




Linux网络收包全链路图解:数据包从网卡到程序的完整旅程

调用recv()函数读取网络数据,是网络编程中的基础操作。但你是否深入思考过,一个远端发送的数据包,究竟是如何从物理网线上的比特流,最终转换为你应用程序缓冲区中的字节序列的? 这个过程横跨了硬件、驱动程序与内核协议栈三大领域。CPU在何时被通知?内核在背后默默完成了哪些关键步骤?像epoll这样的I
调用recv()函数读取网络数据,是网络编程中的基础操作。但你是否深入思考过,一个远端发送的数据包,究竟是如何从物理网线上的比特流,最终转换为你应用程序缓冲区中的字节序列的?
这个过程横跨了硬件、驱动程序与内核协议栈三大领域。CPU在何时被通知?内核在背后默默完成了哪些关键步骤?像epoll这样的I/O多路复用机制,又是如何精准感知到“数据已就绪”这一事件的?
彻底厘清这条数据接收链路,许多看似孤立的高性能网络知识点将瞬间融会贯通——为何epoll是应对高并发的首选模型、零拷贝技术如何削减CPU开销、网卡多队列设计怎样提升吞吐量,其底层原理都植根于同一套核心机制。
今天,我们将完整地拆解一个数据包的“入站之旅”。

一、全局视角:数据包接收的核心流程
在Linux内核中,一个外来数据包的完整接收链路,通常遵循以下关键阶段:
网卡物理层接收 → DMA直接写入内存 → 触发硬件中断 → 启动软中断处理 → 网络协议栈逐层解析 → 数据存入socket接收缓冲区 → 唤醒等待中的用户进程。
各阶段职责清晰,协同工作。我们先通过一张全景图建立整体认知:
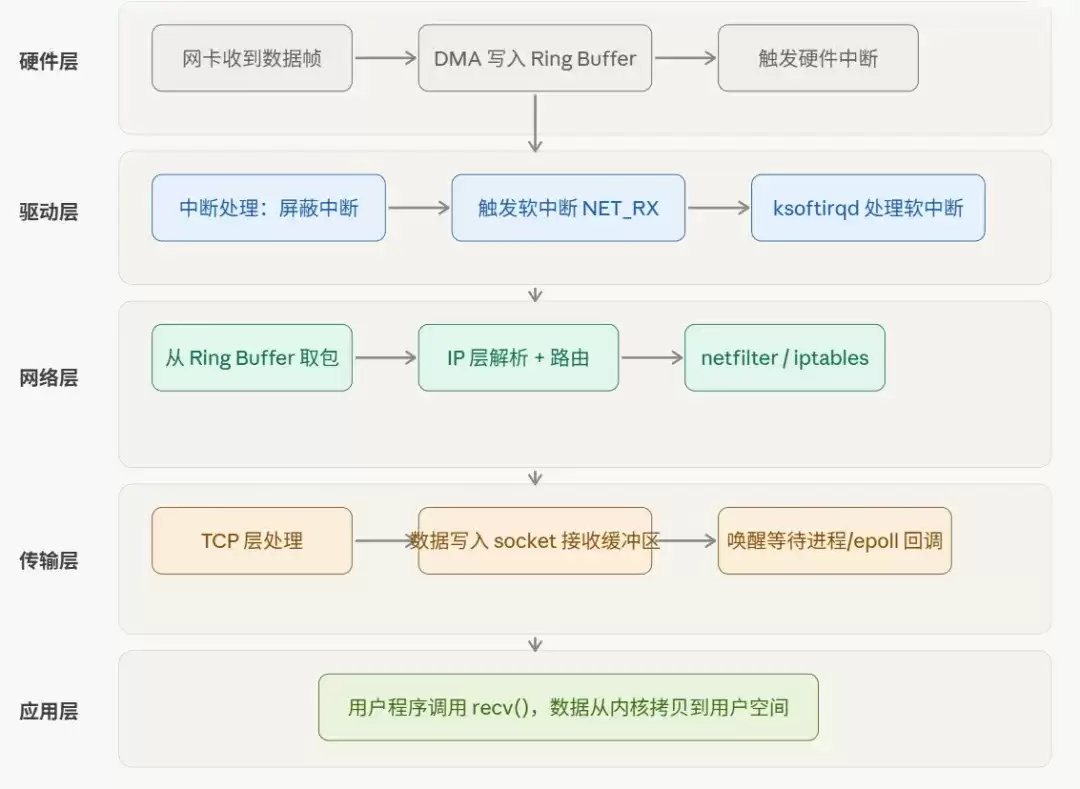
接下来,我们将自底向上,逐一剖析这五个核心环节。
二、第一阶段:网卡接收与DMA内存写入
当数据包抵达物理网卡时,CPU是完全无感知的,也未参与任何操作。
网卡独立完成了初始工作:从网络媒介上接收数据帧,并借助DMA(直接内存访问)技术,将数据直接写入内核驱动程序预先分配好的一块内存区域——即接收环形缓冲区(Ring Buffer)。
整个过程由网卡硬件自主完成,CPU零参与,实现了极高的效率。
