




如何快速定位并解决程序内存泄漏问题

内存泄漏是C/C++开发者最常遭遇的棘手问题之一。程序在测试阶段运行稳定,一旦部署上线,内存占用便如幽灵般悄然攀升,最终导致进程因OOM(内存溢出)被强制终止,服务崩溃。重启后,问题循环往复。由于难以定位具体是哪块内存“只申请不释放”,添加日志排查也常常无从下手。
本文将系统介绍三种高效工具:Valgrind、AddressSanitizer(ASan)和Linux的/proc文件系统。它们优势互补,能够帮助开发者构建从开发调试到线上监控的完整内存泄漏排查体系。

一、内存泄漏的根本原因是什么?
首先需要明确概念。在C/C++中,堆内存需要开发者手动管理:通过malloc或new申请,通过free或delete释放。如果申请后未能正确释放,这块内存就将被进程永久占用,直至进程结束——这就是内存泄漏。
常见的泄漏场景主要包括以下几种:
// 场景一:直接遗忘释放
void func() {
char* buf = (char*)malloc(1024);
// ... 使用后忘记调用 free(buf)
}
// 场景二:异常路径未释放
void process() {
int* data = new int[1000];
if (check_error()) {
return; // 此处直接返回,导致 data 未被 delete[]
}
delete[] data;
}
// 场景三:容器存储指针,清理时未释放元素
std::vector object_cache;
void add_object() {
object_cache.push_back(new int(42));
}
void clear_cache() {
object_cache.clear(); // 仅清空容器,未释放指针指向的内存
} 这些情况的共同点在于:动态申请的内存最终失去了所有指针的引用,成为系统中无法被回收的“孤儿内存块”。
二、三大工具的核心定位与分工
在深入使用前,有必要厘清每个工具的适用场景:
- Valgrind:功能最全面,能精确定位泄漏发生的具体代码行,适合在开发阶段进行深度根因分析。
- AddressSanitizer (ASan):运行速度最快,能在程序崩溃或退出时立即报告错误,性能开销小,甚至可用于准生产环境测试。
- /proc文件系统:零侵入性,用于监控线上运行程序的内存变化趋势,无需对程序进行任何重编译。
简而言之,开发阶段使用Valgrind或ASan定位具体泄漏点;线上运维则先用/proc确认是否存在泄漏趋势,再回到测试环境用前两种工具复现和深入排查。
三、Valgrind:精准定位泄漏的利器
1. 使用方法
# 安装工具
sudo apt install valgrind
# 编译时必须添加 -g 选项以保留调试符号(否则报告只有地址,无代码行信息)
g++ -g -O0 my_program.cpp -o my_program
# 运行检测
valgrind --leak-check=full --show-leak-kinds=all ./my_program其中,--leak-check=full是关键参数,它会指示Valgrind报告每一处泄漏的完整调用堆栈。
2. 解读检测报告
以下面这段存在泄漏的代码为例:
// leak_example.cpp
#include
void allocate_memory() {
char* buffer = (char*)malloc(256);
// 忘记调用 free(buffer)
}
int main() {
for (int i = 0; i < 5; i++) {
allocate_memory();
}
return 0;
} 运行Valgrind后,输出的报告类似如下:
==12345== HEAP SUMMARY:
==12345== in use at exit: 1,280 bytes in 5 blocks
==12345== total heap usage: 5 allocs, 0 frees, 1,280 bytes allocated
==12345== 256 bytes in 1 blocks are definitely lost in loss record 1 of 1
==12345== at 0x4C2FB0F: malloc (in /usr/lib/valgrind/...)
==12345== by 0x10869B: allocate_memory() (leak_example.cpp:4)
==12345== by 0x1086C3: main (leak_example.cpp:9)这里的definitely lost是最严重的泄漏类型,表明内存已确定丢失。调用堆栈清晰地指出:main函数的第9行调用了allocate_memory,而该函数第4行的malloc调用未被释放。
3. Valgrind的局限性
必须承认,Valgrind虽然精准,但代价高昂。它会使程序运行速度下降10至50倍。对于启动耗时较长的C++项目,附加Valgrind后运行测试等待半小时是常有的事。此外,它无法附着到已运行的线上进程进行实时检测,必须预先计划并单独启动。
此时,ASan的优势便凸显出来。
四、ASan:高效、及早发现问题的哨兵
AddressSanitizer(ASan)是LLVM/GCC编译器内置的插桩工具,无需额外安装。其性能开销远小于Valgrind(通常仅使程序变慢2倍左右),并且能检测一些Valgrind难以捕捉的问题,例如栈溢出、释放后使用(use-after-free)等。
1. 使用方法
# 编译时添加以下两个选项即可
g++ -g -fsanitize=address -fno-omit-frame-pointer my_program.cpp -o my_program
# 直接运行程序,无需额外命令
./my_program程序退出时,如果存在内存泄漏,ASan会自动打印出详细的错误报告。
2. ASan能检测更广泛的内存问题
// use-after-free:Valgrind有时会漏报,ASan几乎必现
int* ptr = new int(42);
delete ptr;
*ptr = 100; // ← 程序崩溃!ASan立即报告错误
// 堆缓冲区溢出:申请10字节,访问第11字节
char* buffer = (char*)malloc(10);
buffer[10] = 'x'; // ← ASan立即报告错误
// 栈缓冲区溢出
void stack_overflow() {
int local_array[5];
local_array[5] = 1; // ← ASan立即报告错误
}ASan的报告非常清晰。例如,对于use-after-free错误,它会明确指出:
==9876== ERROR: AddressSanitizer: heap-use-after-free on address 0x...
READ of size 4 at 0x... thread T0
#0 0x... in main my_program.cpp:6
#1 0x... in __libc_start_main
0x... is located 0 bytes inside of 16-byte region [0x...,0x...)
freed by thread T0 here:
#0 0x... in operator delete my_program.cpp:4报告直接告诉你:第6行代码读取了一块已经在第4行被delete的内存。
3. 工具对比总结
两者的核心差异可以通过下图一目了然:

五、/proc:线上内存监控的无侵入方案
Valgrind和ASan都需要重新编译程序,这在生产环境往往不可行。那么,当线上服务出现内存持续增长时,如何快速初步判断是否存在泄漏?答案是使用Linux的/proc文件系统。
Linux内核为每个进程在/proc目录下创建了一个虚拟文件夹,其中/proc/PID/status和/proc/PID/smaps文件实时记录了进程内存的详细信息,无需任何代码修改。
需要关注的关键指标如下:
# 首先获取目标进程的PID
pidof my_server
# 查看内存使用关键数据
cat /proc/1234/status | grep -E "VmRSS|VmSize"输出示例:
VmSize: 512340 kB ← 虚拟内存总量
VmRSS: 128456 kB ← 物理内存驻留集大小(实际占用,看这个)VmRSS(Resident Set Size)是进程实际占用的物理内存大小,是判断内存是否异常增长的关键指标。
判断是否存在泄漏的方法很简单:定期采样,观察其变化趋势。
# 每10秒采集一次RSS,观察趋势
while true; do
date
cat /proc/$(pidof my_server)/status | grep VmRSS
sleep 10
done如果VmRSS在业务流量平稳的情况下持续单调上涨,基本可以确认存在内存泄漏。
若需要更精细地观察堆内存的变化:
cat /proc/1234/smaps | grep -A 15 "heap"输出中的Size和Rss分别代表堆区的虚拟地址空间大小和实际物理内存占用。如果这两个值持续增长,说明堆内存正在扩张,泄漏很可能发生在堆上。
你可以快速编写一个简易监控脚本:
#!/bin/bash
PID=$(pidof my_server)
LOG_FILE=/tmp/memory_monitor.log
echo "Timestamp, RSS(kB)" > $LOG_FILE
while true; do
RSS=$(cat /proc/$PID/status | grep VmRSS | awk '{print $2}')
echo "$(date '+%H:%M:%S'), $RSS" >> $LOG_FILE
sleep 30
done运行数小时后,将日志数据绘制成图表,内存是平稳还是泄漏,便一目了然。
六、如何组合使用这三个工具?
明确分工,组合使用方能事半功倍:
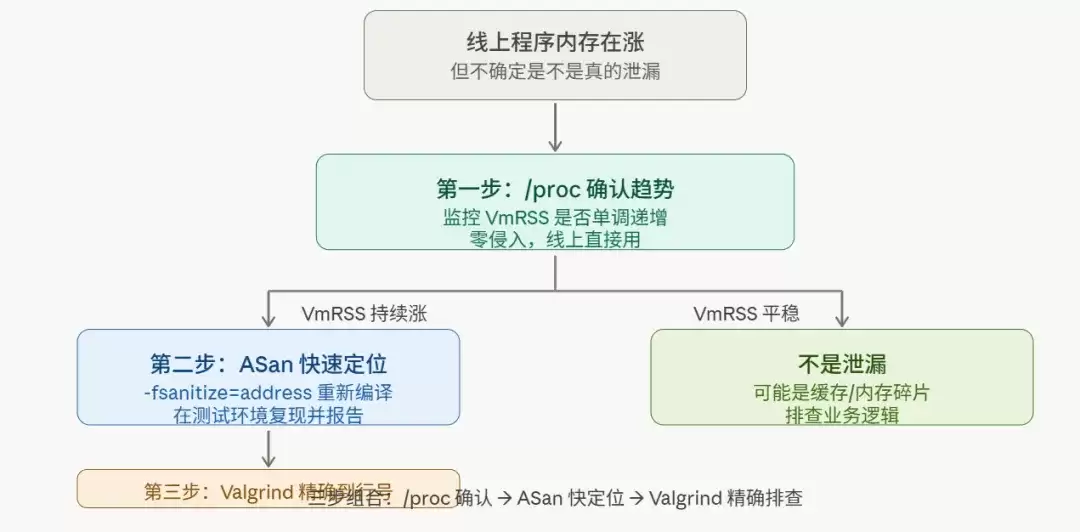
一个典型的高效排查流程是:
线上监控发现内存增长 → 使用/proc工具确认增长趋势 → 在测试环境使用ASan重新编译并复现问题 → ASan报告泄漏位置 → 若ASan未发现或需要更精确信息,则最终使用Valgrind进行深度排查。
七、根治之道:利用RAII从源头杜绝泄漏
工具排查终究是事后补救。最高效的策略是从设计上防止泄漏发生。对于C++而言,答案就是RAII(Resource Acquisition Is Initialization,资源获取即初始化)原则:将资源的生命周期与对象的生命周期绑定,对象析构时自动释放资源,无论程序从哪条路径退出。
// 避免手动 new/delete,使用智能指针
#include
