




DeepSeek-V4延迟发布原因揭秘性能报告深度解析

昨日,AI领域迎来了一场备受瞩目的技术盛宴。DeepSeek-V4技术报告的发布,以其近60页的详尽篇幅,从模型架构、训练流程到后训练细节全面公开,其技术透明度在业界实属罕见。
从V3到V4的迭代,历时长达484天。相比之下,V2到V3的升级仅用了不到8个月。这多出近一倍的时间,究竟投入何处?深入研读报告后,答案清晰指向了硬核的工程优化与对“训练稳定性”的极致追求。可以说,V4真正值得关注的,不仅是其庞大的参数规模,更在于其在处理智能体训练、工程基础设施,尤其是应对“训练震荡”难题时所展现出的系统性解决方案与开放态度。
接下来,让我们深入解析DeepSeek-V4的核心技术架构与创新设计。
33T Token与万亿参数:挑战训练稳定性的极限
V4以“预览版”形式发布,距离上一代已过去484天。报告虽未直接解释这一漫长周期,但一组关键数据揭示了背后的挑战。

V3的预训练使用了14.8T的token,而V4的数据规模实现了翻倍:V4-Flash训练了32T token,V4-Pro更是达到了33T token。模型参数量也同步大幅增长,V4-Pro总参数量高达1.6万亿,V4-Flash则为2840亿。
数据与参数量的指数级增长,直接带来了训练稳定性难度的剧增。报告对此毫不避讳,明确指出了“训练稳定性挑战”这一核心难题。
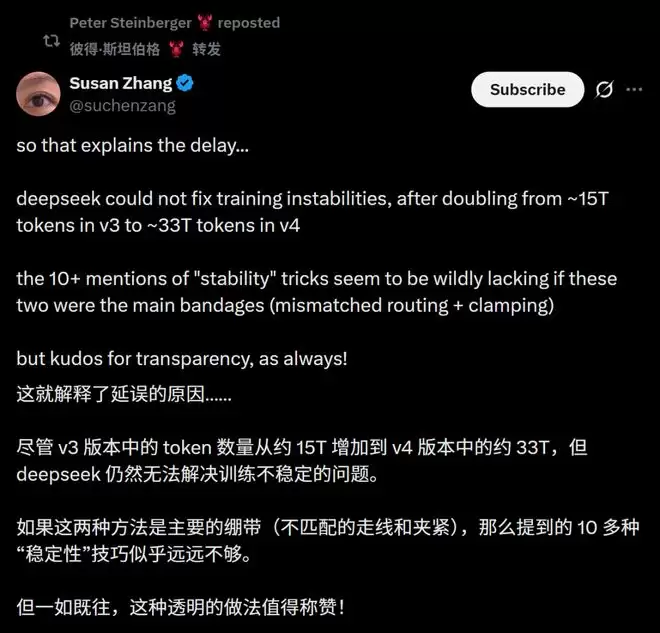
这种坦诚的态度甚至获得了谷歌DeepMind研究员Susan Zhang的公开称赞。在超大规模计算集群上,当模型规模和训练数据超越某个临界点后,硬件的任何微小误差都会被急剧放大。报告中,“稳定性”(stability)一词被反复提及十余次。在一篇聚焦技术细节的报告中,如此高频的出现本身就是一个强烈的信号——它从默认前提转变为了必须攻克的核心技术瓶颈。
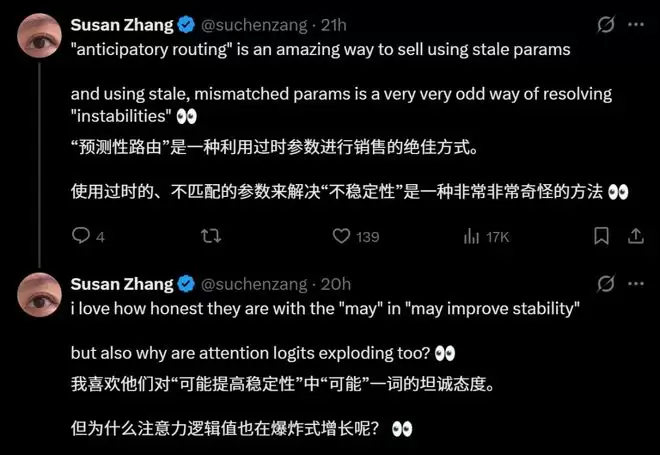
具体而言,DeepSeek团队发现,混合专家(MoE)层中的数值异常值会通过路由机制被不断放大,形成恶性循环,最终引发损失尖峰,导致训练曲线剧烈波动。为此,团队提出了两项关键的工程解决方案。
第一项是“前瞻性路由”。其核心思想是在路由阶段使用稍早版本的参数,将骨干网络和路由网络的更新过程解耦,从而有效打破两者间的负反馈循环。
第二项是“SwiGLU钳位”。该方法更为直接,通过将SwiGLU激活函数的输出值硬性限制在[-10, 10]的区间内,从源头抑制异常值的产生。这种方法看似“简单粗暴”,但实际效果显著。

