




微软开源Phi-4多模态模型15B参数支持自主视觉推理

微软开发者社区近期公布了一项重要进展:正式开源Phi-4-Reasoning-Vision-15B模型。该模型并非传统视觉模型,而是Phi-4系列中首个融合高分辨率视觉感知与任务感知智能推理能力的小型语言模型(SLM)。简而言之,它不仅具备出色的视觉解析能力,还拥有深层次的逻辑思考与推理功能。 以往
微软开发者社区近期公布了一项重要进展:正式开源Phi-4-Reasoning-Vision-15B模型。该模型并非传统视觉模型,而是Phi-4系列中首个融合高分辨率视觉感知与任务感知智能推理能力的小型语言模型(SLM)。简而言之,它不仅具备出色的视觉解析能力,还拥有深层次的逻辑思考与推理功能。

以往多数视觉模型主要扮演被动“识别器”的角色,侧重于回答图像中“有什么”。Phi-4-Reasoning-Vision-15B则实现了显著突破,能够执行结构化、多步骤的推理任务。这意味着它不仅能准确识别图像中的视觉元素与空间布局,还能将这些信息与文本指令深度融合,通过逻辑推导得出具有实际价值的结论。此项能力为开发者构建更智能的应用开辟了新路径,无论是自动化解析复杂图表数据,还是实现图形用户界面(GUI)的智能操作,都提供了可靠的技术支持。
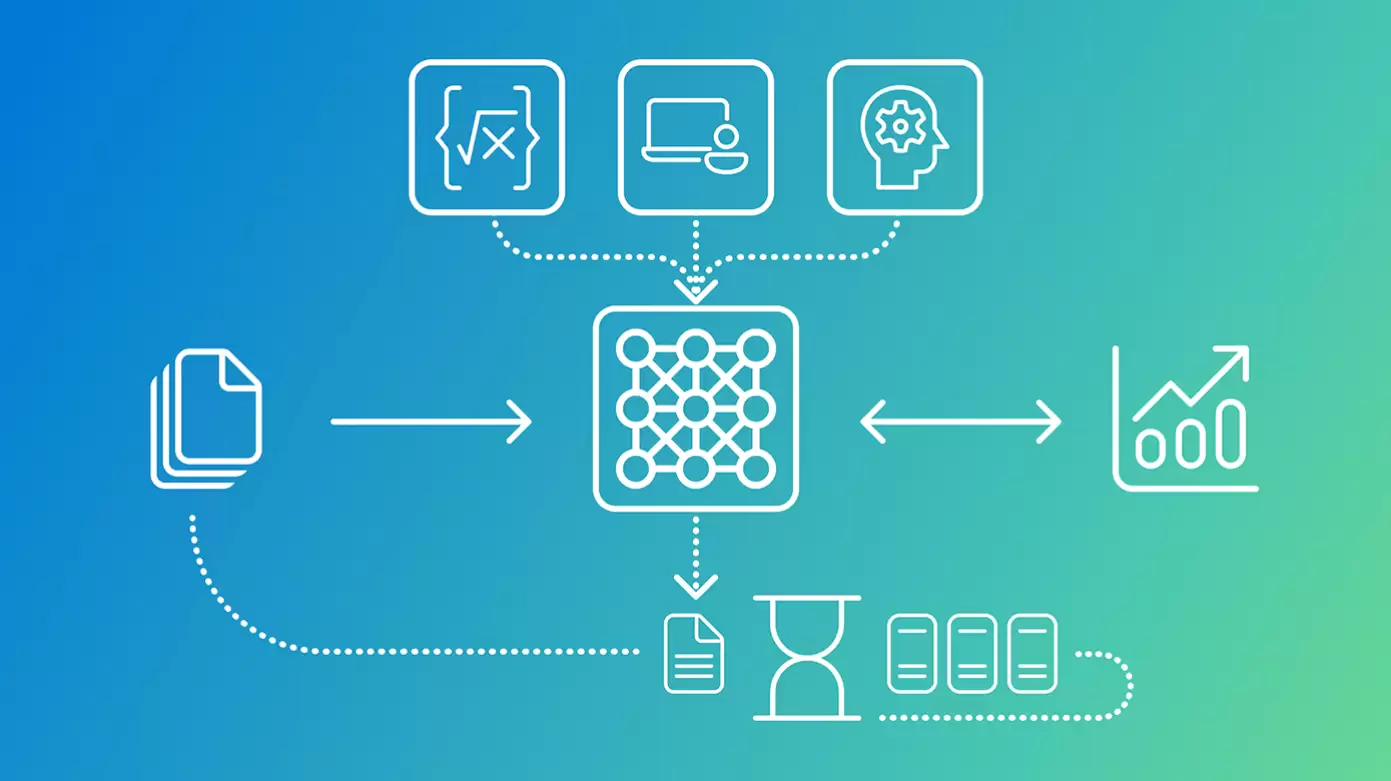
该模型的核心创新之一在于其“混合推理”机制。它能够根据任务的实际复杂度,在“推理模式”与“非推理模式”之间自主切换:
- 当面对需要深度思考的任务时,例如解答数学问题或进行逻辑分析,模型会启动多步推理链,逐步推演至最终答案。
- 而对于仅需快速感知的任务,如光学字符识别(OCR)或界面元素定位,模型则会直接输出结果,从而大幅降低响应延迟,提升处理效率。
这种自适应特性使其在计算机智能体(AI Agent)领域具有突出优势。例如,当模型接收到一张屏幕截图和一条自然语言指令(如“点击登录按钮”)时,它能够输出目标UI元素的精准坐标。随后,其他自动化智能体便可利用该坐标执行点击、滚动等交互操作,实现端到端的流程自动化。
