




英伟达开源Lyra 2.0:探索生成式3D世界的核心技术框架

Lyra 2 0是什么 你是否想过,仅凭一张静态照片,就能构建出一个可以自由漫步、深度探索的宏大三维虚拟世界?这听起来仿佛是科幻电影里的场景,但英伟达最新发布并开源的Lyra 2 0框架,正将这一愿景转变为触手可及的现实。 简而言之,Lyra 2 0是一个开创性的、可探索的生成式三维世界构建框架。其
Lyra 2.0是什么
你是否想过,仅凭一张静态照片,就能构建出一个可以自由漫步、深度探索的宏大三维虚拟世界?这听起来仿佛是科幻电影里的场景,但英伟达最新发布并开源的Lyra 2.0框架,正将这一愿景转变为触手可及的现实。
简而言之,Lyra 2.0是一个开创性的、可探索的生成式三维世界构建框架。其核心流程设计精妙:从一张图像出发,融合了相机轨迹控制视频生成与前馈式三维重建技术,通过一个高效的“检索-生成-更新”迭代循环,逐步构建出大规模、可持久漫游的三维场景。该系统具备独特的“空间记忆”能力——它会为每一帧画面建立独立的3D几何缓存,用于空间信息的检索与关联,同时引入了创新的自增强训练策略,有效抑制了长时间序列生成中常见的“时间漂移”现象,从而实现了数百帧的长程三维一致性生成。最终,Lyra 2.0不仅能生成视频,更能将结果重建为高保真的3D高斯溅射(Gaussian Splatting)和表面网格模型,并直接导出到NVIDIA Isaac Sim等物理仿真引擎中,为机器人训练等具身智能应用提供了一个高度真实、可交互的虚拟环境。
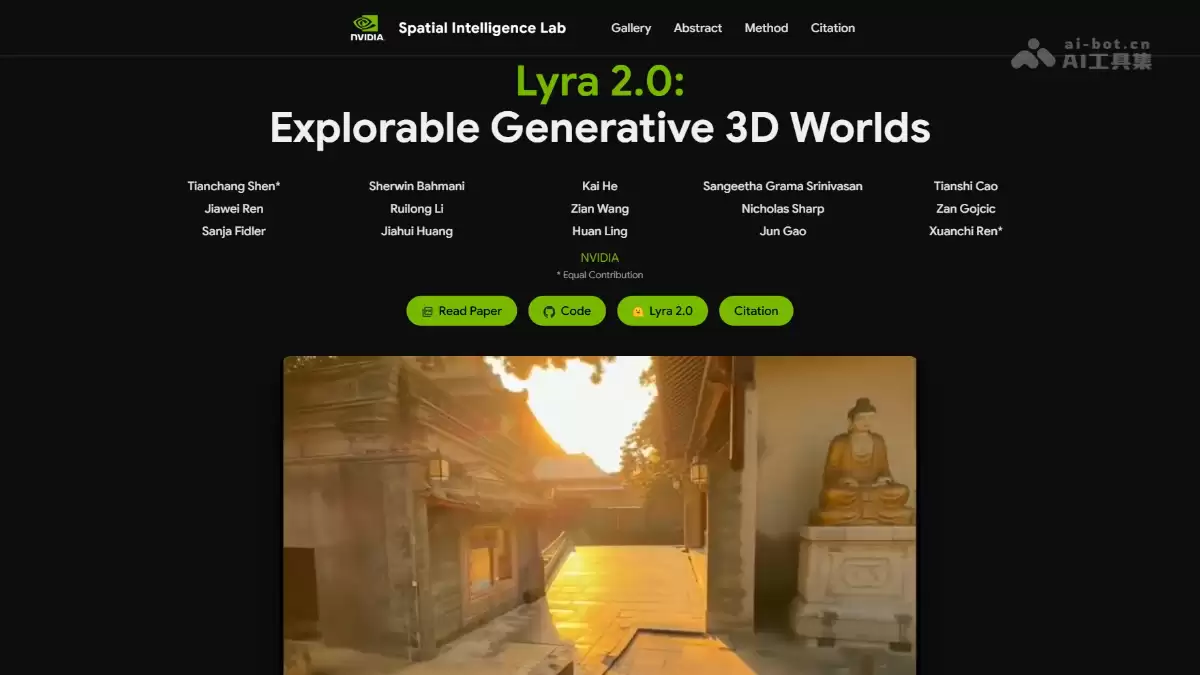
Lyra 2.0的主要功能
- 长程三维一致性视频生成:用户可自定义相机运动路径,系统便能沿此轨迹生成长达数百帧的连续漫游视频。即使视角发生剧烈变化或重新访问已探索过的区域,场景结构与外观也能保持高度一致。
- 空间记忆检索机制:系统为每一帧建立独立的3D几何缓存(如深度图、点云),形成一个动态增长的空间记忆库。当需要生成新视角时,它能智能检索出与目标视角最相关的历史帧作为生成条件。
- 抗时间漂移生成能力:通过独特的自增强训练策略,模型在自回归推理过程中学会了主动识别并纠正误差累积,显著避免了颜色、几何形状在长序列生成中逐渐“失真”或“漂移”的问题。
- 交互式三维场景探索器:提供了直观的图形化界面(GUI),可实时可视化累积的点云。用户可以像玩第一人称游戏一样,自由规划相机轨迹,既能重访旧地,也能勇敢探索未知区域。
- 高效前馈三维重建:生成的视频序列可以通过一个经过专门微调的前馈模型,快速、高质量地重建为3D高斯溅射(Gaussian Splatting)和表面网格(Mesh)。
- 仿真资产一键导出:重建出的三维资产可以直接导出到NVIDIA Isaac Sim等主流物理仿真引擎中,无缝衔接机器人导航、物体抓取等交互式训练任务。
- 加速推理版本:项目贴心地提供了基于分布匹配蒸馏技术优化的4步去噪学生模型,推理速度相比原版模型提升约13倍,大幅降低了计算门槛和使用成本。
