




上交创智瑞金联合发布CX-Mind胸片诊断进入可验证推理时代

胸片AI正迎来一次关键范式升级:其核心目标已从提供单一诊断结论,转向构建一条可供医生逐层复核的完整推理路径。
长期以来,医学影像AI主要扮演着高效“分类器”的角色,擅长回答“有无病变”或“疑似何种疾病”等封闭式问题。然而,真实的临床决策对AI提出了更深层次的需求——医生不仅需要一个答案,更需要一个逻辑清晰、证据确凿、可追溯的诊断思考过程。
近期,上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind多模态大模型,正是这一趋势下的里程碑式成果。它被业界公认为首个将胸片诊断推进至「可验证推理链」阶段的模型。这意味着,从识别影像异常、解释病理征象、进行鉴别诊断,到最终形成结论,模型的每一步推理都有对应的影像证据作为支撑,实现了诊断过程的可视化与可审查。

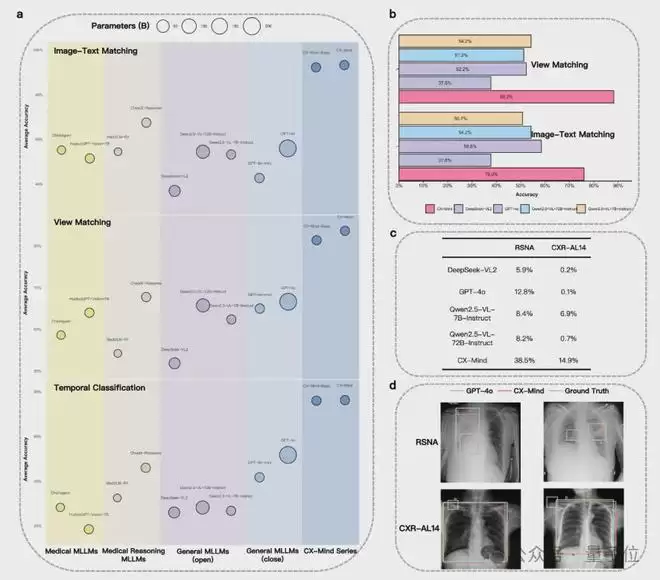
在涵盖23个数据集、总计708,473张影像的大规模评测中,CX-Mind在视觉理解、报告生成和时空对齐三大核心能力上,实现了平均25.1%的性能提升。尤为重要的是,在真实世界测试集Rui-CXR上,经过多中心医生的主观盲评,其在临床相关性、逻辑连贯性等五个关键维度上均位列第一。
为何这项研究至关重要:医学AI的核心矛盾正在转移
胸部X光片是临床应用最广泛的基础影像检查,自然也成为医学多模态大模型首要的落地场景。但该领域的挑战远不止于识别孤立病灶。真正的难点在于,如何将影像观察、病灶定位、共病判断、报告撰写、历史对比以及临床语义理解,无缝整合进一条连贯、完整的诊断逻辑链中。
这也正是过去许多胸片AI难以深度融入临床核心工作流的关键瓶颈。模型或许能输出一个高准确率的标签,但经验丰富的临床医生必然会追问:你的诊断依据是什么?考虑了哪些鉴别诊断?结论是否与影像上的具体发现(Findings)严格对应?如果出现误判,错误究竟发生在观察、鉴别还是总结环节?
