




卡帕西引爆硅谷公开第二大脑黑科技1250万人围观

AI圈这两天又被一个人引爆了。不是Sam Altman,也不是马斯克,而是那个低调、却每次出手都能掀翻桌子的男人——Andrej Karpathy。
这次,他做了一件看起来更“朴素”的事:公开了自己的知识管理方式。就这么简单?没错。但恰恰是这份“简单”,让整个开发者社区炸了锅。他在X上随手发的一条帖子,短短几天收获了1200多万次围观。

卡帕西揭示了一个核心趋势:大模型的下一个战场,或许不是写更多代码,而是管理更多知识。他给出的方案叫做“LLM Wiki”——一种让大模型担任全职知识管家,24小时不间断整理、更新、自检个人知识库的全新范式。
GitHub上他附带的一份“想法文件”,不到12小时就拿下超2100颗Star。
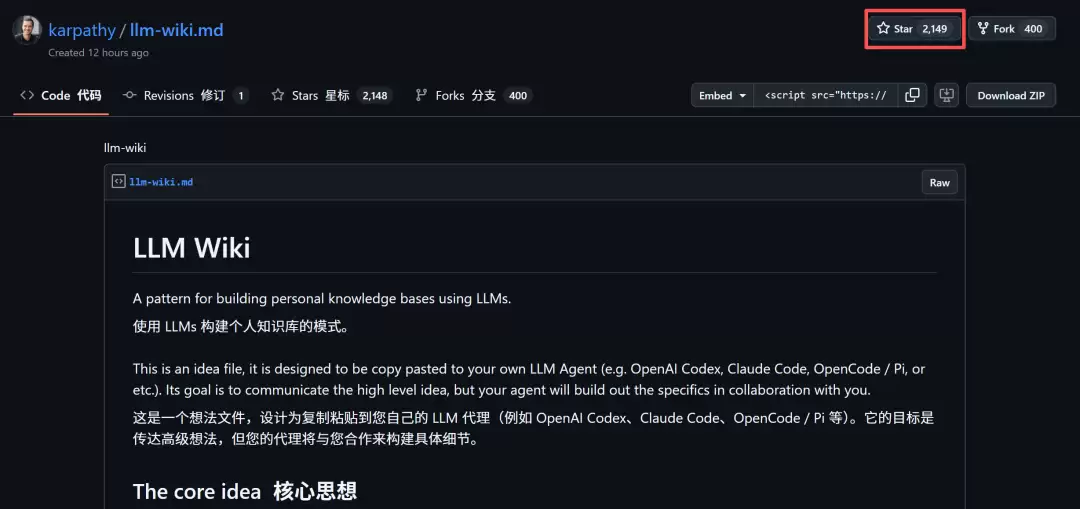
开发者Farza紧随其后,直接用这套思路,把自己2500条日记、笔记和iMessage消息,让大模型“编译”成了一个拥有400篇结构化文章的个人Wiki百科——Farzapedia。这本质上是一个给AI Agent用的、关于“你自己”的百科全书。
听起来很科幻?但它已经在运行了。
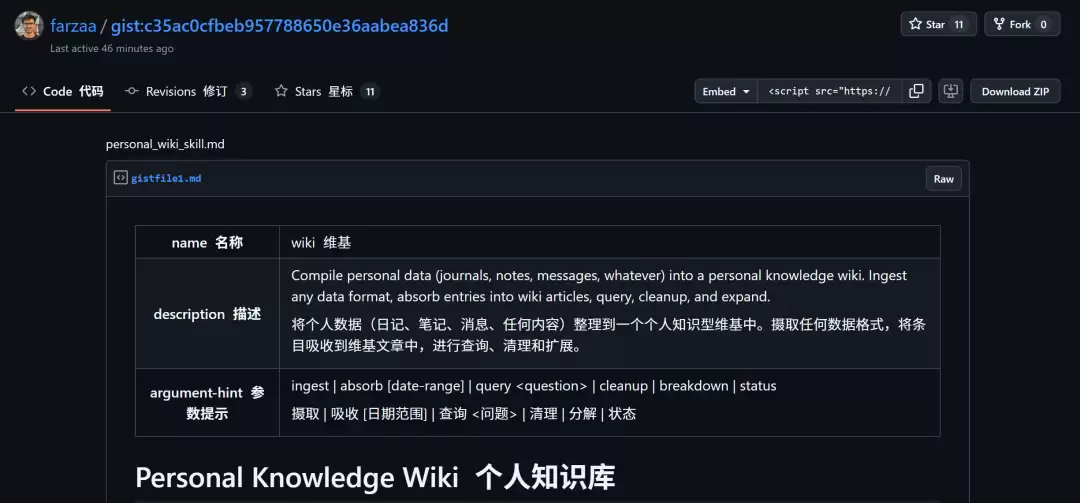
LLM Wiki 到底是什么?
