




EAPO证据奖励机制如何提升大模型推理准确性

阿里通义实验室提出EAPO强化学习框架,通过“证据奖励”机制将监督重点转向证据提取过程,强制模型进行结构化推理,并对证据质量进行细粒度评分,实现奖励模型与策略模型的协同进化。实验显示,该框架显著提升了模型在长文本任务中的证据查找与推理准确性,有效减少了幻觉现象。
搜对≠答对:EAPO用“证据奖励”让大模型不再靠猜
当前,AI搜索技术已能将海量网络信息压缩至数百万Token的上下文窗口,大语言模型的核心任务看似简单:从这片信息海洋中精准定位正确答案。
然而现实情况往往出人意料:正确的参考材料明明近在眼前,模型要么给出错误答案,要么侥幸答对数字,但仔细核查其引用的支撑依据却全是错误的。
问题的症结究竟在哪里?
根源在于现有的奖励机制存在缺陷——传统的强化学习方法只关注最终答案的对错。只要答案猜中,模型就能获得奖励,至于推导过程是否严谨、依据是否可靠,系统并不关心。
阿里通义实验室的研究团队近期提出了一项创新的强化学习框架:EAPO(Evidence-Augmented Policy Optimization,证据增强的策略优化)。该框架引入了一个核心概念——“证据奖励”,将监督的重点从单纯的“答案正确性”下沉到“证据查找与引用”的完整过程中。
这项研究成果已被自然语言处理领域顶级学术会议ACL 2026接收,并在多个权威的长文本理解与推理基准测试中表现卓越。令人瞩目的是,基于该框架训练的300亿参数模型,在长文本推理任务上的性能甚至超越了参数规模达1200亿的GPT-OSS和Claude-Sonnet-4等模型。

论文地址:https://arxiv.org/abs/2601.10306

面对海量搜索结果,大模型为何频频“翻车”?
让我们通过一个具体案例来剖析:
提问:周杰伦在2005年至2010年期间演唱的歌曲中,有多少首曾获得金曲奖提名?
理想的检索增强生成(RAG)流程应遵循以下步骤:

根据检索到的权威资料进行严谨推理,正确答案应为12首。
然而,在处理此类信息噪声大、细节要求高的复杂查询时,大模型通常会出现两种典型的失误模式:
第一种是直接回答错误:例如回答15首。这可能是因为模型错误地将2004年发行的《东风破》,或周杰伦仅参与作曲而未亲自演唱的《淘汰》等歌曲也计入了统计。
第二种是“侥幸蒙对”:最终答案数字是12首,看似正确。但仔细审查其推理链会发现,模型引用的关键证据竟然是歌曲《淘汰》。
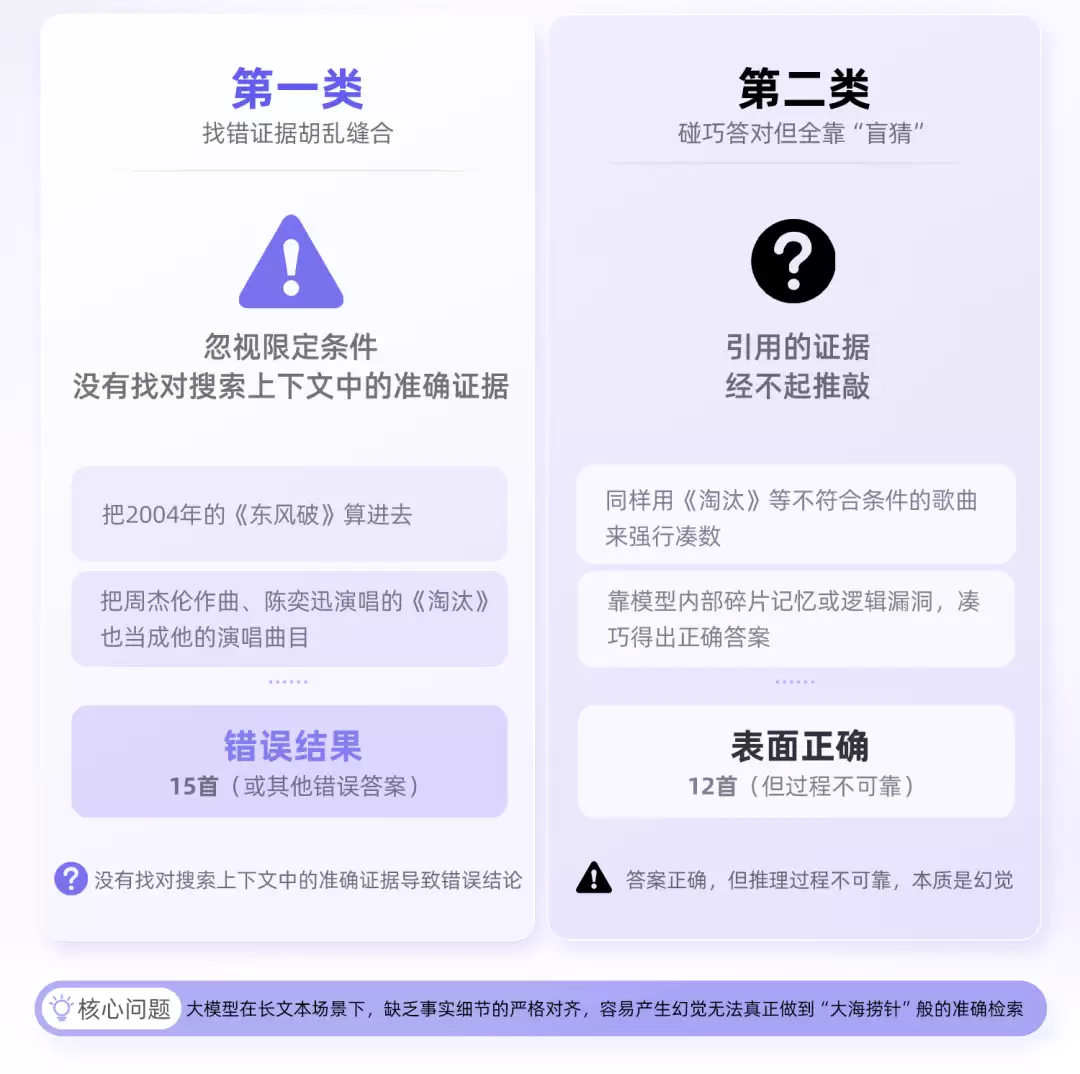
问题的本质由此显现:无论是哪种情况,模型都未能真正执行那项从庞杂文本中“大海捞针”、精准定位关键信息的核心任务。
这种脱离证据支撑的推理,正是大模型在处理长上下文时最常出现的“幻觉”问题之一。

证据质量究竟有多重要?一项关键预实验
为了量化评估“证据质量”对最终答案的决定性影响,研究团队设计了一项预实验。
他们采用了一种“树状证据采样”方法(如下图所示),让模型针对同一问题生成多条不同的证据提取路径,随后分别评估每条路径的证据质量及其对应的最终答案准确性,从而剖析影响任务成败的关键因素。
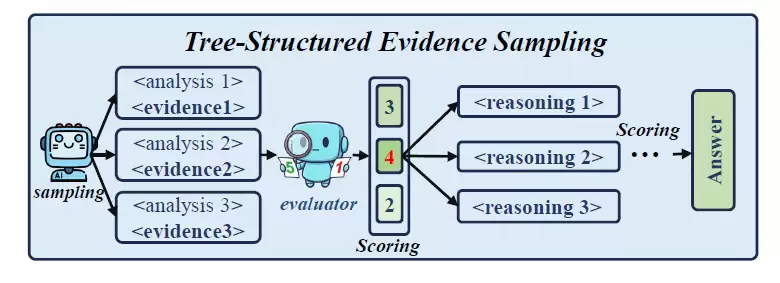
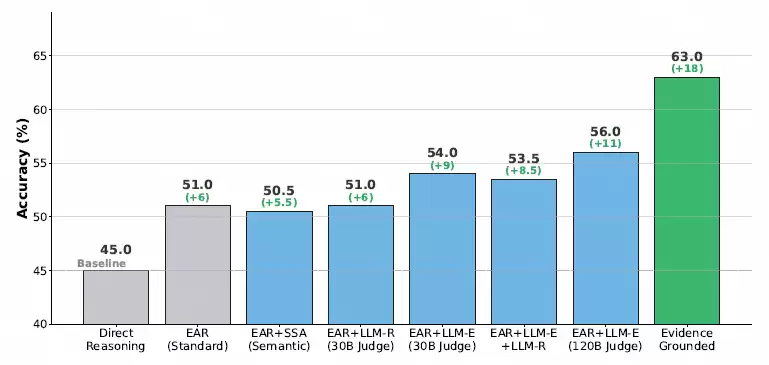
实验数据揭示了一个清晰的规律:找到正确的证据,几乎等同于找到了正确的答案。
数据显示,若直接将高质量证据提供给模型进行推理,其答案准确率可从45%大幅提升至63%。相反,如果证据检索质量低下,那么无论后续如何优化推理步骤,模型的整体性能也难有起色。