那么,Ring Buffer的本质是什么?
它是由网卡驱动在内核空间分配的一个环形队列,其中预置了多个sk_buff(套接字缓冲区)结构。每个sk_buff指向一块可用的内存区域。网卡收到数据后,通过DMA将数据直接写入某个空闲sk_buff所指向的内存,随后将该缓冲区标记为“已占用”。
接收环形缓冲区示意:
┌──────┬──────┬──────┬──────┬──────┬──────┐
│ 空闲 │ 空闲 │ 已用 │ 已用 │ 已用 │ 空闲 │
└──────┴──────┴──────┴──────┴──────┴──────┘
↑ ↑
待处理包 网卡下一个写入位置如果Ring Buffer被全部填满,新到达的数据包会被网卡直接丢弃,这便是在网卡层发生的丢包。可以通过命令ethtool -S eth0 | grep drop查看相关统计。
DMA写入完成后,网卡会执行一个关键动作:向CPU发送一个硬件中断(IRQ)信号,通知其“有新的网络数据包待处理”。
三、第二阶段:从硬件中断到软中断
CPU收到网卡的中断信号后,会暂停当前执行的任务,转而执行与该中断关联的中断服务程序(ISR)。
这里存在一个重要的内核设计原则:中断处理函数必须尽可能快地执行并返回。
原因在于,在处理硬件中断期间,同一CPU核心上的其他中断通常会被暂时屏蔽。若ISR执行时间过长,会导致其他设备(如磁盘、USB控制器)的中断无法及时响应,影响系统整体性能。
因此,网卡的中断处理函数通常只完成最紧要的两件事:
- 确认中断已接收,并可能暂时屏蔽该网卡的后续中断(以避免中断风暴)。
- 触发一个名为NET_RX_SOFTIRQ的软中断(SoftIRQ),然后立即返回。
真正耗时、复杂的收包处理逻辑,被推迟到随后执行的软中断上下文中完成。
软中断由内核线程ksoftirqd负责处理。它在中断处理函数返回后,以异步方式执行核心任务:从Ring Buffer中批量取出数据包,并将其送入内核网络协议栈进行后续处理。
这种设计被称为“上半部/下半部”(Top Half / Bottom Half)机制:
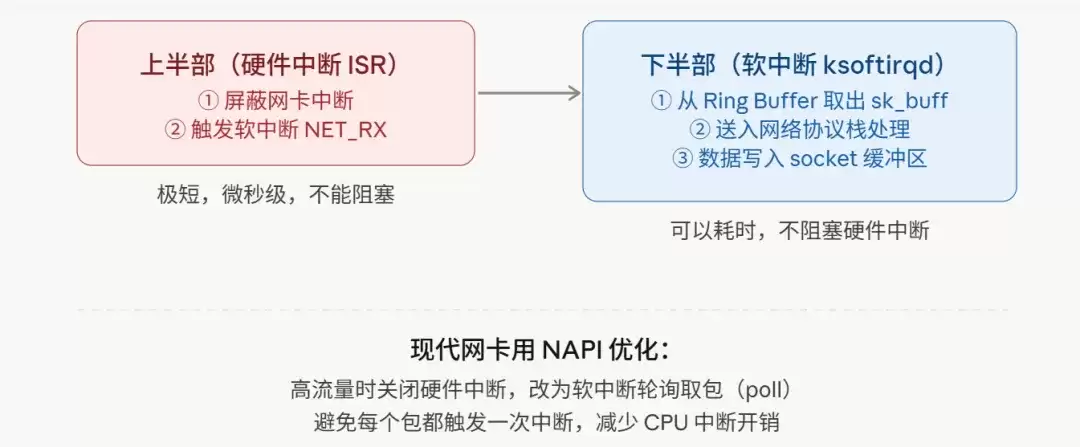
现代网卡驱动普遍采用NAPI(New API)机制进行优化:在高流量场景下,驱动会主动关闭硬件中断,改为由软中断周期性地轮询(Poll)Ring Buffer,从而批量处理多个数据包。这有效避免了每个数据包都触发一次CPU中断,对于每秒处理数十万包(pps)的高并发场景至关重要,否则CPU将把大量时间耗费在中断上下文切换上。
四、第三阶段:内核网络协议栈处理
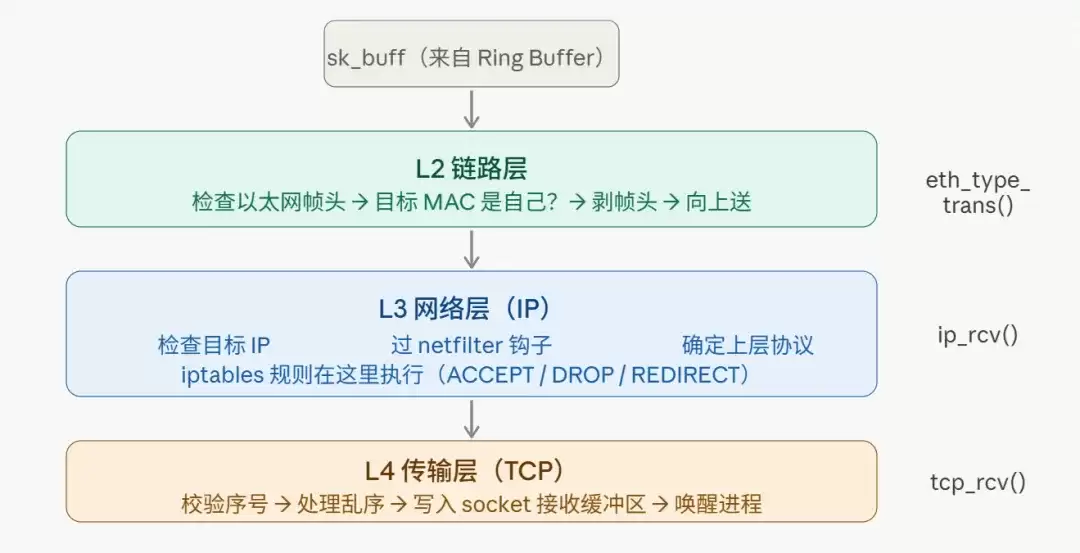
软中断获取到sk_buff结构后,便开始了协议栈的逐层解析。这是内核网络子系统最复杂的部分,但其逻辑是清晰的——本质是自底向上地剥离各层协议头部。
- 链路层(L2):检查以太网帧头,确认目标MAC地址是否匹配本机,剥离帧头和帧尾(如FCS),将数据包向上传递给网络层。
- 网络层(L3):IP层接手后,主要完成三项工作:
- 校验IP头部(如校验和),并确认目标IP地址属于本机。
- 经过Netfilter框架的钩子点(iptables等防火墙规则在此生效)。
- 根据IP头部的协议字段(例如,TCP为6,UDP为17)决定将数据包递交给哪个传输层协议处理。
- 传输层(L4):以TCP为例,这是最为复杂的一层:
- 校验TCP序列号、确认号,处理可能的乱序、重复和重传,确保数据有序可靠。
- 将处理后的应用层数据(Payload)放入对应socket的接收缓冲区(
sk->sk_receive_queue)。 - 检查是否有用户进程正在等待该socket的数据,若有,则将其唤醒。
这三层处理的递进关系如下图所示:
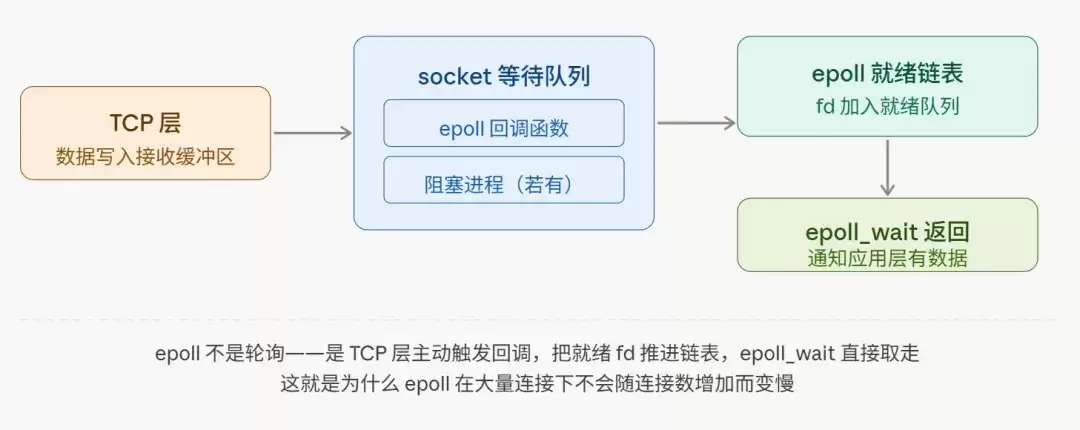
五、第四阶段:数据进入Socket缓冲区与epoll的就绪感知
当TCP层将数据成功放入socket的接收缓冲区后,后续发生什么,取决于应用程序采用何种I/O模型来等待数据。
场景一:进程阻塞在recv()系统调用
