




西湖大学张驰团队提出新方法无需重训即可生成长视频

长期以来,AI视频生成技术最令人惊艳的成果,往往只停留在开头的几秒。人物表情生动,光影效果逼真,动作流畅自然,这很容易让人产生一种错觉:AI生成高质量视频似乎已经触手可及。
然而,随着技术探索的深入,一个根本性的挑战愈发清晰:真正的难点并非创造几秒钟的惊艳片段,而是如何将这种高质量稳定地延续到更长的时长。一旦视频长度增加,许多模型便开始“失控”——人物、场景和动作在表面上看似延续,但细节开始漂移,时间线上的连贯性悄然断裂。
这正是当前AI视频生成领域面临的核心瓶颈。行业的关注焦点,已从“能否生成短视频片段”转向了“能否生成连续、稳定、且能承载完整叙事逻辑的长视频内容”。
设想一个厨房烹饪教程视频,镜头从备菜、下锅翻炒到最终摆盘,观众期望看到的是同一个厨房空间、同一套厨具和同一份食材被自然地串联起来。又或者一段城市街拍视频,人物从地铁站走出,穿过街道,镜头可以切换,但人物的衣着、步态、与环境的互动逻辑必须保持一致,不能越走越“散架”。
只有攻克了这种“长时序稳定性”的难题,AI视频技术才有望从技术演示走向真正的实用化创作与生产。也正是在这一背景下,西湖大学张驰团队的研究《Free-Lunch Long Video Generation via Layer-Adaptive O.O.D Correction》显得尤为关键和及时。
这项研究关注的,并非如何让单帧画面更加炫目,而是试图解答一个更本质的问题:为何模型在短视频生成中表现尚可,一旦生成长视频,质量就难以维持?正因为它精准击中了行业迈向下一阶段的核心痛点,这项研究不再是一次常规的指标优化,更像是在为AI视频从“短片段”迈向“长内容”的必经之路上,扫清了一个关键障碍。