EAPO:一套实现自我进化的强化学习新范式
基于上述核心洞察,研究团队设计了一套自我进化的闭环强化学习框架——EAPO。
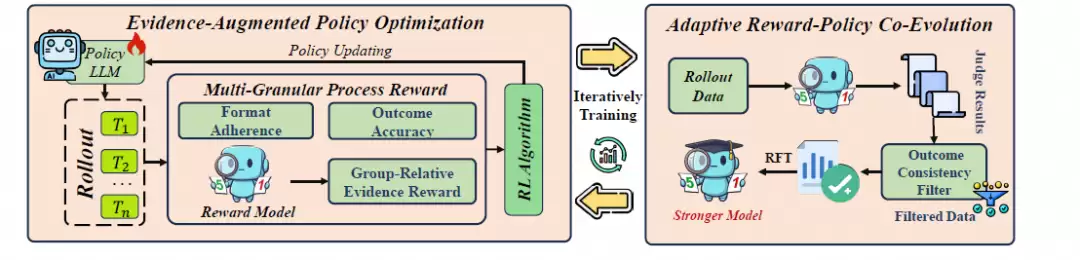
(1)构建证据增强的标准化推理范式
研究团队强制模型执行一个结构化的四步工作流:问题解析 -> 原文证据提取 -> 逻辑推理 -> 生成最终答案。这种格式化的输出确保了推理过程的透明性与可审查性,尤其是中间的“证据提取”环节,首次成为可以直接被监督和量化评估的对象。
(2)细粒度过程打分:引入群组相对证据奖励
传统强化学习仅在最终答案上提供一个稀疏的奖励信号,而EAPO构建了一个过程奖励模型。
在训练过程中,模型会针对同一问题生成多个不同的证据组合。奖励模型通过对比这些证据,为那些引用最精准、最具决定性的证据链赋予高分。这种密集的“过程监督”,让模型深刻理解到“找对证据”远比“猜对答案”更为根本。
(3)奖励模型与策略模型的协同进化机制
如果奖励模型的评判标准停滞不前,随着大模型能力的不断提升,固定的标准将难以区分证据之间日益微妙的优劣差异。
EAPO巧妙地设计了一个“自适应协同进化”机制:大模型在训练中生成的那些高置信度、且最终答案正确的优质证据链,会被自动筛选出来,用于对奖励模型进行持续的微调与优化。
由此,一个良性的增强循环得以建立:大模型的推理能力越强,生成的训练数据质量就越高;奖励模型的评判眼光越精准,反过来又能更有效地指导大模型提炼出更可靠的证据。
从“制定规则”到“过程评分”,再到“协同进化”,EAPO成功地将强化学习的激励信号锚定在证据本身,使得模型的每一次推理都变得有据可查、有迹可循。