Lyra 2.0的技术原理
- 生成式重建新范式:它创新性地结合了相机控制视频扩散模型(保障视觉真实感)和前馈三维重建技术,成功将“单张图片+相机轨迹”这一组合,转化为可直接渲染的三维输出。
- 几何路由与外观合成解耦:这是其核心设计精髓。系统维护的每帧三维缓存(深度和点云)仅负责历史帧检索和建立密集的三维对应关系,扮演“空间导航仪”的角色。实际的像素合成工作,仍交由强大的视频扩散模型的生成先验来完成。这种解耦设计,有效规避了传统三维渲染中伪影的传播难题。
- 规范坐标扭曲注入:具体如何利用历史帧?系统会将检索到的历史帧,通过其深度信息“扭曲”到目标视角,生成规范坐标图和深度图。经过位置编码和多层感知机(MLP)处理后,这些精确的几何对齐信号被注入到DiT模型的自注意力层中,指导新帧的生成。
- 自增强抗漂移训练策略:为了让模型在推理时更加稳健,训练时特意给历史隐变量添加噪声,然后让模型尝试通过单步去噪来恢复干净目标。这相当于对模型进行了“抗干扰训练”,迫使其在条件不完美时也能做出准确判断,从而缩小了训练与推理之间的数据分布差异。
- FramePack上下文压缩技术:为了在有限算力下记住更长的历史信息,Lyra 2.0采用了可变核的patchification技术对时间上下文进行压缩:对近期的帧保留更多细节(细粒度),对远期的帧则进行信息概括(粗粒度)。从而在固定的计算预算内,有效扩展了上下文窗口的长度。
- 微调前馈重建模型:其三维重建模块基于Depth Anything v3进行了改进,优化了在高分辨率下对高斯点云密度的预测。关键在于,该模块在Lyra 2.0自身生成的数据上进行了针对性微调,因此对生成式模型可能产生的特定伪影具有更强的鲁棒性,能产出更干净、连贯的三维模型。
如何使用Lyra 2.0
- 克隆项目仓库:首先,从GitHub官方仓库拉取代码,并严格遵循README文件的指引,配置好Python环境及相关依赖库。
- 下载预训练模型:从Hugging Face平台或项目页面获取预训练好的Lyra 2.0模型权重文件。
- 准备输入素材:准备一张清晰的场景图像作为起点,如需风格引导,可以附加相应的文本提示词。
- 启动交互探索器:运行交互式GUI程序,加载你的输入图像,并开始规划你想要的相机漫游轨迹。
- 启动迭代生成循环:系统将启动“检索-生成-更新”的自动化循环,从空间记忆中智能查找相关信息,并逐段生成长程三维视频。
- 执行三维重建:视频生成完毕后,调用微调好的前馈模型,将视频序列转换为3D高斯溅射(Gaussian Splatting)表示。
- 提取表面网格:运行项目提供的脚本,可以从3DGS表示中进一步提取出表面网格(Mesh),还支持分层稀疏网格的提取,以满足不同精度的应用需求。
- 导出与部署:最后,将得到的三维资产导入NVIDIA Isaac Sim等物理仿真引擎,即可用于具身智能训练或其他虚拟仿真应用。
Lyra 2.0的关键信息和使用要求
- 项目定位:这是英伟达推出的开源可探索生成式三维世界框架,核心目标是支持从单张图像迭代构建出持久、可漫游的大规模三维场景。
