




清华VAST新范式实现3D生成空间智能密度控制高效算力分配


纵观当前主流的3D生成技术路线,一个有趣的共性逐渐浮现:它们似乎都遇到了同一个瓶颈。
对于从事3D AIGC的研究者而言,模型在“生成一个物体”方面能力日益增强,但生成结果的复杂度往往受限于模型架构本身,缺乏灵活性。图形学与渲染领域的专家则更关注,3D表示能否将有限的计算资源精准地分配到最需要的地方。而游戏、XR和交互内容开发者则会持续追问:同一个3D资产,能否同时拥有高质量的离线版本和轻量级的实时版本,而不必每次都从头制作两套不同的内容。
这些看似不同领域的问题,实则指向了同一个核心矛盾:
当前许多3D生成方法,虽然能够产出结果,但在“智能资源分配”方面仍显不足。
以流行的3D高斯表示为例。一个理想的系统应当具备这样的智能:物体的边缘、纹理复杂的区域需要更密集的高斯球来精确刻画,而平坦、简单的区域则可以稀疏分布。然而,许多现有方法更像是使用一套固定的模板来生成3D,而非根据物体自身的结构复杂度,自适应地决定“在何处分配多少计算资源”。
SIGGRAPH 2026收录的论文《Generative 3D Gaussians with Learned Density Control》,正是瞄准了这一痛点。

这篇来自VAST与清华大学的研究,提出了一种名为“密度采样高斯”(Density-Sampled Gaussians, DeG)的全新3D表示方法。其目标不再是简单地生成固定数量的高斯球,而是让模型学会一种“高斯球采样策略”:在复杂区域增加采样密度,在简单区域减少采样密度,并且这种策略能够直接从最终的渲染误差中学习得到。
这听起来像是一个工程优化问题,实则至关重要。它决定了3D生成的结果,最终是一个“看起来尚可但笨重僵硬的静态输出”,还是一个能够根据预算伸缩、按需部署、适配不同场景的、真正可用的3D表示。
从固定结构到可学习密度
3D高斯表示在过去一段时间备受青睐,一个重要原因是它在画质与效率之间取得了良好平衡。它不像传统网格那样依赖复杂的拓扑结构,也能渲染出高质量的画面。其优化过程有一个关键优势,但恰恰也是生成式模型(如Diffusion)最难继承的部分——那就是空间密度控制。
在传统的3D高斯优化中,算法会持续进行“密集化”与“稀疏化”操作。简单来说就是:如果某个局部区域拟合效果不佳,就在那里“补充”更多高斯球;如果某些高斯球贡献微乎其微,就将它们“删除”。
这套机制之所以有效,是因为现实世界物体的复杂度本就是非均匀的。边缘、薄壁结构、纹理剧烈变化的区域,自然需要更强的表示能力;而大块平整、变化平缓的区域,堆砌过多高斯球则纯属资源浪费。
问题在于,这种“补点删点”的流程本质上是离散的、启发式的、不可微分的。这对于单个物体的拟合很有效,但对于一个需要做前馈式生成、从单张图像直接预测3D高斯的模型来说,就很难直接套用。于是,许多现有方法退而求其次,选择了固定结构:
有的方法将高斯球绑定在体素网格上;有的为每个体素分配固定数量的高斯;还有的为2D图像的每个像素预测固定数量的高斯。
这样做当然降低了训练难度,但代价也显而易见:失去了3D高斯最宝贵的灵活性。
DeG的核心思路,是把“高斯球中心位置”这个问题,从一个固定的回归任务,转变为一个从概率密度中采样的任务。
换句话说,模型不再死板地输出一组固定坐标,而是先学习一个3D空间内的概率密度分布。这个分布可以理解为一张“资源分配地图”,标识了哪些位置更值得放置高斯球(高概率),哪些位置不那么重要(低概率)。
在推理时,模型直接从学到的这个分布中采样出一批高斯球,构成最终的3D资产。这一转变,立刻为整个表示赋予了两种非常实用的能力。
能力一:任意数量采样
由于模型学习的是“分布”而非“固定长度的输出”,因此在推理时可以根据实际需求,采样任意数量的高斯球。需要移动端部署、实时预览或低成本传输?那就少采一些。需要高保真渲染、离线展示或复杂场景?那就多采一些。
这意味着,你不再需要为每种分辨率或预算训练一个单独的模型。同一个模型、同一个学到的表示,只需调整采样数量,就能适应不同需求。考虑到3D高斯的渲染成本并不低,这种灵活性对于实际部署至关重要。毕竟,许多应用追求的并非绝对最强的画质,而是在当前设备和时延预算下,获得“最合适”的3D资产。

