




AI挑战红警经济零交战惨败 玩家围观实战翻车现场

还记得童年时在电脑前沉浸于《红色警戒》的激战时光吗?这款考验玩家多线运营、资源调配与战术决策的经典即时战略游戏(RTS),如今已成为评估AI智能体综合能力的“终极试炼场”。近期,Hugging Face重磅开源了OpenRA-RL项目,它将这款经典游戏深度改造,打造为一个专为大模型Agent设计的标
还记得童年时在电脑前沉浸于《红色警戒》的激战时光吗?这款考验玩家多线运营、资源调配与战术决策的经典即时战略游戏(RTS),如今已成为评估AI智能体综合能力的“终极试炼场”。近期,Hugging Face重磅开源了OpenRA-RL项目,它将这款经典游戏深度改造,打造为一个专为大模型Agent设计的标准化训练与评估平台。这并非简单的技术演示,而是一套从底层游戏引擎到上层API接口全面贯通的“基础设施级”解决方案。

简而言之,该项目向AI研究社区全面开放了《红色警戒》的游戏控制权。通过暴露多达50个MCP(模型上下文协议)标准化工具,游戏内部的全量状态信息——包括单位位置、资源储量、建筑健康值等——都能以25Hz的高频率实时同步给AI智能体。同时,平台支持单进程下并发运行64局游戏,无论是采用大语言模型(LLM)、传统规则脚本Bot,还是基于强化学习(RL)算法训练智能体,三条主流技术路径均已铺平道路。

