




英伟达Groq LPU挑战GPU AI推理市场迎来新变局

过去十年间,人工智能技术的迅猛发展始终与GPU算力需求深度绑定。凭借其强大的并行计算能力,GPU几乎成为AI训练与推理的代名词。
然而,行业格局正在悄然改变。在近期举行的GTC大会上,英伟达CEO黄仁勋正式发布了Vera Rubin AI超级计算平台。这一平台的亮相,不仅意味着一款新产品的问世,更标志着英伟达的战略重心已从单一的GPU硬件供应商,全面转向涵盖CPU、GPU及LPU等技术的全栈式“AI工厂”解决方案提供商。这向业界传递出一个明确信号:未来AI算力生态将不再由GPU独家主导。
全栈进化:从“芯片制造商”到“AI工厂”的战略转型
市场趋势清晰地揭示了这一变革的宏观背景。据Statista数据显示,2023年全球GPU市场规模约为436亿美元。然而,随着大模型参数规模呈指数级增长,数据中心对高性能计算的需求呈现爆发态势。预计2024年至2029年间,该市场复合年增长率将高达33.2%,到2029年有望突破2742亿美元。
算力需求的增长速度更为惊人。有分析指出,全球AI算力需求正以“每两年激增750倍”的节奏飞速扩张。在此浪潮下,中国云端AI芯片市场预计在2027年将超过480亿美元,其中国产GPU有望占据超过80%的市场份额。
然而,产业对单一计算架构的过度依赖,也引发了行业内部的深度反思。面对日益突出的能效瓶颈、内存墙限制以及愈发多元化的应用场景,除了GPU之外,是否存在更优的算力解决方案?
英伟达在GTC 2026上给出的答案是Vera Rubin平台。这个AI超级计算机系统,整合了7款芯片、5种机架级计算机以及1台AI超算等丰富组件。
黄仁勋在会后多次强调一个关键转变:“英伟达已不再是一家传统的芯片公司,而是一家全栈式计算公司。”他阐释道,客户需要的并非孤立的芯片,而是能够直接部署投产的完整“AI工厂”。如果缺乏交付整体解决方案的软件与系统能力,仅仅销售硬件将难以持续。正是基于这种“全栈”理念,英伟达推出了备受瞩目的非GPU重磅产品——推理加速机架“英伟达Groq 3 LPX”。
该机架配备了256颗Groq 3 LPU芯片,拥有高达128GB的片上SRAM、315 PFLOPS的计算性能以及640 TB/s的扩展带宽,并可扩展至超过1000张LPU。其设计目标直指大语言模型推理中的核心挑战:延迟优化。
为更直观展示差异,黄仁勋现场对比了Rubin GPU与Groq 3 LPU的关键参数。Rubin GPU堪称“海量存储与高吞吐”的代表,拥有3360亿晶体管、288GB HBM4显存及22 TB/s带宽,在NVFP4精度下算力达50 PFLOPs。而Groq 3 LPU则选择了“极致片上速度”的极简路线,仅集成980亿晶体管与500MB SRAM(容量仅为Rubin的1/500),算力为1.2 PFLOPS。但其制胜关键在于高达150 TB/s的SRAM带宽,使得片内数据传输速度达到Rubin的7倍。

