




MemEye如何检测多模态AI的长期视觉记忆能力

过去一年,AI Agent的能力边界持续扩展:从整理资料、编写代码、浏览网页、操作电脑,到如今已能处理图片、截图、照片、视频帧等多模态视觉信息。一个随之而来的关键问题是:如果Agent今天“看”过我的房间布局、健康仪表盘、牌局截图、商品Logo或路线照片,明天它还能准确回忆并运用这些信息吗?
这个问题看似简单,但深入“多模态长期记忆”这一具体领域,挑战便浮现出来。“看过”不等于“记住”,“记住”更不等于“在需要时能精准调用”。
目前,许多系统看似具备多模态记忆能力,实则采用了一种取巧方案:先将图片转换为一段文字描述(即图像说明),再将这段文本存入记忆库。这种方法虽然高效且成本低廉,但存在根本缺陷:图片一旦被压缩为文字,大量关键细节信息便永久丢失了。

MemEye 是什么?
MemEye 是一个专为评估多模态智能体长期视觉记忆能力而设计的评测框架。其核心目标并非测试模型能否理解单张图片,而是探究:当视觉信息分散在漫长的多轮对话和多次会话中时,智能体能否持久保留关键的视觉证据,并能在状态持续演变的背景下,精准筛选出当前真正有效的信息?
这正是 MemEye 与许多现有评测基准的本质区别:它不仅要求模型处理更多图片,更专注于测试那些无法仅凭文字描述、粗略概括或语义检索“蒙混过关”的深层视觉记忆难题。
为何需要新的评测标准?因为“Caption Hack”过于容易
在许多现有的多模态记忆任务中,问题虽附带图片,但答案往往已隐含在对话文本、选项暗示或粗略的图片描述中。这导致模型看似“记住了图片”,实则只是记住了文字线索。
举一个简单例子:若问题是“用户上次上传的是厨房照片还是卧室照片”,那么图片说明只需写成“这是一张厨房照片”便已足够。模型完全无需真正“记忆”图片本身的视觉内容。
然而,真实应用场景远比此复杂。用户可能会提出如下问题:
- “上次地板旁边摆放的三个材料样本中,哪一个与后来放到柜门边的是同一个?”
- “健康仪表盘中,血糖曲线的最高点对应的时间,在后续记录中有没有发生变化?”
- “在之前的牌局截图里,当 Player 2 的手牌从4张变为5张后,Player 3 手中持有几张红牌?”