效果验证:用数据说话
团队在SEAL、LongBench-V1/V2等涵盖8个主流长文本推理基准的数据集上进行了全面评测:
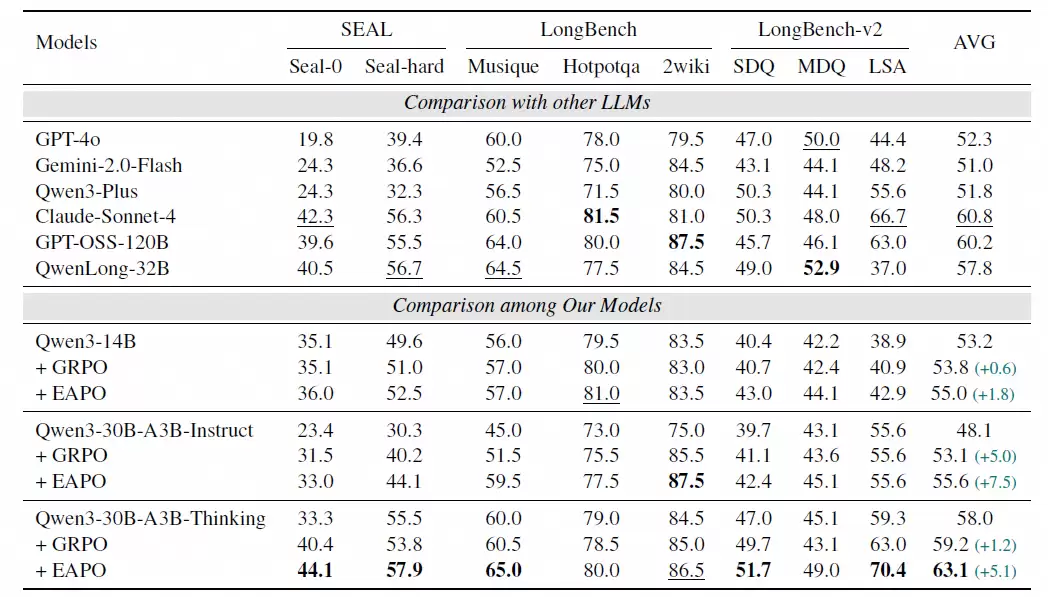
基于Qwen3-30B-Thinking模型训练的EAPO版本,平均得分达到63.1%,性能相较于基线方法提升了5.1%。更值得注意的是,其表现超越了参数规模大得多的开源模型GPT-OSS-120B,甚至在某些任务上优于GPT-4o、Claude-Sonnet-4等闭源商业模型。
为了深入验证EAPO框架设计的有效性,团队对模型训练过程中的行为轨迹进行了细致的“切片”分析:
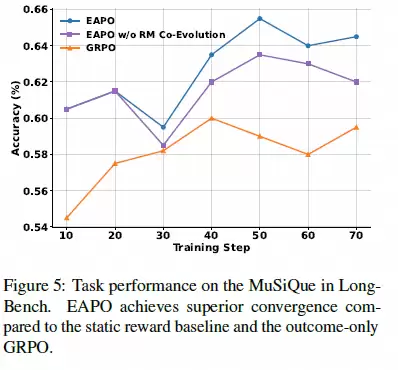
▶ 收敛速度更快,性能上限更高
从准确率变化趋势图可以清晰看出,仅关注最终结果的GRPO方法不仅学习速度慢,而且性能提升很快触及天花板。在引入证据过程打分后,模型的学习效率显著加快;而进一步加入“协同进化”机制后,模型的准确率更是突破了原有瓶颈,呈现出持续上升的态势。
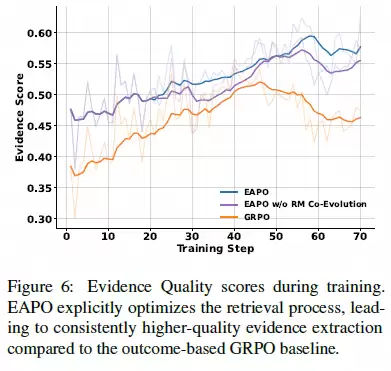
▶ “证据查找”能力实现跨越式提升
从训练过程中的“证据质量得分”曲线来看,GRPO隐式地优化证据,提升幅度有限且缓慢;而EAPO直接针对证据质量进行显式打分与优化,其证据查找能力始终保持显著领先优势。
为了进一步探究EAPO具体改善了模型的哪些能力,团队将错误案例拆解为两类进行分析:一类是未能找到或找错证据的“证据错误”,另一类是证据正确但逻辑推导出错的“推理错误”。
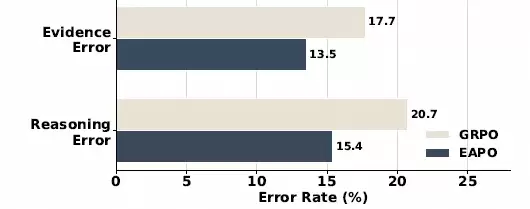
对比EAPO与传统GRPO的表现:
- 证据错误率:从17.7%显著降低至13.5%
- 推理错误率:从20.7%同步下降至15.4%
EAPO实现了两类错误率的同步下降。一个有趣的发现是,该框架并未显式地监督推理步骤,但推理错误率却得到了几乎同等幅度的改善。这恰恰说明,逻辑推理本身或许并非最难的环节,它常常被错误的初始证据引入歧途。一旦前提证据准确无误,得出正确结论的难度便大大降低。

