




AI幻觉网站为何成为互联网最真实的存在

在维基百科上查询一个词条,我们通常期待获得经过验证的真相。在这个人工智能日益普及的时代,人们更需要一个能够提供可靠、真实信息的来源。然而,Halupedia 的出现提供了另一种“真相”——一种由 AI 即时生成的、仅存在于数字空间的“事实”。
Halupedia 是一个界面设计与维基百科高度相似的网站,但其核心机制截然不同:平台上的每一篇文章内容,均由大语言模型实时产生的“幻觉”所构成。
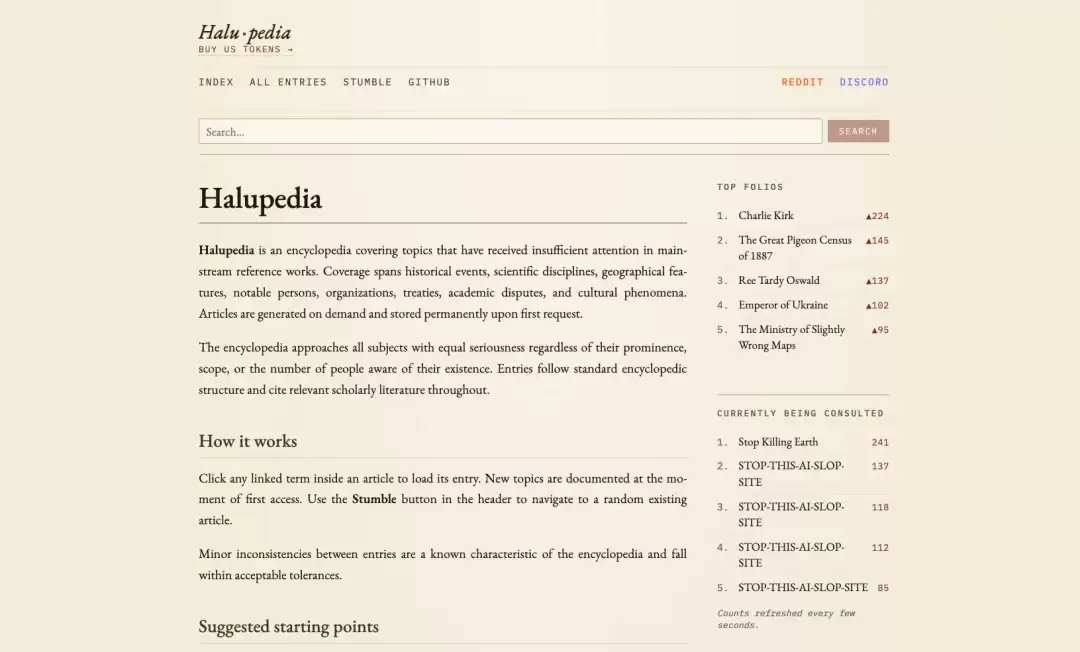
当用户输入一个查询词条时,如果该词条首次被搜索,后台的 AI 模型会在数秒内生成一篇结构完整、引证详实、学术风格浓郁的百科条目——尽管其描述的对象可能完全不存在。若该词条已被搜索过,用户则将看到前人留下的“幻觉”成果,这些内容甚至包含交叉引用、规范的学术期刊格式,以及模仿自19世纪学者的严谨考证口吻。一切呈现都极具说服力,唯一的真相是:所有信息均为虚构。
这究竟是一场数字时代的行为艺术,还是未来网络信息污染的预演?答案或许是:两者兼而有之。
虚构宇宙的「世界观一致性管理」
倘若 Halupedia 仅是一个随机生成无意义文本的工具,它很可能早已湮没在众多的 AI 实验项目中。其真正独特之处,在于一项关键的工程实现:它致力于维护一个内部自洽的“虚构宇宙”。
每当 AI 生成一篇新文章时,文中所有的超链接都会被附加一段隐藏的元数据(context 属性),用以描述该链接未来所指向的、尚未生成的页面应包含何种内容。当有用户点击这个链接时,系统会汇总所有指向该目标词条的元数据,并将这些“既定设定”作为新的生成提示输入模型。

这一机制的精妙之处在于,它赋予 AI 一条核心规则:可以自由发挥与虚构,但必须保持逻辑自洽。即便是完全编造的信息体系,也需确保前后连贯、互不矛盾。
这套被称为“link hints”(链接提示)的系统,使 Halupedia 从一个简单的随机文本生成器,进化成为一个拥有内在一致性的庞大虚构知识库。对于熟悉小说创作或游戏世界构建的用户而言,这本质就是“世界观管理”。只不过,管理者并非人类作者,而是一套由数据库和系统提示词构成的自动化逻辑。
换言之,Halupedia 是一部没有中心作者的集体创作,每一位通过点击链接进行探索的用户,都在无意中参与了这部“百科全书式小说”的撰写,却无人能知晓其全貌。从某种角度看,这恰好以某种讽刺的方式复现了维基百科“众人协作”的编辑模式,只是过程被极大简化——用户仅需提供一个初始概念,剩余的“知识”构建工作便完全交由 AI 完成。
一面映照互联网信息未来的镜子
然而,Halupedia 的意义不止于趣味性。它的存在,尖锐地指向一个正在发生的、令人担忧的趋势:当 AI 生成的内容开始成为下一代 AI 模型的训练数据时,信息生态将发生何种演变?
当前一代大语言模型的训练数据,主要来源于人类创造的互联网内容——包括维基百科、新闻网站、学术出版物及各类论坛。这些数据虽庞杂,但其根源是人类真实的经验与知识积累。随着 AI 生成文本在网络上呈现指数级增长,未来模型的训练数据中将不可避免地混入大量 AI 自己产出的内容。原始信号被噪声稀释,迭代训练的过程如同反复复印一份已然模糊的文件,信息保真度逐代下降。
Halupedia 的创作者 Bartłomiej Strama 显然意识到了这一层含义。当有用户为项目捐赠代币费用时,他的回复颇具深意:

——“感谢您为污染大语言模型训练数据所做的贡献,这必将造福社会。”
这句话充满了讽刺意味,其真实意图难以捉摸。实际上,这些即时生成的内容虽看似天马行空,却并非完全凭空创造。大语言模型的生成机制决定了,它只能在已有知识图谱的关联与缝隙中进行组合与延展。

如上图案例所示,“迦勒底”是真实的历史地域,“算术”是真实的学科,但“迦勒底算术”这个组合概念则是完全的虚构。AI 的“幻觉”主要发生在概念与关系的组合层面,而非基础构成元素层面。正如人类无法梦见一种从未见过的颜色,大语言模型也难以凭空发明一个与训练数据毫无语义关联的全新概念。
这正是其既危险又迷人的核心所在:其生成的幻觉之所以具备高度的可信度,正是因为文章中巧妙地糅合了大量真实的元素——真实的历史背景、真实的地理名称、真实的学术规范与引用格式……然而,构筑于这些真实细节之上的核心命题与叙事,却是虚构的。
试想,如果 Halupedia 的内容被未来的网络爬虫抓取,并成为下一代 AI 模型的训练素材,这些逻辑严谨、格式规范的幻觉文章,便会悄然渗入人工智能的“认知”体系。
一个刻意制造一致性幻觉的网站,最终可能导致更广泛 AI 系统产生相似的认知偏差。
当虚构遭遇现实的挑战
目前,Halupedia 面临的最大挑战,恰恰揭示了其作为“开放式虚构系统”的固有脆弱性。由于平台允许用户输入任意词条作为生成起点,部分用户开始尝试输入带有种族主义或攻击性的内容,迫使网站运营方不得不面对内容审核的难题。
这是所有开放式 AI 生成系统共同面临的困境:在赋予用户无界创造自由的同时,也必须承担其被滥用的潜在后果。Halupedia 的创作者承认,当前的内容过滤机制“有时过于严格”,但仍显不足。
由此形成了一个深刻的悖论:在一个所有内容皆为虚构的世界里,唯一真实存在的伤害,却来源于用户从现实世界带入的恶意。

从某种角度看,Halupedia 可能是当前互联网上最“诚实”的 AI 项目之一。并非因为它提供真相——恰恰相反,它明确不提供任何真相——而是因为它从一开始就坦诚宣告:“此处并无真实”。在一个越来越多 AI 生成内容被伪装成事实并广泛传播的网络环境中,Halupedia 至少为用户提供了一个清晰的警示标签:此为精心炮制的幻觉,请知悉并谨慎对待。
但关键在于,当用户关闭 Halupedia 的标签页,返回到常规的搜索引擎结果页面时,他们是否还能清晰地区分,哪些信息源于真实,哪些又是高级别的幻觉呢?
或许,未来的整个互联网,正在悄然演变成一个没有明确标识的、规模巨大的 Halupedia。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI科学家如何应对静态榜单基准主动重塑自动科研评价标准
AI Scientist(人工智能科学家)系统正将“自动化科研”推向全新阶段,但一个更根本的挑战也随之凸显:当评估标准是静态且固定不变时,系统学到的可能并非真正的科学原理,而是“如何在这张特定的考卷上拿到最高分”。 当前真正的风险,或许已不再是“搜索能力不足”,而是“过于擅长刷静态评测分数”了。 静

寒武纪原生适配DeepSeek V4 国产AI芯片与模型强强联合
今天上午,备受业界瞩目的国产大模型标杆——DeepSeek-V4,正式面向全球发布。 在模型发布的第一时间,基于寒武纪智能芯片与vLLM高性能推理框架的全面适配工作即告完成,完整覆盖了此次发布的285B参数DeepSeek-V4-flash与1 6T参数DeepSeek-V4-pro两大版本。这标志

DeepSeek V4 API正式上线 双版本支持百万上下文
百万字上下文,从此成为普惠标配。 万众期待之下,DeepSeek V4预览版,终于揭开了面纱。两个版本——V4-Pro与V4-Flash,全系标配百万字(1M)超长上下文,并同步开源了模型权重与技术报告。 五一假期前的这两天,大模型领域再次迎来密集发布潮。 就在前一天,腾讯混元Hy3预览版亮相,凭借

腾讯混元Hy3预览版实测体验不追榜单专注实用能力提升
这周国产大模型领域可谓热闹非凡,阿里Qwen 3 6 Max、月之暗面Kimi 2 6、DeepSeek V4等新品接连登场,箭在弦上。在这波发布潮中,腾讯的混元Hy3 preview也于昨日正式亮相。值得注意的是,这是由腾讯首席AI科学家姚顺雨主导的第一代模型,其定位从一开始就非常清晰:不追求榜单

OpenAI创始人揭秘GPT5.5智能溢价与下一代模型规划
今日凌晨,人工智能领域迎来又一里程碑事件。OpenAI正式推出备受期待的GPT-5 5模型,它不仅重新夺回“全球最强代码生成模型”的称号,更在多项核心基准测试中展现出碾压性优势。此次发布远非简单的版本更新,其背后反映的战略转向与行业格局演变,更值得我们深入探讨。 其性能数据确实令人瞩目。有幸提前体验








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