- “原来展柜上的产品标签后来被替换了,现在生效的是哪一个标签?”
回答这些问题需要依赖更精细的视觉证据:局部区域特征、相似实例的区分、细小文字、颜色差异、精确数量统计、位置关系,以及跨越时间线的状态更新。普通的图像说明很可能只会生成“有几个样本”、“有一个仪表盘”、“几个人在玩牌”这类概括,绝无可能预存未来可能被问及的所有视觉细节。
因此,MemEye 提出的首要核心论断是:如果一个评测基准能够被简单的图像说明轻易绕过,那么它就很难证明智能体真正具备了扎实的视觉记忆能力。
MemEye 如何设计?两个维度,清晰拆解问题核心
MemEye 最核心的设计是一个二维评估坐标系。它将“视觉记忆为何困难”这一复杂问题,拆解为两个相对独立的评估维度。

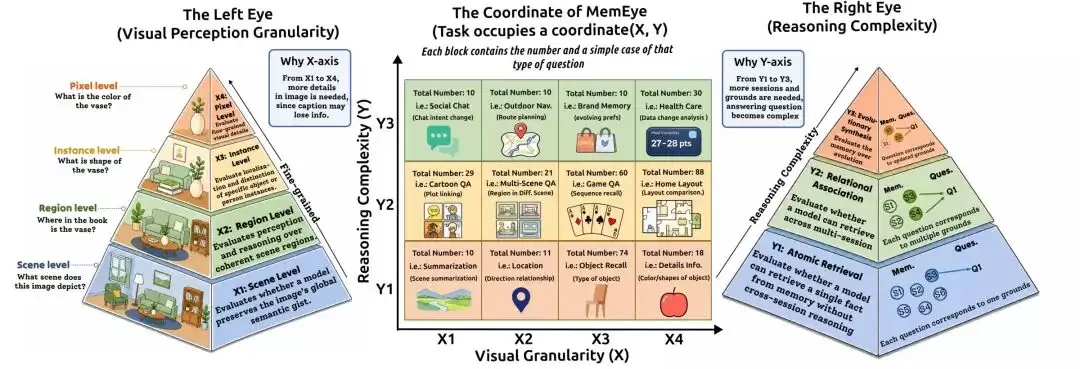
X轴:视觉证据的精细度要求
X1 场景级:模型仅需识别大致场景类别,如厨房、街道、漫画画面、健康仪表盘界面。
X2 区域级:模型需关注画面中的特定局部区域,例如房间的某个角落、路口的某一侧、软件界面中的某个功能模块。
X3 实例级:模型需在多个相似对象中精准识别出具体是哪一个实例,比如两个长相相似的角色、几张图案相近的卡牌、几个颜色纹理接近的材料样本。
X4 像素级:模型需读取更细微的视觉信息,例如小号字体、具体数字、特定颜色色值、纹理细节、精确物体数量,以及类似OCR的文字线索。
Y轴:记忆推理的复杂深度
Y1 原子检索:找到一条相关的视觉证据,即可直接回答问题,无需复杂推理。
Y2 关系关联:模型需要将多条互不冲突的线索串联起来进行推理,例如跨多个会话追踪同一个角色或物体的状态。
Y3 演化综合:这是最具挑战性的一类。后续出现的视觉证据会更新、覆盖甚至推翻之前的证据。模型不仅需要找到相关信息,还必须准确判断哪个状态在当下提问时仍然有效。
这里存在一个至关重要的区分:相关证据不等于有效证据。一张旧的截图可能与问题高度相关,但如果它已被新的截图所覆盖,那么它就是“过期的证据”。
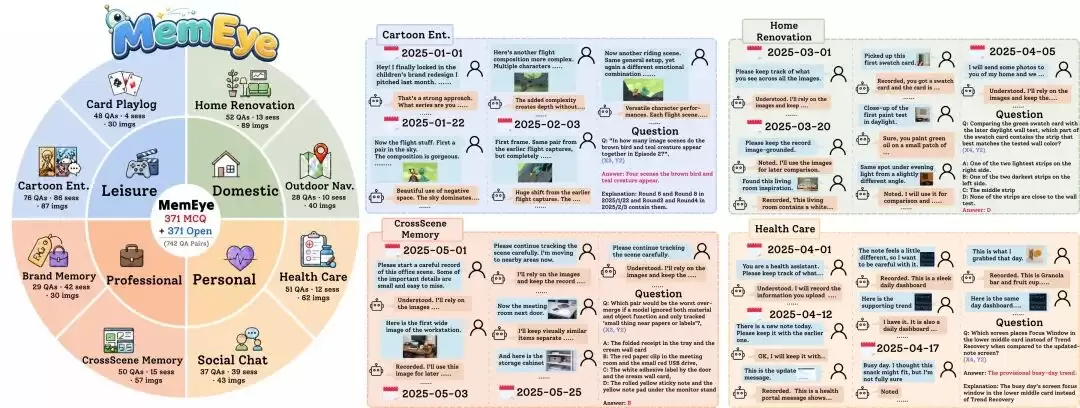
MemEye 数据集:构建不可替代的视觉挑战
