




灵初智能PsiR2模型凭海量数据与规模优势登顶MolmoSpaces评测

具身智能的叙事,正在翻开新的一页。
一个越来越清晰的共识正在形成:仅仅依赖真机遥操作采集的数据,恐怕难以支撑机器人走向大规模的实际应用场景。
背后的逻辑不难理解。真机数据成本高昂、采集缓慢,其动作节拍也往往与真实作业场景存在差距。实验室里跑得通的演示,一旦放到工厂、仓库或零售现场,就会面临速度、成本和稳定性的严苛拷问。决定下一阶段竞争格局的,已经不只是“谁能做出一个惊艳的演示”,而是“谁能率先将人类在真实世界中的操作经验,规模化地转化为机器人可学习、可迭代、可部署的能力”。
近期,灵初智能发布了一系列大模型、数据集及合作计划,包括策略模型Psi-R2、世界模型Psi-W0,以及总规模近10万小时的人类操作数据。其核心意图非常明确:当真机数据不再是唯一答案时,机器人能力的规模化扩展(scaling)还能依靠什么?
表面上看,这是一场新品发布;但深入一层,这更像是一次关于方法论的宣言:当具身智能领域缺乏互联网式的数据红利时,下一步究竟该靠什么继续前进。

当真机数据不再够用:具身智能为何转向“人类数据”
首先,我们来看看这次发布的具体内容。
在模型层面,发布了策略模型Psi-R2和世界模型Psi-W0。在数据层面,则推出了总规模近10万小时的人类操作数据,并首批开源了其中1000小时的数据。这1000小时数据,堪称当前行业内最大规模的开源人类手部操作全模态数据集之一。
进一步拆解,这套数据体系包含5417小时来自灵初自研MobiDex数采平台的真机数据,以及高达95472小时、覆盖多场景、多任务、多物体的人类操作数据。这也是业内少数明确将十万小时量级人类数据系统性用于机器人预训练的模型方案。
那么,为什么是“人类数据”?
根本原因在于,具身智能与大语言模型、自动驾驶不同。它没有互联网上海量的现成数据可供抓取,也很难在商业运行中自然沉淀出足够规模的高质量训练样本。“数据从哪里来”已经成为这个行业最核心的瓶颈之一。
而人类每天都在真实环境中,用双手完成高频、连续且精细的操作。这些数据天然贴近机器人未来需要面对的工作世界——它们源于真实任务,带着真实的节奏和操作细节。从落地角度看,这类数据的价值远不止是“多了一个数据源”那么简单。
然而,人类数据的采集并非“越多越好”那么简单。
它面临的首要难点是“具身鸿沟”(embodiment gap),即人手与机械手在运动学和动力学上的天然差异。其次是精度问题。许多人类操作数据来源于第一视角视频,其轨迹恢复精度往往只在厘米级;一旦涉及手机装配这类亚毫米级精度的任务,这种误差就会被急剧放大。
为了解决这些问题,灵初自研了外骨骼触觉手套和高精度感知硬件,将人手3D轨迹的采集精度推向了更高水平。另一部分裸手数据,虽然精度相对较低,但规模更大,主要承担提供模型泛化能力的职责。
换句话说,灵初并非简单地将“人类数据”视为替代真机数据的廉价选项,而是在尝试构建一套分层的数据体系:高精度数据负责提升任务执行的上限,大规模数据负责拓宽模型的泛化能力,两者共同为机器人训练构筑新的数据底座。
系统协同:比单个模型更关键
值得注意的是,灵初最终选择的技术路径并非特别“花哨”的对齐方式。
他们尝试过图像修补、关键点辅助损失函数、特征空间对齐等方法,试图将人类数据修饰得更接近机器人数据。但最终发现,当数据量较小时,这些方法有所帮助;一旦数据量上来,它们反而会成为瓶颈。
原因并不复杂。这些方法本质上都在努力模糊人与机器人的差异,但在长周期、高精度、接触密集的任务中,这种差异恰恰不能被轻易抹平。任务越复杂、越精细,就越需要承认两种“具身”形式的真实不同。强行“抹平”差异,模型反而更容易在关键动作上出错。
因此,灵初选择了一条更朴素的路径:只进行必要的输入输出维度对齐,将人类关节通过运动学映射到机器人关节,图像数据尽量不做过多处理,直接将原始数据输入模型。他们对这条路径的总结也很直接:原始数据进,原始数据出。
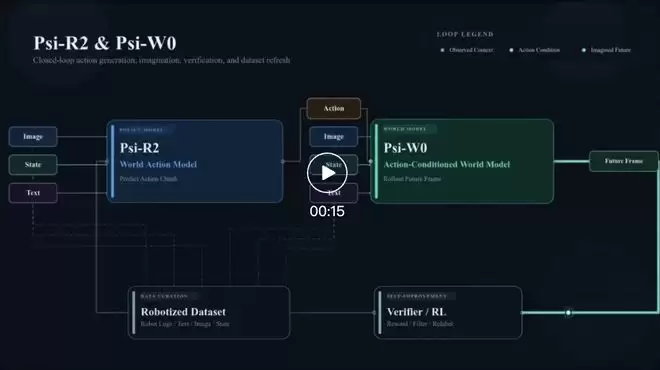
在这套体系中,Psi-R2负责“先学会怎么做”。
它以图像和语言为输入,同时输出未来视频预测和机器人动作。这意味着它不仅学习下一步动作,还在同步学习“接下来世界会如何变化”。这套设计建立在预训练的视频生成模型之上,目标是将大规模人类数据中蕴含的任务知识,尽可能多地编码进策略模型。
经过大规模预训练后,Psi-R2仅需少于100条真机轨迹进行微调,就能完成手机装配、工业包装、叠纸盒等长周期、高精度的任务。