CX-Mind旨在解决的,正是这个更深层次的“黑箱”问题。它的目标并非生成更冗长的思维链(Chain-of-Thought)文本,而是将医学推理过程结构化为一序列可解析的“观察-推断-回答”单元。每一步,模型都基于影像证据进行观察与推断,输出阶段性结论,再逐步推进至鉴别、定位、报告生成或病程评估等后续步骤。
换言之,CX-Mind将医学影像大模型的核心使命,从“提供答案”升级为“提供可审查的答案形成过程”。这使得模型不再是一个难以捉摸的“黑箱”阅片工具,而更接近于医生可以协作、追问与复核的临床推理伙伴。
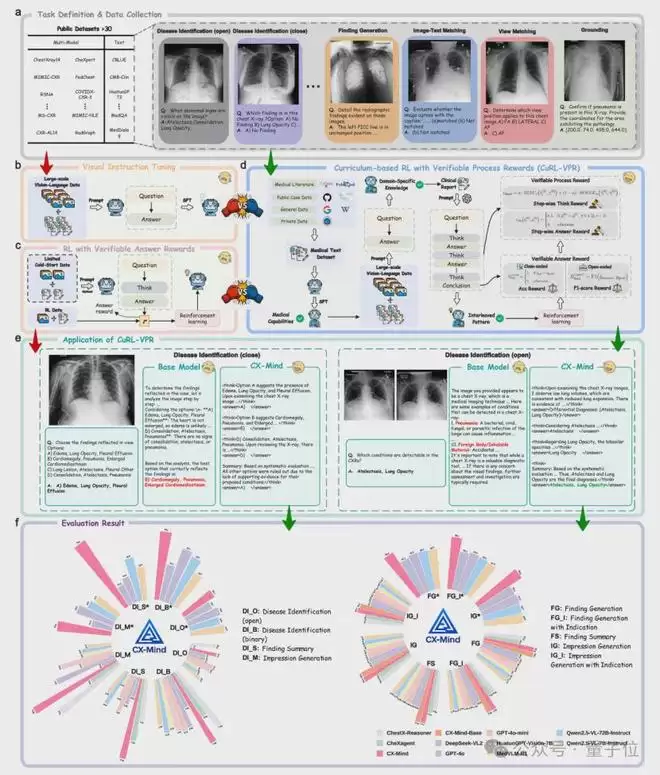
CX-Mind实现的三重核心突破
突破一:重构胸片大模型的输出范式
传统医学视觉模型多采用“端到端一次性判断”模式:输入影像,直接输出标签或整段报告。即便引入思维链,也常沦为一段难以验证真伪的长文本。这类解释看似完整,却难以区分哪些步骤真正源于影像证据,哪些仅是语言模型生成的“合理叙事”。
CX-Mind的关键创新在于其“交错式推理”机制。处理封闭式问题时,它会逐项评估候选答案,并给出保留或排除该答案的影像依据;处理开放式诊断时,则先提出疾病假设,再对每种假设进行证据核验,最终形成诊断结论。这种输出方式高度模拟了医生的真实阅片流程:观察征象、形成假设、鉴别诊断、撰写结论。
这项工作的突破性在于,它并非简单地为模型添加事后解释,而是将可解释性作为模型学习诊断能力时必须遵循的结构性约束。可解释性不再是附加功能,而是内嵌于训练与奖励机制的核心组成部分。
突破二:借CX-Set构建胸片专家能力图谱
要训练一个胜任复杂胸片诊断的大模型,仅靠疾病标签远远不够。为此,团队构建了大规模胸片指令数据集CX-Set。该数据集整合了23个公开胸片数据集,形成了包含708,473张影像和2,619,148条指令样本的庞大资源库,并进一步构建了42,828条由真实放射学报告监督的高质量交错式推理样本。
CX-Set的设计源于一个根本性问题:一位成熟的胸片诊断专家,究竟需要哪些核心能力?研究将其系统拆解为三大能力域:
- 视觉理解:用于疾病识别、单病判断及多病共存诊断。
- 文本生成:用于生成影像发现、印象及总结。