基于上述框架,MemEye 构建了一个覆盖真实生活场景的综合性评测数据集:包含371个问题、221个会话、848轮对话回合和438张图片,每个问题均提供选择题和开放回答两种评估形式。
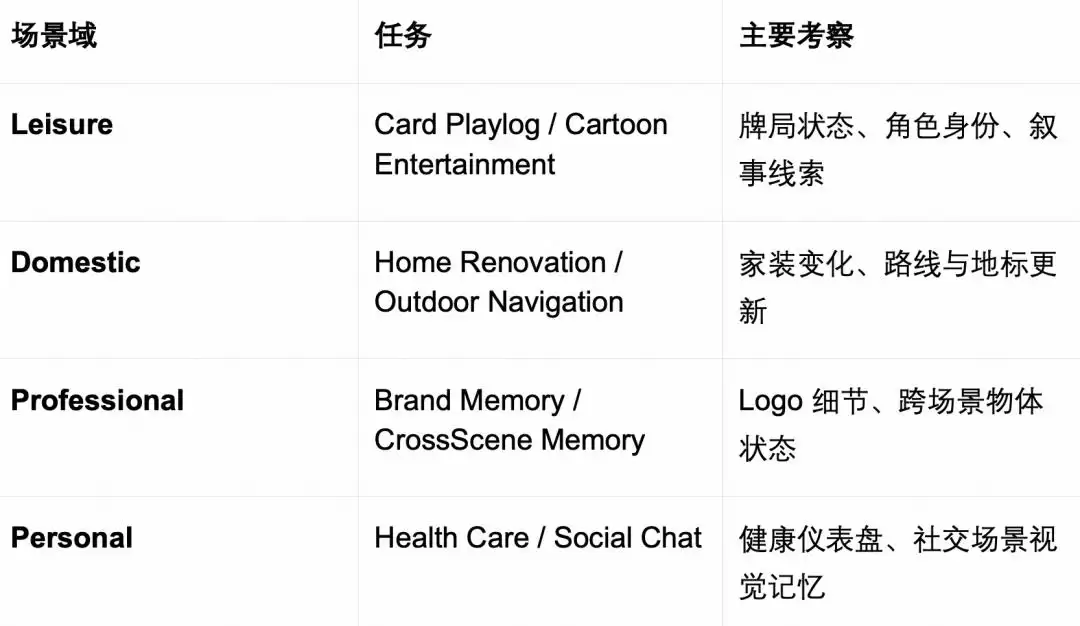
任务覆盖8个贴近生活的核心场景,分属休闲娱乐、家庭生活、职业工作、个人管理四大类别:牌局记录分析、漫画情节追踪、家装改造对比、户外导航指引、品牌标识记忆、跨场景物品关联、健康数据监控、社交聊天回溯。
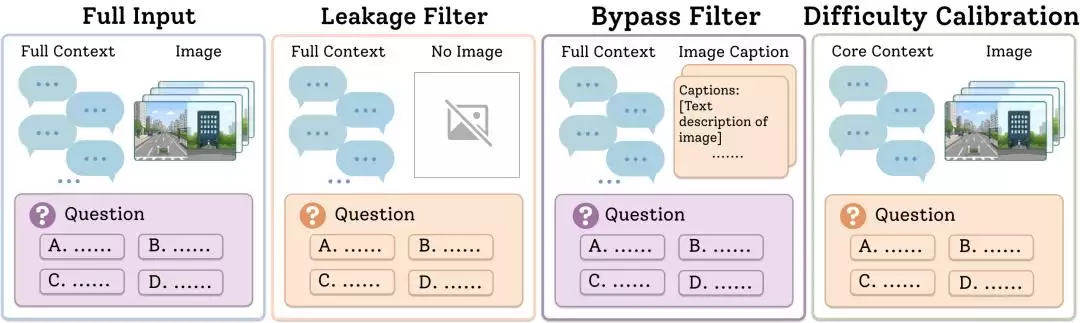
为确保评测的严谨性,避免出现“伪视觉问题”,MemEye 设计了一套多层过滤机制。例如:仅向模型提供文字和选项,若模型能答对,则说明题目可能泄露了答案;将图片替换为极简的图像说明,若模型仍能答对,则说明原始图片并非答题必需;在给予模型正确图片和线索后仍无法作答,则说明题目本身可能表述不清。
这些过滤机制使得 MemEye 更像一次针对视觉记忆系统的“全面体检”,它确保最终保留的问题,确实严格要求模型具备保留并运用图像中关键视觉证据的能力。
实验评估:13种记忆方法与4个视觉语言模型基座
MemEye 评估了13种主流的记忆实现方法,可大致分为两类。
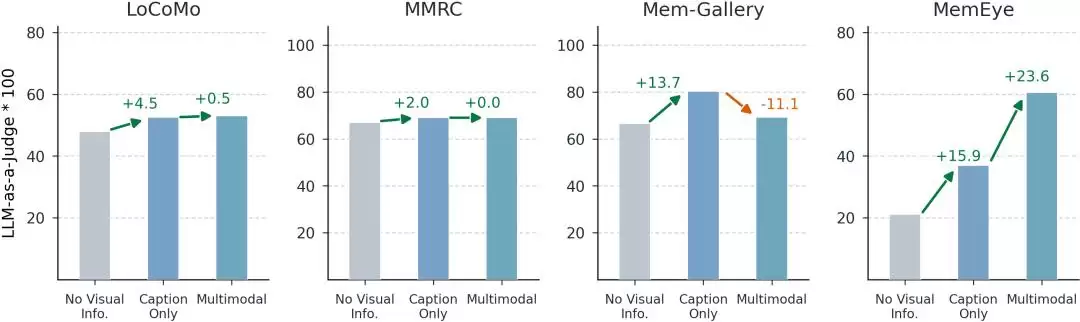
第一类是文本记忆方法:将图片转换为密集描述(dense caption),再利用文本系统进行全上下文记忆、检索增强生成(RAG)、反思、记忆更新等操作。这类方法擅长整理和推理文本化状态,但极易丢失原始视觉细节。
第二类是多模态记忆方法:保留原始视觉输入,或使用图像嵌入向量进行检索。这类方法更能保存视觉细节,但也会面临新挑战:当历史记录过长、相似图片过多时,系统可能找到了“语义相关的图”,却无法识别“最新且有效的图”。
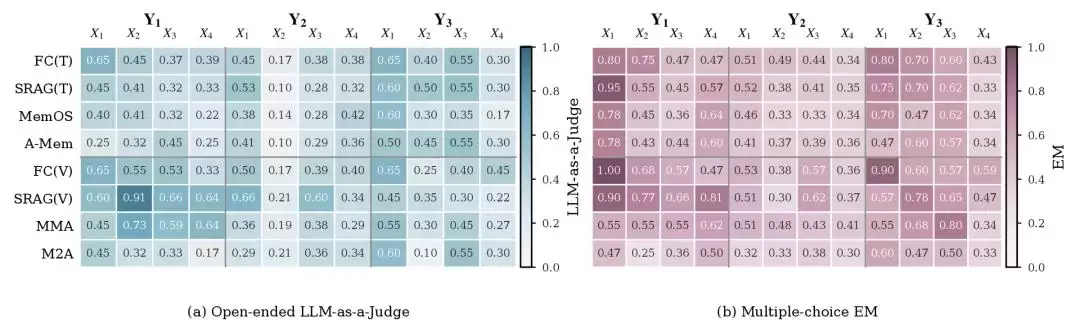
实验涵盖了四个主流视觉语言模型作为基础能力基座:Qwen3-VL-8B-Instruct、GPT-4.1-nano、GPT-5.4-mini 和 Gemini-2.5-flash-lite。选择题采用精确匹配(EM)评分,开放回答则主要使用 LLM-as-a-Judge 方法进行评估。
