




清华校友王冠新作:1/900算力颠覆Transformer预训练模型

训练一个能打的大语言模型,到底要花多少钱?这个问题,如今正把许多研究团队挡在门外。动辄数千张GPU、上千万美元的算力投入,以及数万亿token的数据需求,让基础模型的预训练几乎成了少数巨头的专属游戏。但最近,一项来自清华校友团队的研究,或许为我们推开了一扇新的大门。
这项工作的核心,是一个名为HRM-Text的高效预训练方案。它没有沿着“堆数据、堆算力”的老路内卷,而是选择从模型架构和训练目标这两个根本环节入手,重新思考效率问题。结果令人印象深刻:仅用约1500美元的成本、40B的非重复token和1B参数,HRM-Text就在MMLU、GSM8K等主流基准测试中,取得了媲美2B至7B参数开源模型的成绩。这背后,是比标准基线模型少100-900倍的训练token和96-432倍的估计计算量。

论文链接:https://arxiv.org/abs/2605.20613
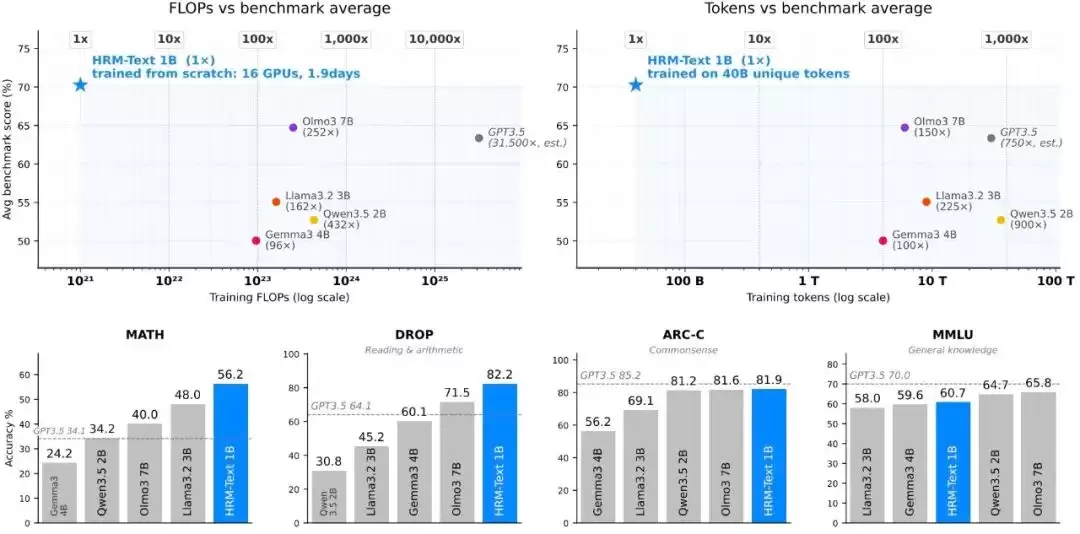
图|预训练效率对比,HRM-Text展现出显著优势。
这项研究传递出一个清晰的信号:通过引入更强的结构先验和更精准的训练目标,我们完全有可能大幅降低预训练的门槛。让更多团队能够从零开始训练有竞争力的基础模型,正变得可行。
HRM-Text 是怎样设计的?