然而,只学习成功的动作示范是不够的。
因为成功示范只能告诉模型“应该怎么做”,却无法揭示“如果换一种做法,会在哪一步失败”。而这恰恰是强化学习最需要的关键信息。
这正是Psi-W0的用武之地。
它接收图像、语言和机器人动作轨迹,并预测未来视频。与Psi-R2相比,Psi-W0多了一项核心职责:建模失败、建模反事实、建模试错空间。为此,Psi-W0的训练数据中额外加入了约30%的失败数据。
换言之,Psi-W0不只是一个“会预测”的模型,它更像一个可用于评估和打磨策略的“训练场”。Psi-R2先从人类数据中学习任务知识,然后将生成的轨迹送入Psi-W0进行推演;随后,在机器人动力学约束下,通过强化学习进行小步修正,将“人类会做”的轨迹改造为“机器人也能做”的轨迹。优质的轨迹回流至训练集,失败的轨迹则帮助世界模型变得更精准,由此形成一个持续优化的数据飞轮。
这也是本次发布最值得关注的一点:真正发挥作用的,并非某个单一模型,而是Psi-R2、Psi-W0与强化学习三者构成的系统协同。
围绕人类数据,灵初也给出了一组对行业颇具参考价值的判断:对于数据分布而言,任务多样性 > 物体多样性 >> 场景多样性;对于模态价值而言,精准的3D位姿 > 触觉 > 2D图像特征。
翻译成更直白的话就是:背景环境是否足够复杂,未必是最重要的;真正决定模型能力上限的,是它见识过多少种任务、接触过多少种物体,以及它是否真正理解了物体接触与操作的物理细节。
正因如此,灵初将触觉视为一种跨越不同“具身”的“通用语言”。人手和机械手的结构可以不同,但“是否发生接触”、“接触是如何发生的”这类物理信号,在本质上是相通的。
从论文到现场:落地还要跨过部署关
如果说前面的部分解决了“技术上行不行”的问题,那么商业化真正关心的,始终是“这条路值不值得走”。
答案很明确:值得,而且必须走。
原因很简单。在实验室里,动作慢一点、路径绕一点,许多演示依然能够完成;但到了工厂、仓储和零售现场,节拍、成本和稳定性会重新定义一切。在实际作业中,一个动作多一步、一拍慢一点,最终都会反映在良品率和运营成本上。
从这个角度看,最具价值的数据,往往并非实验室里的遥操作演示,而是来自一线工人的真实作业数据。
一方面,人类数据的采集成本可以更低,已被压缩至传统真机遥操作方案的十分之一以下。另一方面,其动作节拍更真实,更贴近业务现场的标准作业程序(SOP)和速度要求。
工程侧的进展,则让这件事离实际落地又近了一步。
通过DiT Caching、Torch Compile、量化等一系列优化,单次推理时间已从2.2秒压缩到100毫秒以内。对于需要连续、灵巧、顺滑操作的任务而言,这已经不仅仅是“优化得不错”,而是能否真正进入现场部署的一道关键门槛。
外部基准测试的结果,也为这套方法提供了有力的佐证。
相关公开榜单页面显示,在MolmoSpaces Combined榜单中,且在不使用MolmoBot Data的分组条件下,Psi-R2以46.4的Oracle Success Rate排名第一,并覆盖了4个任务。
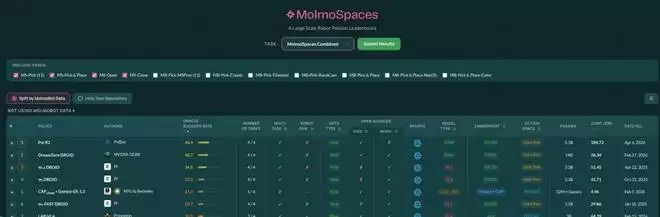
MolmoSpace由美国艾伦人工智能研究所发起,是全球具身智能领域的权威基准评测平台,NVIDIA、PI等全球顶尖团队均参与了本次评测。灵初Psi-R2在评测中超越了PI、DreamZero等国际知名模型,其表现显著优于其他基线模型,成功率大幅领先同类视觉语言动作模型产品,充分体现了企业自主研发路线的先进性与竞争力。
这个细节的价值,不只是“上榜”而已。更重要的是,它标志着这套方法正在进入一个公开、可比较的评价环境中接受检验。
将所有这些信息放在一起看,本次发布的重点并不仅仅是“又发布了一个模型”,也不只是“又开源了一批数据”。
它更像是在向外界传递一个清晰的判断:
第一,具身智能的瓶颈在于数据,而人类数据不是旁支末流,而是未来发展的主线之一。
第二,真正能将人类经验转化为机器人能力的,不是单个模型,而是由Psi-R2、Psi-W0和强化学习共同构成的协同系统。
第三,所有技术问题的终点都不是学术论文,而是实际落地:动作节拍、成本控制、推理速度、数据飞轮能否真正运转起来,才是最终的检验标准。
如果这套技术路线最终能够走通,那么此次开源的意义,就远不止是“放出一个模型,开放一批数据”那么简单。

