




英伟达揭示AI成本真相:为何每Token成本才是关键指标

传统数据中心的核心任务,曾是数据的存储、检索与处理。然而,进入生成式AI与袋里式AI时代,这些设施的定位已悄然转变——它们正演变为一座座“AI Token工厂”。当AI推理成为核心工作负载,其核心产出便不再是原始数据,而是以Token为载体的智能本身。
这一根本性的转变,要求我们对AI基础设施的经济效益评估方式,包括总体拥有成本(TCO),进行同步调整。遗憾的是,当前许多企业在评估时,目光仍停留在芯片的峰值规格、单纯的计算成本,或是每美元能买到的理论算力(即每美元FLOPS)上。
这里存在一个关键区别,我们不妨厘清一下:
算力成本,是企业为AI基础设施支付的费用,无论是租用云服务还是自建部署。
每美元FLOPS,衡量的是每投入一美元所换取的原始计算能力,但这股“蛮力”并不直接等同于现实中可用的Token产出。
每Token成本,则是指企业生成并交付每一个Token所付出的综合成本,通常以每百万Token的成本来计算。
前两者仅仅是“投入”指标。但当你的业务核心是围绕“产出”运转时,只盯着投入做优化,本质上是一种方向性的错配。真正决定企业能否规模化盈利的关键,恰恰是每Token成本。它是唯一能直接、综合反映硬件性能、软件优化、生态系统支持以及实际利用率的TCO指标。而目前,NVIDIA在这一核心指标上实现了行业领先的低成本。
什么在驱动每Token成本下降?
要理解如何优化每Token成本,我们得先看看它的计算公式:“每百万Token成本”是如何得出的。

在这个公式里,很多企业评估基础设施时,只把注意力放在了分子——即每GPU每小时的成本上。对于云部署,这对应着付给云厂商的小时费率;对于本地部署,则是摊销自有设施后得出的等效小时成本。
然而,降低每Token成本的真正钥匙,藏在分母里:最大化实际交付的Token产出。
这个分母背后,其实蕴含着两层商业逻辑:
其一,最小化每Token成本:当Token产出增加,代入公式后自然会拉低单位成本,从而为每一次AI交互服务挤出更多利润空间。
其二,最大化收入潜力:每秒能交付更多Token,也意味着每兆瓦电力能产出更多智能。这直接提升了AI服务的供给能力,使得在相同的基础设施投入下,AI驱动的产品与服务有望创造更高的收入。
所以说,如果只盯着分子看,就会完全忽略决定分母的那些复杂因素。我们可以把它想象成一座“推理冰山”:分子是水面之上显而易见、易于横向比较的部分;而真正决定实际Token产出的关键,都隐藏在水面之下。对AI基础设施的准确评估,必须从探究这片水下世界开始。