能力二:非均匀采样
DeG并非在空间中平均撒点。在训练过程中,模型会根据渲染重构损失,自动将更多的采样预算“投资”到真正复杂的区域。例如,物体的薄壁结构、尖锐边缘、几何变化剧烈或纹理敏感的区域,会自然获得更高的高斯密度;而在平坦、规则、变化较小的区域,高斯球则会稀疏分布。
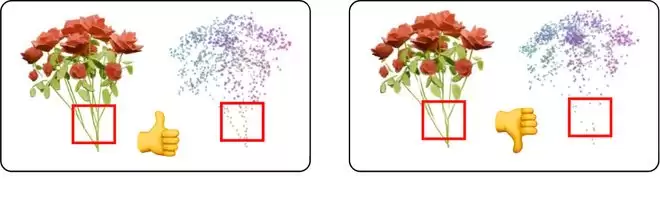
这标志着,模型开始真正具备“好钢用在刀刃上”的智能资源分配能力。而这也引出了本文最核心的算法挑战:
这种空间上的智能密度控制策略,究竟该如何学习?
核心挑战:如何教会模型“分配资源”?
初次接触这个问题,可能会想:既然最终有渲染损失,直接反向传播不就行了?
真正的难点在于,高斯球的位置是“采样”得到的。采样操作本身不是一个连续可微的函数,因此渲染误差无法像在常规神经网络中那样,顺畅地反向传播回“空间密度分布”参数。也就是说,模型虽然知道最终渲染结果哪里错了,却很难直接知道:应该提高哪些区域被采样到的概率,又该降低哪些区域的概率。
这篇论文的关键突破,就是为这个难题构造了一个可训练的梯度信号,作者称之为“渲染损失贡献梯度”。其本质可以理解为一种面向高斯采样的策略梯度方法。
这个想法非常直观。假设我们从当前的密度分布中采样出了一批高斯球。现在,试想如果去掉其中的某一个高斯球,重新计算渲染损失会怎样?
如果去掉它后,渲染质量显著下降,那就说明这个高斯球至关重要,它有效地表示了该区域。那么,系统就应该奖励这类位置,提高它们未来被采样到的概率。
反之,如果去掉它几乎没影响,甚至结果反而更好,那就说明这个位置的高斯球价值不高,其被采样的概率就应该降低。
用更通俗的话说,这个梯度在回答一个问题:“这次被采到的这个高斯球,到底‘值不值’?”
这是一种典型的强化学习策略视角。采样位置如同“智能体做出的决策”,而渲染误差则提供了“环境反馈的奖励信号”。对降低误差有帮助的决策(位置)就给予奖励,帮助不大的就少奖励甚至惩罚。
从数学上看,这套思路与策略梯度方法一致。作者进一步将其表述为“差分奖励”的形式,即比较“有这个高斯球”和“没有这个高斯球”时,渲染损失的差值。这个差值,恰好刻画了该高斯球的边际贡献。
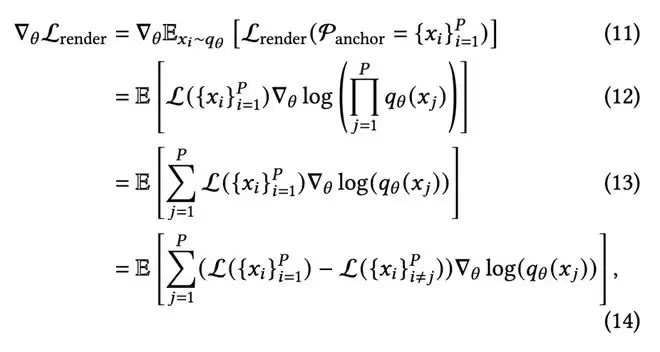
更重要的是,这并非一个仅凭直觉设计的技巧。论文从“渲染损失的期望值”出发,严格推导了其对密度分布参数的梯度,最终得到了用于优化的梯度信号。也就是说,作者是在用梯度下降的方式,直接优化高斯球该如何分布与采样。这与传统3D高斯中基于人工规则的剪枝和密化,虽然结果相似,但思路已完全不同。
当然,如果严格计算每个高斯球的“留一法”贡献,计算代价将高得无法承受,因为这相当于需要为每个高斯球单独删除并重新渲染一次。
接下来的挑战便是:如何高效地计算这个定义清晰的目标?作者针对L1渲染损失,给出了一种既精确又高效的计算方法。简而言之,对于L1损失项,渲染器在正常渲染过程中已经可以获得几个关键中间值,只需进行少量额外计算,就能得到所需的贡献值,而无需反复执行删除和重渲染。具体计算流程可参考论文中的伪代码。
至此,原本依赖人工规则的密集化/稀疏化过程,被改写成了一个可微、可学习、可批量训练的空间密度优化过程。这项工作首次将3D高斯的密度控制,真正变成了一个端到端的优化问题。
从技术突破到应用价值
从应用视角看,这套方法的价值更为直观。
首先,它让3D资产真正具备了按预算伸缩的能力。以往许多方法一旦生成完毕,输出规模就基本固定。想要更轻量,往往只能事后压缩,可能损失质量;想要更高质量,则常常意味着重新训练或从一开始就背负沉重的表示成本。
而在DeG框架下,模型输出的是一个“可采样的密度分布”。这意味着同一个物体,可以自然地衍生出不同规模的高斯版本。对于移动端、实时交互、在线预览,可以采样一个更少、更轻的版本;对于影视级展示、数字藏品或离线精修,则可以直接提高采样预算,获得更密集、更精细的版本。
其次,它让3D表示开始真正理解物体的局部复杂度。许多固定结构方法的问题,不在于它们不能生成高斯球,而在于它们不知道哪些地方更值得花费预算。结果往往是简单区域资源过剩,复杂区域却资源不足。DeG的非均匀采样恰恰相反,它将表示容量更集中地分配给细节、边界、薄结构和高误差区域。这一点在低预算场景下尤其关键。因为当总的高斯球数量有限时,“如何分配”比“总量多少”更重要。论文中的实验也表明,这种空间智能密度控制带来的收益,在少量高斯球的区间尤为明显。换句话说,预算越紧张,这种方法的优势就越突出。
进一步看,这种能力对众多场景都至关重要:
- 对游戏和XR:意味着同一个生成模型能更容易地适配不同等级的设备和实时性能约束。
- 对3D内容平台:意味着资产可以更自然地提供多种质量档位,而无需为每个档位单独制作,实现了类似LOD(细节层次)的效果。
- 对AIGC工作流:意味着生成系统输出的不再只是一个“结果”,而是一个更可调、更易部署的表示。
- 对机器人仿真、数字孪生和交互式AI环境:意味着有限的计算资源可以优先用于真正影响几何感知和渲染质量的部分。
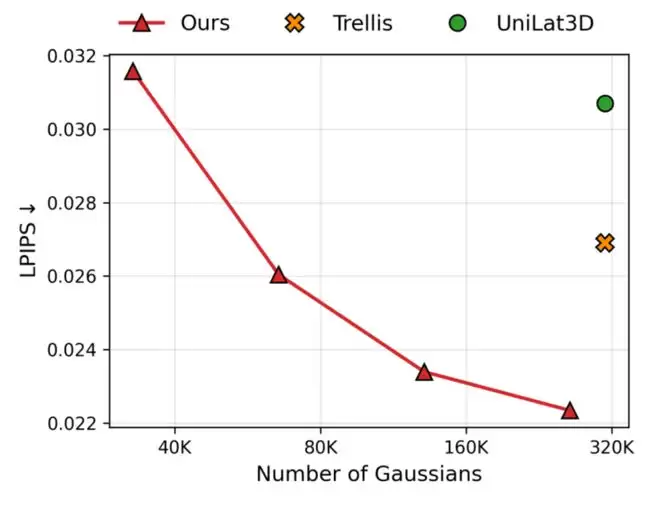
论文给出了具有代表性的结果。作为一个单图到3D的生成框架,DeG在重建和生成质量上都表现强劲。在相近的高斯预算下,其视觉质量优于TRELLIS、UniLat3D等代表性方法;而若以达到相近视觉质量所需的高斯数量来衡量,DeG能显著减少用量。文中提到,在某些场景下,DeG达到与TRELLIS相当的视觉质量时,所需的高斯数量不到后者的一半。