它更像是在向行业宣告:具身智能真正的分水岭,或许已经不再是“谁先做出更惊艳的演示”,而是“谁能率先将人类数据、世界模型和强化学习连接成一条能够持续运转的增长曲线”。
从这个意义上说,这次发布想开启的,或许不只是一个新产品。
而是一个新的发展阶段。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Claude代码助手插件解决编程中断难题
对于深度依赖Claude Code进行开发的用户而言,最令人沮丧的体验莫过于在终端中“盲开”:你永远无法知晓当前对话的上下文容量还剩多少,只能被动等待系统提示耗尽,导致所有精心构建的对话逻辑和代码成果瞬间归零。 就在近期,一个典型的开发场景几乎让项目进度停滞:在编写一个复杂的批量交互脚本时,与Cla

谷歌Gemma 4大模型本地部署安装配置完全指南
4月3日凌晨,谷歌DeepMind向开源AI社区投下了一枚重磅冲击波:Gemma 4正式发布。 这个拥有310亿参数的模型,性能提升堪称“暴力”。在数学竞赛基准上,它从上一代的20 8%直接跃升至89 2%;编程能力方面,LiveCodeBench得分从29 1%飙升至80%。更关键的是,它采用了A

Linux CUPS打印系统高危漏洞可零点击获取root权限
近日,Linux生态系统中一项基础且至关重要的服务——打印服务CUPS被披露存在高危安全漏洞。根据网络安全媒体cyberkendra的报道,攻击者无需任何身份凭证,即可通过远程方式执行恶意代码,并最终获取系统的最高root权限。 这组漏洞由安全研究员Asim Manizada在人工智能工具的辅助下发

手机运行Gemma 4模型实测与可行性分析
昨天看到一条消息,说有人在 iPhone 17 Pro 上运行 Google 最新发布的 Gemma 4 模型,推理速度超过了每秒 40 个 token。第一反应是:这可能吗? 要知道,Gemma 4 是 Google 在 4 月 2 号刚发布的开源模型家族中的旗舰款。其参数量最大的 31B 版本在

大模型训练合成数据生成的十大实用策略
合成数据,这个曾经被视为“辅助工具”的技术选项,如今正快速演进为驱动大模型开发与迭代的核心基础设施。对于任何致力于长期模型训练、优化和持续升级的团队而言,构建高质量的合成数据能力已成为一项战略性任务。 背后的驱动力非常现实:获取大规模、高质量的训练数据始终是AI团队面临的主要瓶颈。数据或许存在,但面








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
