




DeepSeek V4技术揭秘:梁文锋公开四大核心突破

今天,AI开源社区迎来了一颗重磅冲击波:DeepSeek-V4正式开源,并迅速登顶Hugging Face开源模型排行榜。与其一同发布的详细技术报告,毫不吝啬地披露了从华&为昇腾与英伟达芯片适配、模型架构革新到预训练与后训练优化的全链路细节,信息量极大,值得每一位关注大模型技术前沿的从业者仔细研读。
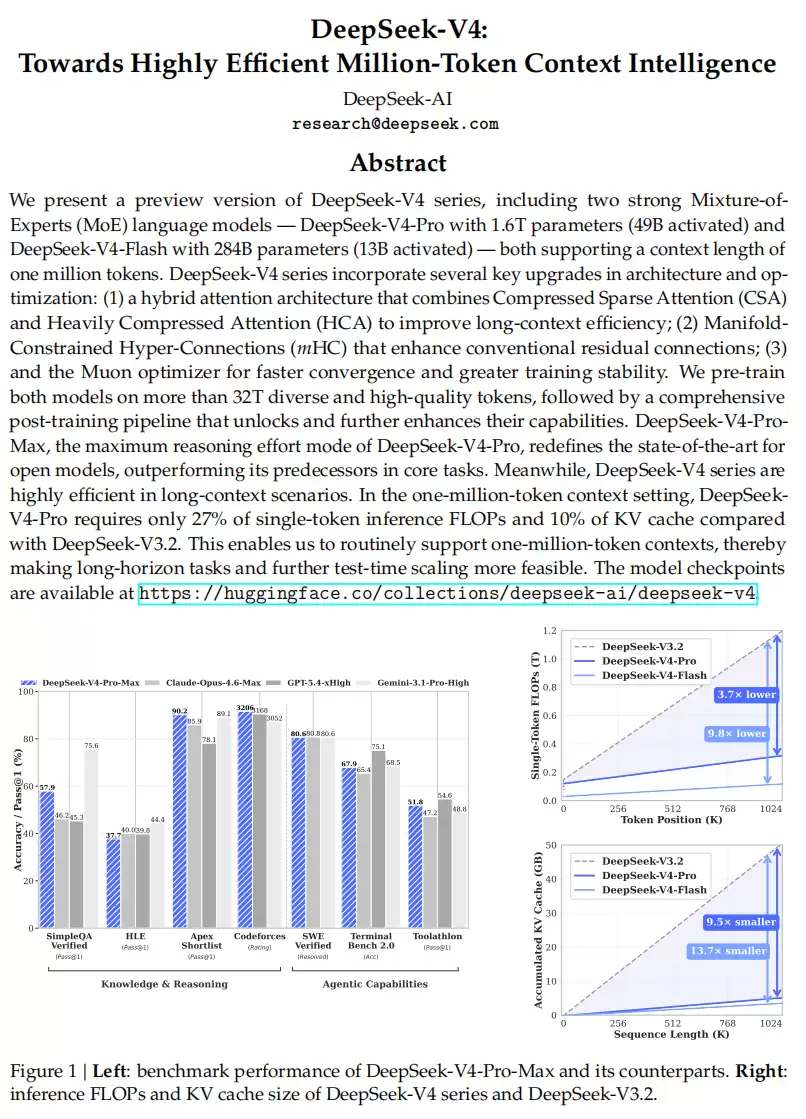
这次升级的亮点非常明确。一方面,模型在推理、知识、代码等核心能力上全线提升,整体表现已能比肩GPT-5.4、Claude Opus 4.6等顶级闭源模型。另一方面,一个更具碘伏性的变化是,DeepSeek-V4首次将“百万上下文”作为默认能力开放。在此设置下,单token推理的计算量相比前代V3.2暴降73%,而用于存储历史信息的KV缓存更是锐减至其10%,这意味着使用成本的大幅降低。
更值得关注的是基础设施层面的突破。从训练到推理的全链路,DeepSeek-V4已完整适配华&为昇腾NPU。其自研的细粒度专家并行方案“MegaMoE”,在英伟达GPU和华&为昇腾NPU上均能实现1.50至1.73倍的加速,为国产算力生态的应用提供了强有力的技术支撑。
训练过程的优化同样关键。在预训练阶段,DeepSeek-V4引入了“样本级注意力掩码”机制,使用的语料总规模超过32万亿tokens,覆盖数学、代码、网页文本及长文档等多种高质量数据。后训练阶段则做出了一项关键调整:用“基于策略的蒸馏”替换了原先的混合强化学习,使得训练过程更为可控,效果也更稳定。
