




谷歌最强开源模型仅2B手机可跑免费商用

谷歌DeepMind今天扔下了一颗重磅冲击波:正式开源发布Gemma 4系列模型。根据官方说法,这是谷歌迄今为止最智能的开放模型,专为高级推理和智能体工作流而生。最引人注目的是,它号称实现了“单位参数下前所未有的智能水平”——换句话说,就是用更小的模型体量,干出更聪明的活儿。
先看几个硬核数据:其31B稠密模型在业界公认的Arena AI文本排行榜上,已经冲到了全球开放模型的第三位。更让人印象深刻的是,在号称“高难度科学推理试金石”的GPQA Diamond基准测试中,它取得了85.7%的准确率,与目前排名第一的Qwen3.5 27B(85.8%)几乎并驾齐驱。要知道,这个测试里的题目都是由博士专家编写,旨在考察真正的研究生级科学推理能力,人类专家的平均准确率也才65%左右。
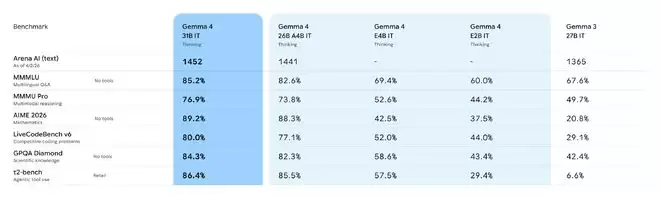
▲Gemma 4系列模型在多项基准测试中的表现对比(图源:blog.google)
自第一代Gemma面世以来,其下载量已突破4亿次,社区衍生的变体超过十万个。而这次的Gemma 4系列,是基于与Gemini 3同源的技术体系构建的。它原生支持图像和视频(以帧序列形式)输入,小模型版本还进一步集成了音频理解能力。系列共包含四款型号:E2B、E4B、26B混合专家模型(MoE)以及31B稠密模型,旨在覆盖从智能手机、树莓派到专业工作站的完整部署场景。最关键的是,所有模型都采用了Apache 2.0协议开源,开发者可以自由修改、分发并用于商业产品。
有开发者在社区里直言不讳地评论:“基准数据一直都在,但没人愿意在一个谷歌随时可能改规则的模型上建立产品。现在它才真的可以部署了。”这句话,或许点出了此次发布更深层的意义。
▲Gemma 4最新模型集合页面(图源:Hugging Face)
在硬件适配性上,Gemma 4采取了“移动优先”的设计思路。E2B和E4B专为边缘设备优化,可以在手机、树莓派甚至NVIDIA Jetson Orin Nano上完全离线运行,延迟接近实时。而26B和31B模型的非量化版本可在单张80GB的NVIDIA H100 GPU上运行,量化版本则能适配消费级显卡进行本地部署。