不妨先回忆一下你自己的日常:读了一篇好文章,收藏了;看了一篇论文,存了个PDF;开会记了一段笔记,扔进了Apple Notes;在群里看到一个不错的观点,截了个图……然后呢?然后就没有然后了。
三天后你需要用到某条信息,翻遍所有App、所有文件夹,就是找不到。要么是关键词想不起来,要么是存的地方太分散,要么干脆就是——记得看过,但忘了在哪看的。信息越多,大脑越乱;收藏越勤,遗忘越快。这就是传统知识管理的死xue:它需要你不断花时间手动整理,而人类天生懒得整理。
那AI能帮忙吗?当然能。目前最主流的做法叫RAG(检索增强生成):把一堆文档切成碎片,存进向量数据库,用户问问题时,AI去“搜”相关片段,拼凑出答案。NotebookLM、ChatGPT的文件上传功能,本质上都是这个路子。
RAG好不好用?能用,但不够好。卡帕西一针见血地指出了RAG的根本问题:它每次都在从零开始“重新发现”知识。你今天问一个需要综合五篇论文才能回答的问题,AI把碎片翻一遍给你拼个答案。明天你换个角度再问,它得重新翻一遍、重新拼一遍。什么都没有积累下来,什么也没有建立起来。用卡帕西的原话说:“没有积累。”(There's no accumulation.)
那他的方案是什么?让大模型不是每次“搜”你的文件,而是把你的文件“编译”成一部活的百科全书。这就是“LLM Wiki”的核心思想。
LLM Wiki的完整架构
卡帕西在GitHub Gist上公开了他的完整构想。虽然他刻意写得比较“抽象”——因为他认为在AI Agent时代,分享的应该是想法而非具体代码,让每个人的Agent去根据想法定制实现——但整套系统的骨架其实非常清晰。
第一层:原始数据(Raw Sources)
这就是你的素材库。论文、文章、代码、图片、数据集……统统扔进一个raw/文件夹。不需要你整理,不需要你分类,扔进去就行。这一层是“不可变”的——大模型只读取,绝不修改。这是你的信息源头、真相之本。卡帕西推荐用Obsidian Web Clipper浏览器插件,看到好文章一键转成Markdown,再用快捷键把图片全部下载到本地,确保以后源链接挂了图也不会丢。
第二层:Wiki(The Wiki)
这是整个系统的核心。大模型读完raw/里的素材后,不是简单地“索引”它们,而是主动地“编译”出一整套结构化的Wiki。
