




腾讯姚顺雨团队发布CL-bench模型学习能力评测基准

CL-bench是什么
当前大语言模型最核心的短板是什么?答案或许并非算力或数据规模,而是一项更为基础的关键能力:上下文学习。简而言之,当面对一段全新的、从未接触过的信息时,模型能否即时理解、吸收并运用这些知识来解决问题?这正是当前许多AI模型的普遍瓶颈。
为了精准量化与评估这一能力,腾讯混元团队与复旦大学合作,正式推出了名为CL-bench的评测基准。其全称为“上下文学习能力评测基准”,专门用于衡量大语言模型从给定的全新上下文信息中,实时学习并应用知识解决实际问题的性能。
该基准的评测体系极为严谨,由领域专家精心构建了涵盖500个复杂场景的测试集,包含总计1899个具体任务,全面覆盖了领域知识推理、复杂规则系统应用、程序性任务执行以及经验发现与模拟这四大类现实挑战。评测结果颇具启发性:即便是当前最先进的顶尖模型,其平均任务解决率也仅在23.7%左右。这一数据清晰地揭示了行业的核心瓶颈——许多模型仍过度依赖预训练记忆,而非真正掌握了动态的“现场学习”能力。这为下一代模型的研发与优化指明了至关重要的方向。
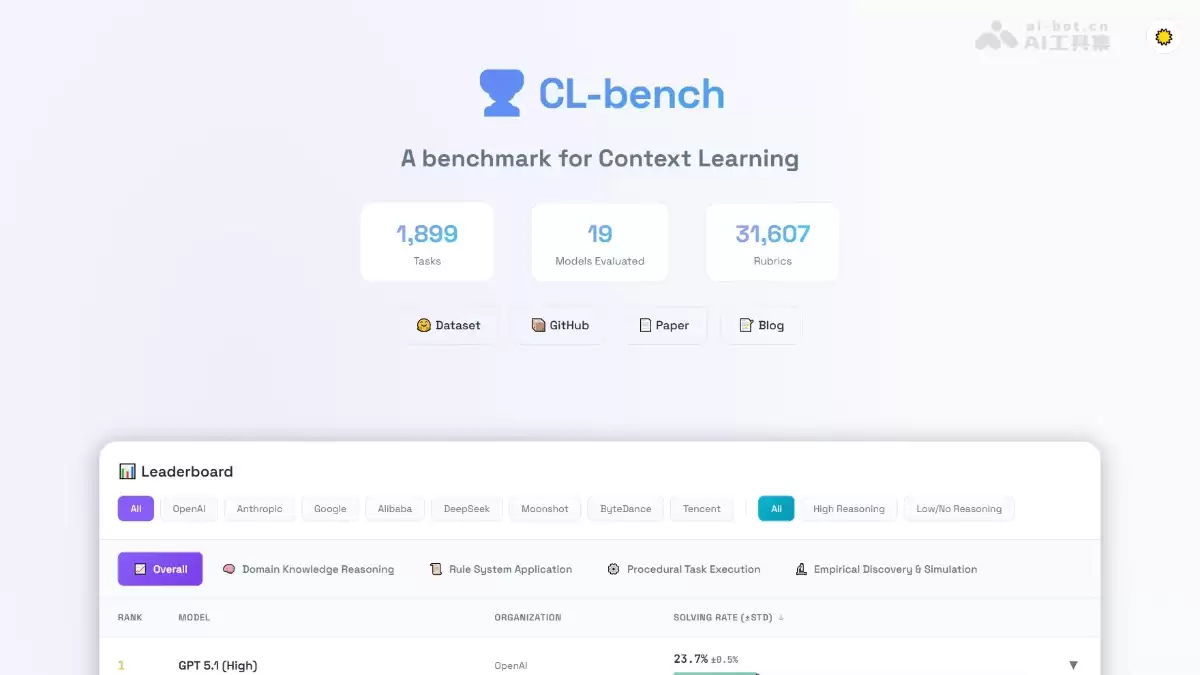
CL-bench的主要功能
CL-bench如何实现对模型上下文学习能力的精准评测?它主要通过以下几项核心功能达成目标:
- 实时学习能力评测:这是基准的核心目标。它严格禁止模型调用外部知识库或依赖内部记忆,所有解题所需信息都必须从给定的上下文中即时提取并应用,从而真实反映模型的“即兴”学习与推理水平。
- 大规模多样化测试集:为模拟现实世界的复杂性,CL-bench构建了一个规模庞大且多样化的测试集,包含500个独立场景、1899个任务,并配备了多达31607条精细的验证标准。其涵盖的四大类场景(知识推理、规则应用、程序执行、经验模拟)几乎囊括了AI在应用中可能遇到的所有棘手情况。
- 抗记忆污染数据设计:为确保评测的公正性,防止模型通过“记忆”旧知识来答题,CL-bench采用了特殊的数据构建策略。所有数据要么是完全虚构的体系(例如为一个虚构文明设计法律),要么是对现有知识进行系统性修改生成的“平行世界”版本,或是整合了极其小众、新兴的内容,确保对所有模型而言都是首次接触。
- 序列依赖任务验证:现实问题往往具有连贯性。CL-bench中超过半数(51.1%)的任务设计了序列依赖性,即后续步骤的解答严格依赖于前一步的正确输出,以此深度检验模型的多轮次、链式推理能力。
- 多维度精细化评估:评估标准绝非简单的二元判断。平均每个任务都设置了约16.6个评估维度,从多个角度全面、细致地检验模型对上下文的理解深度、逻辑一致性以及知识应用准确性,避免单一指标带来的评估偏差。
CL-bench的技术原理
为实现上述功能,CL-bench在技术架构与设计理念上进行了深度创新,其核心原理可归纳为以下三点:
- 自包含上下文环境构建:这是最根本的设计原则。每个任务都提供了一个信息完备、自包含的上下文环境,解决问题所需的全部定义、规则和事实均明确包含其中,无任何隐藏假设,且禁止外部检索。这强制模型必须从当前提供的全新信息中进行学习,清晰地区分“动态学习能力”与“静态记忆能力”。
- 三重数据无污染保障策略:为彻底杜绝数据泄露风险,确保评测数据的绝对新颖性,CL-bench实施了三重保障:一是由专家人工创作完全虚构的体系(如新编程语言语法);二是对现实世界内容进行系统性、结构化的修改,创造可信的变体;三是引入在模型预训练数据中极罕见的前沿或冷门领域内容。这三重策略共同构成了可靠的数据“防火墙”。
- 高复杂度与强可验证性设计:任务本身追求高度的复杂性和序列依赖(如前所述),以模拟真实工作场景中的挑战。同时,每个任务都配有极其详尽、可客观量化验证的评估标准(平均每个上下文关联高达63.2个验证点),确保评测过程既全面、深入,又具备高度的可重复性与公正性。
CL-bench的项目地址
CL-bench是一个面向全球研究社区的开源工具。研究人员与开发者可通过以下官方渠道获取完整的数据集、代码及详细文档:
- 项目官网:https://www.clbench.com/
- GitHub开源仓库:https://github.com/Tencent-Hunyuan/CL-bench
- HuggingFace数据集:https://huggingface.co/datasets/tencent/CL-bench
CL-bench的应用场景
这样一个专业、严谨的评测基准,拥有广泛而实际的应用价值:
- AI模型能力诊断与评估:为各大AI研究机构及企业的模型团队提供一把“标准尺”,精准定位模型在贴近真实应用场景下的能力短板,使研发优化工作更具针对性。
- 新模型研发与效果验证:在新模型或新版本发布前,可作为核心的验证环节。它能有效鉴别性能提升是源于真正的上下文学习能力突破,还是仅仅依赖于参数规模的扩大或记忆的增强。
- 行业解决方案技术选型:助力企业在采购或部署AI行业解决方案时,能够客观、量化地评估不同模型在特定业务场景下的现场学习与适应表现,从而做出更明智、更可靠的技术决策。
- AI教育与能力培训:作为卓越的教学案例与实验平台,帮助AI学习者与实践者深刻理解“上下文学习”与“参数记忆”的本质区别,提升其设计能够解决实际问题的模型架构的能力。
- 学术研究统一基准:为学术界提供一个标准化、公平化的研究基准,使得不同团队在“上下文学习”这一前沿领域的创新成果能够进行有效的横向对比与复现,从而加速该领域理论与技术的整体进步。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