- 时空对齐:用于影像-文本匹配、拍摄体位识别、疾病进展判断及病灶定位。
因此,CX-Mind习得的远不止“标签识别”,而是一套完整的胸片诊断工作流:阅片、定位、比较、鉴别、总结、生成报告。这也使其相较于单一分类模型,具备了更显著的“基础模型”价值。
突破三:CuRL-VPR让强化学习同时约束答案与路径
医学诊断任务的强化学习难度极高。开放式答案空间复杂,疾病可能共存,医学表达也存在多种等价形式。更关键的是,最终答案正确,并不代表中间推理过程可靠。若只奖励最终答案,易导致奖励稀疏、功劳分配困难,并诱发模型产生“医学幻觉”。
CX-Mind提出了CuRL-VPR方法,即基于课程学习的、带有可验证过程奖励的强化学习。其核心思想是:从简单题目开始,逐步增加难度;训练时不仅评判最终答案是否正确,更用真实放射科报告核验模型每一步推理是否有影像证据支撑。
整个训练流程包括医学文本预热、大规模胸片指令微调、交错式推理冷启动,以及基于GRPO的课程强化学习。在奖励机制上,CX-Mind同时采用了格式奖励、最终结果奖励和过程奖励。这意味着,模型必须输出格式正确、结论准确,且其中间的“思考-回答”步骤需与真实放射学报告中的证据保持一致。
这标志着强化学习在医学场景中不再只关注终点,开始重视推理路径的质量。这对医疗应用至关重要:一个基于错误证据得出的正确结论仍不可接受,一段缺乏报告证据支撑的解释仍可能是模型的“幻觉”。
同时,CX-Mind采用了从封闭到开放的课程学习策略:先在二分类和选择题等封闭式任务上建立稳定、可验证的奖励机制,再迁移至开放式的诊断任务。这种训练节奏更符合临床任务的难度梯度,也使开放式医学推理的强化学习过程更加稳健。
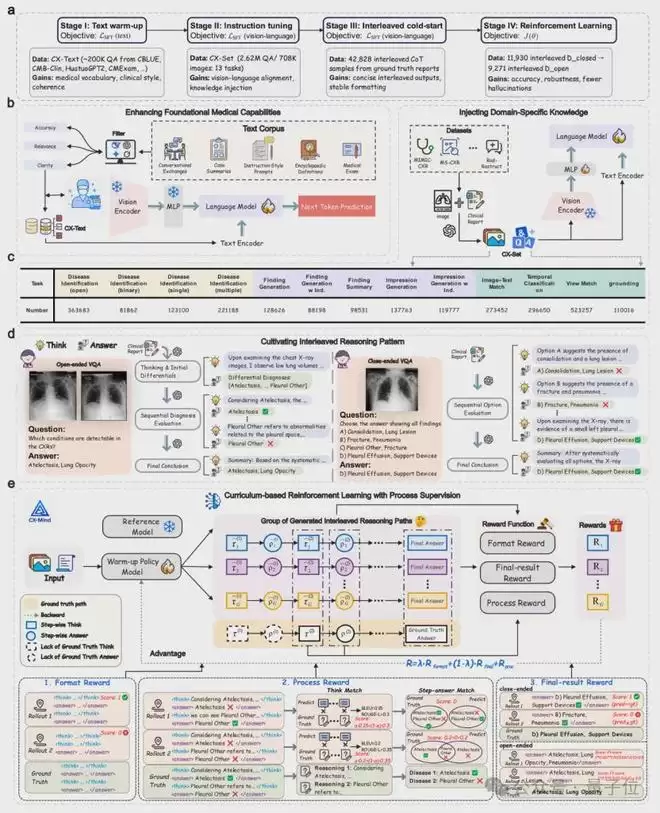
性能表现:越接近真实诊断,交错式推理优势越显著
视觉理解:在多病共存与开放式诊断中优势凸显
在二分类、单疾病识别、多疾病共存识别和开放式疾病识别等一系列任务中,CX-Mind整体表现领先。论文数据显示,相比其他胸片专用模型,CX-Mind在三大能力域上取得了25.1%的平均性能提升。在更贴近真实临床的复杂任务中,这一优势尤为突出。