一、基础设施再创新,全链路高效适配华&为昇腾
DeepSeek-V4在底层基础设施上的改进相当扎实。其核心依然是采用专家混合(MoE)技术,并通过专家并行化(EP)来加速计算。但问题在于,传统的EP方案对节点间的通信带宽和延迟要求极高,容易成为性能瓶颈。
为此,DeepSeek团队提出了一种名为“MegaMoE”的细粒度EP方案。其核心思路是将通信与计算整合到单一的流水线中,让两者能够重叠执行,从而有效缓解通信瓶颈。经过在英伟达GPU和华&为昇腾NPU两大平台上的验证,该方案在通用推理任务中实现了约1.50-1.73倍的加速,在延迟敏感的场景下,加速比甚至最高可达1.96倍。相关的CUDA实现已作为DeepGEMM的组件开源,名为MegaMoE2。
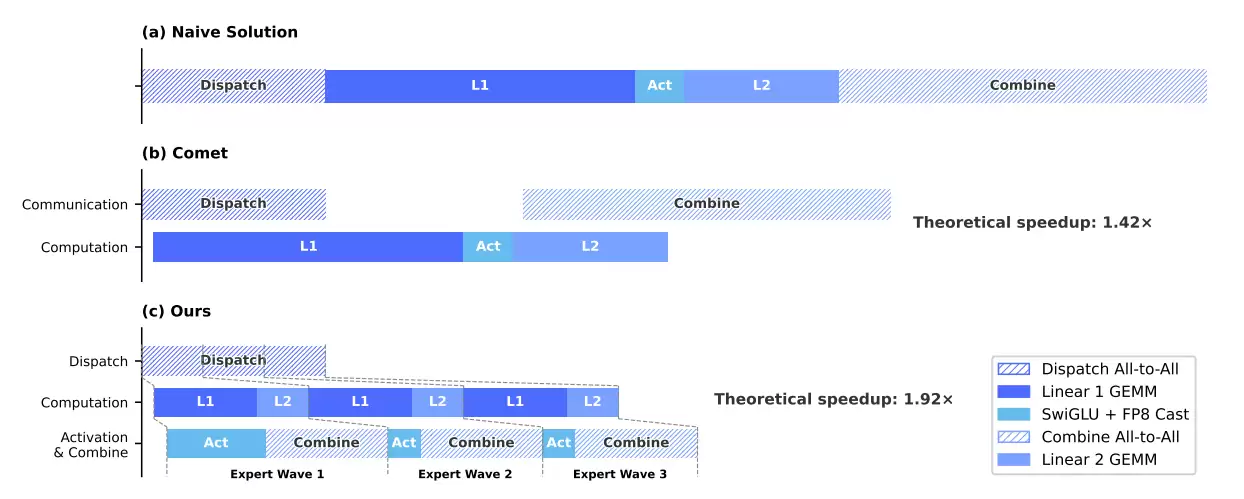
具体实现上,通过将专家调度与Linear-1计算重叠,将Linear-2与结果合并计算重叠,实现了更细粒度的计算优化。面对复杂模型架构产生的数百个细粒度运算符,团队采用TileLang开发了一套融合内核,将大量碎片化的小算子融合成大块,成功将调用开销从百微秒级压缩到1微秒以内。同时,引入Z3形式化求解器进行优化验证,确保了计算过程的比特级可复现性——这对大模型的调试至关重要。
在量化方面,DeepSeek将FP4(MXFP4)精度应用于两个关键部分:一是占用大量显存的MoE专家权重;二是压缩稀疏注意力(CSA)中索引器的Query-Key路径,在长上下文场景中加速注意力分数的计算。训练框架则在V3的基础上,引入了适配新架构组件(如Muon优化器、流形约束超连接mHC及混合注意力)的关键创新,保持了训练的高效与稳定。