什么叫“编译”?就像编译器把你的源代码变成可执行程序一样,大模型把你的“原始资料”变成了一部可导航、可查询、互相引用的知识体系。具体来说,大模型会做这些事:给每篇素材写摘要,抽取关键概念,为重要主题撰写独立文章,在不同页面之间建立反向链接,维护一个总索引文件(index.md),记录操作日志(log.md)。
你几乎不用手动编辑Wiki里的任何内容。写文章的是大模型,打标签的是大模型,建链接的也是大模型。用卡帕西自己的话说——Obsidian是IDE,大模型是程序员,Wiki是代码库。
第三层:规则文件(The Schema)
这是一份“说明书”,告诉大模型这个Wiki怎么组织、有什么规矩、遇到不同情况该怎么操作。比如在Claude Code里是CLAUDE.md,在OpenAI Codex里是AGENTS.md。这份文件由你和大模型“共同进化”——你用着用着发现什么规则好用就加上去,什么不好用就改掉。
四大操作:导入、查询、输出、自检
架构搭好了,日常怎么用?卡帕西给出了四个核心操作。
操作一:导入(Ingest)
把新素材扔进raw/,告诉大模型:“处理这个。”大模型读完之后,会跟你讨论关键发现,然后写一篇摘要页,更新总索引,并且在整个Wiki中找到所有相关的页面——可能是某个概念页、某个人物页、某个对比页——逐一更新。一篇新素材可能会触发10到15个Wiki页面的联动更新。卡帕西个人喜欢一次导入一篇素材,边导入边看大模型写的摘要,确保方向对了。当然你也可以批量导入,一口气扔100篇论文,让大模型自己慢慢消化。
操作二:查询(Query)
一旦Wiki积累到一定规模,你就可以对着它问各种复杂问题了。卡帕西自己的一个研究Wiki攒了大约100篇文章、40万字。他本以为这个规模得搞一套复杂的RAG才行——结果发现根本不需要。为什么?因为大模型平时把索引文件和摘要维护得很好,它先读索引,找到相关页面,再钻进去细看。40万字的规模,轻松应对。而且查询的输出格式不限于文字——可以是Markdown文章,可以是Marp格式的幻灯片,可以是matplotlib图表,任何你想要的可视化形式。
操作三:回填(File Back)
这是最精妙的一步:把查询结果存回Wiki。你问了一个对比分析的问题,大模型给了一份精彩的回答——这份回答本身也是有价值的知识。卡帕西的做法是把这些输出“归档”回Wiki,让它成为Wiki的一部分,供未来的查询使用。你的每一次提问,都在让知识库变得更丰富。用的越多,它越聪明。这不是消耗,是投资。