如果进程调用recv()时,对应socket的接收缓冲区为空,进程会被置为睡眠状态(TASK_INTERRUPTIBLE),并加入到该socket的等待队列中。当TCP层写入数据后,内核会直接唤醒等待队列中的这个进程,进程随即从recv()调用中返回并读取数据。
场景二:进程使用epoll等多路复用机制监听
当通过epoll_ctl将一个socket文件描述符(fd)添加到epoll实例时,内核会在该socket的等待队列中挂载一个特定的回调函数(例如ep_poll_callback)。当TCP层写入数据并执行唤醒逻辑时,会触发这个回调函数——该函数的职责就是将对应的socket节点加入到epoll的就绪链表(ready list)中。随后,用户调用的epoll_wait便会返回,通知应用程序“有fd处于可读状态”。
这就是epoll高效感知数据到达的底层机制:它不是通过轮询所有fd,而是由协议栈处理数据时的回调事件所驱动。
六、第五阶段:recv()完成数据从内核到用户空间的拷贝
epoll_wait返回可读事件后,应用程序调用recv(),这才进入接收链路的最后一步。
char buf[4096];
int n = recv(fd, buf, sizeof(buf), 0);recv()作为系统调用,陷入内核后所做的工作相对明确:从对应socket的接收缓冲区中,将数据拷贝到用户空间提供的缓冲区buf中,然后返回实际拷贝的字节数。
这里存在一个至关重要的性能节点:这是整个数据接收链路中,唯一一次发生数据从内核空间到用户空间拷贝的环节。
从网卡DMA写入Ring Buffer,到协议栈层层处理,再到最终放入socket接收缓冲区,数据全程都在内核地址空间内流动。唯有执行recv()(或其变体如read)时,才会发生这次跨越内核边界的数据拷贝。
这也正是零拷贝技术(如sendfile、splice)能够显著提升网络传输性能的核心原因——它们通过不同的方式,避免了这次昂贵的拷贝操作。
七、完整链路梳理与总结
至此,一条完整的数据包接收链路已经清晰呈现。每个阶段的核心职责总结如下:
- 网卡与DMA:负责物理信号的接收和到内核内存的搬运,CPU不参与,实现高效数据搬移。