void safe_process() {
// unique_ptr 离开作用域时自动 delete
auto data = std::make_unique(1000);
if (check_error()) {
return; // 安全!unique_ptr 析构,内存自动释放
}
use_data(data.get());
} // 作用域结束,自动调用 delete[],绝无泄漏 遵循简单的规则:
- 独占所有权使用
std::unique_ptr - 共享所有权使用
std::shared_ptr - 优先使用
std::make_unique和std::make_shared,避免直接使用裸new操作符
当智能指针成为编程习惯,Valgrind和ASan便会退居二线,成为最后的“安全网”,而非日常的“救火工具”。
八、实用命令速查手册
# ── Valgrind 相关命令 ─────────────────────────────────
# 安装
sudo apt install valgrind
# 编译(必须加 -g 调试符号)
g++ -g -O0 my_program.cpp -o my_program
# 运行并生成完整泄漏报告
valgrind --leak-check=full --show-leak-kinds=all ./my_program
# ── ASan 相关命令 ─────────────────────────────────────
# 编译(添加两个编译选项)
g++ -g -fsanitize=address -fno-omit-frame-pointer my_program.cpp -o my_program
# 直接运行,退出时自动报告
./my_program
# 仅检测内存泄漏(不报告UAF等其他错误)
ASAN_OPTIONS=detect_leaks=1 ./my_program
# ── /proc 监控相关命令 ────────────────────────────────
# 查看进程当前RSS
cat /proc/$(pidof my_server)/status | grep VmRSS
# 每5秒监控一次RSS变化
watch -n 5 'cat /proc/$(pidof my_server)/status | grep VmRSS'
# 查看堆内存的详细映射信息
cat /proc/$(pidof my_server)/smaps | grep -A 10 heap总结
内存泄漏是C/C++开发者必须面对的挑战。幸运的是,我们拥有强大的工具链。
本文介绍的三种工具构成了清晰的防御梯队:Valgrind如同高精度显微镜,能精确定位每一处泄漏的源代码行;ASan则像反应迅速的哨兵,检测范围广,是日常开发和测试的首选;而/proc文件系统提供了零成本的远程监控能力,让你在线上环境也能第一时间感知内存异常。
当然,最根本的解决方案始终是培养良好的编程习惯,积极拥抱RAII和智能指针,从源头上实现资源管理的自动化与可靠性。优秀的工具是强大的辅助,但严谨的代码设计与规范,才是彻底解决内存问题的根本良药。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