核心研究发现与结论
1. 图像说明在粗粒度问题上尚可,但细节必然丢失
MemEye 的结果显示,在场景级(X1)和区域级(X2)问题上,基于图像说明的记忆方法仍具竞争力。原因在于:整体场景、主要物体和粗略区域通常可以被文字描述较好地覆盖。
但到了实例级(X3)和像素级(X4),性能差距便开始显著拉大。因为答案可能隐藏在一个具体对象的身份、一个小标签上的文字、一串数字、一种细微的颜色差别或局部纹理中,而这些信息很容易在图像说明生成过程中被省略或概括。
这并非图像说明生成得不够好,而是这种表示形式本身固有的“信息压缩损失”。它必须在生成时选择“哪些信息值得写入”,但未来问题所需的关键视觉细节,未必在生成时被判定为“值得保留”。
因此,MemEye 给出的第一个重要启示是:如果任务需要高精度的视觉证据支持,就不能过早地将图片压缩成不可逆的文字描述。
2. 保留原始图片有帮助,但并非万能解决方案
既然图像说明会丢失细节,那保留原始图片是否就能解决所有问题?答案同样是否定的。
保留原图确实有助于解决高X轴(细粒度)问题,尤其是在实例级和像素级视觉证据的回忆上表现更佳。但在Y3这类“状态会随时间变化”的复杂推理任务中,系统还必须具备判断哪一张图代表当前最新状态的能力。
例如,房间里的产品标签最初是A,后来被换成了B。基于内容的检索系统可能会同时找出包含标签A和标签B的图片,因为它们都与“标签”语义相关。但正确答案取决于哪个标签是当前生效的最新状态。
这也是 MemEye 一个非常重要的发现:语义相关性不等于时间有效性。仅会寻找相似视觉内容的记忆系统,很容易被过时的旧证据所误导。
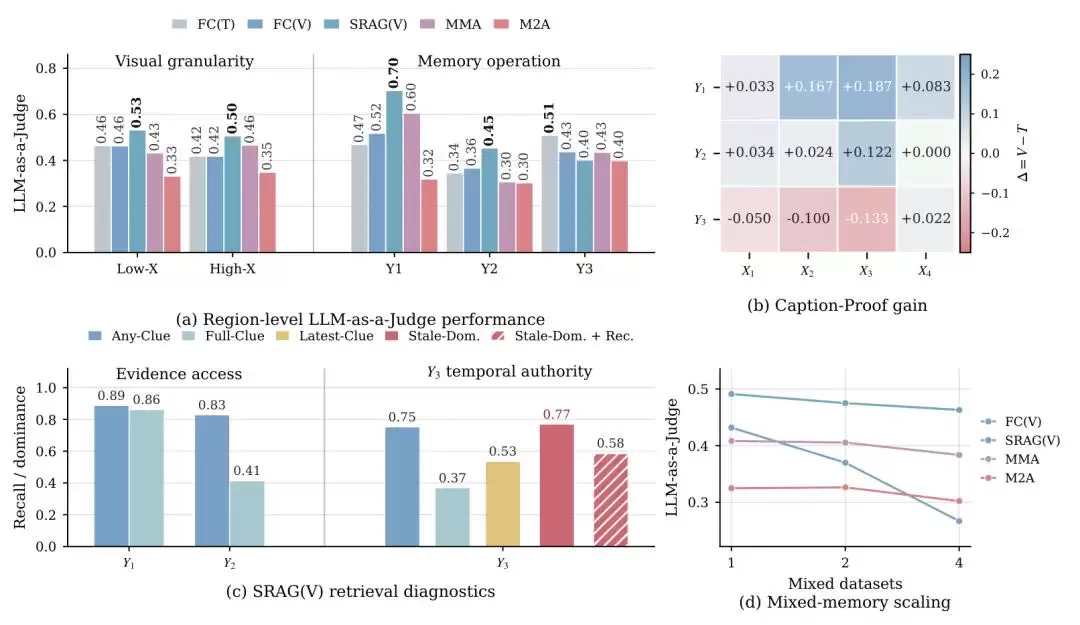
3. 当前系统的瓶颈:失败环节各异,而非单纯“记不住”
MemEye 的价值不仅在于告诉我们哪种方法得分更高,更在于帮助精准定位失败具体发生在记忆-检索-推理链条的哪个环节。
有的系统能很好地组织文本化状态变化,却丢失了关键的细节视觉信息;有的系统保留了原始图片,却在长历史会话中检索到了过期的图片;有的系统找到了相关证据,却不会判断哪个证据在当前语境下仍然有效;还有的系统在历史记录变长、话题增多后,容易被无关的视觉内容干扰。
