




医疗视频理解大模型开源 精标测试集与评测平台发布

手术视频的“黑盒”,终于被一脚踢开了。
最近,GitHub和Hugging Face社区悄然上线了一个堪称医疗AI领域的“重磅冲击波”——全球规模最大、性能最强的医疗视频理解大模型uAI Nexus MedVLM(元智医疗视频理解大模型),宣布开源。
最令人惊讶的是,这个模型是真的能“看懂”手术。其相关论文已被CVPR 2026收录,研发团队还同步开源了一套包含6245个视频-指令对的标准测试集。这意味着,长期以来缺乏统一评测标准的医疗视频理解领域,终于有了一把“公共标尺”。如此大规模、高质量医疗视频数据的开源,在业内尚属首次。
实测表现:专业领域的“降维打击”
先来看看uAI Nexus MedVLM的基本面:它汇聚了超过53万条视频-指令数据,提供4B和7B两种参数规模,单张显卡即可部署。更重要的是,它整合了8个专业医学数据集,覆盖内镜、腹腔镜、开放手术、机器人手术、护理操作等几乎所有主流手术场景。
那么,它的实际表现究竟如何?
其演示界面设计得非常友好,核心模块清晰,支持直接上传手术视频文件进行测试。
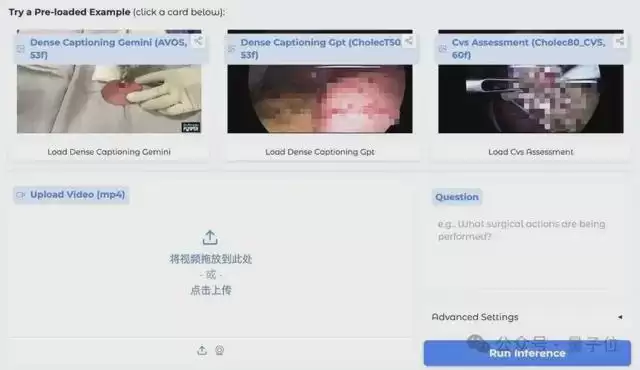
我们可以使用预置的腹腔镜胆囊切除术视频,从三个核心临床维度进行测试,并与GPT-5.4、Gemini-3.1等通用大模型进行对比。结果堪称“碾压”。
在手术安全评估任务上,uAI Nexus MedVLM的准确率达到89.7%。相比之下,GPT-5.4仅为16.4%,Gemini-3.1为24.2%,某国产大模型为30.9%。也就是说,其准确率是GPT-5.4的近5.5倍。
在时空动作定位任务上,其mIoU指标是Gemini-3.1的3.2倍,是GPT-5.4的47倍。在视频报告生成任务上(5分制),它拿到了4.24分,而其他模型均在4分以下。
经过MedGRPO强化学习优化后,相比基座模型,其器械定位能力提升了14%,手术步骤识别能力暴涨52%,手术描述质量提升16%到25%。

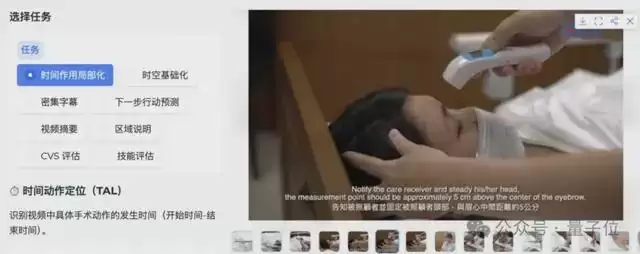
该模型覆盖了视频摘要、关键安全视野评估、下一步操作预测、技能评估等8个核心任务,在每一项上的表现均超越了通用大模型。
定性测试的结果同样震撼。例如,给出一段标记了绿色边界框的手术视频,并提问:“请描述0.0秒时边界框内物体的状态,以及在0.0~29.0秒时间段内的操作。”

标准答案是:“钳持续夹持并将胆囊向手术视野的左上方牵拉,提供反向牵引和暴露。”GPT-5.4只能给出笼统描述,未能识别具体器械;Gemini-3.1则错误识别为“电凝钩”;某国产大模型无法识别正确步骤。只有uAI Nexus MedVLM给出了接近标准答案的专业描述:“位于左上方的抓钳持续向上并朝中央牵引胆囊,保持张力并为钩子暴露分离平面。”
再看一个温和的示例:一段护士为患者监测生命体征的视频。模型需要完成“时间动作定位”任务,即回答“脉搏测量动作发生在什么时间?”标准答案是46.0-61.8秒。模型给出的预测是43.0-65.0秒,误差在数秒之内,且正确答案完全落在预测区间内。
为何手术视频是AI的“无人区”?
在AI医疗领域,影像辅助诊断、病历书写等应用已不新鲜。但手术视频理解,却长期被视为“无人区”。原因在于三重地狱级难度:
首先,数据获取极难。临床手术视频涉及患者隐私与医学伦理,获取门槛极高。即便获得原始视频,由专业医生进行逐帧标注的成本也令人望而却步。
其次,缺乏统一评测标准。过去,各家模型使用自己的私有数据集和评价指标,导致效果无法横向比较,严重阻碍了技术迭代与产业落地。