海尔暖通商用多品类领先行业增速114%稳居市场第一
4月27日,海尔智家正式发布了2026年第一季度财务报告。作为一家致力于向平台化、服务型科技生态企业转型的行业领导者,这份财报的深层价值,远不止于营收与利润的财务数字。当我们深入审视其暖通商用业务板块时,更能发现一系列在存量竞争市场中尤为突出的增长亮点与竞争韧性。 财报数据显示,海尔智家一季度实现营

2026全球CIS五大龙头投资评级与智能视觉增长趋势分析
2026年,当AI的触角深入产业的每一个角落,半导体行业的格局正在被重塑。作为智能世界的“眼睛”,CMOS图像传感器(CIS)的进化,正悄然驱动着手机、安防、汽车乃至万物互联的体验革新。全球CIS市场已步入高速增长通道,技术迭代、场景扩容与国产替代三重动力交织,让这个赛道的竞争格局与投资价值,迎来了

Ubuntu 2604 原生支持 NVIDIA CUDA 与 AMD ROCm 安装指南
对于长期在Linux平台进行GPU加速计算与AI开发的用户而言,一个影响深远的技术痛点终于迎来了官方解决方案。Canonical正式发布了代号为“Resolute Raccoon”的Ubuntu 26 04 LTS长期支持版本,其最核心的突破在于将NVIDIA CUDA和AMD ROCm这两大主流G

追觅火箭车亮相硅谷 零百加速09秒推力达100千牛
美国硅谷,一场以“DREAME NEXT”为主题的科技盛会于当地时间4月27日正式启幕。本次发布会的主角——追觅科技,不仅重磅推出了多款创新产品,更首次系统性地向全球展示了其构建“人车家”全场景智能生态的战略蓝图。 发布会现场,最引人瞩目的焦点无疑是那台代号为Nebula NEXT 01 JET E

阿里医疗AI再突破 胰腺癌胃癌肠癌筛查模型发布
4月28日,医疗AI领域迎来一项突破性进展。阿里巴巴达摩院携手广东省人民医院等权威机构,共同发布了全新的肠癌筛查AI模型——DAMO COCA。该模型创新性地提出了一种基于平扫CT的“无感”肠癌机会性筛查方案,患者无需进行繁琐的肠道准备。临床研究证实,该模型成功从2 7万份平扫CT影像中精准识别出5








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