二、架构升级,突破长文本计算效率瓶颈
随着推理模型的兴起,“测试时扩展”已成为提升大模型性能的新范式。但这一范式本质上受制于传统注意力机制,难以高效处理超长上下文和复杂推理任务。同时,从智能体工作流到跨文档分析,市场对超长上下文支持的需求日益迫切。尽管开源社区已有不少进展,但处理超长序列时的架构低效问题,始终是核心瓶颈。
DeepSeek-V4的答案是一系列架构创新,旨在将上下文长度真正推向“百万token”量级。总体来看,V4系列在继承Transformer架构和多Token预测模块的基础上,对V3进行了三项关键改进:一是采用结合压缩稀疏注意力(CSA)与高压缩注意力(HCA)的混合注意力架构;二是引入流形约束超连接(mHC)来增强传统残差连接;三是使用收敛更快、更稳定的Muon优化器。
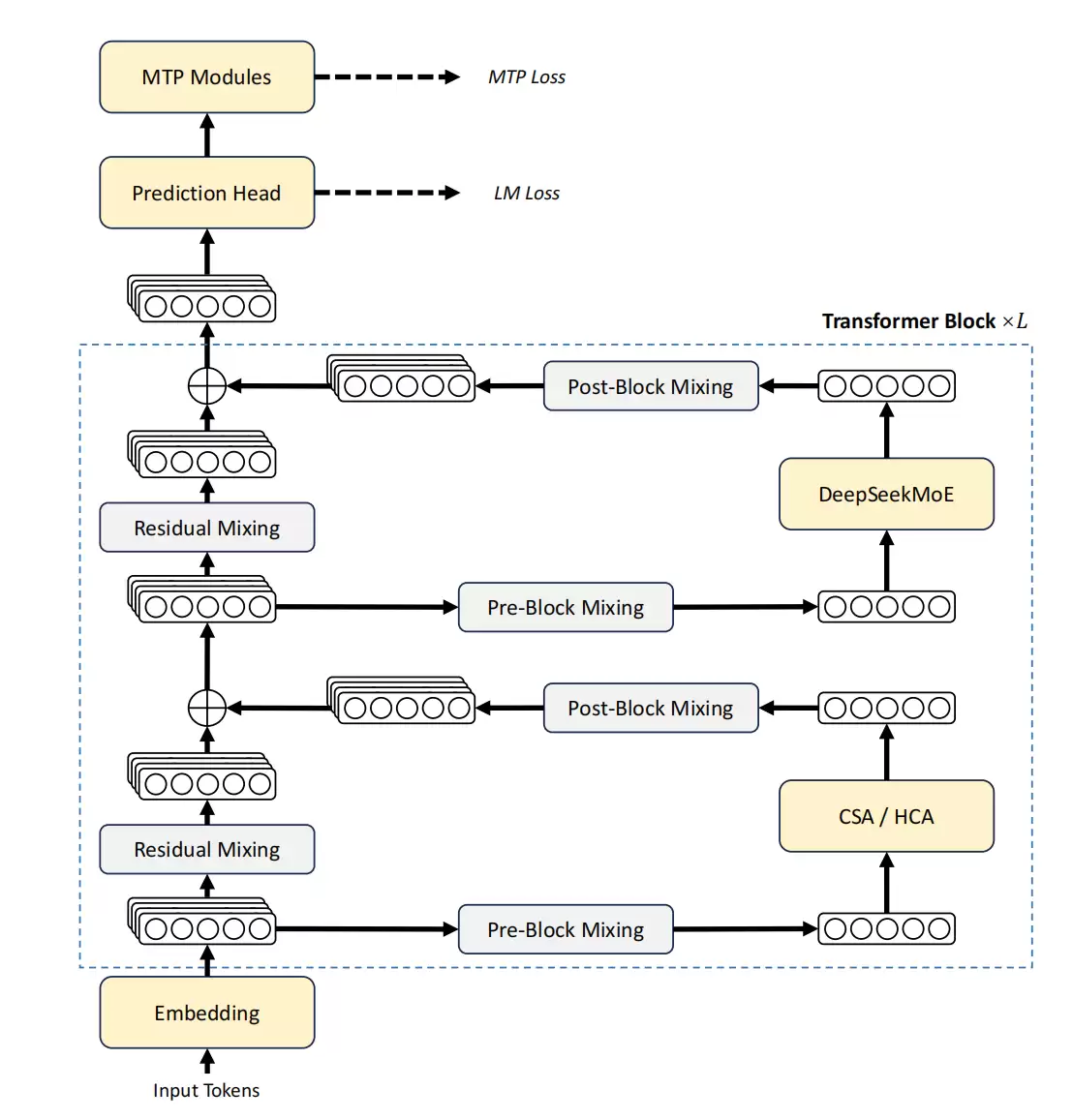
具体来说,模型保留了MoE结构和多token预测策略,改造的重点放在了注意力机制上。提出的“混合注意力”将两种压缩方式结合:一种先压缩再做稀疏注意力,另一种进行更激进的压缩但仍保持稠密计算。这种设计在保证信息利用率的同时,大幅削减了计算和存储开销。此外,改进的残差连接和新的Muon优化器,共同增强了模型表达能力和训练稳定性。
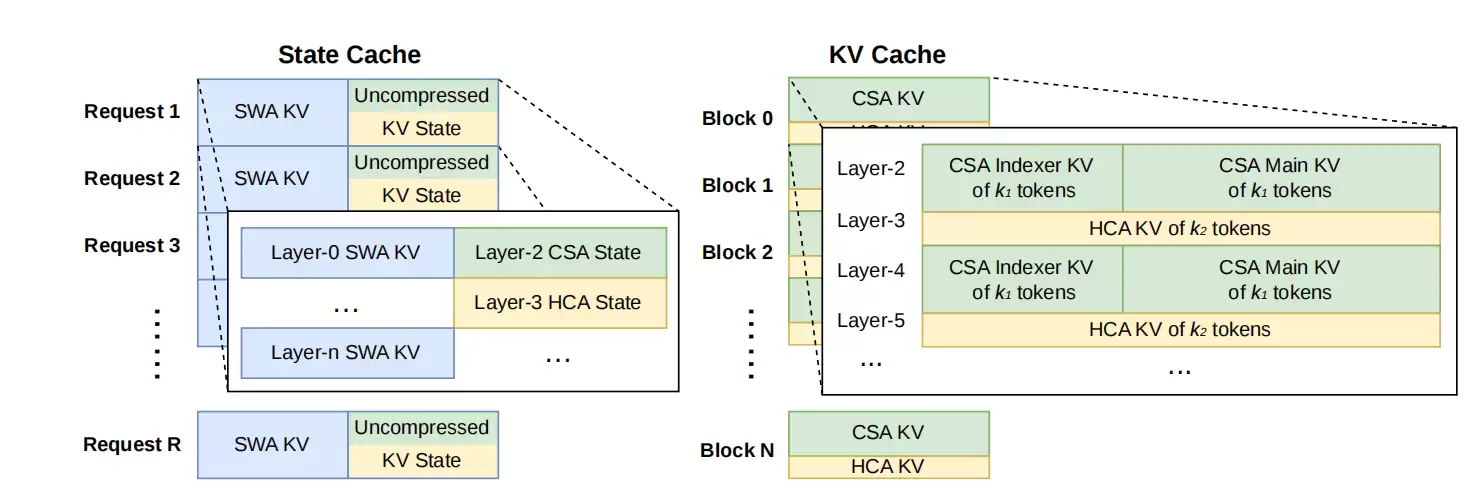
除了模型本身,DeepSeek在系统工程上也下了狠功夫。例如,将MoE的计算、通信和内存访问融合执行,用定制化语言优化内核,并确保计算过程可复现。推理阶段还设计了更复杂的KV缓存存储策略,甚至能部分利用磁盘,从而在支持极长上下文时避免内存溢出。