要理解HRM-Text的高效从何而来,得先看看当前预训练的“痛点”。标准Transformer架构在处理每个token时只做一次前向传播,而大量的计算实际上消耗在了提示词、格式填充和网页噪声等与核心推理无关的token上。这就像为了提炼一点黄金,却不得不处理整座矿山的矿石,效率自然低下。
HRM-Text的解决方案是双管齐下:革新架构,并重塑训练目标。
首先是架构革新。 研究团队用分层循环模型(HRM)取代了标准Transformer。HRM的核心思想是“递归深化”:它将计算拆分为慢速(H)和快速(L)两个模块,对同一个token进行多轮递归更新。你可以把它想象成一个反复推敲、逐步深化思考的过程。H和L模块各自只占一半的核心参数,整体计算量大致相当于对同一套参数递归展开4次。这样做的妙处在于,在不增加参数总量的前提下,显著提升了模型的有效计算深度。
其次是训练目标的重塑。 团队放弃了传统的全文自回归预训练模式。取而代之的是,直接在高质量的“指令-回答”对上训练,并且只对回答部分计算损失。同时,配合使用PrefixLM掩码机制:让模型在理解指令时可以双向关注所有信息(就像阅读理解),而在生成回答时则严格遵循因果顺序(像逐字写作)。这确保了每一份计算力,都直接用于提升模型完成指令、输出答案的核心能力上。
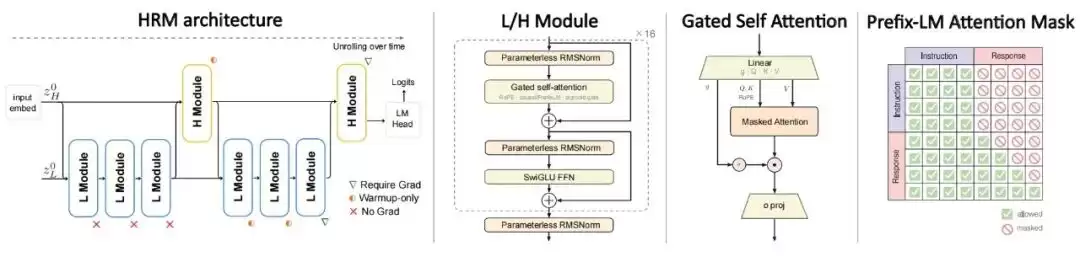
图|HRM-Text 架构示意图,展示了分层循环与PrefixLM训练目标的结合。
当然,深度递归训练 notoriously 难以稳定。为此,团队引入了两项关键技术:MagicNorm和Warmup Deep Credit Assignment。
MagicNorm是一种巧妙的混合归一化策略,它利用了截断反向传播中前向与反向计算深度的不对称性,在模块内部采用PreNorm,并在出口额外添加归一化,从而稳住了深层递归的训练过程。
Warmup Deep Credit Assignment则像一种“学步车”机制:训练初期,梯度只回传到最后2个递归步骤,让模型先在短依赖路径上稳定收敛;随后再线性地将梯度回传路径扩展到最后5步,逐步教会模型处理更长的依赖关系。这套组合拳,有效解决了循环模型训练的稳定性难题。
效果怎么样?
理论设计精妙,实际效果如何?实验数据给出了有力的回答。
1. 循环架构,效率更高吗?
在固定训练计算量(FLOPs对齐)的条件下,HRM-1B模型在大多数基准测试上的表现,都优于参数规模相同的Transformer-1B、甚至参数更多的Transformer-3B。与同样尝试循环计算的Looped Transformer和RINS模型相比,HRM也显示出优势。更重要的是,HRM在所有测试规模下都保持了平稳的训练动态,而Transformer模型在10亿参数规模时出现了严重的不稳定。在某个0.6B规模的对比中,HRM仅需比Transformer少2倍的计算量,就能获得具有竞争力的性能。
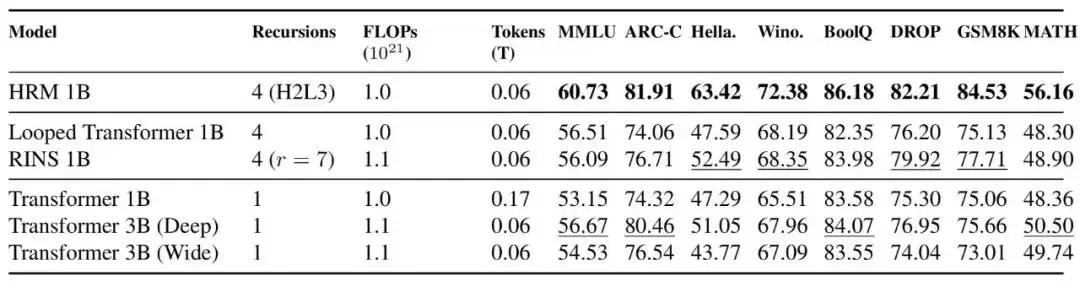
图|与Transformer等模型在性能与训练稳定性上的对比。
2. 新的训练目标,贡献有多大?
