




具身智能新突破LIBERO终结者以物理推理革新机器人学习范式

机器人拉拉链,到底需不需要“脑子”?
过去几年,从OpenVLA到π0、π0.5,具身大模型已经能让机器人把指令和动作连得有模有样。但一个尴尬的现实是,一旦包裹的位置挪了几厘米,或者环境光照暗了一点,这些模型往往就会“大脑宕机”,动作变得不知所措。
问题出在哪?很大程度上,是因为这些机器人大多在玩一种高级的“连连看”:看到什么,就直接输出对应的动作。它们记住了成千上万条轨迹,却并不理解动作背后的物理逻辑。这种模式,显然遇到了隐形的天花板。
现在,一种让机器人“先想明白,再稳定行动”的新范式来了。由至简动力、北京大学、香港中文大学联合提出的LaST-R1,首次将隐空间的物理推理过程,塞进了强化学习的优化闭环里。这相当于给机器人装上了一套可以自我进化的“物理脑”。

它的表现有多夸张?几个数字足以说明:
- 仿真满分级别:在权威的LIBERO基准测试上,仅靠1条演示轨迹预热,平均成功率就冲到了99.9%;
- 真机性能起飞:在真实的抓取、旋转等复杂操作任务中,表现比目前最强的SOTA模型π0.5还要高出22.5个百分点。
- 强化“物理推理”:即便换了物体、背景或光照,它依然能稳如磐石。因为它不再是单纯的动作复刻机,而是真正学会了在隐空间里进行“物理思考”。
这个让机器人长出“物理脑”的LaST-R1,到底是怎么炼成的?那个能让环境反馈同时优化“怎么想”和“怎么动”的LAPO算法,又藏着什么玄机?
具身大模型的隐形天花板:只会模仿,不懂物理
尽管从OpenVLA到π0.5,具身大模型已经完成了图像、语言与动作的初步对齐,但在实际落地中,工业界发现了一个致命的“幻觉”:
能模仿,不等于能在物理世界泛化。
这就导致了极差的泛化性。打个比方,机器人可能记住了100种拉拉链的轨迹,但只要拉链的角度偏转15度,或者光照发生变化,单纯靠“观察→动作”的端到端映射就会立刻失效。
核心问题在于,现有的视觉-语言-动作模型缺少一个“思考”的中间层——即让机器人在行动之前,对物理世界进行推理。过去,学术界尝试引入语言思维链来解决推理问题,但对于机器人操作而言,语言推理往往太慢且颗粒度太粗,你很难用文字精准描述“拉链咬合时的细微阻力反馈”。
LaST-R1的核心突破,就是放弃了低效的语言思维链,转而在隐空间中构建物理推理链。它不再让机器人看到图像就“闭眼”出动作,而是先在隐性空间里建模场景的结构、物体的物理关系以及未来的动态变化。
然而,要让机器人学会这种“思考”,仅靠静态的模仿学习是不够的。目前的强化学习方法大多像是一个只看结果的严厉教练:它只告诉机器人动作成没成功,却无法指导机器人“刚才那下你是怎么想的”。
针对这一痛点,研究团队提出的LAPO算法,正式将“思考过程”拉进了强化学习的优化闭环,让环境反馈不仅优化动作,也优化行动前的“物理思考”。
不只练“手”更要修“脑”:如何让机器人强化模型的物理推理?
近日,至简动力、香港中文大学、北京大学计算机学院多媒体信息处理国家重点实验室,提出了一种面向机器人操作的自适应物理隐空间推理强化学习框架——LaST-R1。
它希望通过强化学习后训练,让具身大模型不仅学会生成动作,也学会在行动前,进行面向物理世界的隐空间推理。
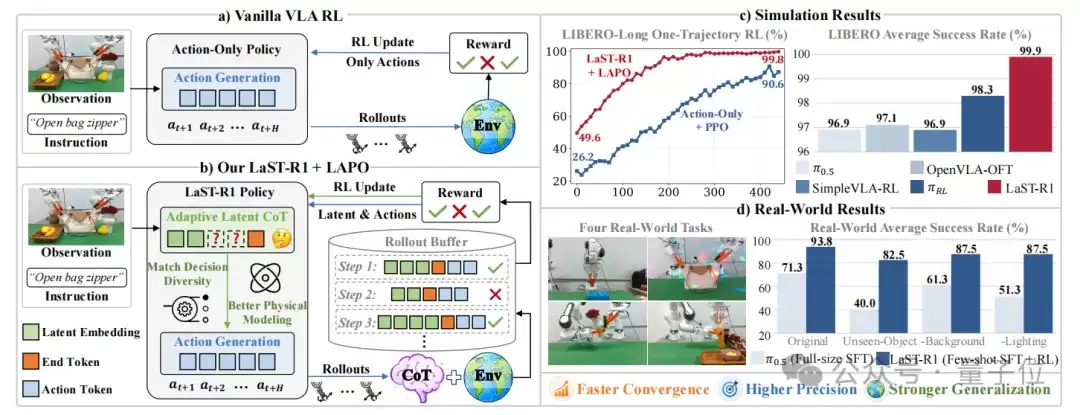 △LaST-R1概览
△LaST-R1概览
- (a) 不同于仅严格优化动作的传统强化学习方法,
- (b) LaST-R1利用LAPO联合优化自适应的隐空间思维链与物理执行过程。通过连接认知推理与控制,实现了