谷歌DeepMind的CEO德米斯·哈萨比斯将Gemma 4称为“在各自参数量级下性能最优的全球开源模型”。
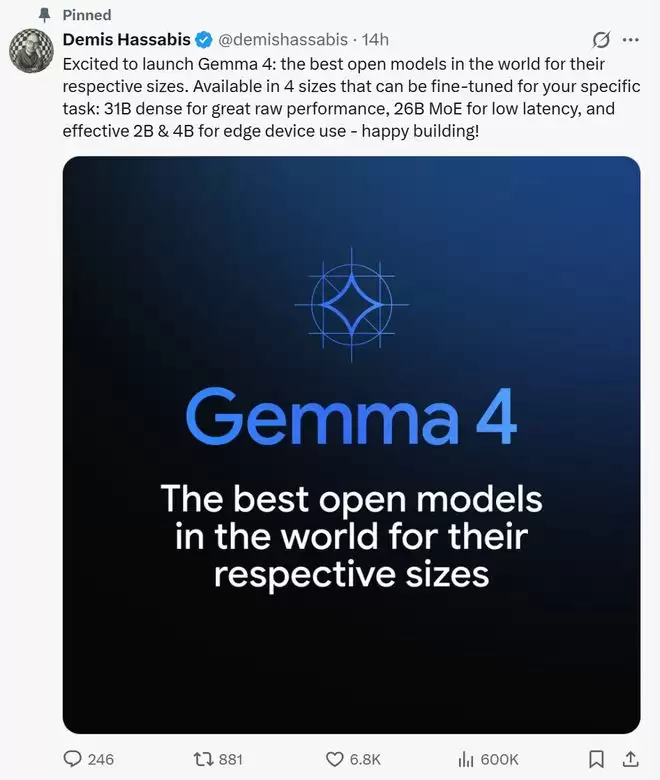
▲谷歌DeepMind CEO 德米斯·哈萨比斯(Demis Hassabis)在X平台的推文
Hugging Face联合创始人克莱门特·德朗格则将此次发布视为“本地AI正在迎来关键发展阶段”,他认为开放模型与可本地部署能力将成为未来AI的重要方向。
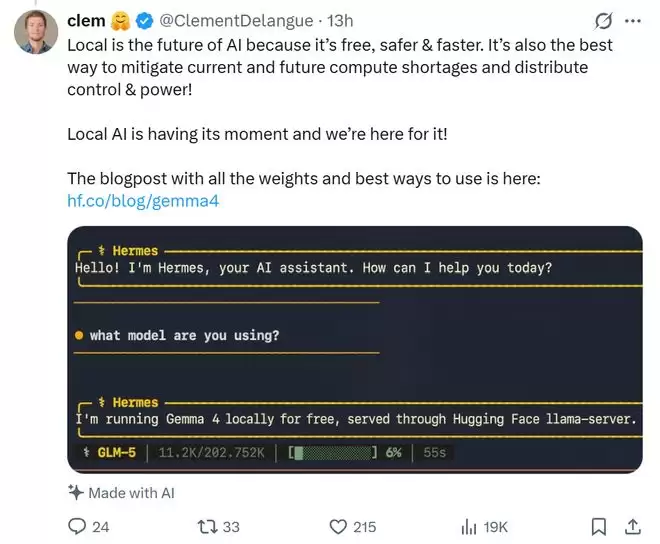
▲Hugging Face联合创始人克莱门特·德朗格(Clément Delangue)在X平台的推文
多家外媒将Gemma 4的发布解读为谷歌重返开源主战场的标志性事件,意味着美国模型阵营迎来了一位关键选手。
一、4大模型配置,性能表现超越参数规模达其20倍的模型
谷歌在技术博客中强调,Gemma 4的核心突破在于实现了“单位参数智能”的新高度。这意味着开发者可以用更低的计算开销,获得接近前沿大模型的能力。它走的不是单纯堆参数的路线,而是通过架构设计和训练优化的系统性改进。
具体来看,其31B模型在Arena榜单上的表现,甚至超越了某些参数规模是其20倍的模型。对于开发者而言,这直接转化为硬件成本的降低和部署门槛的下降。
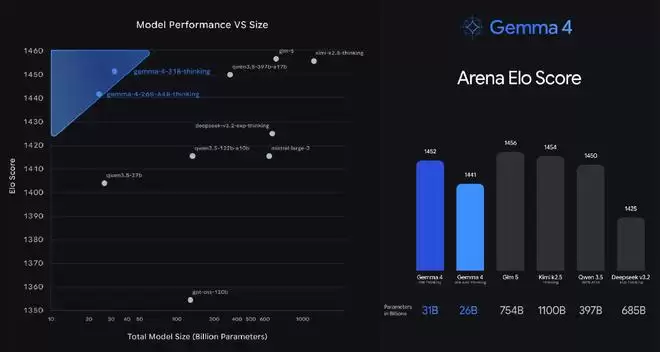
▲Gemma 4 在Arena用户偏好排行榜中的参数量对比(左)与用户偏好(右)(图源:blog.google)
架构上的巧思是达成这一目标的关键。比如26B的MoE模型采用了“按需激活参数”的设计,推理时实际活跃的参数只有约3.8B,在显著降低算力需求的同时保持了高性能。而E2B和E4B这样的小模型,则引入了Per-Layer Embeddings机制,为解码器的每一层配备独立的嵌入表,从而增强了各层的表达能力,提升了参数利用效率。