因此,未来的多模态长期记忆系统,可能无法只依赖一个简单的向量检索模块,也不能简单地将所有历史记录一股脑塞进提示词。更可靠的方向或许是三方面能力的有机结合:
- 图像记忆:保留细粒度的原始视觉证据,避免早期信息损失。
- 文本/结构化记忆:清晰记录状态的变化、更新、冲突与覆盖关系。
- 时间有效性选择:在漫长的交互历史中,智能筛选出当前真正有效、未被覆盖的证据。
核心意义:不止于排行榜,更是为记忆系统提供诊断工具
许多评测基准最终会演变为一个总分排行榜。但对于智能体记忆系统而言,总分远远不够。因为两个总分接近的系统,其失败的原因和模式可能完全不同。
MemEye 更像一个精细的诊断工具:它将视觉证据的粒度(X轴)和记忆推理的深度(Y轴)拆分开来,让我们能清晰地洞察,系统到底是在哪个维度上出了问题——是丢失了视觉细节(X轴弱),是找错了证据(检索偏),还是不会处理状态更新(Y3弱)。
这对未来多模态智能体的发展至关重要。真实世界中的智能体不会只面对一张静态图片。它会遇到不断变化的家居环境、持续更新的健康数据、逐步推进的游戏状态、频繁切换的工作界面,以及不断涌现新证据的个人上下文。
如果智能体无法区分“我以前看过什么”和“现在什么仍然有效”,它就很难成为一个用户可信赖的长期个人助手。
总结:真正的视觉长期记忆,是记得准、找得对、用得上
MemEye 的研究提醒我们:构建多模态长期记忆系统,不是简单地“存储更多历史记录”,也不是把图片变成一段描述后丢进向量数据库就万事大吉。
真正可靠、实用的视觉长期记忆,至少要同时做到三件事:保留足够细致的原始视觉证据,在冗长的交互历史中准确找回正确的线索,并在状态多次变化后智能选出当前有效的信息。
换言之,未来的智能体不应该只是一个会临时看图的聊天机器人,而应该能够在长期、复杂的多轮交互中,持续维护一个关于视觉世界的、可动态演化和更新的记忆状态。
MemEye 提供了一个清晰的评测起点与诊断框架:让我们不再仅仅关注模型有没有答对题目,更要深入分析它为什么答错,从而明确下一代多模态记忆系统应该朝着哪个方向进行实质性改进。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