在单疾病识别任务中,CX-Mind相比CheXagent和ChestX-Reasoner模型平均提升19.5%和21.0%;而在多病共存诊断中,相应的提升幅度达到了63.5%和21.2%。这表明,交错式推理的价值不仅在于优化简单分类,更在于当多异常、多证据、多候选诊断并存时,能帮助模型更稳定、可靠地完成临床鉴别。
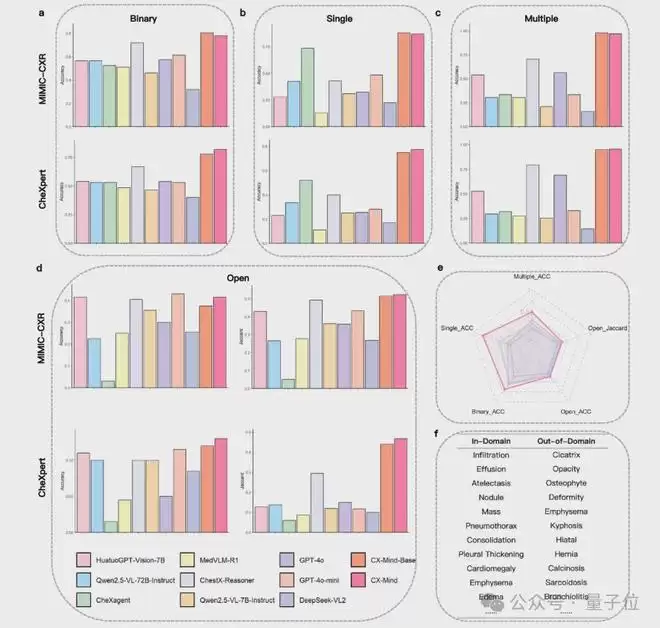
报告生成:从“识别异常”迈向“专业表达”
一个临床可用的胸片AI,不能仅输出疾病标签,还需将影像发现转化为规范、清晰、可供医生审阅修改的医学语言。CX-Mind在影像发现生成、印象生成和发现总结等报告生成任务中,取得了当前最优(SOTA)的表现。
与GPT-4o相比,CX-Mind在发现生成任务中,BERTScore高出1.6%,BLEU高出7.6%,ROUGE平均高出11.1%。在带有临床指征的发现生成任务中,BERTScore、BLEU和ROUGE平均分别高出3.6%、21.7%和22%。在印象生成及相关任务中,CX-Mind的BERTScore分别达到了90.3%和80.7%。
这意味着,CX-Mind不仅仅是“诊断更准”,还能够将影像证据准确地转化为与金标准报告语义一致的专业表述,为报告草拟、质量控制、教学培训及交互式问答提供了坚实的能力基础。
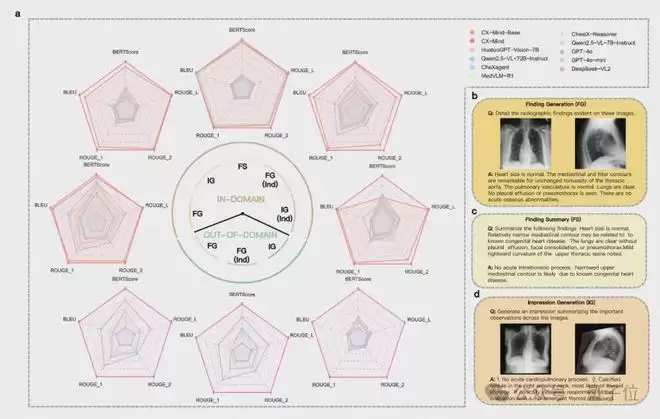
时空对齐:深度理解影像、文本、体位、时间与空间
真实的胸片诊断常涉及纵向比较与跨模态对齐。医生需要判断同一患者不同时间点的病变进展,也需要确认报告描述、拍摄体位和病灶位置是否一致。因此,CX-Mind将时空对齐能力作为其核心能力之一进行重点构建。
在影像-文本匹配和疾病进展判断任务中,CX-Mind相比最佳基线模型平均提升了25.8%和30.2%。在OpenI外部测试集上,其影像-文本匹配和体位识别准确率分别达到76%和88.3%。在RSNA与CXR-AL14外部定位数据集上,CX-Mind的平均交并比分别达到38.5%和14.9%。
这部分能力指向了更广阔的临床应用前景:随访比较、病程追踪、多模态病历整合,以及未来医学智能体对患者纵向健康状况的深度理解与评估。
真实世界验证:从公开数据集走向院内场景与医生评估
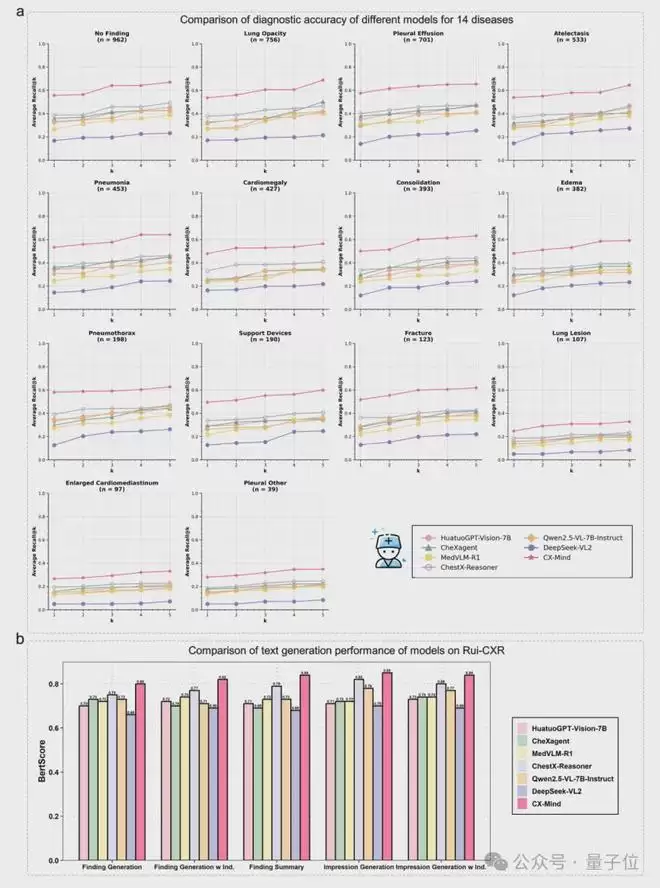