三、预训练:基础模型提升明显,Flash模型就已超V3.2
预训练数据主要基于DeepSeek-V3的语料库,并持续优化以构建更多样、高质量、有效上下文更长的训练数据。与V3不同的是,V4引入了“样本级注意力掩码”机制。对于网页数据,团队采用了过滤策略,去除了批量自动生成和模板化内容,以降低模型崩溃的风险。数学和编程语料仍是核心,同时在训练中期引入了智能体数据,以进一步提升代码能力。
在多语言数据方面,V4构建了更大规模的语料库,旨在增强模型对不同文化中“长尾知识”的理解。此外,团队特别强调了长文档数据的构建,优先收集科学论文、技术报告等材料。最终,预训练语料总规模超过32万亿tokens,涵盖数学、代码、网页文本、长文档等多个高质量类别。
基础模型的评估覆盖了四个关键维度:世界知识、语言理解与推理、代码与数学,以及长上下文处理。在统一的内部评测框架下,V3.2、V4-Flash和V4-Pro的基础模型表现如下。
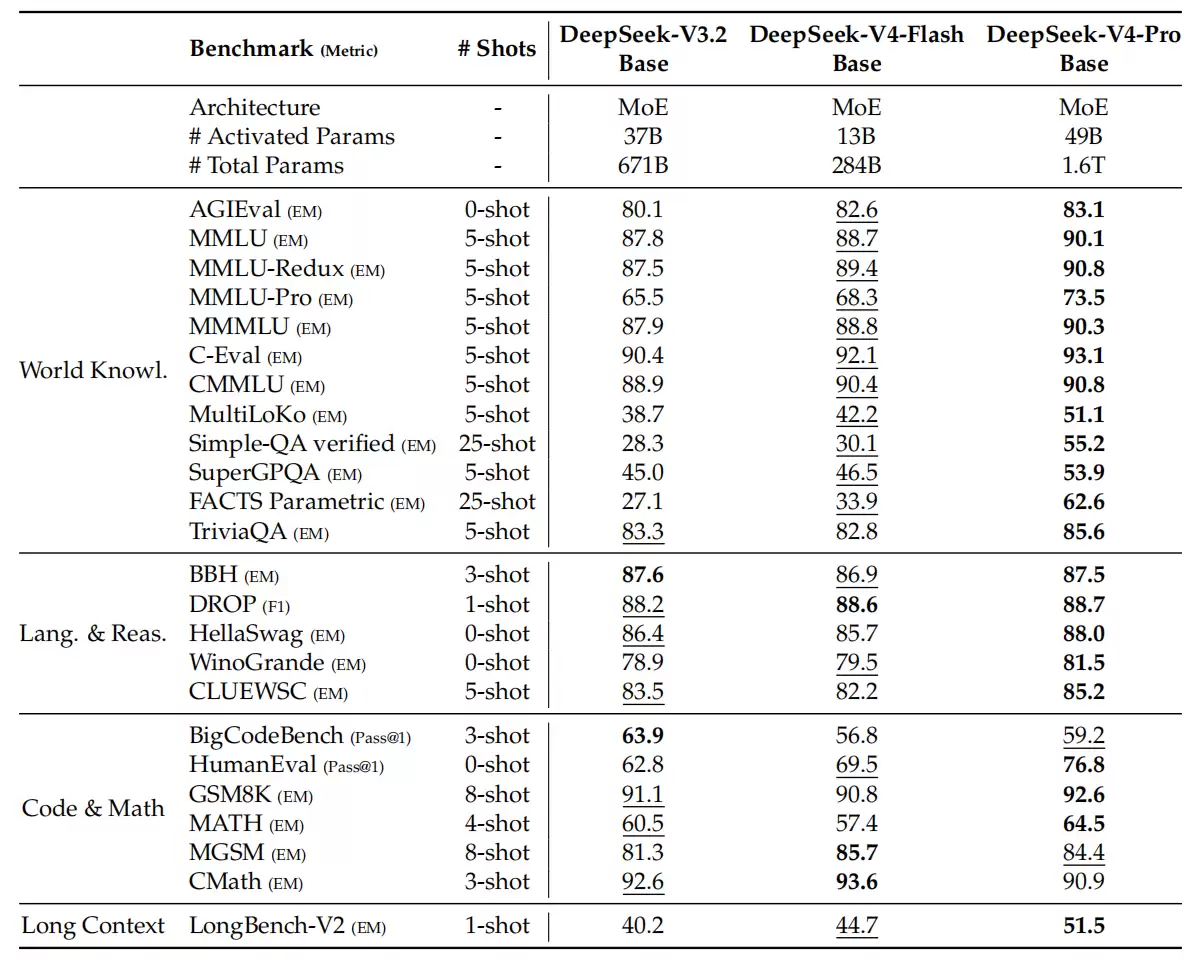
尽管DeepSeek-V4-Flash-Base的激活参数和总参数量都更小,但它在大量基准测试中超过了规模更大的V3.2-Base,这一优势在世界知识任务和长上下文场景中尤为明显。结果表明,V4-Flash-Base在更紧凑的参数预算下,实现了更强的性能。
而DeepSeek-V4-Pro-Base的能力跃升则更为显著,几乎在所有评测中都领先于V3.2-Base和V4-Flash-Base,刷新了DeepSeek基础模型的性能上限。其在知识密集型评测和长上下文理解能力上提升突出,在大多数推理和代码基准上也超越了前代模型,实现了知识、推理、代码和长上下文能力的全面超越。