启示与展望
从更长的技术脉络来看,这项工作指出了一个重要方向:
3D生成模型能否不只负责“生成出来”,还负责决定“资源该如何分配”?
这看似一个底层技术问题,却直接决定了3D AIGC能否从“实验室效果”走向“实际可用”。真实世界的部署永远面临预算约束,真正有价值的模型,不仅要会生成,还要懂得在预算有限时,什么最值得被保留和强调。
DeG的意义,就在于将这种“保留什么、强调什么、简化什么”的能力,首次以可学习、可优化的方式交给了模型自身。它让3D表示不再是固定长度、固定密度的静态输出,而变成一种能够根据需要调整密度、成本和质量的表现形式。
如果再往前思考一步,这项工作促使我们重新审视一个基础问题:一个物体的高模和低模,到底应该被视为两个不同的资产,还是同一物体在不同资源约束下的两种状态?
在传统流程中,我们通常将其视为两份独立资产,因此建模、简化、LOD制作和部署被拆分成多条管线。但DeG提示了一种更自然的理解:物体本身没有改变,变化的只是我们愿意为其分配多少表示能力和渲染预算。
如果这个视角成立,那么未来的3D生成模型学到的就不仅是“物体长什么样”,还包括“在何种条件下,应以何种密度和成本被呈现出来”。到那时,高模、低模、移动端版本,或许将不再是彼此割裂的几份资产,而会成为同一个对象在不同应用场景下的连续状态。
从这个意义上说,DeG虽然具体落脚于3D高斯技术,但它真正有趣的地方,或许在于提醒我们:未来的3D内容可能不再是一份静态的“答案”,而更可能是一种能够随着设备、任务和预算不断动态调整的、“活”的表示。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