消融实验清晰地揭示了每一步改进的价值。以一个1B的Transformer模型为起点,在MMLU基准上:
– 采用标准自回归训练,得分为40.55。
– 引入“只对回答计算损失”的任务完成目标后,得分提升至47.72。
– 再加入PrefixLM掩码机制,得分进一步跃升至53.15。
– 最后,将架构替换为HRM,得分最终达到60.73。
这充分说明,架构革新与目标重塑,两者结合产生了显著的协同效应。
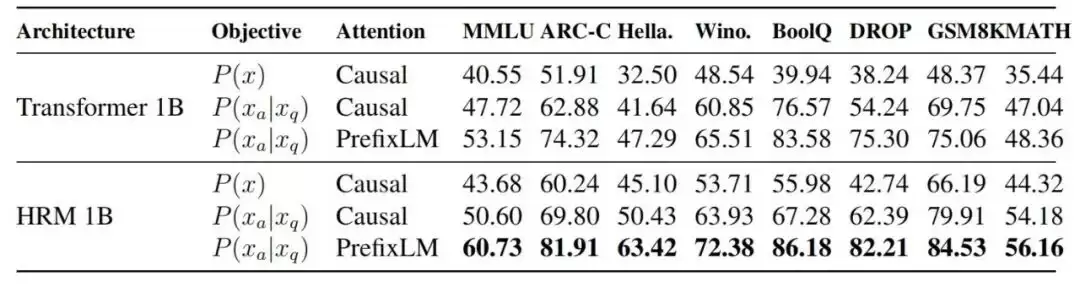
图|不同架构与训练目标组合的性能消融分析。
3. 与开源模型相比,优势在哪?
这才是最硬核的对比。HRM-Text-1B最终在MMLU、ARC-C、DROP、GSM8K、MATH五个核心基准上分别取得了60.7、81.9、82.2、84.5和56.2的成绩。这意味着,仅用400亿唯一token和1B参数,它就成功闯入了需要2B到7B参数、训练数据量往往大得多的开源模型的性能区间。折算下来,其训练所需的token量最多减少了900倍,算力开销最多降低了432倍。效率提升的程度,堪称降维打击。
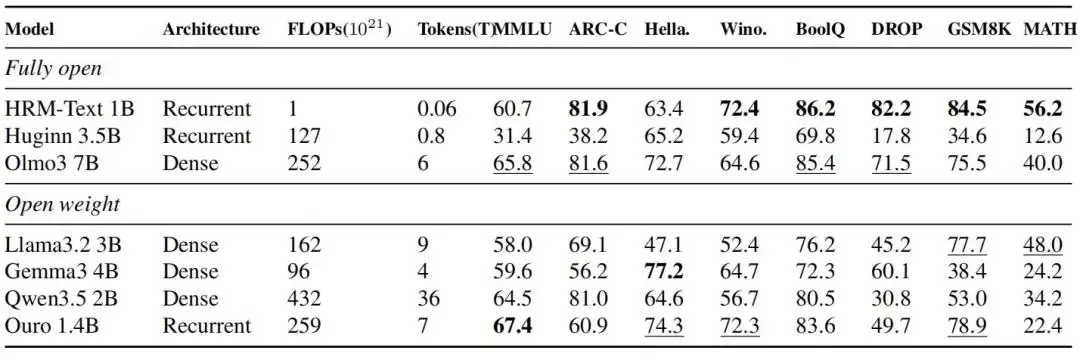
图|HRM-Text 1B 与同期各类开源模型的评测结果对比。
4. 循环结构,真的加深了模型吗?