四、后训练:基于策略蒸馏,跨轮次保留推理历史
预训练完成后,DeepSeek通过后训练得到了最终的V4系列模型。整体流程虽沿用V3.2的方案,但方法上有一处关键替换:原先的混合强化学习阶段被完全替换为“基于策略的蒸馏”。
具体操作分为两步。首先,针对每个目标领域分别训练一个独立的专家模型。每位专家都经过相同的流程:先用高质量领域数据进行监督微调,再使用GRPO算法进行领域特定的强化学习,从而得到十余位各有所长的“领域高手”。
关键的合并发生在第二阶段。不同于V3.2将各类数据混合进行强化学习(容易导致技能干扰),V4的做法是让一个统一的学生模型自行采样答题,在此过程中,由那十余位专家老师在完整的词表层面对其输出进行打分和校准,利用反向KL散度损失将学生模型“拉向”老师们的分布。这种方式能最大程度保留每个领域的专长。另一个重要细节是,V4坚持进行全词表蒸馏,这使得梯度更稳定、训练曲线更可控,当然,工程实现的难度也更高。
依托于百万token的上下文窗口,DeepSeek进一步优化了机制,以最大化智能体环境中多轮思考的效果。
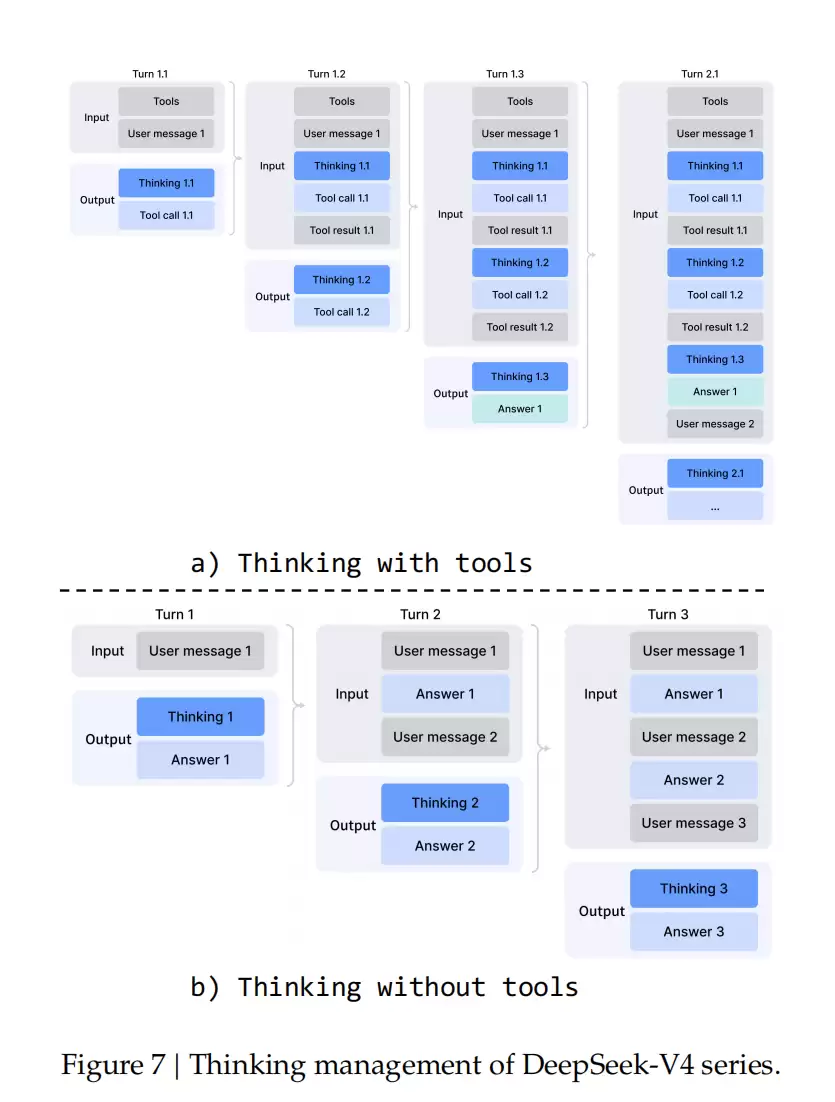
在工具调用场景中,所有的推理内容都会在整个对话过程中被完整保留。与V3.2每轮新输入就丢弃思考轨迹不同,V4系列会跨越所有轮次保留完整的推理历史,使得模型在长周期智能体任务中能够维持连贯且持续累积的思考链条。