- 硬件中断:快速响应硬件通知,将耗时的处理工作委派给软中断,遵循“上半部快进快出”原则。
- 软中断:在进程上下文之外,批量处理数据包,并将其送入网络协议栈,常由ksoftirqd线程执行。
- 协议栈处理:逐层解析以太网、IP、TCP/UDP头部,进行校验、过滤、重组,最终将有效载荷放入目标socket的接收缓冲区。
- 唤醒与通知机制:根据进程的等待方式(阻塞I/O或I/O多路复用),唤醒相应进程或触发epoll等机制的回调函数。
- recv()系统调用:完成数据从内核空间到用户空间的最终拷贝,是用户程序获取数据的唯一接口。
八、延伸问题与性能优化探讨
Q:为什么在高性能服务器中推荐使用多队列网卡?
默认的单队列网卡所有收包中断都集中发送给一个CPU核心,在高流量下容易使该核心成为瓶颈。多队列网卡配合RSS(接收端缩放)技术,可以创建多个硬件接收队列,每个队列可以绑定到不同的CPU核心上。这样,收包中断和软中断处理负载就被分散到多个核心,实现了并行处理,网络吞吐量可随CPU核心数近似线性增长。
Q:系统监控发现ksoftirqd软中断进程CPU占用率过高怎么办?
在top命令中若看到si(软中断)占用率持续很高,通常表明网络收包压力极大。优化思路包括:确保NAPI机制已启用,实现批量收包以减少中断频率;为多队列网卡配置RSS,将中断均衡到多个CPU;调整网络参数(如net.core.netdev_budget);在极致性能场景下,可考虑使用DPDK(数据平面开发套件)或XDP(eXpress Data Path)等技术,将网卡数据旁路到用户态处理,彻底绕过内核协议栈。
Q:recv()系统调用返回0代表什么含义?
对于TCP socket,recv()返回0通常表示对端已正常关闭连接(发送了FIN包),并且本端已接收完全部数据。这标志着TCP连接的四次挥手已完成,连接被正常关闭。返回0是文件结束(EOF)的正常指示,并非错误。应用程序应关闭对应的socket描述符,而不应继续调用recv()。
Q:socket的接收缓冲区被填满会导致什么后果?