团队通过分析模型中间层的表示变化来验证“有效深度”。结果显示,标准Transformer和Looped Transformer的层间表示在较浅层就趋于稳定(相似度很高)。而HRM则在更深的递归步骤中,依然保持着更明显的块间表示变化、更低的层间余弦相似度,以及更高的logit lens KL值。这些指标一致表明,HRM的循环机制确实赋予了模型更强大的深层信息处理能力。
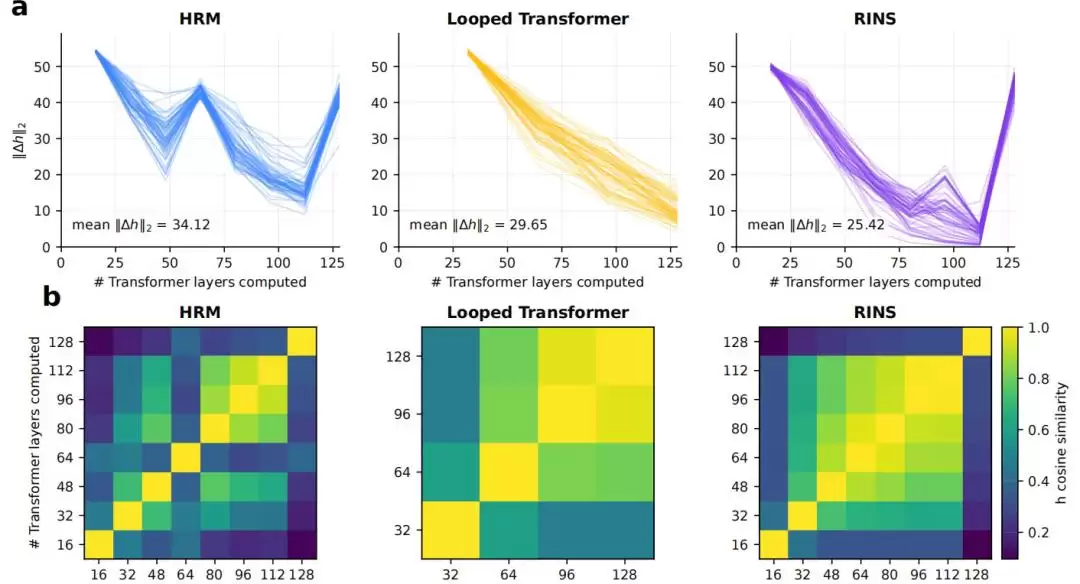
图|有效深度分析,HRM展现出更持续的层间变化。
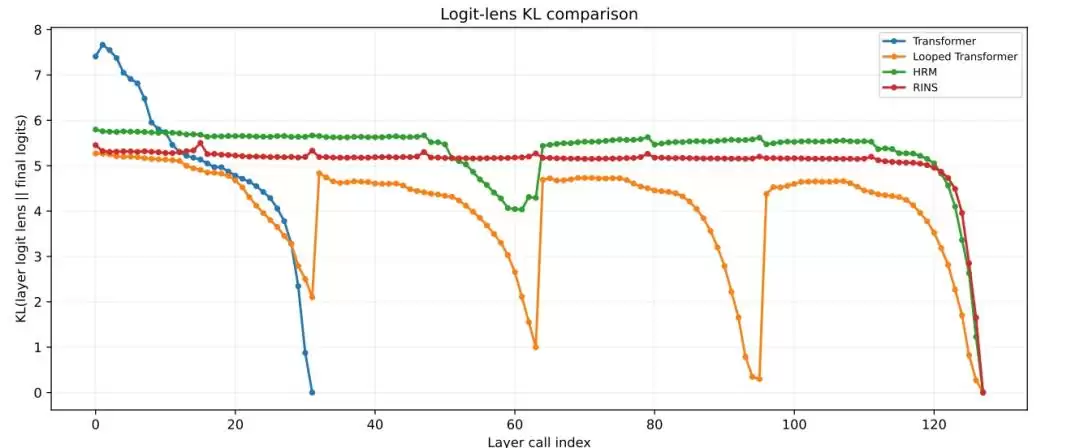
图|逐层 Logit Lens KL 分析,HRM在深层保持更高活性。
不足与未来方向
尽管HRM-Text在推理密集型任务上表现强劲,但研究团队也坦诚地指出了当前方法的局限与未来的探索空间。
1. 走向“知识”与“推理”的解耦
目前,模型更广泛的事实知识覆盖,仍然严重依赖训练数据的规模和广度。HRM-Text仅在400亿token上训练,且显式知识源只占数据混合的一部分。未来的一个关键方向,是设计将紧凑的“推理核心”与外部“知识存储”分离的架构。让知识广度由精选语料库、检索增强模块或可学习的记忆网络来负责,而模型本身则专注于精炼的推理能力。
2. 自适应计算时间
HRM-Text目前采用固定步数的递归计算,这意味着无论问题难易,推理成本都是固定的。一个诱人的改进方向是引入自适应计算时间(Adaptive Computation Time)机制。让模型学会“偷懒”:对简单样本提前停止计算,将宝贵的循环预算留给真正困难的样本,从而在保持性能的同时,进一步降低推理阶段的平均成本。
3. 规模化验证的边界
当前的缩放实验主要对比了最大3B参数的Transformer和1B参数的HRM。在更大参数规模(例如百亿、千亿级)下,HRM是否还能保持如此显著的效率优势?这需要后续更大规模的实验来给出答案。
4. PrefixLM 的工程实践挑战
PrefixLM掩码在提升训练效率的同时,也为实际部署带来了一些工程上的复杂性。虽然它能运行在vLLM等主流推理框架上,但这要求框架在预填充阶段支持自定义注意力掩码。若想将其扩展到多轮对话场景,还需要精心设计KV缓存机制,以确保用户历史片段内部双向可见,同时助手生成过程依然遵循严格的因果约束。
