




北大彭宇新团队CPL++框架提升视觉定位模型自检与纠错能力

视觉定位(Visual Grounding)这项任务,目标是让机器根据一句自然语言描述,在图像中精准地框出对应的物体。听起来很直接,对吧?但全监督的方法有个绕不开的痛点:它需要海量精确到像素级的“图像-文本-物体框”三元组标注。面对大规模、场景复杂的真实数据,这种标注成本高得令人望而却步。
于是,弱监督视觉定位成了研究热点——只给“图像-文本”对,让模型自己学会定位。现有的方法大多把它看作一个跨模态检索问题:用文本去图像里“找”最匹配的区域。但这里有个根本性的挑战:语言描述是高度抽象的(比如“那个穿着红色毛衣正在喝咖啡的人”),而图像区域是具体的像素块。这两者之间存在巨大的“异构鸿沟”,导致跨模态匹配常常不靠谱。模型一旦在训练初期学错了关联,错误就会像滚雪球一样累积,最终陷入性能瓶颈。
怎么破局?最近,北京大学彭宇新教授团队在IEEE TPAMI上发表了一项新研究,提出了一个名为CPL++的框架。它的核心思路颇具启发性:与其绞尽脑汁去弥合鸿沟,不如先给模型建立更可靠的初始关联,然后赋予它“自知之明”,让它能在训练中自己发现并纠正错误。