如果TCP层试图将数据放入一个已满的socket接收缓冲区,它会失败。随后,TCP会在发出的ACK确认包中将接收窗口(rwnd)通告为0,以此通知对端“暂停发送数据”——这就是TCP的流量控制机制。对端收到零窗口通告后会进入“持续计时器”状态,直到你的应用程序通过recv()消费掉部分数据,内核重新打开接收窗口并发送窗口更新为止。
九、代码示例:对照epoll服务器理解链路
// 服务端:基于epoll的收包框架示例
int epfd = epoll_create1(0);
// 将 listenfd 和已建立的 connfd 注册到 epoll 实例
// 内核会在socket的等待队列中挂载epoll的回调函数
struct epoll_event ev = {.events = EPOLLIN, .data.fd = connfd};
epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev);
struct epoll_event events[64];
while (1) {
// epoll_wait 阻塞等待,直到某个socket的TCP层处理数据时触发了回调
// 回调函数将该socket加入就绪链表,epoll_wait 才得以返回
int n = epoll_wait(epfd, events, 64, -1);
for (int i = 0; i < n; i++) {
char buf[4096];
// 此时才真正调用recv,将数据从内核socket缓冲区拷贝到用户空间buf
int len = recv(events[i].data.fd, buf, sizeof(buf), 0);
// ... 处理接收到的数据 buf
}
}对照这段典型的epoll服务器代码,整条接收链路便一目了然:
epoll_ctl注册回调 → 网卡收包 → DMA写入内存 → 软中断处理 → 协议栈解析 → TCP层触发epoll回调 → epoll_wait返回 → recv()执行最终的数据拷贝。
十、总结
回顾全程,一个数据包从物理网线抵达你的应用程序缓冲区,穿越了硬件、驱动、内核协议栈三个世界,每一层都恪尽职守:
- 网卡与DMA:负责物理信号的接收和到内存的零CPU拷贝搬运。
- 中断机制:硬件中断实现快速通知,繁重任务交由软中断异步处理,保障系统响应性。
- 协议栈:逐层剥离协议头部,TCP层确保数据可靠、有序地放入目标socket缓冲区。
- epoll/IO多路复用:通过事件回调机制高效感知就绪事件,避免了无效的轮询开销。
- recv()系统调用:是数据旅程中唯一一次踏入用户空间的时刻,也是零拷贝技术优化的关键点。
深入理解这条完整的接收链路,许多高性能网络编程中的“最佳实践”便不再神秘。epoll为何能支撑高并发、零拷贝技术优化了哪一步性能瓶颈、多队列网卡与RSS如何提升吞吐量……你会发现,它们都是对这套底层机制在不同层面进行的深度优化与适配。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

先导智能交付海外首条全极耳圆柱电芯产线助推欧洲豪车电气化转型
先导智能成功交付海外首条全极耳圆柱电芯产线,用于欧洲顶尖豪华车品牌德国诺德林根电池工厂。产线搭载自研智能系统,实现单电芯100%在线溯源,AI视觉检测识别潜在风险,焊接不良率和运营成本均降低30%。

八位堂Xbox机械键盘新版新增RGB背光
八位堂推出Retro87机械键盘Xbox版,采用初代Xbox透明绿外壳,首次加入RGB背光,提供八种模式。键盘为87键布局,搭载凯华JellyfishX开关,内置2000mAh电池,续航达200小时。同步发布RetroR8鼠标,配备PAW3395传感器和充电底座。键盘现已在亚马逊开启预售,售价119 99美元,2025年1月16日发货。

天硕V60 256GB SD卡 高速稳定的卓越品质 开启存储新境界
天硕V60256GBSD卡具备256GB容量,读取260MB s、写入150MB s,支持4K60P视频录制。采用长江存储闪存与自研主控,达到IP68三防等级,兼容主流相机,集成纠错编码与磨损均衡技术,为专业影像创作提供可靠存储方案。

i扫地机器人全球热销 高端市场占有率30%
杉川机器人全球高端扫地机器人市场占有率达30%,获广东省制造业单项冠军。公司全球出货超千万台,拥有多项专利。其净水循环与空气制水技术实现终生不用加清水、倒污水,突破传统使用瓶颈。

荣耀笔记本X Plus系列全新配色定档12月2日
荣耀笔记本XPlus系列将于12月2日发布,推出浅海蓝新配色,搭配银色品牌标识,主打轻薄机身。该系列首发搭载酷睿第二代英特尔酷睿5处理器,续航提升。荣耀CEO预告明年将全面布局PC领域。同期荣耀300系列也将发布。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-11 15:04
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:02
2026-07-11 15:02
热门教程
2026-07-11 15:04
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:02
2026-07-11 15:02
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