视频越长,优势越显著
为了验证方法的有效性,研究团队在Wan2.1-T2V-1.3B模型上进行了系统性测试。他们将视频生成长度扩展至原始长度的2倍和4倍,结果发现,其提出的FreeLOC方法优势明显,且视频生成得越长,这种优势越突出。
首先看2倍长度(161帧)的生成结果。在衡量稳定性的关键指标上,FreeLOC表现卓越:主体一致性高达98.06,背景一致性达到97.49,运动平滑度达到98.98。这意味着在人物、场景和动作的时序连贯性上,它已达到或接近最优水平。
更亮眼的表现体现在画质相关指标上。图像质量得分达到68.31,显著高于直接生成(Direct)的60.34,也优于滑动窗口(Sliding Window)的64.64和FreeNoise的67.19。在美学质量上,FreeLOC获得了62.33的高分,而其他对比方法大多在52到56分之间,领先优势相当明显。动态程度得分39.41,也已接近最佳。可以说,在2倍长度下,FreeLOC实现了稳定性、清晰度与整体观感的全面领先。
当挑战升级到4倍长度(321帧)时,生成长视频的难度急剧增加,模型更容易出现内容漂移、画面模糊或动作失真。但实验数据表明,FreeLOC在这种更严苛的条件下依然表现稳健。
其主体一致性维持在98.44的高位。图像质量得分67.44,而直接生成的方法已降至59.21,差距拉大到8.2分。美学质量得分61.21,对比直接生成的49.43,优势扩大到11.8分。动态程度得分36.27,远超直接生成的4.32,几乎是数量级的提升。
这些结果清晰地表明,随着视频长度增加,许多方法的性能会急剧衰退,但FreeLOC依然能将画面质量和动态表现维持在较高水准。它的优势并非偶然,而是在高难度的长视频生成场景中依然稳固成立。
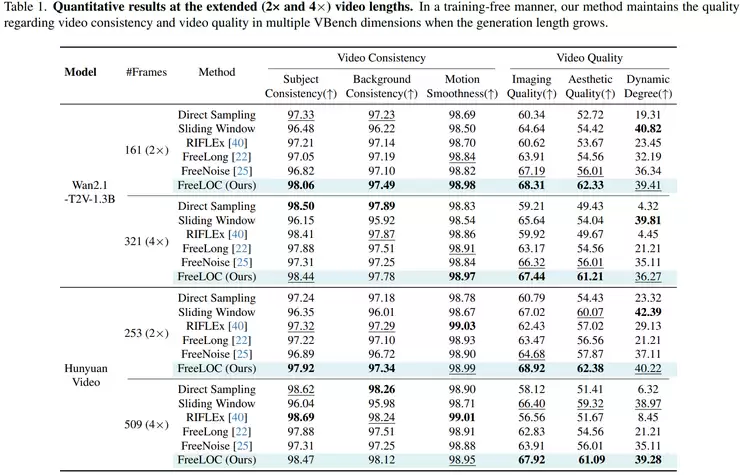
这种性能提升并非特定模型的“特权”。研究团队在另一个主流视频生成模型HunyuanVideo上进行了复现实验,趋势完全一致。在2倍长度(253帧)下,FreeLOC的图像质量(68.92)和美学质量(62.38)均为最高,主体一致性(97.92)也优于多数对比方法。
到了4倍长度(509帧),其图像质量(67.92)和美学质量(61.09)依然保持领先,动态程度(39.28)接近最佳。这充分证明了FreeLOC方法的跨模型通用性。
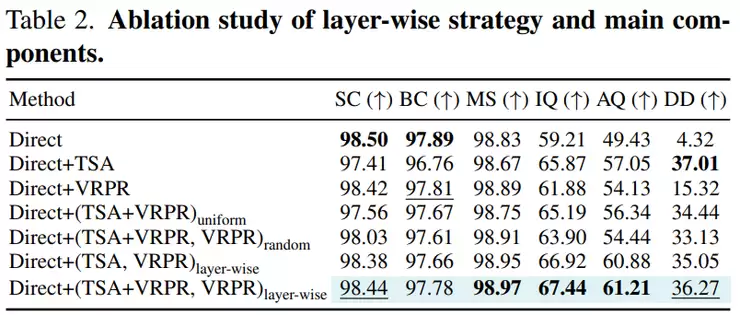
那么,这种显著的提升究竟源于何处?研究团队通过消融实验进行了深入剖析。单独使用其核心组件之一的时序敏感注意力(TSA)时,图像质量为65.87,美学质量为57.05,说明处理长上下文问题本身就能带来可见增益。单独使用另一组件视觉相对位置重编码(VRPR)时,图像质量为61.88,美学质量为54.13,表明单独修正位置问题也有效,但作用有限。
如果将TSA和VRPR简单叠加,但对所有网络层进行统一处理,图像质量是65.19,美学质量是56.34,虽优于单一模块,却并非最佳。更有趣的是,如果随机地将这些模块分配到不同层,图像质量反而会下降至63.90。这恰恰说明,模块本身并非“放之四海而皆准”。
关键在于“按层选择”。这正是FreeLOC的核心创新之一:根据Transformer每一层网络对不同问题的敏感度,进行差异化的处理。采用这一策略后,图像质量达到67.44,美学质量达到61.21,均为最高。性能的提升,不仅源于增加了新模块,更源于这种精细的分层适配策略。
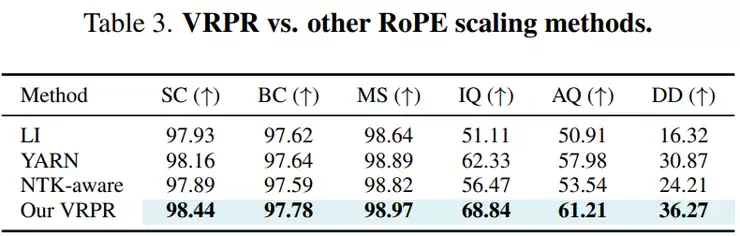
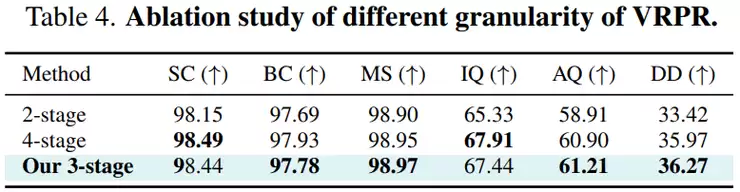
研究人员还进一步比较了不同的位置处理方式和注意力机制。在位置处理上,VRPR的效果(图像质量68.84,美学质量61.21)明显优于简单的截断(Clipping)或分组(Grouping)。这证明多粒度的位置重编码比粗暴的简化策略更有效。
在注意力机制上,TSA(图像质量68.84,美学质量61.21)也优于滑动窗口(Sliding Window)和选择性帧注意力(Selected Frame Attention)。这意味着,单纯的滑动窗口虽能控制计算量,却会损失重要的长程时序依赖信息,而TSA能在管理上下文长度的同时,更好地保留这些关键关联。
综合来看,这一系列实验清晰地表明,FreeLOC的优势并非来自某个孤立的技巧,而是源于一套协同的设计:更有效的位置编码、更智能的注意力控制,以及最关键的分层应用哲学。
结论是明确的:无论是在Wan2.1还是HunyuanVideo模型上,无论是在2倍还是4倍的长度设定下,FreeLOC都能同步提升生成视频的稳定性、清晰度、美感和动态表现。并且,生成任务越漫长、越困难,它的优势就越突出。
从实验设置到机制验证,步步为营
为了确保研究结论的可靠性与普适性,研究团队在实验设计上颇为严谨。他们选用了两个公开可用的主流视频生成模型——Wan2.1-T2V-1.3B和HunyuanVideo,以此验证FreeLOC是否具备跨模型的通用能力。
在生成阶段,输出分辨率统一设置为480p(832×480),并重点测试了将视频长度扩展到2倍和4倍后的效果。目的非常直接:观察模型在面临更长的生成任务时,能否守住画面质量和时序连贯性的底线。
对比基线也设置得相当全面,涵盖了当前主流的几种长视频生成思路:包括最基础的直接采样(Direct Sampling)、保证局部连贯的滑动窗口(Sliding Window),以及已有的无需训练的方法如FreeNoise、FreeLong、RIFLEx等。这样的对比足以清晰地勾勒出FreeLOC在现有方法丛林中的独特位置与优势。