从“跨模态”到“单模态”:构建更可靠的起点
既然跨模态匹配容易出错,CPL++的第一步是换个思路,在更可靠的单模态空间内建立关联。具体来说,框架会为图像中的每个候选区域,自动生成多条高质量、多样化的文本描述。这些描述通过三条互补的管线产生:基于规则的启发式增强、聚焦物体本身的描述,以及包含物体间关系的描述。
这样一来,每个区域都有了属于自己的“伪查询”文本。接下来的关键操作是:在纯文本的特征空间里,计算用户给出的真实查询与每个区域“伪查询”的相似度。相似度最高的区域,就被选为初始的伪标签。这个方法巧妙地绕开了直接进行跨模态对齐的难题,为模型训练提供了一个更干净的起点。
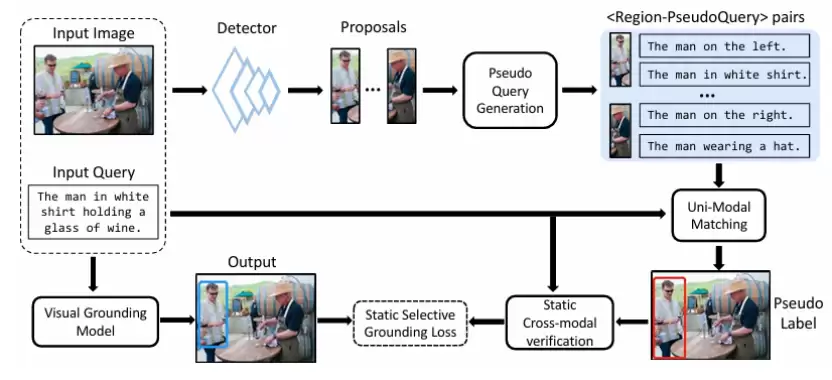
图 1. 置信度感知的伪标签学习框架 CPL
静态过滤与动态进化:赋予模型“纠错”能力
有了初始关联,CPL++引入了双重保障机制。首先是静态过滤:利用一个冻结的、预训练好的视觉-语言大模型,对所有“区域-查询”对进行一次事前评估,打出一个静态置信度分。分数太低的关联会被直接过滤掉,防止明显的错误样本干扰训练。
但这还不够。静态过滤是“一刀切”,且无法在模型训练过程中动态调整。于是,CPL++的核心创新——自监督关联校正与验证模块登场了。这才是让模型获得“自知之明”的关键。
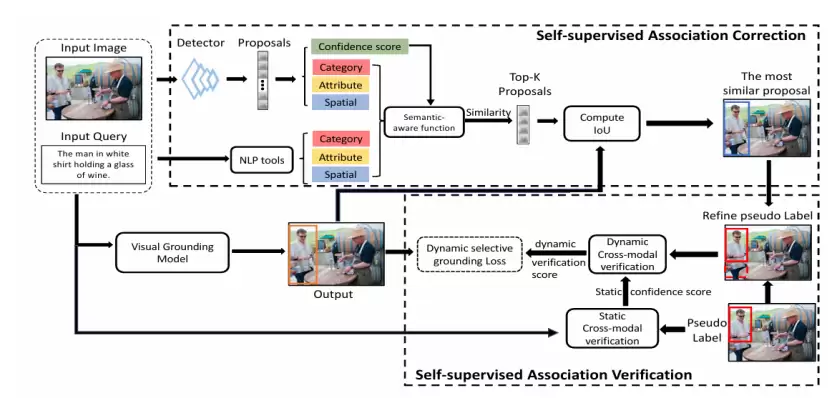
图 2. 置信度感知的伪标签学习框架的进阶版本 CPL++
1. 自监督关联校正: 模型不再仅仅依赖检测框的分数,而是会综合分析查询文本中的类别、属性和空间关系信息,构建一个语义感知更强的候选区域池。它会计算一个综合评分,来评估当前“区域-查询”关联的可靠性。
更重要的是纠错机制。在训练中,模型会不断将自己的预测框与候选池中最优的区域进行对比。如果两者重合度太低,模型就会“意识到”当前的伪标签可能错了。这时,它不是简单地抛弃这个样本,而是动态地将初始伪标签和自己的预测进行加权融合,生成一个更准确的新伪标签。这就好比学生在做题时,不仅知道答案可能错了,还能参考自己的推理过程,修正出一个更接近正确的答案。
2. 自监督关联验证: 另一个有趣的发现是,模型在面对错误样本(噪声)时,通常会产生较大的训练损失。CPL++利用了这一特性,设计了一个动态的选择性定位损失。它会根据当前轮次每个样本的训练损失大小,动态调整该样本的权重。损失大的(可能是噪声)权重降低,损失小的(可能是干净样本)权重提高。这种机制让模型能够利用自身训练过程中的反馈,实时甄别并抑制不可靠的监督信号。
效果如何?数据说话
研究团队在RefCOCO、RefCOCO+、RefCOCOg、ReferItGame和Flickr30K Entities这五个主流数据集上进行了全面测试。结果令人印象深刻。
基础的CPL框架在各项测试中均已超越之前的弱监督和无监督方法。而具备了“自我纠错”能力的CPL++,性能更是实现了显著提升,在五个测试集上分别取得了2.78%、5.81%、1.08%、2.03%和2.55%的绝对精度提升。这一进步将弱监督方法与全监督方法之间的性能差距进一步缩小。
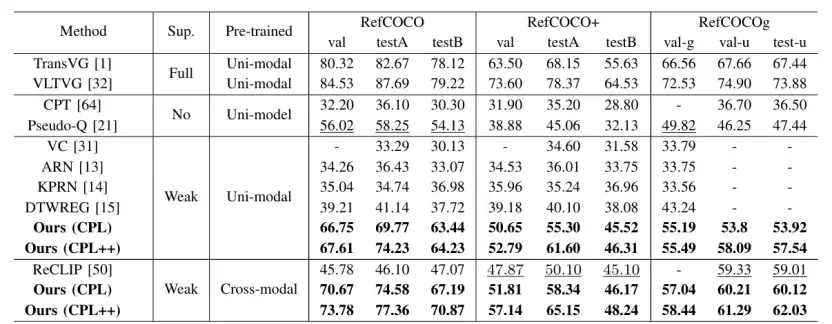
表 1:RefCOCO、RefCOCO+、RefCOCOg 数据集结果
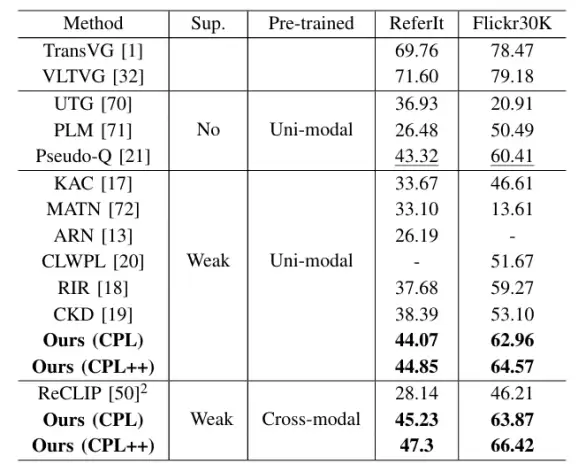
表 2:ReferItGame、Flickr30K Entities 数据集结果
可视化结果更直观地展示了模型的“进化”过程。图3显示,CPL能为区域生成描述准确、句式多样的伪查询。图4则完整演示了自校正模块的工作流程:从可能出错的初始关联,到模型识别出偏差,最终成功地将预测框纠正到真正描述的目标上。