这项研究无疑为高效预训练打开了一扇新的窗户。它提醒我们,在盲目追逐数据与算力规模之前,或许更应该回归模型设计的本质,从结构和目标中挖掘潜力。更多的技术细节,可以在原论文中一探究竟。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

特朗普面临伊朗协议与中期选举双重挑战
特朗普推动美伊协议的努力在共和党内遭遇阻力。鹰派议员担忧停火、制裁松动及资产解冻会让伊朗获得喘息空间,削弱既有军事成果。党内分歧与选举压力交织,使协议成为对党内忠诚与强硬姿态的考验。特朗普需在“美国优先”叙事下说服鹰派接受妥协,这直接关系到协议能否落地及其政。

Sam Altman以算力换股权向169家YC公司发放200万美元Token
在互联网创业时代,云服务商提供的免费服务器额度曾是初创团队最熟悉的“启动羊毛”;如今,随着人工智能浪潮席卷,大模型调用额度(Token)正迅速成为AI创业圈公认的“新硬通货”。 而这一次,在资源扶持上出手最为阔绰的,正是OpenAI的掌门人Sam Altman。 上周,在知名创业孵化器Y Combi

AI智能体从聊天到执行开启全民智能助手新时代
当你说“帮我订一家周末的亲子餐厅”,传统AI或许会给你一份长长的餐厅名单;而智能体,则会像一个真正的私人助理,自动核对档期、比较评价、完成预约,甚至把行程同步到你的日历——整个过程一气呵成,无需你反复操作。 时间来到2026年,AI智能体(Agent)早已不再是实验室里的前沿概念,它正实实在在地渗透

产学研共建AI实验室如何破解工业数据治理难题
工业企业AI应用面临数据割裂与语义理解不足的瓶颈。产学研共建实验室聚焦构建工业本体语义体系和开发智能体数字员工,通过“研究院+技术平台”模式,结合政策与需求,为企业提供从数据治理到场景化应用的落地实践路径。

马斯克宣布Grok V9-Medium 1.5T完成训练 预计两三周内发布
马斯克宣布GrokV9-Medium1 5T模型已完成训练,参数规模较当前版本大幅提升,并加入了大量Cursor代码助手数据以增强编程能力。模型将进入微调与强化学习阶段,预计两到三周后发布,其处理复杂编程任务的表现有望取得重大进步。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