评价体系采用了业界认可的VBench标准,并将指标分为“一致性”和“质量”两大类。一致性方面,关注主体一致性(人物是否变形漂移)、背景一致性(场景是否稳定)和运动平滑度(动作是否自然连续)。质量方面,则考察图像质量(画面清晰度)、美学质量(视觉美感)和动态程度(运动表现力)。这套组合拳确保评估不再局限于单一的“清晰度”,而是涵盖了从内容稳定到观感体验的多维标准。
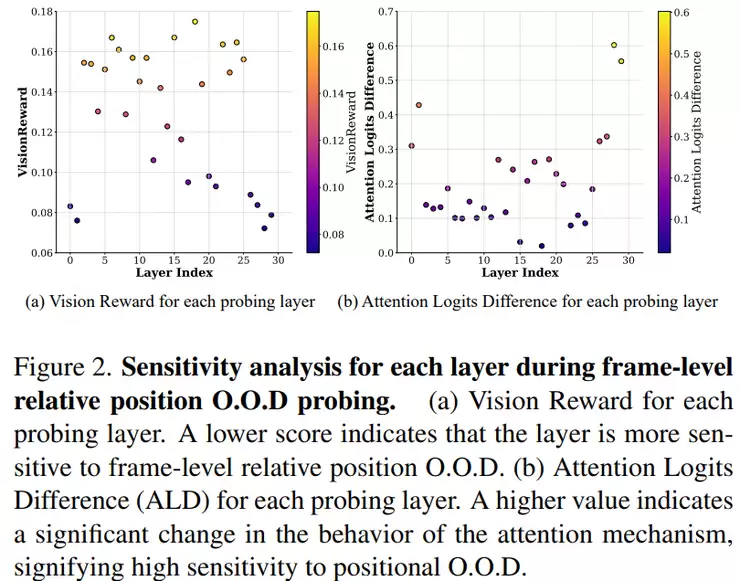
除了常规的性能对比,研究还进行了一项关键的“探测实验”——逐层分析Transformer。具体做法是对每一层网络施加微小的扰动,然后观察两件事:视觉质量下降了多少,以及注意力模式的变化有多大。
正是通过这个实验,他们发现了一个关键现象:不同的网络层对问题的敏感度截然不同。有的层更容易受到帧间位置关系变化的影响,有的层则对长上下文扩展更为敏感。这个发现为后续的分层处理策略提供了直接依据——不能“一刀切”,必须“因层施策”。
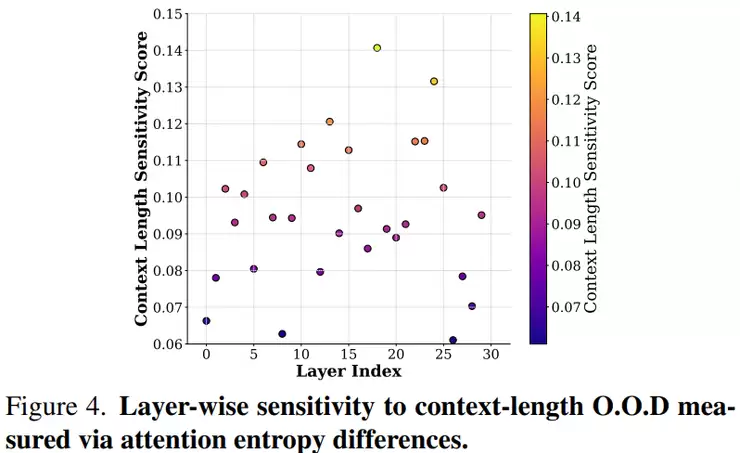
研究还专门验证了两类核心的“分布外”(O.O.D)问题。第一类是位置O.O.D,通过改变帧之间的相对位置关系,观察生成质量是否下降。第二类是长度O.O.D,通过直接增加视频长度,计算注意力熵(分散程度)。实验表明,视频越长,注意力就越分散,而注意力越分散,生成质量通常就越差。
正是基于对这两类问题根源的深入剖析,研究团队才系统地提出了VRPR(应对位置O.O.D)、TSA(应对上下文O.O.D)以及最终的分层适配策略。可以说,这部分工作的价值在于,它没有停留在结果对比,而是深入机制,先拆解问题根源,再有的放矢地设计解决方案。
从「能生成」到「能使用」的关键一步
这项研究的价值,远不止于提升了几个技术指标。它的深层意义在于,为长视频生成的顽疾提供了一个机制上的解释。研究团队指出,长视频之所以容易出现画面模糊、动作断裂、人物失稳等问题,根源在于两类O.O.D问题:位置O.O.D和上下文O.O.D。
这个判断至关重要。它意味着,过去许多方法可能只是在技巧和参数上做文章,而这项研究开始将问题推向机理层面。它不仅给出了一个更优的解决方案,更解释了旧方法为何容易失效,以及视频变长后模型为何会“失控”。
另一个颇具实用价值的贡献是,它证明了“重训练”并非唯一出路。以往提到生成长视频,一个常见的思路是必须重新训练模型,或者进行繁重的额外训练,因为为短视频设计的模型很难直接处理超长的时序依赖。
而这项研究表明,仅在推理阶段进行精细化的修正,就能显著改善生成效果。这一点非常关键,因为它大幅降低了算力成本和部署门槛,使得现有的、成熟的视频生成模型能够更容易地被直接利用,对于技术的实际落地和普及极为友好。
此外,研究重新揭示了Transformer内部不同层级的职能差异。他们发现,不同层并非千篇一律,有些层对位置信息更敏感,有些层则更受长上下文影响。因此,真正有效的方法不是对所有层进行无差别的修改,而是先定位出问题集中的层,再进行针对性修复。这一认识具有相当的普适性,它不仅适用于视频生成,对于处理长上下文的LLM、图像生成模型的推理优化,同样具有启发意义。
换言之,这项研究贡献的不只是一个技术技巧,更是一种可推广的思路:先诊断问题,再定位层,最后进行局部修复。
从更广阔的视角看,这项研究的影响相当直接。未来,当普通用户尝试用AI生成稍长一点的视频时,那些令人头疼的“人物变脸”、“服饰突变”、“背景跳跃”和“动作接不上”的情况,有望大幅减少。
对于普通用户而言,这意味着制作故事短片、教学视频或产品展示时,成片会更加稳定可靠,更接近真正“可用”的内容。对于内容创作者来说,这意味着更少的返工、更低的制作门槛,个人或小团队也有更大机会利用现有模型,产出更长、更连贯的视频作品。
因此,这项研究推动的不仅是技术指标的爬升,更是让AI长视频生成向着“日常可用”与“商业可用”的目标,实实在在地迈进了一步。
FreeLOC 的创建者
论文第一作者田佳豪,目前是西湖大学AGI Lab的科研助理,师从张驰教授,主要从事计算机视觉与生成式AI研究。他的研究重点集中在扩散生成模型、视频生成与世界模型等前沿方向。从学术成果看,他已发表或参与多项工作,包括以第一作者身份发表在CVPR 2026的FreeLOC,以及投稿于ECCV 2026的HeadForcing。此外,他还参与了DCCM、Loss-Guided Diffusion For General Controllable Generation等工作。其研究轨迹呈现出从图像扩散模型理论、视频时序建模到自回归长视频生成与交互式视频合成的清晰演进路径。