当前,大语言模型的训练已进入硬件底层、编译器栈与数学架构深度融合的深水区。报告中有一个细节尤为引人深思:对于“前瞻性路由”和“SwiGLU钳位”这两种方法,DeepSeek确认其“显著有效”,但随即补充说明“其底层机理仍是开放性问题”。即便是像Q/KV归一化这样已被广泛验证的基础操作,报告的措辞也谨慎地表述为“可能改善训练稳定性”。一个“可能”,足以说明在训练万亿级参数的MoE模型时,没有任何技术是百分百确定的。

从15T到33T,数据量的翻倍带来的并非线性增长的困难,而是指数级放大的系统性风险。每一层网络的前向传播、每一次梯度更新、每一轮通信同步,都在更大的规模下转化为潜在的训练崩溃点。而DeepSeek选择将这一切挑战与应对策略悉数写入论文,这种程度的开源透明度,在业内尚属先例。
硬件瓶颈还是软件挑战?训练稳定性问题的根源探讨
那么,技术报告中明确提出的“训练稳定性挑战”,其根源究竟在于硬件平台还是软件栈?虽然报告未直接点名任何特定平台,但技术社区已展开深入分析与推测。
有观点指出,此类挑战很可能与底层算力平台本身相关,且这并非DeepSeek一家独有,各大AI厂商在训练超大规模模型时都可能遭遇类似问题。例如,xAI团队曾在一次分享中隐晦提及,适配最新的高性能芯片带来了“不小的工程挑战”,迫使团队重新开发底层硬件适配层,这或许也部分解释了其项目进度一度受到影响的原因。
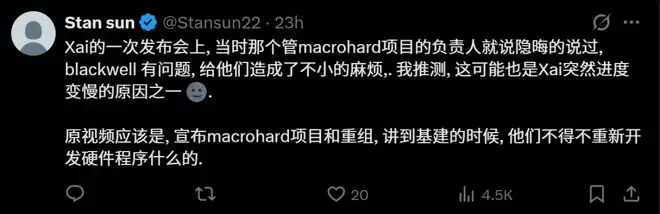
当然,问题的根源往往更为复杂。大型AI算力集群涉及众多变量:芯片设计、互联架构、散热系统、电力供应、驱动版本、编译工具链适配……训练不稳定未必直接等同于芯片缺陷,也可能源于系统集成层或软件栈的兼容性问题。目前,一切仍处于技术社区的探讨与猜测阶段。

智能体训练体系:展现教科书级的工程美学
如果说V4的预训练是在与硬件极限进行博弈,那么其后训练阶段则堪称展现了教科书级别的工程设计与审美。可以说,关于智能体能力的工程化实现路径,是V4论文中最具价值、最值得精读的部分。
以往普遍认为智能体能力是后期“教导”出来的,但DeepSeek的实践表明,智能体能力更应该是从底层“生长”出来的。