- (c) 更快的收敛速度、更高的仿真成功率,
- 以及 (d) 更强的真实世界泛化能力。
与以往主要优化动作空间的具身大模型强化学习不同,LaST-R1的核心思想是:机器人不应只从图像和指令直接预测下一步动作,而应先在隐空间中理解场景结构、物体关系和物理动态,再生成更稳定、精准的动作。
换句话说,LaST-R1不只优化机器人的“手”,也优化它的“脑”。
具体来看,LaST-R1构建了一个面向“先推理后行动”策略的强化学习后训练框架,核心由三步组成:
1. 物理隐空间推理建模
- 传统模型往往直接从观测生成动作,动作前缺少可建模、可优化的物理推理过程。
- LaST-R1在模型推理中引入隐空间思维链:生成动作前,先在隐空间中建模当前场景、物体关系和未来物理动态。
- 相比语言推理,隐空间推理更适合承载连续、高频、难以语言化的物理信息。
2. 隐空间推理与动作生成的联合强化优化
- 传统强化学习多数只优化动作结果:哪个动作带来更高奖励,就强化哪个动作。
- LaST-R1提出LAPO,把环境奖励同时作用于隐空间推理和动作生成:成功轨迹不仅强化正确动作,也强化动作之前的“好推理”;失败轨迹不只修正动作结果,也反向调整内部物理推理空间。
3. 自适应隐空间思维链推理机制
- 不同任务决策需要不同长度的思考。LaST-R1引入自适应隐空间思维链:简单状态下,模型可以快速结束推理并执行;面对拉拉链、擦花瓶、拧瓶盖等复杂接触式操作,则分配更长的推理时长。
- 让机器人在交互中学会:什么时候该多想,什么时候该立刻执行。
LaST-R1改变的,是具身大模型后训练的优化对象:从只优化动作,转向同时优化动作背后的物理推理。
研究团队在仿真和真机环境中都进行了系统验证。在仿真LIBERO基准测试上,LaST-R1仅依赖1条轨迹完成预热,随后通过在线强化学习优化,最终取得99.9%的平均成功率,并展现出比仅优化动作的方法更快的收敛速度和更高的最终性能。
在真机部署中,LaST-R1仅使用30条轨迹预热,再通过强化学习后训练将平均成功率从52.5%提升到93.75%,显著超过使用100条专家轨迹的π0.5模型(71.25%)。
更重要的是,在真实扰动条件下,LaST-R1仍保持较小的性能下降,这说明其学习到的不是单一场景中的动作轨迹,而是更可迁移的空间语义和物理动态理解。
上述结果意味着,具身大模型强化学习的重点正在发生深刻变化——机器人不再只是通过强化学习学会更熟练地执行动作,而是开始学会更合理地进行物理推理。LaST-R1提出了一种新的后训练范式,能够让环境反馈同时塑造机器人的“思考方式”和“行动方式”。
一旦隐空间推理从模仿学习的“静态脚本”进化为强化学习的“演进核心”,机器人便能摆脱对演示数据的刻板复现,在不断的交互试错中,真正强化其内在的物理推理能力。这或许也是具身大模型从“会模仿”走向“会适应”的关键一步。
LaST-R1框架概述
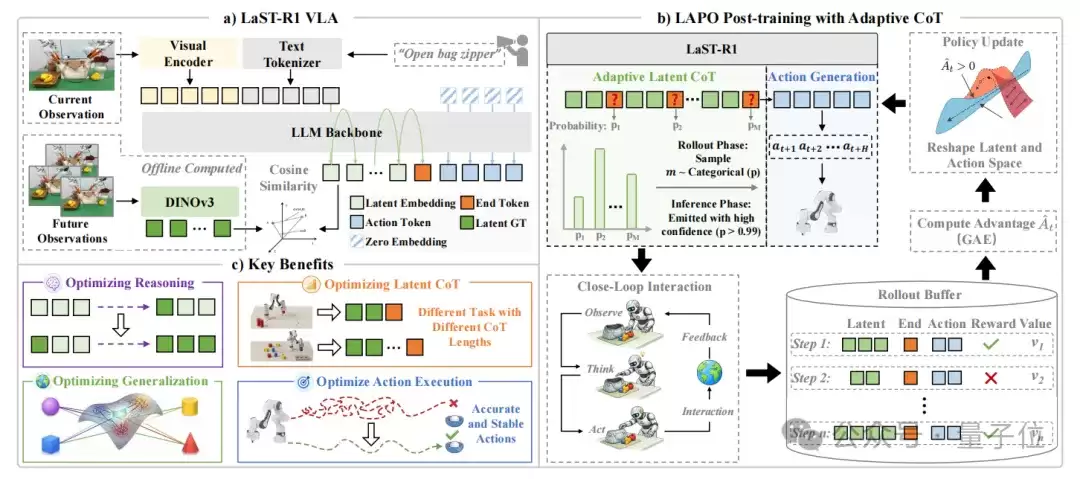 △LaST-R1框架
△LaST-R1框架
- (a) LaST-R1是一个统一模型,以视觉观测和语言指令作为输入,其中视觉基础模型提供具有物理语义约束的隐空间目标,用于在动作生成前引导隐空间思维链推理。
- (b) 在LAPO强化学习后训练过程中,LaST-R1以闭环方式与环境交互,并将隐状态、动作和奖励存储起来,以联合重塑隐空间与动作空间。模型通过基于预测概率学习生成特定标记,实现自适应推理,从而在不同任务中动态调整推理长度。