在注意力机制上,Gemma 4交替使用局部滑动窗口注意力和全局注意力,并在最后一层采用全局注意力,在保证长上下文处理能力的同时,有效控制了内存消耗。其边缘机型支持128K上下文窗口,大型号则提供256K,足以应对代码库或长文档的处理需求。
这些优化并非纸上谈兵。谷歌列举了实际案例:INSAIT基于Gemma开发了保加利亚语优先大模型BgGPT;耶鲁大学则与谷歌合作推进Cell2Sentence-Scale项目,探索癌症治疗新路径。这些都展示了Gemma在垂直领域落地应用的潜力。
二、原生支持图像、视频输入,可处理140种语言
Gemma 4的野心不止于文本。它从底层架构开始,就将多模态理解和智能体调用能力原生整合进了模型。
全系四款模型都原生支持图像和视频输入(视频被处理为帧序列),在OCR、图表理解等视觉任务上表现突出。E2B和E4B更进一步,集成了原生音频理解能力。在视觉处理上,模型支持可变分辨率和可配置的token预算,从70到1120 token多档可选,方便开发者在速度与精度间取得平衡。
更值得关注的是其智能体能力。Gemma 4将函数调用和结构化输出能力直接训练进了模型本身,而不是依赖提示词工程去引导。这意味着模型可以原生输出结构化的JSON,支持多工具调用和多轮任务执行,大大降低了开发者构建自动化工作流的工程成本。
在代码能力上,它被定位为“本地优先”的AI编程助手,支持高质量的离线代码生成。在多步推理和复杂指令执行任务中,表现较上一代有显著提升。此外,模型原生支持超过140种语言。
三、采用Apache 2.0许可证开源,可在手机上离线运行
除了技术能力,Gemma 4在开放策略上的调整同样关键。谷歌此次全面转向Apache 2.0许可证,取代了之前的自定义授权方式。这赋予了开发者对模型、数据和基础设施更高的控制权,允许自由修改、再分发和商业化部署。
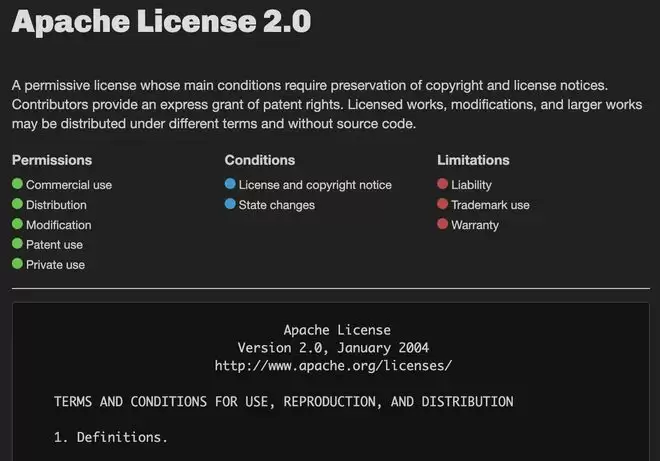
▲Apache License 2.0开源协议核心条款说明(图源:devmandan)