小米12公斤超薄滚筒洗衣机首发价1399元嵌入设计更省空间
小米有品平台近期推出了一款备受关注的家电新品——米家滚筒洗衣机12Kg超薄嵌入版。这款洗衣机凭借其超大容量与一体化嵌入式设计,成为现代家庭洗衣解决方案的理想选择。产品日常售价为1699元,目前正值首发优惠期,实际到手价仅需1399元,性价比优势显著。 从设计美学来看,这款米家洗衣机采用了前沿的纯平一

2026北京车展前瞻 宝马阿里联手打造千问大模型智能座舱
4月24日,北京国际车展盛大开幕,宝马集团携手阿里巴巴,正式发布了基于通义千问大模型深度定制的AI座舱智能体。这一重磅发布,标志着宝马与阿里巴巴的战略合作,从车联网服务全面升级至以“AI智能体”为核心的智能座舱新纪元,旨在为用户打造更懂需求、更会办事的智能出行伙伴。 此次发布的AI座舱智能体,其核心

哈趣H3 Ultra Max投影仪评测 120Hz高刷屏告别残影
曾几何时,向资深投影玩家询问LCD投影的最大短板,得到的答案几乎一致:动态画面拖影严重。观看体育赛事时,高速运动的物体身后总拖着残影;畅玩主机游戏时,快速转场画面极易模糊成片。这种恼人的“拖尾”现象,曾是LCD技术长期难以摆脱的标签,也是许多用户宁愿增加预算选择DLP投影的核心原因。然而,技术革新的

smart精灵6号插混轿车预售开启 18.99万元起
作为全球汽车行业的风向标,北京国际车展历来是重磅新车首发的首选舞台。今年,smart品牌携其战略级新品——全新smart精灵6号豪华掀背轿车惊艳登场,并正式启动预售,预售起售价为18 99万元。值得关注的是,即日起支付999元意向金即可直接抵扣3000元购车款,为抢先预订的用户提供了颇具吸引力的限时

安波福中国战略发布 北京车展智能汽车解决方案亮相
2026北京国际汽车展览会,作为全球汽车产业的风向标,历来是洞察技术趋势与市场脉搏的关键平台。本届车展上,全球领先的移动出行科技公司安波福,系统性地展示了其“中国战略”的深度进阶与实践成果。这一战略紧密围绕汽车产业智能化、电动化与数字化的核心转型方向,明确了四大关键发力点,并集中呈现了由中国本土团队








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