结语
AI搜索与智能体(Agent)技术解决了“如何获取海量资料”的问题。然而,信息越丰富,模型“走捷径、凭猜测”的空间就越大;上下文越长,“假装阅读并理解”的成本就越低。仅奖励最终结果的强化学习范式,无形中纵容了这种投机行为。
在长文本与大模型深度结合的时代,我们需要的不仅是一个能对海量检索结果囫囵吞枣的“快速阅读者”,更是一个严谨细致、言必有据的“学术考据派”。
EAPO框架突破了长文本强化学习长期依赖“稀疏结果奖励”的瓶颈。它找到了一个清晰可评估的过程节点——证据提取,并围绕它构建了一套可持续自我进化的监督与优化体系。这使得每一次推理都变得透明可追溯,让每一个结论都能经受住追问:你的判断依据究竟是什么?
? 今日互动
你是否也曾被大模型的“幻觉”或“信口开河”所困扰?
欢迎在评论区分享:你遇到过哪些大模型检索资料正确,却依然给出错误答案的案例?你认为哪类问题最容易让模型“翻车”?我们将抽取3位幸运读者,赠送定制周边礼品。
近期活动推荐

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:EAPO证据奖励机制如何提升大模型推理准确性要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点最近留意到一款AI聊天机器人构建工具——Craftman,它的核心思路很有意思:让企业或个人能用自己已有的数据来训练ChatGPT,然后直接嵌入到网站上做智能客服或问答助手。简单来说,就是把通用大模型变成你的专属知识库响应系统。什么是Craftman?Craftman是一个AI聊天机器人构建平台,允
如果告诉你,现在借助AI技术就能一键生成时长16秒、分辨率达1080P的高清视频,并且画面流畅自然、物理规律真实可信,你是不是觉得有些不可思议?事实上,这就是Vidu——由中国生数科技与清华大学联合打造的全球首个长时长、高一致性、高动态性视频大模型。它采用独创的Diffusion与Transform
想象一下,你拥有一个庞大而复杂的知识库,里面堆满了各类文档、PDF文件以及YouTube视频教程。过去想要查找某份资料,往往需要翻遍目录、反复尝试关键词搜索,效率低下令人困扰。如今,借助Hansei这款知识库管理工具,一切变得轻松高效——你只需像与朋友聊天一样,用自然语言提出需求,AI助手就能从你的
Blinkn是基于ChatGPT的智能电商购物助手,具备语义理解、精准产品推荐与比较、多语言支持等功能,可与主流平台无缝集成并个性化定制,提供7×24小时实时客服,高效解决购物疑问,显著减少决策摩擦,提升转化率与用户体验。
- 日榜
- 周榜
- 月榜
热点快看