为了支持从实验到生产的完整链路,谷歌提供了Google AI Studio和AI Edge Gallery等工具供开发者快速体验。更重要的是,在发布首日,Gemma 4就获得了包括Hugging Face Transformers、vLLM、llama.cpp、Ollama等在内的主流开发框架的支持。
在硬件优化层面,它针对NVIDIA GPU(从Jetson到Blackwell架构)、AMD GPU(ROCm生态)以及谷歌自家的Trillium与Ironwood TPU都进行了深度优化。云端部署则可以通过Vertex AI、Cloud Run等多种方案轻松扩展至生产规模。
四、实测多模态复杂任务效果一般
当然,理想很丰满,现实也需要检验。知名AI开发者Simon Willison在实际测试后指出,Gemma 4在“单位参数能力”上确实表现突出,这反映了行业正在从一味追求大参数,转向在既定规模下挖掘更高性能。
他以“骑自行车的鹈鹕”这个复杂的视觉生成任务做了测试。结果显示,从2B到26B参数规模,模型的生成质量呈现明显的递进关系:小模型在表达复杂结构时仍有不足,而中等规模模型已经能生成语义完整的图像。这说明,在多模态复杂任务上,模型规模依然是一个重要因素。
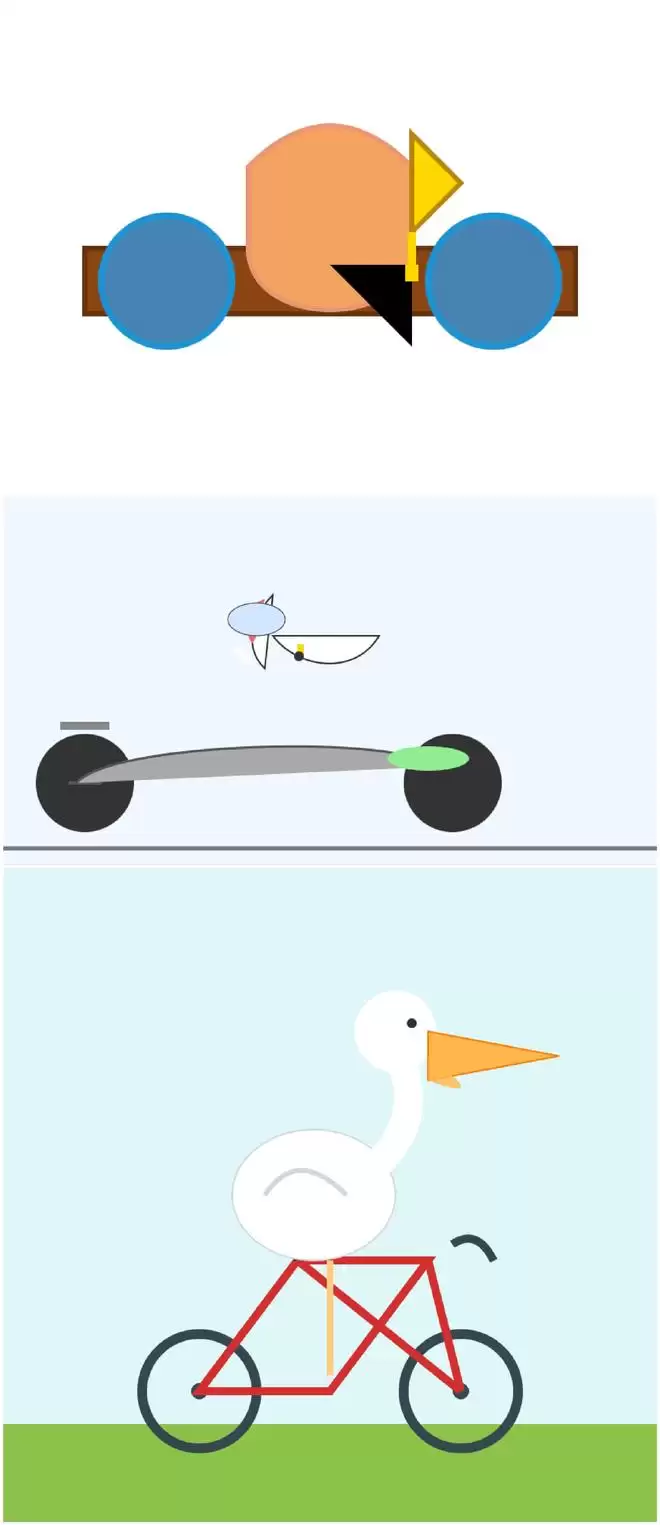
▲Willison以“骑自行车的鹈鹕”对该模型从2B到4B再到26B-A4B的测试
Willison也提到,尽管小模型已宣称具备音频等多模态能力,但从实际开发环境看,本地推理框架对这些输入形式的支持仍在完善中,完全落地尚需时日。
Hugging Face在技术解读中指出,与以往依赖云端部署的庞然大物不同,Gemma 4系列覆盖了从2B到31B的广泛谱系,使其既能用于数据中心,也能跑在本地和边缘设备上,这清晰地指向了AI模型“端侧化”的发展趋势。
五、编程、高难度推理表现,接近Qwen3.5
从各项基准测试来看,Gemma 4在文本任务上的能力实现了全面跃升。无论是在写作、编程、复杂指令执行,还是多轮对话与长文本理解方面,其表现都明显优于前两代产品,并在多个维度接近当前开源模型的第一梯队。