小米开源机器人VLA模型技术解析与应用指南
Xiaomi-Robotics-0是什么 如果需要一个能够“感知环境、理解语言、并执行物理操作”的智能核心,那么小米最新开源的Xiaomi-Robotics-0,无疑是这一领域的一次重大突破。作为拥有47亿参数的首代机器人VLA(视觉-语言-动作)大模型,其设计理念极具巧思:它采用一种混合架构,清晰

北大联合谷歌推出AI学术插图生成框架PaperBanana
PaperBanana是什么 对于广大AI科研工作者而言,绘制符合发表标准的论文插图是一项耗时费力的挑战——既要精确表达复杂的模型架构与算法流程,又要满足NeurIPS、ICLR等顶级会议的视觉审美要求。如今,这一难题迎来了创新的解决方案:PaperBanana。 这是由北京大学与Google Cl

字节跳动Seed2.0通用模型系列详解与应用
Seed2 0是什么 近期,字节跳动旗下Seed团队正式发布了全新的Seed2 0大语言模型系列,这一动作在人工智能领域引发了广泛关注。该系列阵容完备,包含三款通用智能体(Agent)模型——Pro版、Lite版和Mini版,以及一款专精于编程的Code模型。 此次版本迭代的核心在于模型综合能力的全

字节跳动Seedance 2.0 AI视频生成模型详解
Seedance 2 0是什么 在AI视频生成技术快速发展的今天,每一次重大升级都意味着创作门槛的进一步降低。字节跳动最新推出的Seedance 2 0模型,正是这一浪潮中的前沿代表。它被定义为新一代的AI视频生成引擎,其核心优势在于强大的“多模态参考理解”与“高效一体化创作”能力。 通俗地讲,用户

Mistral AI发布Voxtral Transcribe 2语音转文本模型
Voxtral Transcribe 2是什么 在语音转文本领域,竞争日益白热化。近期,Mistral AI推出的Voxtral Transcribe 2系列模型,为市场注入了新的活力。该系列包含两款针对性产品:Voxtral Mini Transcribe V2专注于批量音频转录,支持包括中文在内








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