医学AI的最终价值,必须通过真实世界的严格检验。为此,研究团队构建了Rui-CXR真实世界测试集,其原始数据来源于上海交通大学医学院附属瑞金医院骨科在2018-2024年间采集的80,648名患者的标准后前位胸片及对应报告。经过脱敏、筛选和一致性验证后,形成了包含4,031张高质量胸片的测试集,覆盖了14种常见胸部疾病。
在Rui-CXR测试集上,CX-Mind在14种疾病诊断中均保持领先,平均召回率显著超过第二名模型。在真实世界报告生成任务中,标准发现生成的BERTScore达到0.80,带临床指征的版本达到0.82,较第二名模型平均提升约5%。
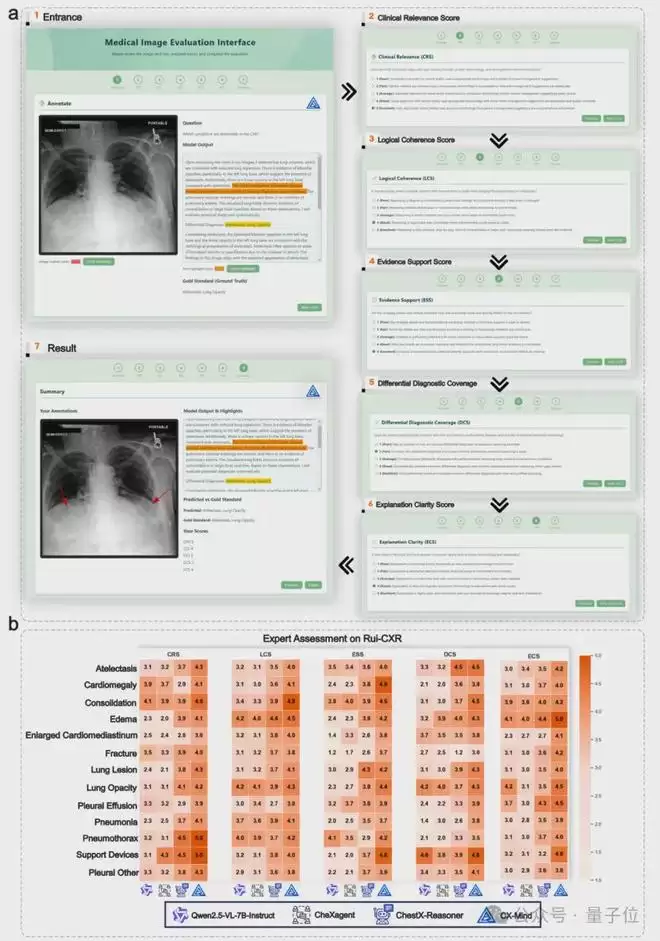
更为关键的是,团队邀请了来自多中心、不同资历层级的临床医生进行主观评估,评价维度包括临床相关性、逻辑连贯性、证据支持度、鉴别诊断覆盖度和解释清晰度。CX-Mind在所有五个维度上均获得了最高平均分。
这表明,CX-Mind的优势不仅体现在自动化评估指标上,更体现在医生能否真正理解、信任并有效复核模型的输出。对于医疗场景而言,可审查性本身就是临床价值不可或缺的核心组成部分。
更深远的影响:从胸片模型到医学智能体的基础能力
将CX-Mind置于医学AI发展的宏观图景中审视,其意义在于推动了一个关键范式的演进:从“医学视觉模型”走向“医学推理模型”,再进一步迈向“可被医生协作审查的医学智能体”。
这一设计思路有望迁移至更多医学影像乃至临床场景。例如,胸部CT的多癌种筛查需要模型在3D影像中分层定位病灶,并结合报告与病史进行鉴别;MRI诊断需要跨序列整合信息;病理分析需要高分辨率的区域级证据支持;而全流程的临床智能体,更需要在患者入院评估、检查解释、治疗建议和随访管理之间保持连续、一致的推理链条。
当然,走向真正的临床部署,仍需前瞻性研究、跨医院泛化验证、与医生工作流的深度集成、错误边界评估以及严格的监管审查。但从研究范式来看,CX-Mind已发出一个清晰信号:下一代医学AI的核心竞争力,将不仅是“诊断准确”,更是“推理清晰、证据可核、过程可协作”。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Perplexity Pages代码报错解决方法 沙箱环境预检与修正指南