而在一般对话场景中,V4则保留了原有策略:当新的用户消息到来时,会丢弃上一轮的推理内容,以保持上下文的简洁。需要注意的是,对于那些通过用户消息模拟工具交互的框架,可能无法触发增强的推理持久化机制。对于这类架构,官方仍然建议使用非思考模型。
五、知识、推理、代码三线抬升,开源模型逼近闭源上限
从最终的评测结果看,DeepSeek-V4-Pro-Max相比其他开源模型保持领先,部分能力已逼近闭源模型的天花板。
在知识能力和推理能力上,V4-Pro-Max在开源模型中略占优势,但仍稍逊于闭源模型Gemini 3.1-Pro。具体到推理能力,它优于GPT-5.2和Gemini-3.0-Pro,但落后于GPT-5.4和Gemini-3.1-Pro。而V4-Flash-Max则与GPT-5.2和Gemini-3.0-Pro能力近似,在复杂推理任务中展现出很高的性价比。
在智能体能力方面,V4-Pro-Max与Kimi-K2.6、GLM-5.1等领先开源模型表现相当,略逊于最前沿的闭源模型。在长上下文能力上,V4-Pro-Max在合成任务和真实应用场景中均表现强劲,在学术基准测试中甚至超过了Gemini-3.1-Pro。
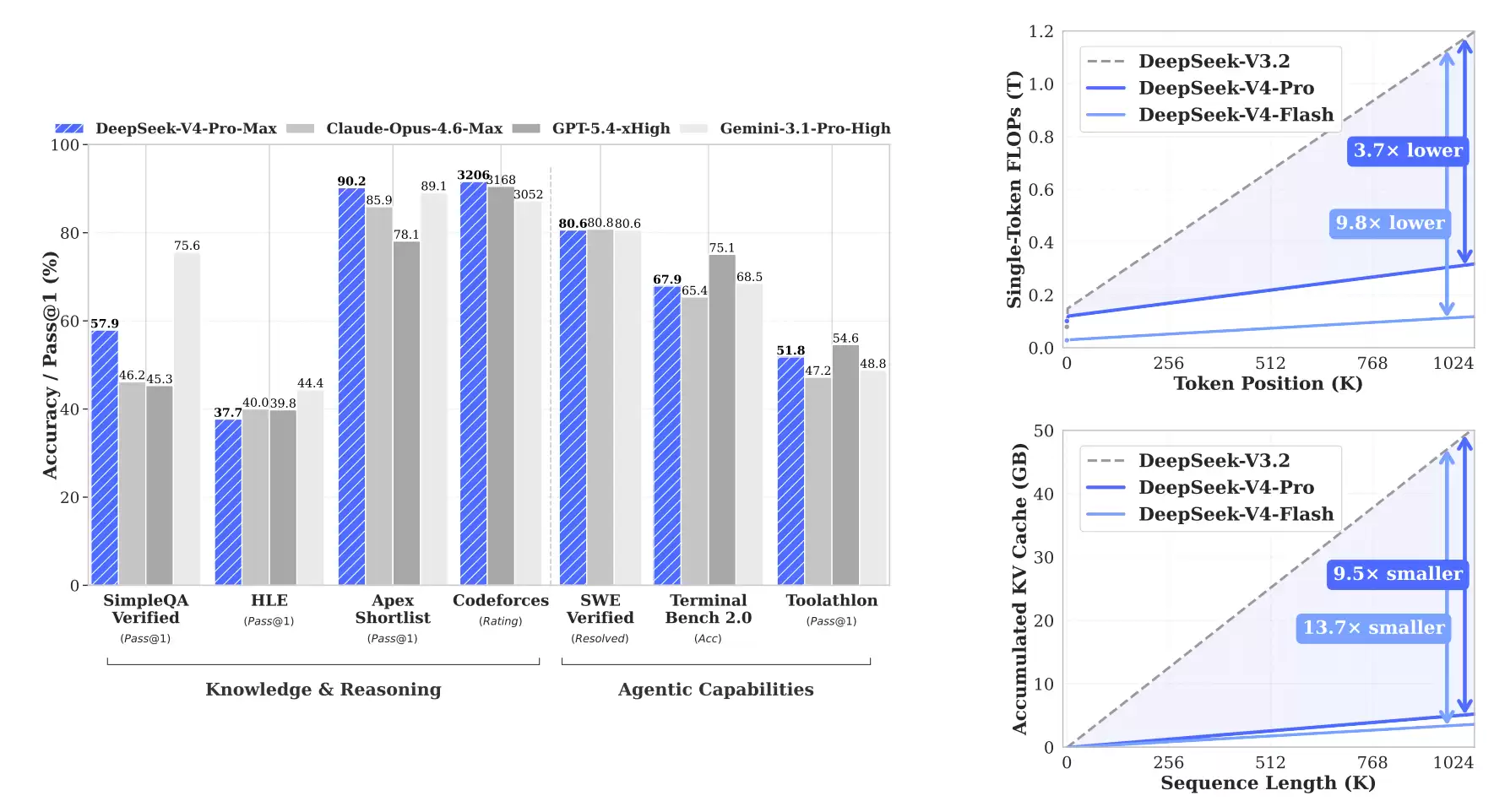
对比V4-Pro与V4-Flash,由于参数规模较小,V4-Flash-Max在知识类评测中表现稍弱。但当给予更多推理token时,其在推理任务中的表现可以接近V4-Pro-Max。在智能体评测中,V4-Flash-Max在部分基准上能达到与V4-Pro-Max相当的水平,但在更复杂、高难度的任务中仍略逊一筹。
结语:高效支持百万级token上下文,后续需简化架构