- (c) 通过LAPO,LaST-R1能够在多样化任务中形成自适应推理长度,从而提升泛化能力与执行稳定性。
整个LaST-R1框架可以概括为三个关键阶段:先推理、再优化、动态决定想多久。
第一阶段:行动前的隐空间推理
给定当前视觉观测和语言指令,LaST-R1不会直接生成动作,而是先生成一段隐空间推理嵌入,作为行动前的“物理思考”,用于建模物体关系、未来状态和操作动态。随后,模型再基于这些隐空间推理并行生成动作标记。这一步解决的是如何让动作生成建立在物理推理之上。
第二阶段:LAPO同时优化隐空间和动作
LaST-R1的核心算法是LAPO。传统方法主要优化动作,而LAPO将隐空间推理也纳入强化学习目标,让环境奖励同时塑造“怎么想”和“怎么动”。
论文中最关键的是隐空间层面的比率替代函数:
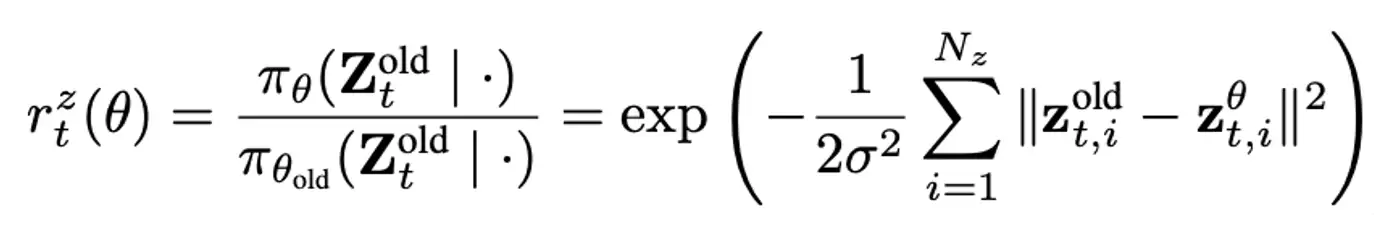
其中,
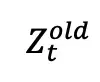
表示旧策略生成的隐状态序列,
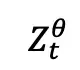
表示当前策略重新生成的隐状态序列,
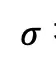
控制隐状态分布的宽度。
直观来说,如果某条轨迹成功,LaST-R1不仅会强化对应动作,也会强化动作之前产生的“好推理”。随后,LAPO将隐空间和动作的优化目标统一在一个裁剪目标函数中。这意味着LaST-R1的强化学习后训练不只是优化机器人的动作结果,也在优化行动前的物理推理过程。
第三阶段:自适应隐空间思维链
不同任务需要不同的思考长度。因此,LaST-R1引入自适应隐空间思维链,通过一个特殊的结束标记,让模型动态决定何时结束隐空间推理并进入动作生成阶段。这是为了让机器人根据任务难度自适应分配“思考”预算。也就是说,LaST-R1不是让机器人每一步都固定想同样久,而是让它学会:简单状态快速执行,复杂状态多想一步。
实验结果分析
1. 仿真实验:LIBERO 99.9%
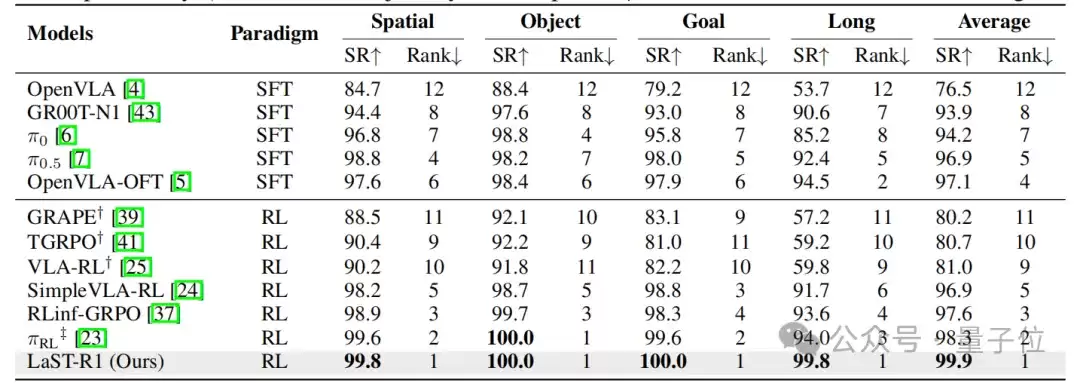
LaST-R1在LIBERO基准测试上进行了系统评估,覆盖空间、物体、目标和长程四个任务套件。实验在单条轨迹模仿学习预热的设置下进行,随后进入在线强化学习后训练。
结果显示,LaST-R1在四个套件上分别达到99.8%/100.0%/100.0%/99.8%的成功率,平均成功率达到99.9%,超过了多个强基线模型。相比只优化动作空间的方法,LaST-R1收敛更快、最终成功率更高,说明隐空间推理与动作生成的联合优化能够为强化学习提供更稳定的“认知缓冲区”,从而提升复杂长程操作能力。
2. 真机实验:从52.5%到93.75%
LaST-R1在四个真实操作任务上进行了测试,覆盖单臂高精度插入、双臂协同、接触式擦拭和连续旋转等复杂物理交互。为了突出强化学习后训练的效果,论文将其与SOTA模型π0.5对比:π0.5使用100条专家轨迹进行模仿学习,而LaST-R1仅使用30条轨迹预热,并通过强化学习后训练继续优化。
结果显示,LaST-R1将真机平均成功率从预热后的52.5%提升到93.75%,显著超过π0.5的71.25%。这说明其优势不仅存在于仿真环境,也能迁移到真实物理交互中,并形成更稳定的执行策略。
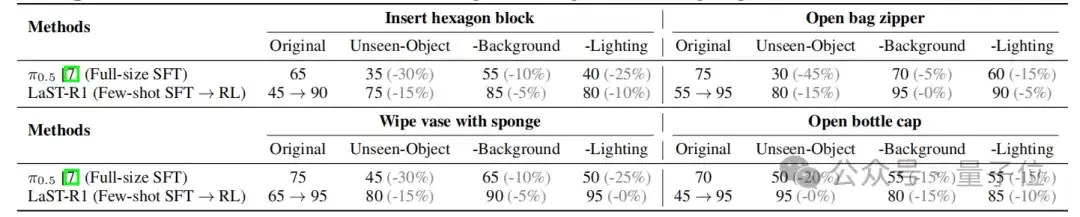
3. 泛化实验:换物体、换背景、换光照,依然稳