特别是在编程和高难度推理任务上,提升堪称跨越式。独立评测媒体ai.rs的分析认为,这是开源模型领域“单代提升幅度最大的一次”。其Codeforces ELO评分从Gemma 3的110分(勉强可用水平),飙升至2150分(接近竞技编程专家级),进步幅度惊人。
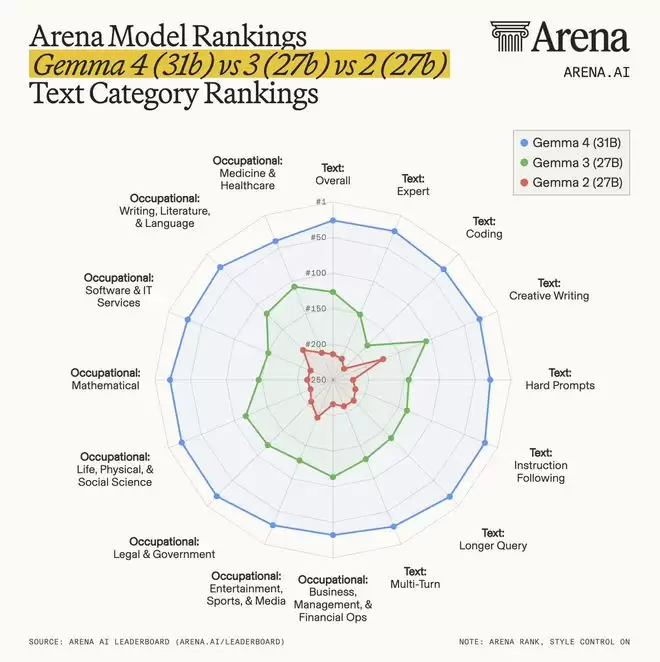
▲Gemma系列模型在Arena文本类别排名对比(图源:Arena.ai)
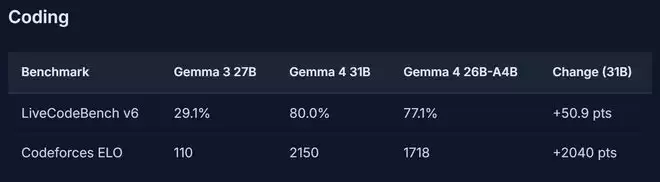
▲Gemma 4编码能力测试(图源:ai.rs)
在GPQA Diamond这样的高难度科学推理基准测试中,其31B模型以85.7%的准确率紧咬榜首的Qwen3.5 27B(85.8%)。从得分与参数量的关系图来看,Gemma 4的26B和31B变体都落在了“高效象限”,证明了其以较小参数规模实现高性能的特点。
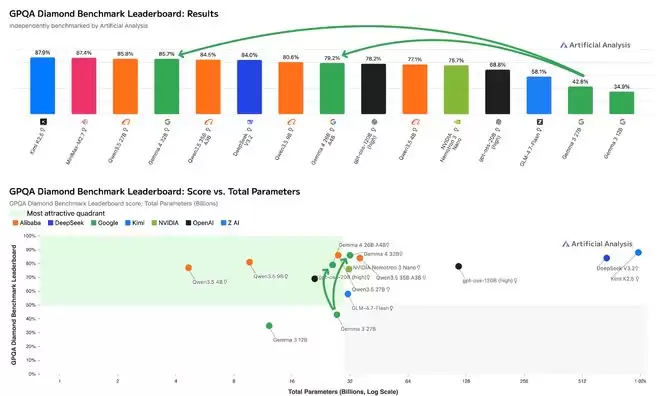
▲GPQA Diamond基准测试结果(柱状图)及得分与参数量关系(散点图)(图源:Artificial Analysis)
结语:从“能用”到“可部署”, 效率、成本与生态的综合较量
纵观Gemma 4的发布,其意义远不止于某项基准测试分数的刷新。它标志着开源大模型的竞争,正在进入一个全新的维度:从单纯追求性能指标的“军备竞赛”,转向效率、成本与生态的综合较量。
一方面,通过架构优化,小模型的能力不断逼近中等规模模型,降低了部署门槛;另一方面,多模态能力与真正的本地部署支持同步推进,减少了特定场景对云端算力的依赖。再加上Apache 2.0许可证带来的商业自由度,Gemma 4试图在“好用、可部署、可扩展”之间找到一个精妙的平衡点。
这场竞赛的下半场,或许不再是谁的模型最大,而是谁的模型能在现实世界的约束下,最优雅、最经济地解决实际问题。Gemma 4的这次出击,无疑为市场提供了一个强有力的新选项。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

