




Decart AI发布实时视频生成模型Lucy 2

Lucy 2是什么
视频编辑的未来正迎来一场深刻的变革:从传统的离线渲染等待,转向可交互、即时反馈的实时体验。引领这一变革的关键技术之一,便是Decart AI最新发布的Lucy 2.0实时世界转换模型。它的核心使命非常清晰:让高保真度的视频编辑操作,获得如同游戏般的即时响应能力。
从技术架构上看,Lucy 2.0是一个纯粹的扩散模型。这意味着它无需依赖传统的3D几何建模或深度图来解析场景,其所有关于物理世界动态的“认知”,都源自对海量视频数据演变规律的自主学习。该模型能够以1080p高清分辨率和30帧/秒的流畅度,实现近乎零延迟的连续画面生成。尤为关键的是,借助其独创的“智能历史增强”技术,模型能够自我检测并修正长时间运行中可能出现的画面质量衰减,从而确保数小时内容生成的连贯性与稳定性。为了达成极致的实时性能,Lucy 2.0专门针对AWS Trainium3芯片进行了深度优化。无论是实时角色替换、虚拟试衣,还是为机器人训练提供物理规则一致的仿真环境,它的问世,无疑为实时视觉内容创作开启了一扇全新的大门。
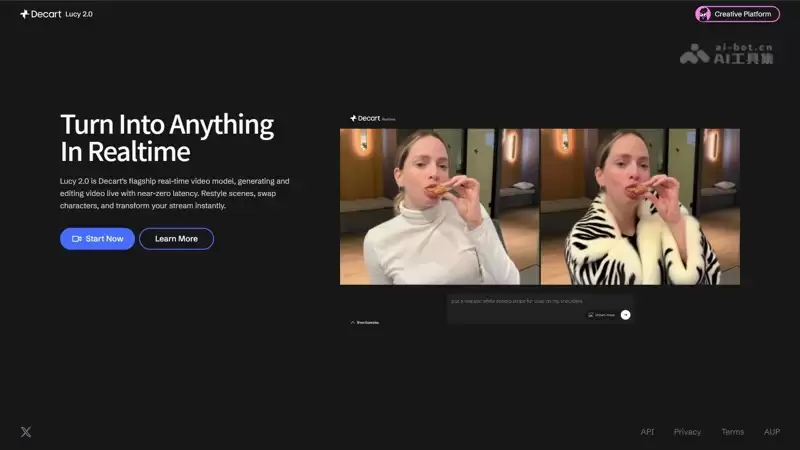
Lucy 2的主要功能
那么,这款强大的AI视频生成模型具体能实现哪些功能?我们可以从以下几个核心方面来了解:
实时视觉转换:这是其最根本的能力。模型能以30fps、1080p的高清画质,实现几乎无延迟的持续画面生成与编辑。这使得它能够直接处理直播视频流,进行即时特效叠加与内容修改,彻底告别了需要漫长等待的预渲染时代。
多维度视频编辑:用户仅需通过简单的文本指令或上传参考图片,即可轻松实现人物角色替换、服装风格变换、产品动态植入,甚至精确控制物体的运动路径与整体环境氛围的切换,操作维度全面而灵活。
持久稳定生成:在长时间生成视频时,常见的挑战如角色面部失真、几何结构扭曲或纹理细节丢失,Lucy 2.0通过其“智能历史增强”技术有效应对,保障模型能够连续运行数小时而始终保持输出画面的高质量与一致性。
机器人数据增强:这或许是它最具前瞻性的应用方向之一。模型可充当一个实时物理仿真引擎,在严格遵守现实物理规律的前提下,动态改变物体的表面材质、场景的光照条件与环境背景。从而,仅凭一段真实操作录像,就能衍生出成千上万种不同的训练场景变体,极大缓解了机器人及AI训练中高质量数据稀缺的核心难题。
Lucy 2的技术原理
支撑这些卓越功能的,是一套极具创新性的技术架构。深入理解其运作原理,便能洞悉它为何与众不同。
首先,它采用了纯扩散模型架构。这相当于摒弃了传统的“辅助工具”——不依赖于深度图、三维网格或任何显式定义的物理引擎规则。模型对于视觉动态的所有理解,都源于对视频数据本身内在规律的观察与学习,这是一种更为本质和原生的世界建模方式。
由此带来的一个重要特性是涌现的物理理解能力。模型能够从数据中隐式地学习到世界的结构知识,例如手指的关节拓扑、布料受力的褶皱形态、物体之间的分离逻辑等。所有这些复杂规则都无需工程师手动编码定义。
其实现长期稳定性的核心在于Smart History Augmentation(智能历史增强)技术。这项技术的精妙之处在于,在训练阶段,模型会被有意地暴露于自身有缺陷的历史输出面前,并因此受到训练信号的“惩罚”。通过这种机制,它学会了主动识别并纠正生成过程中逐渐累积的质量偏差,而非简单地延续前一帧的错误,从而有效防止了失真现象的扩散。
最后,所有算法优势都需要强大的硬件支撑才能完全释放。Lucy 2.0针对AWS Trainium3芯片进行了深度定制:采用宏内核设计以减少计算启动开销,利用片上SRAM来规避高带宽内存的访问延迟,再结合定制化的WebRTC视频传输管道,共同构建了一条从云端计算到终端显示的端到端实时处理流水线。
Lucy 2的项目地址
如果您希望深入了解技术细节或亲自体验其强大功能,可以通过以下官方渠道访问:
项目官网与论文:https://decart.ai/publications/lucy-2-introducing-sota-video-generation-in-realtime
在线演示与体验:https://lucy.decart.ai/
Lucy 2的应用场景
基于上述强大的实时视频生成与编辑能力,Lucy 2.0正在多个行业领域催生创新的工作流程与解决方案:
实时直播与互动娱乐:对于直播和电竞行业,这意味着一场体验革命。主播可以在直播过程中,实时进行虚拟形象更换、在线试穿不同服装或动态植入广告产品,各种复杂的视觉特效无需后期制作即可即时呈现,显著提升了直播的互动性与观赏性。
影视广告与现场创作:电影、广告及短视频领域的创作者将获得前所未有的灵活性。在拍摄现场,导演即可通过文本指令实时调整画面色调、环境天气或场景元素,将大量后期特效工作前置,实现“所调即所得”的即时视觉预览,极大提升了内容创作的决策效率与制作流程。
机器人及AI训练数据合成:这是人工智能研发领域的强大助力。研究团队可以利用模型实时生成大量多样且符合物理规律的训练数据,将一段有限的真实操作记录,扩展为涵盖不同材质属性、光照条件和背景环境的数千个高质量仿真样本,从根本上突破机器人强化学习中数据采集成本高昂、场景覆盖不足的关键瓶颈。
虚拟制片与实时仿真:对于影视制片与游戏开发团队,模型长时间稳定运行的能力价值巨大。它可以用于实时生成可交互的动态虚拟背景与环境模拟,直接替代传统耗时且昂贵的离线渲染流程,让虚拟制片、预可视化以及沉浸式体验开发变得更加敏捷与经济。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿里达摩院开源具身智能大脑RynnBrain基础模型详解
RynnBrain是什么 在具身智能领域,如何让机器人真正理解并适应复杂的物理世界,始终是核心挑战。近期,阿里巴巴达摩院发布了一项重要成果——开源了名为RynnBrain的具身智能大脑基础模型。这一模型实现了关键突破,首次赋予机器人接近人类的时空记忆与物理空间推理能力。 具体而言,RynnBrain