最后,任务本身极端复杂。手术视频理解要求AI在空间上精准识别毫米级的器械与解剖结构,在时间上理解不可逆的操作流程,在语义上掌握高度专业的医学知识。任何一环的缺失,都会导致模型失效。
从技术突破到临床价值
uAI Nexus MedVLM的突破,远不止于技术指标的领先。它的核心价值在于切实的临床落地场景。
在术前阶段,它可以分析海量历史手术视频,挖掘临床规律,为外科医生优化手术方案提供数据支持。想象一下,一位年轻医生在开展复杂手术前,能获得由AI总结的、来自上万台顶级专家手术的“经验大脑”辅助。
在术中,它可以实时分析视频流,在分离关键结构、显露安全视野等步骤提供指引,并对可能的违规操作或动作偏差进行毫秒级预警,成为主刀医生的“第三只眼”。
在术后,它能自动生成结构化的手术报告与总结,将医生从繁重的文书工作中解放出来,同时将本次手术的经验沉淀下来,成为后续手术的决策参考。
这对于医疗资源分布不均的现状尤其有意义。优质医疗资源往往集中于大型医院,基层医生成长缓慢。此类模型有望将顶级专家的手术经验“标准化”和“可复制化”,让基层医生也能获得高质量的术中智能辅助。
开源生态:开启全球协同新范式
此次发布最深远的影响,或许不在于模型本身,而在于其开创的开放模式。模型背后的联影智能,首次向全球开源了大规模高质量医疗视频标注数据、模型及一个统一的评测基准。
这相当于为手术视频理解这个垂直领域,建立了一个“全球公共测评体系”。从此,不同模型的优劣可以在同一把尺子下衡量,技术发展有了清晰的参照坐标。
不仅如此,团队还同步上线了医疗视频理解大模型公开榜单,向全球开发者发出挑战。
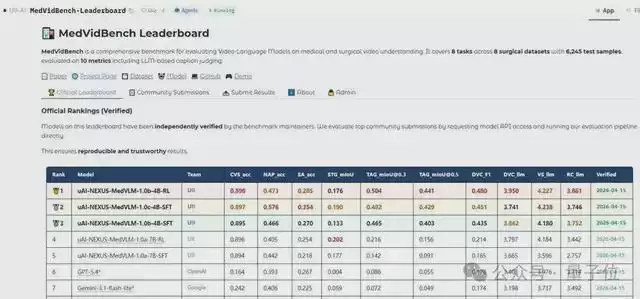
开发者可以提交自有模型的测试结果,系统将基于标准自动评分并生成动态排行榜。这种开放竞赛的模式,能极大加速技术边界的拓展。尤其是医生在实际应用中提交的、模型表现不佳的复杂罕见病例视频,将成为驱动技术持续迭代的宝贵燃料。
从数据开放、模型共享到全球协同,医疗视频AI正迎来一个黄金时代。未来,这类技术将与具身智能结合,完善从感知、推理到执行的闭环能力,并从手术室拓展至更广泛的临床场景,推动医疗全流程的智能化变革。这条路,才刚刚开始。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

别克携全系车型亮相北京车展 定义未来出行舒享新体验
2026北京车展的聚光灯下,别克品牌以一场“至境·至新——至境品牌进化日”发布会,清晰地勾勒出其在新能源赛道的全新版图。三款新能源车型——至境E7、至境世家与至境L7首次以完整阵容同台,而全球首发的“至境移动空间智慧体”概念车,则如同一份宣言,标志着别克正式驶入了一个以“舒享”为核心竞争力的全新时代

谷东科技参展2026上海VRAR博览会展示智能穿戴方案
5月14日至15日,备受瞩目的2026中国上海VR AR产业博览会在上海隆重开幕。作为AI眼镜产业链上游的核心光学技术供应商,谷东智能科技有限公司携旗下多款AI+AR创新产品与前沿技术成果重磅参展,全面展示了公司在消费级AI眼镜、行业级AR解决方案以及空间计算领域的最新战略布局与研发突破。 当前,随

DeepSeek-V4模型上线 OpenClaw平台已默认启用
能用DeepSeek-V4“养龙虾”了!这并非一句玩笑,而是今天凌晨OpenClaw平台更新带来的实质性功能升级。 4月26日最新消息,OpenClaw正式发布了2026 4 24版本更新。此次版本迭代的核心亮点,在于全面接入了DeepSeek-V4系列的两款高性能模型,并将DeepSeek-V4-

AI Agent安全护栏解决方案与风控实践指南
随着AI Agent在办公协同、客户服务、企业运营等真实生产场景中的加速落地,一个核心挑战也愈发受到关注:如何确保这些具备自主决策与行动能力的智能体始终“行为可控、安全可靠”? 针对这一关键需求,深圳深知智新技术有限公司旗下的深知安全风控团队,于5月14日正式推出了其解决方案——AI Agent安全

蚂蚁百灵Ring-2.6-1T模型发布:双档推理技术如何提升智能效率
2026年5月15日,蚂蚁集团百灵大模型正式开源其万亿级旗舰推理模型——Ring-2 6-1T。这款专为复杂真实任务场景设计的大模型,现已全面向开发者、研究机构及企业开放,支持验证、适配与深度二次开发。目前,模型权重文件已同步上线Hugging Face与ModelScope两大主流开源平台。此前,








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