ManusAI教育应用指南 AI智能体教学实战案例解析
ManusAI是专为教育设计的智能协作者,教师只需用自然语言描述教学目标,它便能自动完成资源检索、内容生成、交互开发等全套工作,无需复杂操作。其内置教育流程可生成覆盖课前到课后的完整教学资源包,支持互动网页、微课脚本、个性化题库等。实际案例显示,该工具能有效提升学生参与度并减。

五菱缤果Pro威海上市 续航长配置全5.68万起预售火爆
五菱缤果Pro新能源车正式上市,售价5 68万至7 08万元,提供330公里与403公里两种续航版本。新车采用五门五座布局,空间利用率高,并配备快充技术。车身结构强调安全,高强度钢占比达72%。智能座舱搭载大模型与多互联方式,兼顾舒适与便利性。预售订单已突破5万台。

Trae在Python数据分析与机器学习项目中的实际应用评测
Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

吉利银河星耀7 MAX四驱版上市 售价10.88万起性能解析
吉利银河星耀7正式上市,共五款配置,售价10 88万元起。新车定位中型SUV,提供MAX四驱版本,搭载e-AWD智电四驱系统,零百加速5 4秒。设计延续“涟漪美学”,配备发光格栅与贯穿式尾灯。内饰采用环抱式座舱,配备智慧中岛扶手与Eva车载机器人。智能驾驶方面搭载千里浩瀚H3方案,支持高速NOA与自动泊车功能。

AI视频教程:如何制作镜头推进效果
在即梦AI中实现镜头推进效果,可通过慢推模板或手动运镜控制来设置轨道距离与速度。结合运动笔刷可增强局部动态,利用分镜与预设指令库能优化节奏与效率。需注意主体描述明确,参数匹配画面比例。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