Perplexity Pages生成的HTML代码运行报错?五步排查法帮你搞定 当你将Perplexity Pages生成的HTML代码下载到本地运行,浏览器却显示错误信息时,确实令人沮丧。请先别质疑自己的能力,这通常并非你的操作失误。AI生成的代码有时会遗漏Web开发中的一些必要规范,例如缺少标准

精准控制Claude输出格式的提示词技巧
想要精准控制Claude的输出格式,确保生成内容结构严谨、无冗余信息?这确实是许多开发者和内容创作者在利用AI辅助工作时遇到的核心痛点。Claude虽然功能强大,但有时其“自由发挥”的特性会导致输出包含不必要的解释或偏离预设框架。无需担忧,掌握以下五个核心技巧,就能像为Claude设定精确指令集一样

零成本接入ToClaw本地模型运行心跳任务方案
想在本地运行OpenClaw并接入自己的大模型,同时又不花一分钱维持心跳任务持续激活?核心思路很明确:绕开依赖云端API的默认心跳机制,充分利用本地已有的计算和硬件资源,实现自主唤醒。下面这几种方法,各有适用场景,你可以根据自己的部署环境对号入座。 一、基于FreeRTOS SysTick的裸机心跳

如何优化文章标题以提升搜索排名与点击率
调用Qwen-VL等多模态大模型时,账单费用偶尔会超出预算,这通常不是模型定价过高,而是图文联合输入产生的Token叠加效应所致。简单来说,处理一张图片加一段文本的成本,远高于两者单独计费之和。要有效控制Qwen-VL API调用成本,关键在于深入理解其计费机制并实施针对性优化策略。以下五个步骤,将

HermesAgent连接Telegram教程:手机端获取BotToken实现远程控制
必须先获取Telegram BotToken才能连接HermesAgent实现手机远程控制:一、通过BotFather创建Bot并获取Token;二、在HermesAgent配置中填入该Token;三、在手机Telegram中搜索并对话Bot验证连通性;四、启用控制权限、添加授权用户ID并绑定指令映








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