- 核心技术:底层基于Wan 2.1 VAE + DiT架构的视频扩散模型,采用“检索-生成-更新”的自回归循环。其两大创新在于:通过每帧独立三维几何缓存解决“空间遗忘”问题;通过自增强训练策略抑制“时间漂移”。
- 输入与输出:输入需要一张RGB图像,可选文本提示和自定义相机轨迹;输出则是长程的、相机控制视频。该视频可进一步重建为三维高斯溅射(Gaussian Splatting)与表面网格,并支持导出至物理仿真引擎。
- 性能优化:项目提供了基于分布匹配蒸馏的4步加速模型,推理速度提升显著,约为原版模型的13倍。
- 硬件环境:需要配备NVIDIA GPU,推荐使用显存容量较高的显卡,以支持长视频生成与三维重建等计算密集型任务。CUDA环境是必需的。
- 软件依赖:主要包括PyTorch、diffusers、transformers、FramePack、Depth Anything V3、OpenVDB等关键库,具体版本请严格参照项目仓库中
requirements.txt文件的规定。
Lyra 2.0的核心优势
- 全局空间持久性:得益于独立的每帧几何缓存和智能的可见性检索机制,它彻底解决了长程三维生成中的“空间遗忘”难题。这意味着,即使相机绕行一周再回到原点,场景结构依然能保持完美一致。
- 长期视觉稳定性:自增强训练策略效果显著,能有效抑制自回归过程中误差的累积。与基线模型相比,它在数百帧的生成中,颜色漂移和几何畸变都得到了大幅减少,画面稳定性极高。
- 高质量三维输出:其前馈重建模型专门针对生成式数据进行了优化微调,能够容忍轻微的多视图不一致性,最终产出干净、连贯、实用的三维高斯溅射与网格模型。
- 高度交互可控:整个过程并非一次性、不可控的“黑盒”生成。用户能够实时规划任意长度的相机轨迹,系统则渐进式地扩展场景,赋予了创作者极高的控制自由度和创作灵活性。
Lyra 2.0的项目地址
- 项目官网:https://research.nvidia.com/labs/sil/projects/lyra2/
- GitHub仓库:https://github.com/nv-tlabs/lyra
- HuggingFace模型库:https://huggingface.co/nvidia/Lyra-2.0
- arXiv技术论文:https://arxiv.org/pdf/2604.13036
Lyra 2.0的同类竞品对比
| 维度 | Lyra 2.0 | GEN3C | Wonderland |
|---|---|---|---|
| 技术路线 | 视频生成 + 前馈三维重建,解耦几何路由与外观合成 | 视频生成 + 全局三维表示条件生成,紧耦合设计 | 相机控制视频扩散 + 专用前馈网络预测三维高斯溅射 |
| 记忆机制 | 每帧独立三维缓存,仅用于信息路由与对应关系建立 | 累积全局点云/深度渲染图作为生成条件 | 无显式空间记忆,依赖视频模型自身时间上下文 |