豆包AI如何辅助教师编写教案与教学内容
对于一线教师来说,教案撰写与教学内容设计既是专业能力的体现,也是日常工作中耗时费力的环节。传统备课往往需要反复研读课程标准、搜集整合零散资料、精心打磨教学语言,流程繁琐且重复性高。如今,借助豆包AI这类智能工具,教师可以将部分结构性、重复性的工作交由AI助手处理,从而将更多精力聚焦于核心的教学创意与

Trae能否支持大型C++项目的代码补全与开发
Trae的C++智能功能依赖clangd语言服务器。需确保clangd版本不低于15 0 0并正确安装插件。项目需生成compile_commands json编译数据库,CMake项目可通过参数生成,Makefile项目可使用bear工具。在Trae配置中指定clangd路径并启用后台索引等参数。针对Qt或Boost等框架,需额外配置使其识别特定编译规则。

Trae自定义代码模板与代码片段配置使用指南
通过配置用户代码片段,可将高频代码块设为快捷指令实现快速补全。安装文件模板插件能标准化新建文件的初始结构和头部信息。启用TraeAgent的代码知识图谱功能,可自动分析项目代码并智能推荐相关片段,实现代码的智能复用。

考研英语阅读理解训练技巧 海螺AI长难句分析与解题思路详解
海螺AI能辅助考研英语阅读训练,通过解析长难句语法结构并标注成分,帮助用户理解句子逻辑。它还可分析题目选项,识别干扰类型以掌握出题思路。此外,工具支持自定义词库高亮学术词汇,并关联真题考法,同时能生成个性化错因报告,针对弱点提供强化训练,从而提升复习效率。

豆包AI智能邮件回复高效方法与实战指南
豆包大模型可构建智能邮件回复系统,需注意其能力边界。关键实践包括:调用API时设置temperature=0 3以提升稳定性;编写prompt时注入客户历史与订单等完整上下文,避免生成重复或不准确回复;对返回文本进行本地后处理,完成变量替换、敏感词过滤和格式清洗;处理附件应先通过OCR提取并归一化关键信息,再拼接。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