通讯作者张驰,是西湖大学助理教授、独立PI,并担任AGI Lab负责人,研究方向为生成式人工智能与多模态智能。在加入西湖大学前,他曾任腾讯研究科学家,并于新加坡南洋理工大学获得博士学位,师从林国盛教授,同时与沈春华等学者保持长期合作。在学术影响力方面,他连续入选斯坦福大学发布的全球前2%科学家榜单,并担任ICML、ICLR、CVPR等顶级会议的领域主席,以及IEEE T-CSVT期刊的副编辑。
在学术研究上,张驰教授长期深耕生成式人工智能领域,研究方向涵盖扩散模型、多模态生成建模以及智能体系统。近年来,他带领团队在CVPR、ICCV、ICLR、NeurIPS等顶级会议上持续产出成果,例如Ultra3D、FlowDirector、WorldForge、MeshAnything、Metric3D、StableLLaVA等代表性工作。这些研究从图像生成、视频生成延伸到3D/4D场景建模以及多模态智能体,形成了一条从视觉理解到世界建模的系统性研究路线。
总体来看,张驰教授的研究强调生成模型的可控性、多模态融合能力以及向真实世界建模能力的拓展,既关注模型的基础理论,也注重实际系统的构建与应用落地。例如,在视频生成与3D建模方向,他推动研究从单纯的内容生成向可控的相机运动和空间理解发展;在智能体方向,他探索多模态大模型在真实交互环境中的应用。这种研究路径体现了从传统计算机视觉向通用人工智能过渡的前沿趋势。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