摒弃“硬迁移”:在预训练阶段注入智能体“基因”
行业内的常见做法是先训练一个通用的对话模型,再通过微调将其“硬迁移”为智能体。在DeepSeek看来,这种方式效率低下。在V4的中期训练阶段,团队就注入了海量的智能体交互数据。这意味着,模型在基础能力形成期,就已经接触过复杂任务链、环境反馈和文件操作模式。它在学会生成优美文本之前,就已经见识过Linux命令行的报错信息。这是一种从根本上重塑模型认知架构的设计哲学。
独创的“专家分阶段特训法”
另一大创新亮点是DeepSeek独创的专家分阶段特训法。V4并未直接训练一个“全能模型”,而是先分别独立训练出数学专家、代码专家、智能体专家、指令跟随专家等多个专项模型。这种分领域的深度特训确保了每个垂直领域的能力上限被充分挖掘。最后,再通过创新的“多教师在线策略蒸馏”技术,将这些专家模型的“知识精华”融合到一个统一的最终模型中。
此过程中的工程难点在于,同时加载十多个万亿参数级别的教师模型进行在线推理是不现实的。V4的解决方案颇具巧思:不缓存教师模型的完整输出(显存无法承受),只缓存其最后一层的隐藏状态,在训练时按需通过轻量级的预测头重建输出。同时,按教师索引对训练样本进行排序,确保每个教师的预测头在单次训练循环中只加载一次。KL散度的计算则使用专门为TileLang编写的高效内核进行加速,极大提升了训练效率。
超越传统奖励模型范式
此外,对于“难以量化评估”的复杂任务,传统的标量奖励模型已显得力不从心。为此,DeepSeek引入了“生成式奖励模型”。它不再简单地输出一个0到1的分数,而是能够根据预设的、细粒度的评估准则,生成结构化的详细评估报告。更关键的是,DeepSeek对GRM本身也进行了强化学习优化,让行动者网络同时扮演生成式奖励模型的角色,使得模型的评判能力与生成能力在同一个框架内实现协同进化与联合优化。
将智能体训练视为分布式系统工程
不仅如此,为了支撑如此复杂的训练流程,DeepSeek为V4专门自研了一整套底层系统。
DSec:生产级分布式沙箱集群
为了高效训练智能体的实际操作能力,DeepSeek搭建了名为DSec的专用平台。其核心的3FS分布式文件系统确保了海量训练数据的极速存取;支持数十万并发的高性能沙箱实例则意味着,V4在训练时,相当于有几十万台“虚拟计算机”在同步运行代码、测试程序、反馈结果。
MegaMoE:通信与计算一体化融合
在关键的MoE层,DeepSeek创新地将通信和计算过程融合进单个流水线内核,专家按波次进行智能调度,使得通信延迟被完全隐藏在计算过程之下。最终效果是,在通用场景下获得1.5到1.73倍的加速,而在对延迟极为敏感的强化学习展开等特定场景,加速比最高可达惊人的1.96倍。
自研DSML领域特定语言:确保工具调用可靠性
在工具调用接口方面,DeepSeek选择自行设计了一套类似XML但更精简的领域特定语言(DSML)。这套协议简单而高效,直接将工具调用的成功率和稳定性从“依赖概率”提升到了“工业级可靠”的水平。

推理努力分级模式训练
另一个体现工程精细度的设计,是V4支持多种不同的“思考”强度模式。“非思考”模式用于简单的工具选择或直接回答,响应速度极快;“高/最大努力”模式则针对长文档处理、复杂代码重构、疑难Bug排查等场景,全力投入推理算力。这种“该省则省,该花则花”的弹性策略,也是V4能够将综合成本控制在同类顶尖模型(如Claude)约四分之一的关键所在。
许多研究者在深入阅读这部分内容后感叹:“DeepSeek展现的工程实现能力,依旧扎实得令人叹服。”