图 3:CPL 框架伪标签可视化

图 4:CPL++ 框架自监督关联校正可视化
总结与展望
总的来说,CPL++框架为弱监督视觉定位提供了一条新路径。它通过单模态匹配构建了更稳健的初始化,其精髓在于引入的自监督校正与验证机制,让模型在训练中获得了动态识别和修正错误的能力。这项研究有力地证明,在数据标注成本高昂的现实约束下,赋予模型“自知之明”和“自我纠错”能力,是推动弱监督学习性能边界向前迈进的一个非常有效的方向。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI项目成功关键指标:准确率之外的三大生死线
许多人工智能项目最终未能成功部署,问题往往不在于算法模型本身不够先进,而是整个系统在运行中逐渐“失效”:响应速度变慢、数据质量悄然下滑、各模块衔接出现异常。结果如何?模型预测或许依然准确,但整个系统已失去实际应用价值。这揭示了一个关键现实:准确率只能反映实验室环境下的表现,却无法应对真实生产场景的复

AI安全架构三大支柱防投毒泄密保障企业智能升级
在人工智能系统规模化部署的初期阶段,许多技术决策者曾普遍陷入一个认知误区:将安全架构与数据治理视为模型开发完成后的“附加项”或“补丁”。我们曾热衷于追求开发速度,快速推出AI模型,并为早期成果欢呼,然而现实往往在数月后给出冷静的反思。一个典型案例是,某条机器学习流水线在无意中将包含敏感客户信息的数据

AI时代CIO如何平衡老板与员工需求跳出管理困境
眼下,企业界正上演着一幕颇具戏剧性的场景:董事会与资本方热切推动AI部署,但现实反馈却往往是员工疲惫不堪,项目频频受挫。问题出在哪里?根源或许不在于AI技术本身,而在于“用法”——许多企业只是简单地将AI工具叠加在原有流程之上,结果非但没能提升效率,反而催生了一种新的职业困扰:“AI倦怠”。 技术迭

Docker沙箱安全运行AI智能体完整指南
你是否曾希望AI智能体能在你的项目中自由探索、安装依赖并执行命令,同时又完全隔离于你的本地系统之外?这种“既要灵活性,又要安全性”的需求,在AI驱动的开发场景中日益普遍。如今,Docker Sandboxes 恰好提供了一个完美的解决方案,它能创建一个安全的隔离环境,让AI助手在受控的沙箱内高效工作

树模型与表格建模的规模化应用与未来趋势
一张H100 GPU的算力,大约相当于多少个Hadoop集群节点? 站在2026年的视角回望,这个对比极具启示意义:单张H100 GPU(FP16精度)的峰值计算能力,大致等同于200台搭载96核CPU的传统Hadoop服务器实例。 这一巨大差距背后,揭示了一个深刻的行业现状:尽管AI芯片算力正以指








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
