实时告警机制,作为上线前的必备能力进行设计和测试,而不是事后再打补丁。
第五,如果业务场景涉及代码执行、对外部系统的写操作、凭证调用或长时间后台任务,应默认将其归类为高风险场景。必须严格贯彻权限最小化原则,并将运行时监控置于最高优先级。
提出这些建议,并非因为K2.6本身特别“不安全”,而是因为这类模型一旦开始承担复杂的执行链条,其安全问题的性质就必然从“内容风险”转向更具挑战性的“系统风险”。
结语
Kimi K2.6毫无疑问是一个技术里程碑。它将开源模型在长程代码、工具调用、多智能体协作和持续后台执行方面的能力,推上了一个新的高度,也让“开源智能体能否接近闭源前沿”这个问题,答案越来越趋向肯定。
但这次发布更重要的启发,或许恰恰在能力之外:当调度300个智能体变得触手可及时,安全保障不能再仅仅是技术发布会最后一页上,那个“来不及细讲”的附注。
如果能力的民主化进程已经启动,那么与之配套的责任机制、评估方法和运行时护栏,也必须尽快跟上。否则,开源智能体时代越是热闹喧嚣,真正的风险就越可能被掩埋在“更强了”这三个字的背后。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

防范Agent间接越狱攻击的工程实践可信动作清单
今天我们来深入探讨一个日益紧迫的现实挑战:当AI智能体(Agent)开始自主处理邮件、浏览网页、操作各类工具时,如何确保其行为不被恶意内容“带偏”?近期一篇题为《PlanGuard: Action-Level Guardrails for Language Agents via Reference

Java与LangChain4j实现RAG文档智能拆分提升检索质量
在AI驱动的RAG系统开发与后端面试中,文档切分策略是衡量工程深度的关键指标。简单回答“按固定字符数截取”往往暴露了项目经验的不足。业务场景中RAG的召回效果,数据预处理的质量占据了决定性因素。切片(Chunking)策略的优劣,直接为整个系统的召回能力设定了天花板。后续无论采用多么先进的大模型或精

Excel反向查找数据技巧:一句话快速匹配信息
本文目录 Excel反向查找的常见痛点 AI自动化处理效果预览 1 准备工作与数据要求 2 超简单的AI自动化解决方案详解 第1步:规范整理你的原始数据表 第2步:对目标文件下达清晰指令 第3步:一键验收并拓展同类应用 核心指令的底层逻辑与优势 更多可直接套用的实战场景 1 快速填充联系人电话

2026年新车盘点 8款车型上市续航超两千公里起价6万多
2026年的汽车市场,热闹非凡。当许多人的目光被比亚迪秦L牢牢吸引时,一份涵盖8款新车的清单悄然浮现,价格从6万多横跨至12万多,最长续航甚至达到了惊人的2150公里。这场混战,让选择变得前所未有的丰富。 燃油拥趸的新选择:2026款荣威i6 对于依然钟情于燃油车可靠与便利的消费者来说,2026款荣

福田汽车发布苍穹AI大模型 赋能商用车全场景智能生态
在中国公路货运的庞大生态中,3800万卡车司机是当之无愧的基石力量。然而,这份职业长期伴随着超负荷工作与健康隐患的双重压力。行业调研数据显示,近40%的重型卡车司机年工作时长超过3600小时,夜间行车比例高达60%以上,而各类职业相关疾病的检出率已超过70%。更值得警惕的是从业者结构的老化趋势:45








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