跨轮次交错思考机制升级
V3.2在每个新用户消息到来时会丢弃之前的思考痕迹,而V4在工具调用场景下,能够保留完整的跨轮次推理历史。这使得智能体在处理长周期、多步骤的复杂任务时,能够维持一条连贯、持久的推理链,显著提升了任务完成的连贯性与逻辑性。当然,在普通的对话场景中,为了保持上下文简洁,仍会每轮清空,体现了良好的设计权衡。
性能的另一面:高达94%的幻觉率揭示的权衡
第三方分析机构Artificial Analysis的独立实测,为我们提供了一个更为立体的性能全景图。
在完成全面的Intelligence Index基准测试时,V4 Pro仅消耗了1071美元的成本,远低于Claude Opus 4.7所需的4811美元,性价比优势超过四倍。在体现实际工作能力的智能体基准测试中,V4 Pro Max在面向真实工作任务的GDPval-AA基准上取得了1554的高分,全面领先于当前一众开源模型。
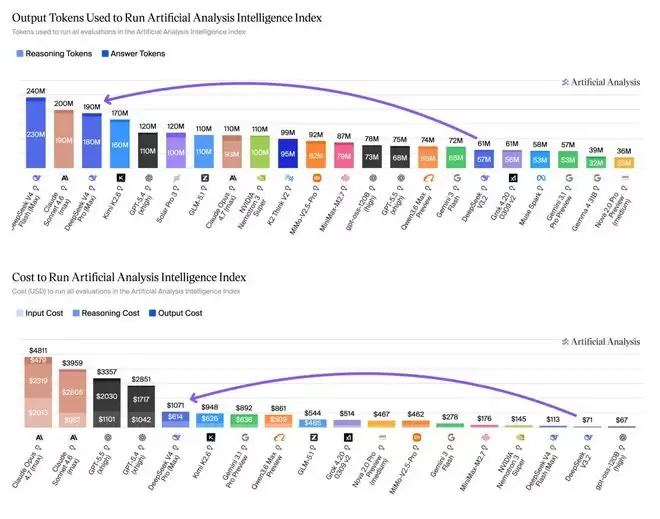
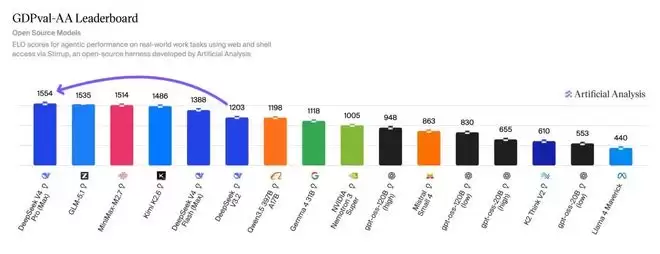
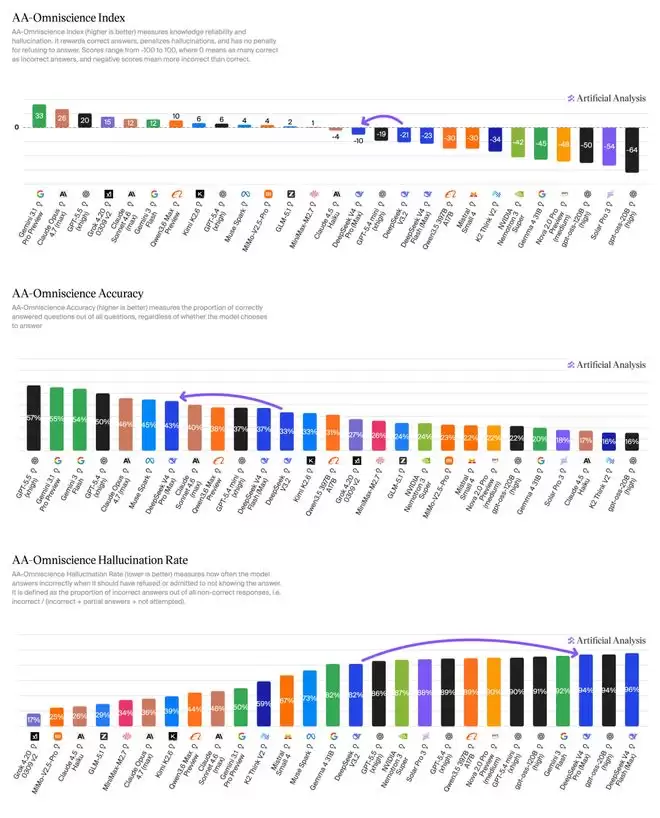
然而,天下没有免费的午餐。该报告也非常客观地指出了这种卓越性能背后的代价:V4 Pro在衡量知识准确性的AA-Omniscience基准测试中,幻觉率高达94%。