那么,Phi-4-Reasoning-Vision-15B在实际任务中的性能表现如何?以下为该模型在多项关键评测中与其他主流模型的对比数据。
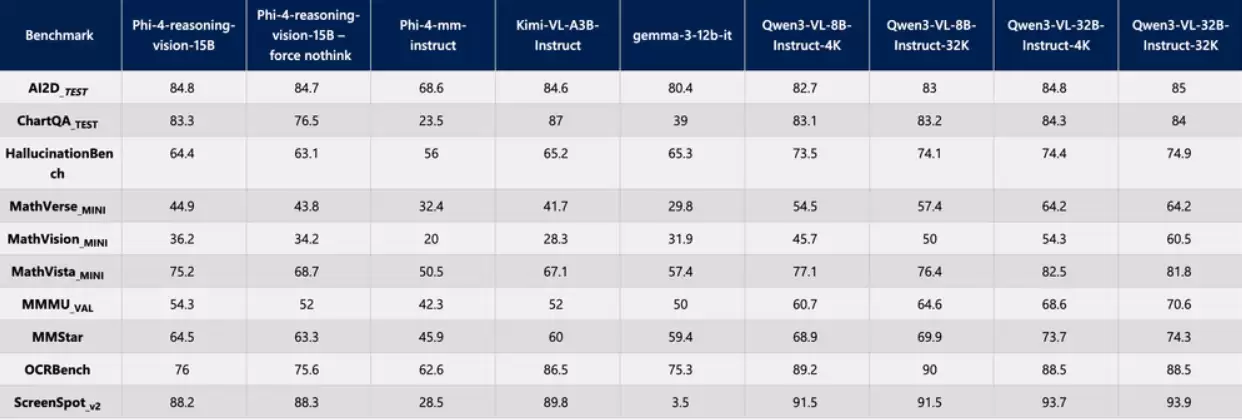
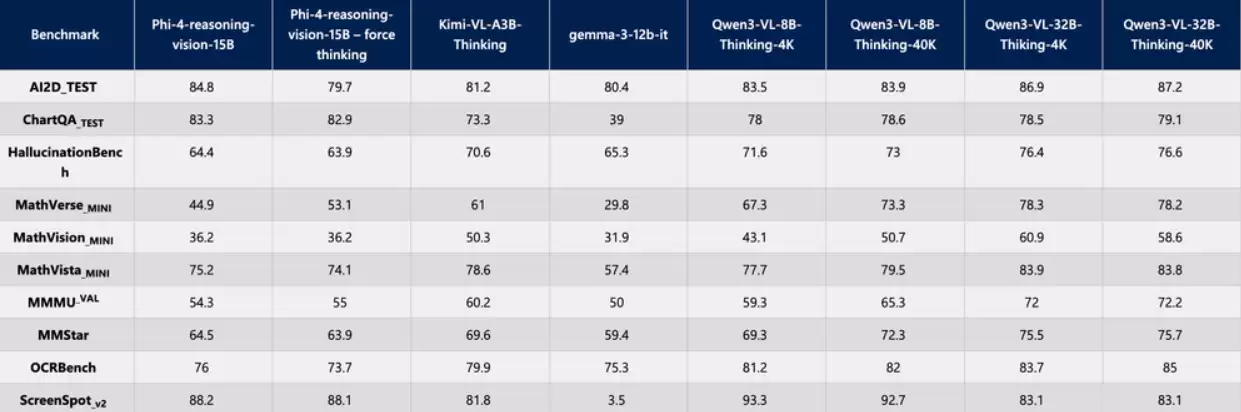
对于关注该技术的研究人员与开发者,可通过访问其在Hugging Face平台的开源项目页面,获取完整的模型细节、使用文档及相关资源。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:微软开源Phi-4多模态模型15B参数支持自主视觉推理要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点可灵AI默认输出16:9横屏,需主动设置9:16竖屏以适配抖音等平台;提示词开头必须写“竖屏9:16”,界面高级设置中选9:16或手机端点比例图标切换,横屏视频可用剪映或影忆AI转竖屏。可灵AI生成视频时若不主动设置比例,系统默认输出16:9横屏,但抖音、小红书等主流平台要求9:16竖屏,直接发布会
即梦AI生成文艺咖啡封面图需精准控制视角、光影和氛围细节。先输入基础主体描述器皿材质与液体质感,再通过方位介词、道具参照或镜头参数三种路径锁定视角,最后以胶片颗粒感、Portra 400色谱和具象细节注入文艺感,避免抽象词汇干扰。用即梦AI生成文艺咖啡封面图时,提示词必须精准控制视角、光影和氛围细节
即梦AI生成办公桌面场景前必须先输出5条编号结构框架;否则元素堆砌失序、文件层级错乱、关键物件被遮挡、光照不统一。三步触发法:首行严格输入角色指令;分号连接三项硬性约束;确认右下角出现绿色标签。你想让即梦AI生成办公桌面场景前,先输出可验证的视觉结构框架,而不是直接渲染一张图——否则桌面元素会堆砌失
即梦AI生成咖啡拉花视频需剔除空洞形容词,改用毫米级尺寸、角度、渗透状态等可拍摄物理参数;限定焦距景深、运镜节奏;嵌入商用设备、奶泡厚度、倾角变化及设备水渍等真实约束。用即梦AI生成咖啡拉花视频时,提示词里堆砌“高清、精致、唯美、艺术感”这类空洞形容词,会导致模型忽略真实拉花细节,输出千篇一律的假质
- 日榜
- 周榜
- 月榜
热点快看