操作四:自检(Lint)
定期让大模型给Wiki做一次“体检”。检查什么?数据不一致的地方;新素材推翻了旧结论的地方;有引用但没有独立页面的重要概念;孤立的、没有任何链接指向的页面;通过网络搜索可以补全的信息空缺。这让整个Wiki不仅保持健康,还在不断生长。VentureBeat对此有一个精彩的评价:“这就像一个能自我修复的活知识库。”(It acts as a living knowledge base that actually heals itself.)
到这里,你会发现卡帕西做出来的东西,跟传统知识库完全不是一回事了。传统知识库是一个需要你不断喂养的存储工具,而LLM Wiki是一个自运行的知识引擎——大模型负责整理、更新、自检、生长,人类只需要做一件事:思考。
Farzapedia:当你的一生被「编译」成百科全书
如果说卡帕西给出了理论框架,那开发者Farza就是第一个把这套理论“跑通”的人。Farza做了一件听起来有点疯狂的事:他把自己的2500条日记、Apple Notes笔记和部分iMessage对话全部喂给了大模型,让AI从中“编译”出了一部关于他自己的个人Wiki百科——Farzapedia。
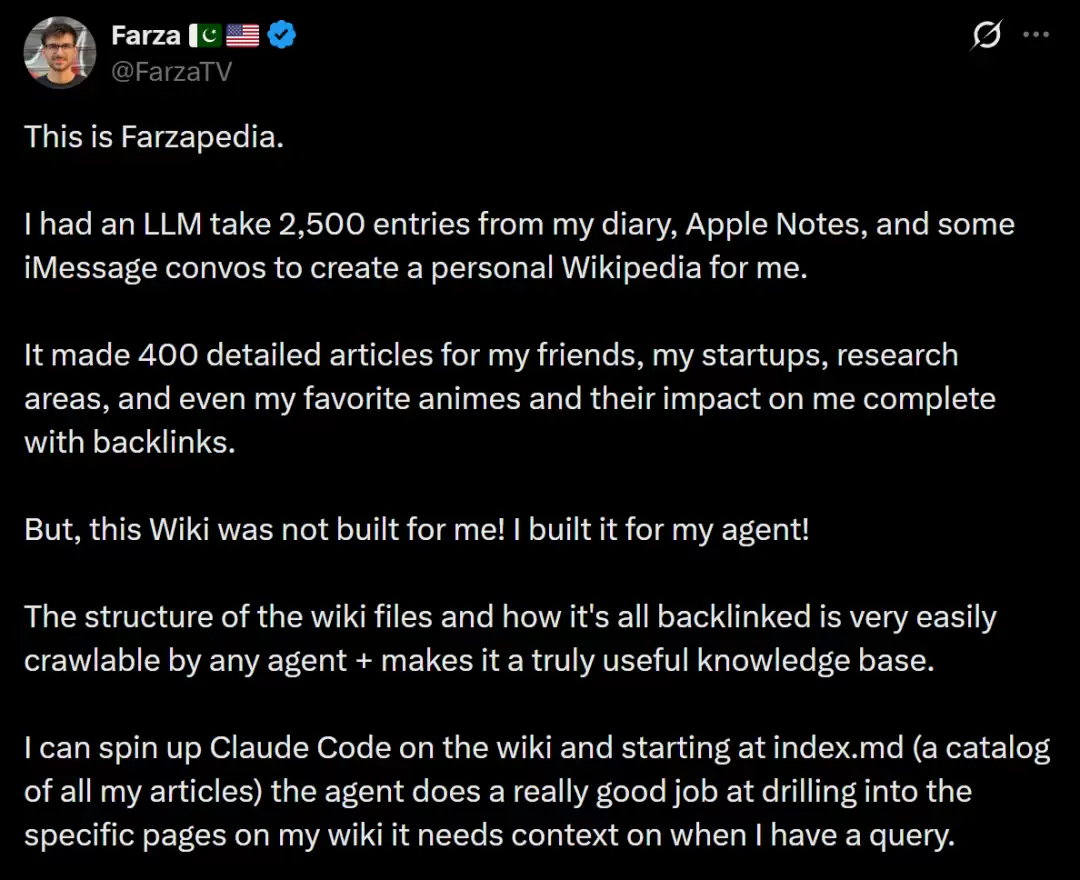
这部“百科全书”包含400篇详细文章,覆盖了他的朋友们、他创办过的公司、他的研究领域、甚至他最爱的动漫以及这些动漫对他的影响。每篇文章都带有反向链接,形成了一个完整的知识网络。
但最关键的一点是——Farzapedia不是给Farza自己看的,是给他的AI Agent用的。整个Wiki的结构和链接方式,天然适合Agent爬取。Farza用Claude Code打开这个Wiki,Agent从index.md(总目录)开始,可以像蜘蛛一样顺着链接一层层钻到它需要的具体页面。
举个例子:Farza在设计一个新项目的落地页,他问Agent:“我最近有什么影响了我审美的电影和图片?帮我找找灵感。”Agent怎么做的?它在Wiki里找到了Farza的“哲学”文章——那里记录了他看一部吉卜力纪录片时的笔记;找到了“竞品分析”文章——里面有他截图保存的YC公司落地页;甚至翻出了他几年前存的1970年代披头士乐队周边商品的图片。结果Agent给出了一份极其精准、极其“懂他”的创意方案。