水面之上的问题(表层比较):
- 每GPU小时的成本是多少?
- 峰值PetaFLOPS性能和高带宽内存容量有多大?
- 每美元能买到多少FLOPS?
水面之下的分析(深度成本关键):
- 每百万Token的成本是多少?特别是针对当前部署最广泛的大规模混合专家(MoE)推理模型,这个成本是多少?
- 每兆瓦电力可交付多少Token?这对本地部署尤其关键,因为在土地、电力和基础设施上的资本投入巨大,最大化每单位能源产生的智能产出至关重要。
- 纵向扩展(scale-up)互连能否支撑MoE模型所需的“all-to-all”通信模式?
- 是否支持FP4精度?推理软件栈能否在保持高模型质量的同时充分利用FP4?
- 推理运行时是否支持投机解码或多Token预测,以提升用户体验的响应速度?
- 服务层是否支持解耦服务、KV缓存感知路由、KV缓存卸载等高级优化?
- 平台能否满足袋里式AI工作负载的独特需求,包括超低延迟、高吞吐以及处理长输入序列?
- 平台是否支持从模型训练、后训练优化到大规模推理的完整生命周期,并覆盖所有主流模型架构?这直接关系到基础设施的可互换性和总体利用率。
这里面的每一项——算法、硬件、软件优化——都必须切实有效且能够相互集成。否则,分母就无法最大化。一块看似“更便宜”的GPU,如果其每秒Token产出显著更低,最终反而会导致更高的每Token成本。只有能够实现全栈深度优化、确保各项优化相互增强的AI基础设施,才能持续提升整体效率,真正压低分母。
为什么每Token成本比每美元FLOPS更有说服力?
我们来看一组基于DeepSeek-R1模型的数据,它清晰地展示了理论指标与实际商业结果之间的巨大鸿沟。
如果单看算力成本,NVIDIA Blackwell平台的成本似乎是上一代Hopper的2倍左右。但这笔投入能换来多少实际产出?算力成本本身无法回答。如果仅用每美元FLOPS来分析,Blackwell相较于Hopper的优势大约只有2倍。
然而,实际测试结果却呈现出数量级的差异:Blackwell每瓦特电力产生的Token产出是Hopper的50倍以上,其每百万Token的成本更是降低到了Hopper的约1/35。
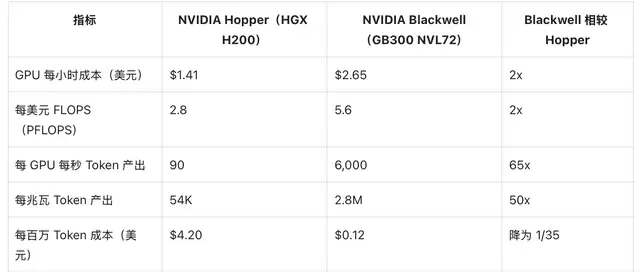
(注:数据来源于NVIDIA内部分析及SemiAnalysis InferenceX v2基准测试。)
这一悬殊的差距表明,相较于上一代Hopper,NVIDIA Blackwell带来的商业价值跃迁,远远超过了其系统成本的增加幅度。
如何做出明智的AI基础设施选择?
综上所述,仅凭算力成本或每美元理论FLOPS来比较不同的AI基础设施,不仅是不充分的,更无法真实反映推理经济学的全貌。正如数据所揭示的,要准确评估一项AI基础设施的营收潜力和盈利能力,必须将衡量维度从“输入指标”转向“产出指标”,即每Token成本和实际Token产出量。
NVIDIA通过其在计算、网络、内存、存储、软件及合作伙伴技术上的极致协同设计,实现了业内领先的低Token成本与高Token吞吐量。更重要的是,基于NVIDIA平台构建的整个软件生态——包括vLLM、SGLang、NVIDIA TensorRT-LLM和NVIDIA Dynamo等开源推理软件的持续优化——意味着即使在基础设施部署完成后,Token产出仍有提升空间,每Token成本有望持续下降。
这一优势已在领先的云服务提供商和NVIDIA云合作伙伴的规模化部署中得到验证。包括CoreWea ve、Nebius、Nscale和Together AI在内的合作伙伴,已经部署并优化了基于NVIDIA Blackwell的技术栈,为企业提供当前市场上极具竞争力的Token成本。它们正在充分发挥NVIDIA在硬件、软件与生态系统协同设计上的全部优势,确保每一次AI交互都构建在这一完整、高效且持续进化的体系之上。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

全球首个开源医疗视频理解大模型发布 附六千组测试集与评测榜单
手术视频的“黑盒”,被一脚踢爆了。 就在这两天,GitHub和Hugging Face社区上线了一枚医疗大模型领域的“核弹”。 全球规模最大、性能最强的医疗视频理解大模型——uAI Nexus MedVLM(中文名:元智医疗视频理解大模型)宣布开源。 最惊人的是,这玩意儿是真的能看懂手术。 相关论文

城市如何布局算力新赛道以把握Token驱动未来
4月27日,蚂蚁集团旗下全模态AI助手“灵光”App正式上线“体验世界模型”创新功能。用户仅需上传一张图片,即可在手机端一键生成长达60秒的沉浸式3D场景,并以第一人称视角自由探索。这一过程如同体验一款轻量级互动游戏,用户可在AI实时构建的动态环境中随意漫游。该功能无需本地部署与复杂配置,打开App

开源OfficeCLI命令行工具专为AI智能体设计
在AI智能体技术快速发展的当下,如何高效、精准地处理日常办公文档已成为一个核心挑战。传统方案如Python库依赖复杂环境与脚本编写,而直接调用Office API则面临跨平台与依赖难题。如今,一个名为OfficeCLI的开源项目正致力于从根本上解决这一痛点。 OfficeCLI是什么 简而言之,Of

芒果传媒携手爱诗科技:AI视频全栈技术赋能内容生态升级
4月23日上午,湖南广播电视台金鹰大厦内举行了一场备受业界关注的战略签约仪式。芒果传媒有限公司与北京爱诗科技有限公司正式达成深度战略合作。湖南广播影视集团有限公司(湖南广播电视台)党委委员、副总经理、副台长杨贇,爱诗科技联合创始人谢旭璋、副总裁徐舒帆等双方核心管理团队共同出席见证。 本次战略合作的核

斑陌易行T6无人车硅谷商用开启自动驾驶新纪元
硅谷的四月末,一场关于未来的对话正在上演。The Magic X全球具身智能创新大会上,来自中国的无人配送科技公司斑陌易行,向世界展示了其如何用一套完整的技术栈,将无人配送从实验室构想推向商业现实。 这场汇聚了图灵奖得主、英伟达、亚马逊、谷歌DeepMind等顶尖力量的盛会,无疑是中国具身智能企业走








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