昆仑万维开源SkyReels-V3多模态视频生成模型详解
SkyReels-V3是什么 视频创作的门槛,正在被一项新技术重新定义。最近,昆仑万维开源的SkyReels-V3,可以说在业内投下了一枚“重磅冲击波”。它不再是一个功能单一的玩具,而是一个用单一架构就能实现专业级视频创作的“多面手”。简单来说,它能让你手里的静态照片“活”起来,变成动态影像;还能智

HKUDS开源AI Agent经济生存基准测试框架ClawWork详解
ClawWork是什么 如果让AI去真实世界里“打工”,它能不能养活自己?香港大学数据科学实验室(HKUDS)开源的ClawWork项目,就是为了回答这个问题而生的。它本质上是一个AI Agent的“经济生存”基准测试框架,专门评估大模型在模拟真实商业环境中的“赚钱能力”。 这套系统的规则很现实:给

小红书开源图像编辑模型FireRed使用指南
FireRed-Image-Edit是什么 在AI图像生成与编辑领域,开源模型正迅速崛起,其能力已能比肩甚至超越部分闭源方案。近期,由小红书Super Intelligence团队研发并开源的FireRed-Image-Edit模型,便是这一趋势下的杰出代表。这款基于先进扩散架构的通用图像编辑AI,

蚂蚁开源全模态大模型Ming‑Flash‑Omni 2.0详解
在人工智能模型普遍追求规模与通用性的当下,开发者们迫切需要一款能够真正“看懂”图像、“听懂”声音、“读懂”文字,并能自由进行跨模态内容创作的“全能型”AI工具。近期,蚂蚁集团重磅开源的全模态大语言模型Ming-flash-omni-2 0,正将这一愿景变为现实。它不仅彻底打通了图像、视频、音频与文本








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