Farza坦言,他一年前用RAG搭过类似的系统,但体验很差。而基于文件系统的知识库,让Agent通过它真正理解的目录结构去查找信息,效果天差地别。
而Farzapedia最神奇的地方在于——它是“活”的。当Farza往Wiki里添加新内容(一篇文章、一张灵感图、一份会议纪要),系统会自动判断这条新信息应该归入哪2到3篇已有文章,或者干脆创建一篇新文章。用Farza的比喻:“它就像一个超级天才图书管理员,专门管理你的大脑——它永远在帮你把东西归到最合适的位置,而且它从不疲倦。”
权力归你
卡帕西在转发Farzapedia时,用了一段话来阐述他为什么如此推崇这种知识管理方式。这段话值得仔细品味,因为它透露了一种关于“AI时代个人数据主权”的深层思考。
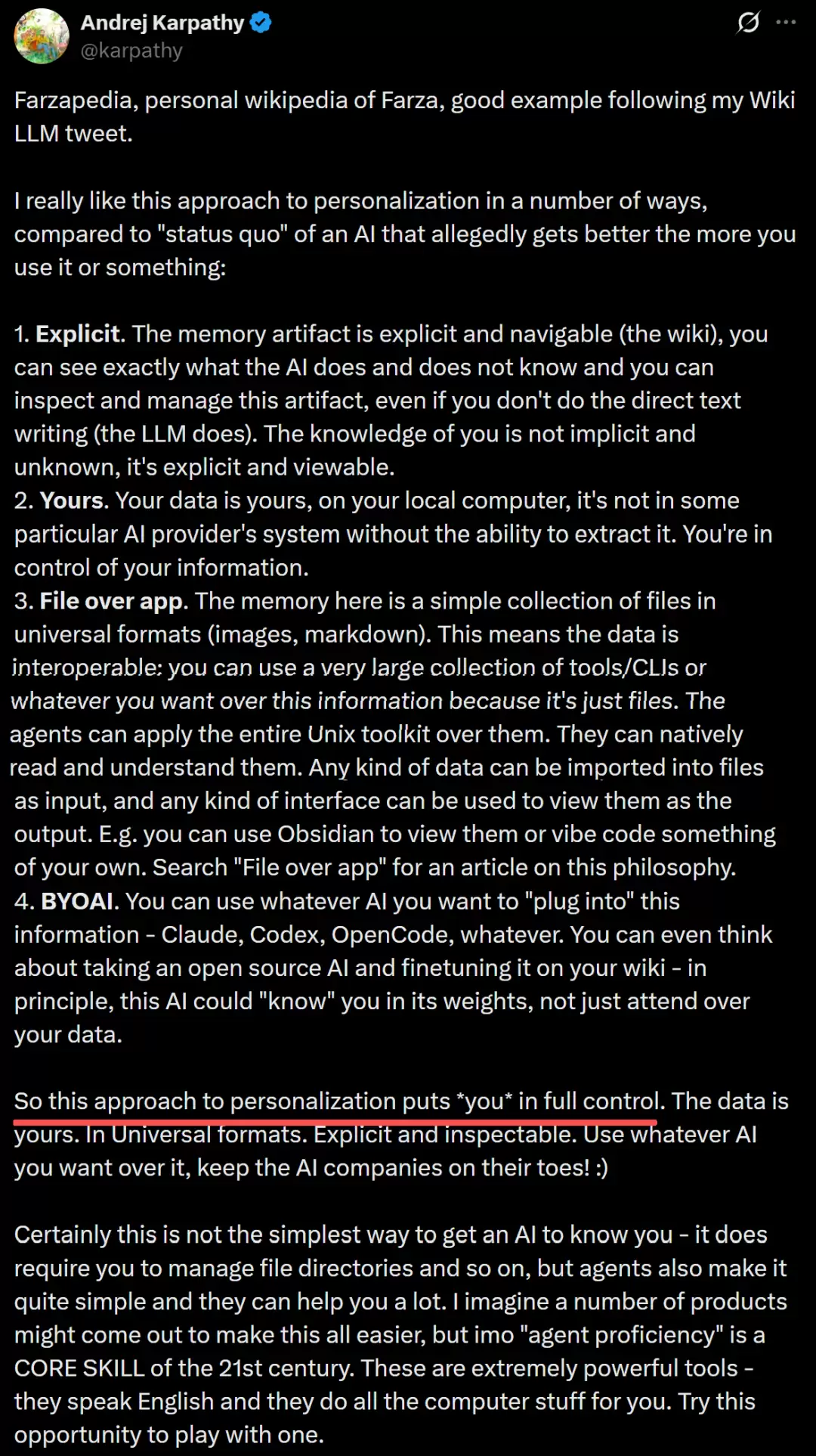
他归纳了四个核心优势:
第一,显式(Explicit)。你的知识不是藏在某个AI的“隐式记忆”里——那种你看不见、摸不着、也不知道它到底记了什么的黑箱。Wiki是显式的、可导航的,你可以清清楚楚看到AI知道你什么、不知道你什么,可以检视和管理这份“记忆制品”。
第二,你的(Yours)。数据就在你的本地电脑上,不在某个AI厂商的云端系统里。你不需要担心“我的数据被谁拿去训练了”,也不用恐惧“如果哪天换了AI服务商,我的记忆还能不能带走”。
第三,文件优于应用(File over App)。整个知识库就是一堆Markdown文件和图片——最通用的格式。任何工具都能读取它们,任何Agent都能操作它们,你可以用Obsidian看,也可以自己写个界面来看。这叫“互操作性”。
第四,自带AI(BYOAI - Bring Your Own AI)。你想用Claude就用Claude,想用Codex就用Codex,想用开源模型就用开源模型。甚至你可以把Wiki当训练数据,微调一个“打从权重层面就认识你”的专属AI。AI厂商之间的竞争?让他们卷去,你只管挑最好的用。
卡帕西的总结很干脆:这种个性化方案把你放在了完全的控制位上。数据是你的,格式是通用的,内容是透明的。用哪个AI随你挑,让AI公司们保持紧张吧!