在LIBERO的分布外泛化测试中,研究团队采用9个已见任务进行在线强化学习,并保留1个未见任务做测试。结果显示,仅优化动作的方法容易出现性能停滞甚至退化,而LaST-R1能在分布外任务上持续提升,说明隐空间推理能帮助模型学到更可迁移的空间语义和物理动态。
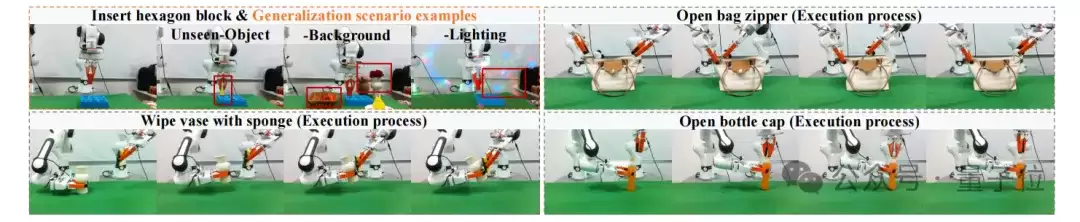
在真实世界中,论文进一步测试了未见物体、背景变化和光照条件三类扰动。相比仅经过模仿学习的π0.5模型,LaST-R1在这些变化下保持了更小的性能下降,说明它并不是简单记住训练场景中的动作轨迹,而是形成了更鲁棒的物理推理与动作生成能力。
结语:具身大模型不只是要会行动,而是开始学会“思考推理”
LaST-R1的意义,不只是把LIBERO平均成功率推到99.9%,也不只是让真机任务成功率提升到93.75%。更重要的是,它提出了一种新的具身大模型后训练范式:强化学习不应该只优化机器人的动作,也应该优化动作背后的物理推理过程。
过去,我们更关心机器人能不能生成正确动作。现在,LaST-R1在此基础上进一步追问:机器人能不能在行动前进行正确的物理推理?
通过LAPO,环境奖励可以直接塑造隐空间推理;通过自适应隐空间思维链,机器人可以根据任务难度动态调整思考长度。这意味着,机器人不再只是复现演示数据中的动作轨迹,而是在交互中逐步强化其内在的物理推理模型。
从这个角度看,LaST-R1让具身大模型强化学习从“看见就动”走向“先想明白,再稳定行动”。当具身大模型开始学会在隐空间中思考,机器人距离真正的自主与适应,无疑又近了一步。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