更为关键的是,它原生集成了OpenEnv生态系统,这意味着TRL、torchforge、Unsloth等主流AI训练框架能够实现即插即用。回顾历史,DeepMind的AlphaStar在《星际争霸II》中达到宗师水准,OpenAI Five在《Dota 2》里展现统治级表现,但其背后依赖的是数千块专用TPU集群以及高度定制化、难以复现的庞大工程系统。对于广大普通研究者和技术爱好者而言,这道门槛曾经高不可攀。
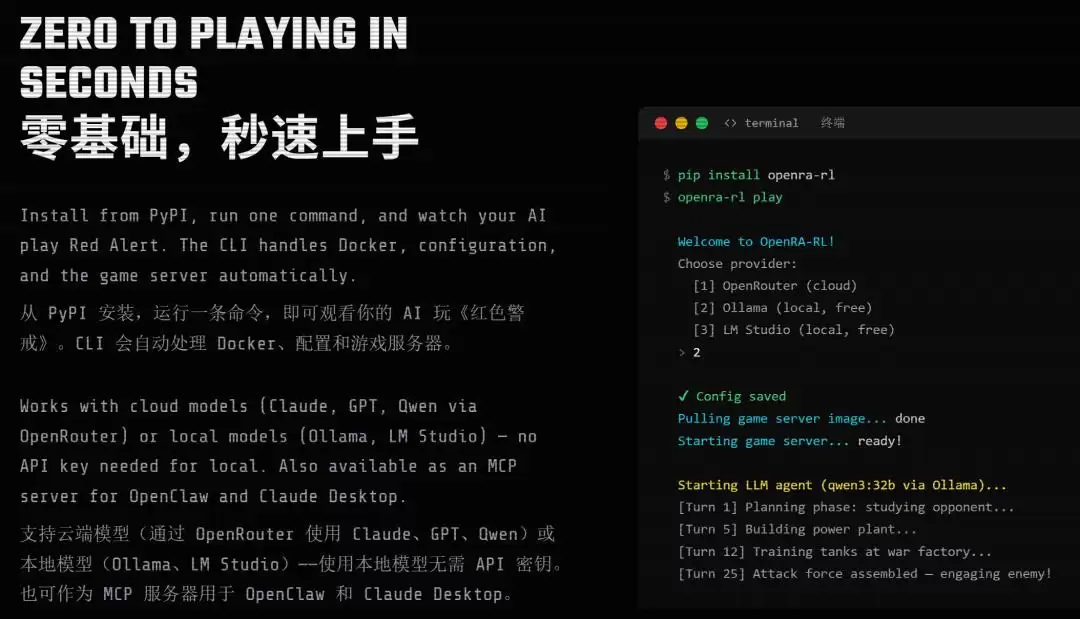
如今,局面已然改变。OpenRA-RL致力于将RTS智能体研究的门槛“降至地板级”:研究者仅需一台配备消费级显卡的电脑,运行一行“pip install openra-rl”安装命令,即可获得与顶尖AI实验室在本质上等同的实验环境。这无疑为更广泛、更开放的AI智能体前沿探索敞开了大门。
首秀表现:经济运营满分,战术进攻零分
那么,当前主流大模型在这个全新的硬核战场上表现如何?项目团队进行了一次基线测试。他们使用Ollama在本地部署了Qwen3 32B模型,让AI智能体在128x128的标准盟军地图上,与游戏内置的“新手”难度AI进行5局对战。
在此过程中,AI Agent通过MCP工具集接收结构化的游戏观测信息,并据此发出高层级动作指令。每局游戏开始前,模型会进行战略规划;每局结束后,则会启动“反思复盘”机制,将提炼出的经验教训以系统提示词的形式注入到后续对局中。
结果颇具启发性:5局游戏均以平局告终,对战双方甚至未曾发生一次正面战斗冲突。
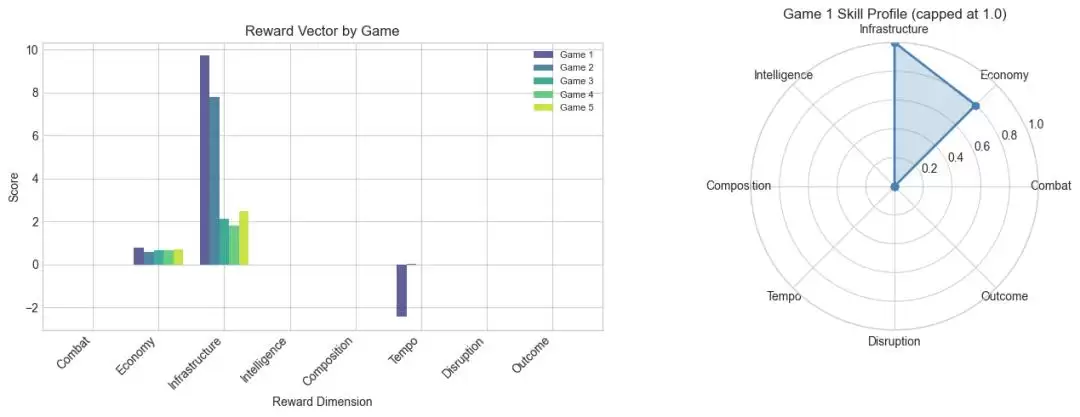
深入分析战报发现,AI在每一局都成功构建了完整的经济体系,矿场、发电厂、兵营等基础设施一应俱全,但它自始至终未生产任何一支进攻型作战单位。若仅看胜负结果,此事似乎平淡无奇。但OpenRA-RL平台提供的8维精细化奖励向量,为我们勾勒出一幅更精确的“智能体能力画像”:AI在经济运营维度的得分稳定在0.58至0.80之间,证明其基建能力可靠;然而,在“战斗输出”与“战术骚扰”两个核心维度上,得分赫然为零。
这正是此类标准化评估环境的宝贵价值——它能对智能体的失败模式进行精准诊断。研究者可以清晰定位AI的能力短板,从而有针对性地设计奖励函数或规划课程学习策略,例如优先激励其生产一辆坦克发起试探性进攻。
从第五局对战前10个回合的详细决策日志中,可以清晰洞察模型的“思考节奏”与行为模式:

一个典型的三段式决策循环浮现出来:首先进行情报收集与战略规划,随后下达建造经济建筑的指令,最后频繁调用“advance”工具加速游戏时间流逝,以弥合大模型数秒级的推理延迟与游戏实时节奏之间的巨大鸿沟。数据统计印证了这一点,“advance”工具调用约占全部操作数的57%,这凸显了其异步架构设计的核心价值。
另一个值得玩味的细节是模型展现的“上下文学习”能力:在第二局结束后的反思中,AI自行发现了“战争工厂应建于发电厂之后”这一建造顺序错误。到了第四局,它的开局建造顺序果然调整为优先建造发电厂。提示词注入式的学习能够修正此类程序性知识,却无法填补“主动进攻”策略能力的根本空白。而这,正是从依赖上下文的快速适应,转向通过模型权重更新进行强化学习后,理应产生可量化性能提升的关键环节。
设计初衷:为何选择《红色警戒》?为何是当下时机?
一个根本性问题在于:为何选择《红色警戒》作为AI智能体的训练场?答案源于现有RTS研究平台与LLM特性的“不兼容”。
试想,一个未经任何RTS专项训练的前沿大语言模型,在即时战略游戏中能坚持多久?在此之前,无人能给出准确答案,因为像SC2LE、PySC2这类经典的RTS研究框架,均为毫秒级响应的传统AI设计,其动作空间是底层的像素点击与单位移动指令。
而大语言模型的需求恰恰相反:它需要高层的、语义化的抽象接口(例如“在基地附近建造一座矿场”),能够容忍从40毫秒到数秒不等的推理延迟,并且最好以异步非阻塞方式与游戏环境交互。强行将LLM塞入传统框架,即便能够运行,其结果也缺乏可比性与可复现性。
OpenRA-RL选择基于Westwood经典之作《红色警戒》的开源复刻版OpenRA进行深度定制。理由务实而充分:游戏具备足够的策略深度与复杂性,代码结构清晰易于修改,并且内置了从“新手”到“困难”的梯度化AI对手。最终实现的效果是,无论你使用Qwen3、Claude等大模型,还是一个简单的Python脚本Bot,都可在完全相同的、零改动的标准化环境中进行对战或训练。
技术内核:“三明治”架构与并发性能革命
OpenRA-RL的系统架构可形象地比喻为“三层三明治”。最底层是经过深度定制的OpenRA游戏引擎(由C#编写),以约25Hz的频率驱动游戏世界心跳。中间层是一个高性能gRPC桥接层,负责实时向外推送游戏观测数据,并接收来自外部的操作指令。最上层则是Python封装,对外提供类似Gymnasium标准的reset、step、close等易用接口。
在此之上,一个MCP服务器将大约50个游戏核心动作(如建造、移动、攻击、集合)暴露为标准化工具,使得任何兼容MCP协议的LLM客户端都能直接驱动一场完整的游戏对局。

这套分层设计的核心目标在于:实现智能体计算与游戏逻辑执行的彻底解耦。这意味着,一个反应速度仅40毫秒的脚本Bot,与一个需要思考2秒的大模型,可以同时在同一个25Hz的游戏引擎上并行运行,彼此互不干扰。
为满足大规模训练与批量评估的需求,项目在并发性能上实现了关键突破。早期的v1版本每开启一局游戏便需启动一个独立的.NET进程,运行64局将占用约40GB内存,且每次环境重置需等待5-15秒,实用性较低。
v2版本的核心革新在于:让单个.NET进程承载多达64个独立的游戏会话。其技术关键在于,游戏中的ModData(包括单位属性、建筑参数、科技树、地图规则等全局数据)在初始化后是不可变的。因此,只需加载一次,即可在所有会话中实现无锁共享。仅此一项优化,便回收了约35GB的内存占用。每个会话独立维护自身的World、OrderManager和BotBridge状态,确保了严格的隔离性。
最终性能提升堪称显著:环境重置延迟从5-15秒骤降至256毫秒(提升约40倍);运行64个会话的总内存占用从约40GB降至约6GB(节省约7倍);.NET的JIT(即时编译)开销也从64次减少为1次。
超越游戏:开放生态与标准化基准的真正价值
因此,OpenRA-RL项目的真正价值,并不在于让某个大模型在游戏里多建造了几座发电厂。它的深远意义在于,提供了一个足够硬核、评估精准、且完全开放的智能体训练与评测基准。
这个环境本身具备真实的策略复杂性——一个拥有320亿参数的顶尖模型,对阵游戏中最弱的AI对手,连续进行5局却未能发起一次有效进攻。这足以证明,即便是“新手”难度的红警环境,也足以暴露大模型在建造顺序优化、兵种协同搭配、进攻时机把握等高层战略决策上的显著短板。
而且,它暴露得极其精确。如果仅看胜负平局,结果一言可蔽之。但8维精细化奖励向量会清晰地告诉你:经济运营得分0.58-0.80,基建能力合格,战斗与骚扰能力为零。弱点一目了然,后续的课程学习与算法优化该从何处着力,也就有了明确的方向。
项目团队在技术博客中列出了清晰的后续路线图:基于Qwen3基线进行GRPO训练,用模型权重更新替代提示词注入,观察能否打破“战斗零分”的僵局;利用8维奖励设计渐进式课程学习,从只需简单战斗的场景开始,逐步增加策略复杂度;开展跨模型横向评测,让Claude Sonnet、GPT-4等不同规模与架构的模型,在相同地图、相同对手、相同时间限制下同台竞技;最终,建立公开透明的Agent对Agent天梯排行榜。