这揭示了大模型开发中的一个根本性困境:在有限的算力与成本预算约束下,若要逼近顶级模型的综合性能,就不得不在某些维度上做出战略性的取舍。DeepSeek的选择是将资源与优化重点全押在复杂推理和智能体执行能力上,而为此付出的代价,便是模型在事实性知识准确性上的相对弱势。
为何DeepSeek-V4依然值得尊敬?
在V4的技术报告中,有人看到了“训练不稳定”的挑战,有人注意到了“高幻觉率”的短板。但这份报告最打动人心之处,恰恰在于其前所未有的技术透明度。
团队敢于坦诚面对硬件适配过程中的阵痛,敢于详细披露那些看似“打补丁”但切实有效的工程解决方案,更敢于展示自己如何通过最硬核的系统工程能力,在数十万个并行沙箱中一点点锤炼出智能体的“灵魂”。从V3时代创新的多头潜在注意力机制,到V4的多教师在线蒸馏和DSec沙箱集群,DeepSeek正在用一种近乎偏执的“工程现实主义”,探索着大模型通向通用人工智能的另一条务实路径——如果模型架构尚未达到理论完美,那就用极致的工程把城墙砌得足够坚固;如果绝对算力成本高昂,那就用顶尖的算法将每一份计算资源的效率榨取到极致。
DeepSeek-V4或许不是通往AGI的终极答案,但它无疑是当前最真实、最硬核、也最充满探索精神的“中国AI工程实践”的杰出写照之一。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

吉利发布首款原生Robotaxi Eva Cab 千里科技AI全栈赋能
4月24日,在备受瞩目的第十九届北京国际汽车展览会上,吉利汽车集团正式揭晓了其重磅新品——中国首款原生正向开发的Robotaxi(自动驾驶出租车)原型车Eva Cab。这款车型不仅是前沿概念的展示,更是一款具备完整落地潜力的产品,其核心驱动力源自千里科技提供的全栈式Robotaxi解决方案。该方案深

Akamai与NVIDIA合作推动分布式AI推理从内容分发迈向智能分发
自2010年在中国设立团队以来,Akamai已深耕本地市场十六年。在服务中国企业出海的漫长征程中,其团队展现出卓越的稳定性与战略专注度。 回顾NVIDIA GTC 2026,其CEO黄仁勋曾预言,AI推理的规模将迅速达到训练负载的数十亿倍。进入2026年,行业共识已然明确:AI大模型竞争的焦点,正从

跑车品牌宣布暂停全面电动化转型计划
莲花集团发布“Focus2030”战略,宣布调整全面电动化路线,将同步发展燃油、混动及纯电车型,直至市场成熟。未来将推出燃油跑车Emira420,并于2028年上市搭载V8混动系统的超跑Type135,战略重心转向追求更高利润率。

大语言模型如何实现类人对话与思考的智能原理
我们每天都在与大语言模型(LLM)对话,一个直观的感受是,它们似乎真的“懂”我们在说什么,尽管偶尔也会“胡言乱语”。观察它们输出的思维链,那种逐步推理的语言痕迹,更让人觉得它们仿佛具备了某种思考能力。 这引出了一个核心问题:LLM的语言和思考能力,究竟是一种怎样的能力?这些能力又是如何通过其底层的实

ICML 2026论文解读:TGO标量反馈对齐视觉生成模型
生成模型的偏好对齐,可能正在进入一个新的阶段。 过去几年,大模型在训练后优化(post-training)最主流的方法,是让模型从“成对偏好”中学习。无论是经典的RLHF,还是后来更简洁的DPO,都绕不开同一个前提:反馈必须成对出现。 但在真实世界里,反馈往往不是这样。用户给一个结果打分、系统记录一








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