DeepSeek V4模型的主要不足与未来改进方向
DeepSeek-V4未集成Engram模块。该模块由DeepSeek与北京大学联合研发,旨在通过原生知识查表机制分离静态查询与深度推理,以提升效率。相关理念已应用于CXL内存池化以突破存储瓶颈,并经实证检验后成功迁移至视觉模态,为下一代模型发展提供了重要探索路径。

智会心研免费开放高级检索与AI深度分析功能
智会心研宣布其核心AI功能面向个人用户免费开放。该平台提供高级检索、AI伴读、图表分析等工具,帮助用户快速获取并深度分析全球产业技术数据。同时开放多智能体协作,包括专利技术路线和创新方案挖掘智能体,旨在降低使用门槛,辅助研发与决策过程。

Inworld AI实时语音合成模型TTS-2技术解析与应用
在对话式AI领域,让机器“开口说话”早已不是新鲜事,但如何让它说得自然、有感情,甚至能“察言观色”,一直是技术攻坚的难点。最近,Inworld AI推出的Realtime TTS-2模型,似乎在这个方向上迈出了关键一步。它不再仅仅是将文本转为语音,而是试图让AI真正“听懂”对话的弦外之音,并据此做出

OpenAI在美国面临集体诉讼 ChatGPT被指泄露用户隐私给谷歌和Meta
OpenAI在美国加州面临集体诉讼,被指控在ChatGPT中嵌入MetaPixel和GoogleAnalytics等追踪工具,向第三方分享用户隐私数据。据称,泄露信息可能包括邮箱、用户ID及具体查询内容,涉及医疗、法律等敏感对话。尽管行业普遍使用追踪代码,但ChatGPT处理高度私密的对话,引发隐私担忧。法律层面,OpenAI隐私政策已声明可能共享数据用于分

小米米家空气净化器6国补新低 到手价1059元
小米米家空气净化器6近日上市,首发价1399元。叠加多重优惠后,实际到手价可降至约1059元,并享有一年质保与30天价保服务。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