知识的「编译时代」来了
回头看卡帕西的LLM Wiki,你会发现它的精神内核其实并不新。1945年,美国科学家Vannevar Bush在那篇著名的论文《As We May Think》中,就提出过一个叫“Memex”的构想——一个个人化的、持续策展的知识存储系统,文档之间由“关联线索”(associative trails)连接起来。

Bush认为,文档之间的连接和文档本身一样有价值。这个想法比互联网还早了半个世纪。后来,互联网确实实现了文档的连接,但走向了公共化、碎片化,而非个人化、结构化。Bush当年没能解决的问题只有一个:谁来做维护?
现在,大模型解决了这个问题。卡帕西的方案,本质上是对Bush的Memex做了一次“现代编译”:AI负责所有枯燥的维护工作——更新交叉引用、保持摘要最新、发现新旧数据的矛盾、维护几十上百个页面之间的一致性。人类之所以放弃维护知识库,不是因为不想,而是因为维护成本增长得比价值更快。大模型消除了这个瓶颈。
我们正在目睹一个新范式的诞生——从“AI搜索信息”到“AI编译知识”。在这个范式里,大模型不再只是一个你问什么它答什么的“搜索引擎”,而是一个持续运转的“知识编译器”。你的人生经历、工作素材、阅读记录、灵感碎片,都是它的“源代码”。而它的产出,是一部只属于你的、永远在生长的、从不遗忘的“第二大脑”。
人类负责思考,AI负责记住。这可能是大模型最“朴素”、却也最深刻的一个应用方向。不炫技,不烧钱,不需要百万Token的上下文窗口,不需要复杂的向量数据库——就是一堆Markdown文件,加上一个勤劳的AI图书管理员。
1945年,Vannevar Bush只能把Memex画在纸上。2026年,你可以把它跑在你的笔记本电脑上了。未来已来。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

政府项目申报材料写作指南 海螺AI使用教程
利用AI工具辅助撰写政府项目申报材料,能够显著提升工作效率。然而,许多实践者反馈,AI生成的内容常常存在“政策契合度不足、结构不规范、数据引用不严谨、表述口语化”等问题,缺乏公文应有的严肃性与专业性。 问题的关键通常不在于AI模型的能力局限,而在于我们提供的“指令”不够精确。AI输出出现偏差,核心在

智谱清影绘制晨雾河流倒影的宁静画面教程
想要在智谱清影中生成晨雾朦胧、河流静谧、树木倒影清晰的画面,关键在于掌握AI对复杂氛围的“理解”逻辑。直接输入“晨雾中的河流”往往效果不佳,画面容易过亮、过实,雾气与倒影难以和谐共存。下面这套系统方法,通过精准的提示词组合、关键参数调整与分层合成技术,能有效引导模型输出富有水墨意境的宁静画面。 一、

Vidu软件运行需要什么电脑配置
如果你在尝试用Vidu生成高质量视频时,遇到了渲染失败、频繁卡顿或者导出意外中断的情况,那很可能是因为你的电脑硬件还没达到它稳定运行的基本要求。别担心,这就像跑大型3A游戏,配置到位了,体验才能流畅。下面我们就针对不同的使用强度,来详细拆解一下所需的硬件配置以及一些关键的优化思路。 一、基础配置:保

Trae AI代码补全功能实测准确率与使用体验
目前缺乏关于TraeAI代码补全功能的权威准确率数据。官方未公布验证过的量化指标或测试方法,也未提供置信度反馈或离线评估工具。用户可通过查阅文档、运行本地样本测试、检查日志和对比开源工具等方式,自行验证其上下文感知和补全质量,从而形成相对实际的认知。

夸克AI如何为摄影作品生成图片描述与社交媒体文案
夸克AI能帮助摄影爱好者高效生成图片描述和生成社交媒体文案。上传照片后,AI可智能识别构图、光影等元素,转化为专业描述,并针对不同平台定制推文风格。利用预设模板确保结构稳定,批量生成功能提供多种情绪维度的文案选择。嵌入摄影术语库还能校准输出,避免空泛表述,提升专业性。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