对于整个AI智能体研究领域而言,这套开源工具链的意义远不止于复活一款经典游戏。AlphaStar和OpenAI Five已经证明了AI在复杂RTS环境中可以达到超越人类的水平,但那些辉煌的成果曾被封闭在高墙之内——依赖于数千块专用芯片、无法复现的定制化架构。
OpenRA-RL首次推倒了这堵高墙的重要部分。现在,凭借一台消费级显卡和一行安装命令,任何有兴趣的研究者或开发者,都能站到RTS智能体前沿研究的起跑线上。《红色警戒》在此刻成为一个强烈的信号:这里正是检验与推进强化学习、智能体决策与规划能力的绝佳战场。而如今,进入这个战场的门票,已不再只属于少数巨头实验室。
参考资料:
https://huggingface.co/blog/jadetan/openra-rl
https://huggingface.co/spaces/openra-rl/openra-rl
https://openra-rl.dev/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

学霸港姐王嘉慧晒美照颜值体态双在线气质出众
2024年港姐五强王嘉慧晒出写真,身形清瘦线条紧致,气质出众。她分享长期健身塑造体态,并立下目标:计划2027年挑战HYROX综合体能赛事,展现突破极限的决心。她表示将为此加强训练,追求更完美自我。

理想汽车负责人称张雪819三缸机解决国产大排量摩托瓶颈
这几天,中国摩托车圈最火的话题,莫过于张雪机车在 WSBK 赛场上拿下的那个冠军——这可是中国摩托第一次在这个国际顶级赛事里站上最高领奖台。一时间,张雪 820RR 这台车成了话题中心,大家热议的焦点,自然是它搭载的那台直列三缸发动机:最大马力 135PS,零百加速只要 2 81 秒,数据相当硬核。

鸿蒙智行6月车型销量问界第一尚界跃居第二
鸿蒙智行6月零售:问界30199台居首,尚界Z7系列跃升第二,智界、享界、尊界随后。总交付50624台,环比增9 7%;上半年累计24万台,同比增18 6%。

吉利银河M7中型电混SUV本月上旬预售下旬上市
吉利银河M7正式登场,携硬核实力进军中级电混SUV市场。4月3日官方确认,新车将于本月上旬开启预售,下旬正式上市。作为银河M系列首款中级电混SUV,其核心参数令人瞩目:纯电续航达225km,综合续航突破1730km。 简单来说,新车可视为银河L7的改款升级,前脸采用银河M9家族式设计语言,双色车身设

捷豹路虎因车顶饰条脱落隐患召回部分进口揽胜及揽胜运动版
近日,国家市场监督管理总局发布了一则重要召回信息。2026年4月7日,捷豹路虎(中国)投资有限公司正式备案了召回计划,涉及部分进口路虎揽胜和揽胜运动版车型,引起了广泛关注。 根据召回编号S2026M0038V:自2026年6月1日起,捷豹路虎将召回2024年1月18日至2025年11月27日期间生产








- 热门数据榜



 相关攻略
相关攻略
 2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
热门教程
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