DeepSeek-V4系列预览版通过融合CSA与HCA的混合注意力架构,并结合系统级的基础设施优化,成功突破了超长上下文处理的效率瓶颈,为模型高效支持百万token级上下文奠定了基础。这为测试时扩展、长时序任务和在线学习等方向提供了新的可能性。
从评测结果看,DeepSeek-V4-Pro-Max在开源模型中表现突出,在知识、推理和智能体任务上均取得强劲结果,部分能力已接近前沿闭源模型。而DeepSeek-V4-Flash-Max则在较低成本下实现了强大的推理能力,性价比显著。
当然,V4的架构也相对复杂,部分用于提升稳定性的方法(如Anticipatory Routing和SwiGLU Clamping)其机理仍有待进一步理解。后续的工作预计将集中在简化架构、提升训练稳定性、探索更多稀疏化方向、降低长上下文推理延迟、增强多轮智能体与多模态能力,以及持续改进数据构建策略等方面。开源社区的探索,才刚刚开始。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI科学家如何应对静态榜单基准主动重塑自动科研评价标准
AI Scientist(人工智能科学家)系统正将“自动化科研”推向全新阶段,但一个更根本的挑战也随之凸显:当评估标准是静态且固定不变时,系统学到的可能并非真正的科学原理,而是“如何在这张特定的考卷上拿到最高分”。 当前真正的风险,或许已不再是“搜索能力不足”,而是“过于擅长刷静态评测分数”了。 静

寒武纪原生适配DeepSeek V4 国产AI芯片与模型强强联合