预计算力需求持续旺盛行业景气度维持高位
近日,上海在数字经济战略布局上再出关键举措。市政府办公厅正式印发《国家数字经济创新发展试验区(上海)实施方案》,其中对算力资源的规划部署成为业界关注焦点。方案明确提出,要加快推进算力资源的高效互联与协同调度。具体而言,将进一步提升上海市算力监测调度平台与长三角(上海)算力互联互通平台的核心功能,积极

千问AI一键生成PPT 三分钟完成内容排版
近日,千问AI的PPT生成功能迎来了一次架构层面的重大升级,全面转向全新的智能体驱动模式。官方数据显示,升级后的系统能在1至3分钟内,自动完成从主题分析、内容规划、素材搜集到版式设计的全流程工作。这一效率的飞跃,迅速在教育工作者及办公用户群体中引发了广泛的试用与热议。 具体而言,用户现在只需输入简单

上交大与vivo团队在CVPR 2026提出扩散模型高效优化新方法
许多用户初次接触图像生成模型时,常被其快速生成“像模像样”图片的能力所惊艳。然而,当真正将其投入高频生产工作流时,另一层面的挑战便逐渐浮现。 例如,在创作活动主视觉时,模型生成的前几稿可能在主体、色调与氛围上都符合预期,但一旦放大审视细节,手部结构、材质纹理或元素间的边缘关系往往经不起推敲。又如,为

支付宝AI付龙虾插件更新日志与安装升级指南
当你在对接支付宝AI付功能,使用OpenClaw(常被开发者称为“龙虾”)插件时,如果突然遇到功能异常、支付回调失败,或者系统无法识别最新的交易字段,这很可能不是你的业务逻辑出了问题,而是插件版本滞后了。技术栈的兼容性就像齿轮,一个齿对不上,整个传动就可能卡住。别担心,升级插件通常就能解决。下面这几

支付宝AI付在龙虾OpenClaw上的测试与支付成功确认指南
为OpenClaw(龙虾)成功接入支付宝AI付功能后,如何全面验证支付链路是否真正畅通无阻?关键在于模拟一次真实的用户支付行为,并严格确认从指令识别、订单生成、授权跳转、支付执行到状态记录的五个核心环节全部正常运转。以下这套详细的测试流程,将帮助你系统性地完成功能验证,确保支付体验流畅可靠。 一、发








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