| 长程一致性 | 支持数百帧大视角变化与区域重访,抗时间漂移能力强 | 受限于全局三维表示质量,误差易被放大 | 视角覆盖有限,长程一致性未作为重点解决 |
| 交互方式 | 显式相机轨迹规划 + 可选文本提示 | 显式相机轨迹 + 三维条件控制 | 显式相机轨迹控制 |
| 输出格式 | 三维高斯溅射 + 表面网格,支持物理引擎导出 | 视频与三维输出 | 三维高斯溅射 |
| 训练数据 | DL3DV真实场景长视频,采用自增强策略 | 未公开详细训练方案 | 未公开详细训练方案 |
| 推理效率 | 提供4步蒸馏模型,速度提升约13倍 | 标准扩散采样 | 标准扩散采样 |
Lyra 2.0的应用场景
- 具身智能与机器人仿真:为机器人导航、物体操作等复杂训练任务,快速生成高度可交互的室内外三维虚拟环境,能有效替代成本高昂、周期漫长的真实场景数据采集。
- 虚拟世界与游戏开发:在游戏制作或元宇宙场景搭建中,可以从单张概念艺术图快速生成可自由漫游的关卡或场景原型,极大地加速前期美术设计和创意验证流程。
- 建筑与室内设计可视化:基于设计师提供的平面图或效果图,快速生成三维漫游视频,让客户能够沉浸式地预览空间布局、光照和材质效果,显著提升沟通与决策效率。
- 影视预演与动画制作:为导演和视觉预览团队提供强大工具,能够将静态的概念设计图迅速转化为动态的场景漫游动画,用于镜头规划、节奏测试和早期创意决策。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:英伟达开源Lyra 2.0:探索生成式3D世界的核心技术框架要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点最近留意到一款AI聊天机器人构建工具——Craftman,它的核心思路很有意思:让企业或个人能用自己已有的数据来训练ChatGPT,然后直接嵌入到网站上做智能客服或问答助手。简单来说,就是把通用大模型变成你的专属知识库响应系统。什么是Craftman?Craftman是一个AI聊天机器人构建平台,允
如果告诉你,现在借助AI技术就能一键生成时长16秒、分辨率达1080P的高清视频,并且画面流畅自然、物理规律真实可信,你是不是觉得有些不可思议?事实上,这就是Vidu——由中国生数科技与清华大学联合打造的全球首个长时长、高一致性、高动态性视频大模型。它采用独创的Diffusion与Transform
想象一下,你拥有一个庞大而复杂的知识库,里面堆满了各类文档、PDF文件以及YouTube视频教程。过去想要查找某份资料,往往需要翻遍目录、反复尝试关键词搜索,效率低下令人困扰。如今,借助Hansei这款知识库管理工具,一切变得轻松高效——你只需像与朋友聊天一样,用自然语言提出需求,AI助手就能从你的
Blinkn是基于ChatGPT的智能电商购物助手,具备语义理解、精准产品推荐与比较、多语言支持等功能,可与主流平台无缝集成并个性化定制,提供7×24小时实时客服,高效解决购物疑问,显著减少决策摩擦,提升转化率与用户体验。
- 日榜
- 周榜
- 月榜
热点快看