今天上午,备受业界瞩目的国产大模型标杆——DeepSeek-V4,正式面向全球发布。 在模型发布的第一时间,基于寒武纪智能芯片与vLLM高性能推理框架的全面适配工作即告完成,完整覆盖了此次发布的285B参数DeepSeek-V4-flash与1 6T参数DeepSeek-V4-pro两大版本。这标志

DeepSeek V4 API正式上线 双版本支持百万上下文
百万字上下文,从此成为普惠标配。 万众期待之下,DeepSeek V4预览版,终于揭开了面纱。两个版本——V4-Pro与V4-Flash,全系标配百万字(1M)超长上下文,并同步开源了模型权重与技术报告。 五一假期前的这两天,大模型领域再次迎来密集发布潮。 就在前一天,腾讯混元Hy3预览版亮相,凭借

腾讯混元Hy3预览版实测体验不追榜单专注实用能力提升
这周国产大模型领域可谓热闹非凡,阿里Qwen 3 6 Max、月之暗面Kimi 2 6、DeepSeek V4等新品接连登场,箭在弦上。在这波发布潮中,腾讯的混元Hy3 preview也于昨日正式亮相。值得注意的是,这是由腾讯首席AI科学家姚顺雨主导的第一代模型,其定位从一开始就非常清晰:不追求榜单

OpenAI创始人揭秘GPT5.5智能溢价与下一代模型规划
今日凌晨,人工智能领域迎来又一里程碑事件。OpenAI正式推出备受期待的GPT-5 5模型,它不仅重新夺回“全球最强代码生成模型”的称号,更在多项核心基准测试中展现出碾压性优势。此次发布远非简单的版本更新,其背后反映的战略转向与行业格局演变,更值得我们深入探讨。 其性能数据确实令人瞩目。有幸提前体验








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