黄仁勋对这一新平台寄予厚望。他预测:“我们正处于英伟达推理拐点的第一年,这是十年来该领域真正意义上的首个拐点。而Vera Rubin将引领拐点的第二年,新增需求的比例同样将达到极高水准。这有些类似当年的iPhone 3,其销量绝大部分源于前所未有的增量市场。”在他看来,Vera Rubin平台有望在十年内将整体计算效能提升4000万倍,从而加速英伟达成为全球最大的“AI算力工厂”。
Groq:补齐推理拼图的关键一环
引入Groq技术,其战略意图并非取代GPU,而是为了完善全栈拼图中至关重要的一块。黄仁勋清晰地阐述了其内在逻辑:一个新兴的细分市场正在形成,它对模型提出了三项极为严苛的要求:模型参数量巨大、支持超长上下文、同时保持极低的推理延迟。单一的Groq LPU只能完美满足其中一项,无法三者兼顾。唯有将Vera Rubin与Groq深度融合,才能同时达成这三项目标。这也是英伟达收购Groq的核心战略考量之一。
全新的Vera Rubin平台通过CPU、GPU与LPU的深度协同,实现了算力质的飞跃。这一架构不仅为长期由GPU主导的复杂计算提供了替代思路,更凭借强大的推理调度能力,重新定义了算力分工的边界——促使不同计算单元各司其职,基于工作负载特性实现精准协同与效能最大化。
LPU的工作原理与GPU存在本质差异。GPU采用SIMD(单指令多数据)架构,而LPU基于顺序指令集计算机架构。这种设计降低了对HBM高频重载的依赖,不仅有效规避了HBM供应链瓶颈带来的成本压力,更显著缓解了“内存墙”的限制。
在能效表现上,LPU通过减少多线程管理开销并避免核心资源闲置,实现了极致的每瓦特算力密度,尤其在推理负载下优势突出。公开数据显示,在Llama 2-70B模型的推理任务中,LPU系统实现了每秒近300个token的吞吐量,相比英伟达H100,性能提升最高可达10倍,单位推理成本降低达80%。
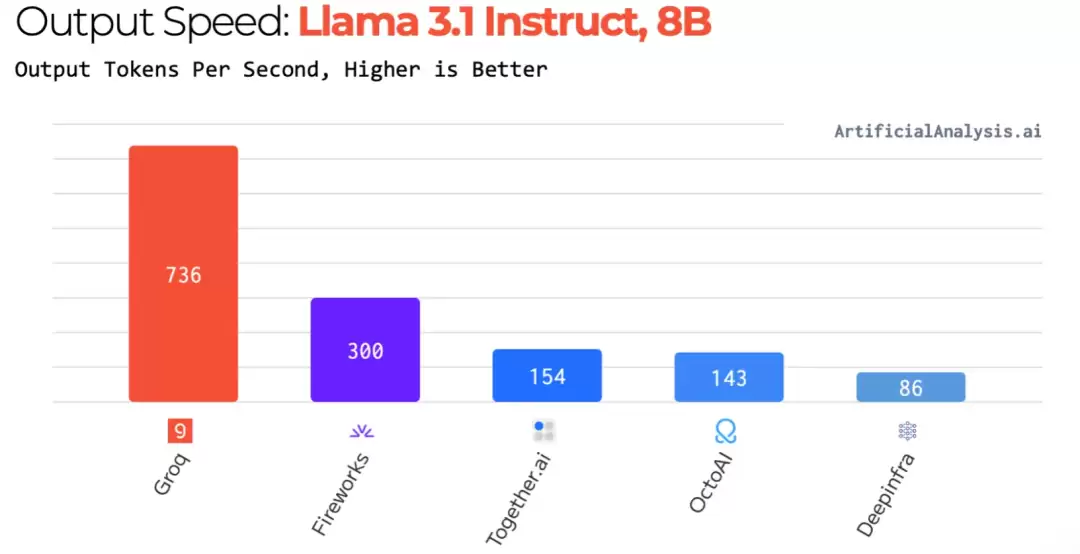
图源:Groq官网
融入英伟达Vera Rubin平台后,该解决方案尤其适用于电力资源紧张的兆瓦级数据中心。在这座“AI工厂”中,GPU负责处理高并发的复杂矩阵运算,而Groq 3 LPU则凭借其独特的确定性低延迟架构,专注于高速的Token生成,在长上下文场景中表现尤为出色。黄仁勋再次强调其核心理念:我们构建的不是一块GPU,而是一座完整的AI算力工厂。
他形象地说明了这种转变:过去十年,超大规模数据中心受“按核计费”的云服务模式驱动,CPU设计追求核心数量最大化。但AI时代的逻辑已然改变,核心指标从“资源存量”转向了“任务吞吐量”。“面对价值500亿美元的GPU集群,绝不允许其因价值10亿美元的CPU处理瓶颈而闲置。此时的核心诉求,是驱动CPU以极致速度完成调度,确保整个GPU集群持续满负荷运转。”他指出。
总结:算力部署的根本性变革
可以预见,未来的AI算力部署将迎来根本性变革,GPU不再是唯一的选择。黄仁勋描绘了他心中的“算力工厂”配置蓝图:在一座标准的算力工厂中,约75%的部署将采用纯Vera Rubin架构;其余25%则会采用“Vera Rubin + Groq”的混合模式。他反复强调,Vera Rubin将是无可撼动的核心基石,其性能之强大,甚至让英伟达自身都难以构想超越路径。
“我们自己都不知道如何超越Vera Rubin,否则我们早就设计出超越它的产品了。”他认为,虽然当前的推理性能王者由Grace Blackwell平台占据,但在不远的将来,Grace Blackwell将功成身退,而Vera Rubin及其后续迭代版本,将加冕为新的“推理算力之王”,登顶性能巅峰。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

杰和科技LM2-100-V0算力模组如何赋能人形机器人突破性能瓶颈
人形机器人面临主控算力不足的瓶颈。杰和科技LM2-100-V0算力模组作为专用协处理器,可提供高达25TOPS的额外算力。它主要卸载视觉感知与复杂运动规划等高负荷计算任务,其小巧集成设计与高能效比有助于机器人保持流畅响应与精准控制,从而提升整体性能。

千问最新版本功能更新与核心能力详解
通义千问系列模型近期全面升级。核心模型强化编程与智能体能力,可自主拆解复杂任务并交付成果。开源版本优化本地部署与长上下文支持。新增TableAgent实现自然语言转Excel文件。AI眼镜结合场景提供主动服务并引入空间3D显示技术,APP则聚焦教育场景,提供智能讲解、解题与批改功能。

沐曦曦云C系列GPU适配腾讯混元Hy3预览版语言模型
腾讯混元发布开源Hy3preview语言模型,沐曦股份曦云C系列GPU同日完成适配。其自研MXMACA软件栈实现高效兼容,大幅缩短模型适配周期。沐曦已快速适配多个顶尖模型,覆盖语言、多模态等全领域,通过软硬协同为国产AI算力生态提供支撑。

2026年5月27日最新科学热点 新浪实时资讯速递
NASA计划今年三次无人登月,推进月球基地建设。一艘邮轮暴发人际传播汉坦病毒,致多人感染。中国科学家发现新型生物标志物,有望实现帕金森病与多系统萎缩的早期精准鉴别。我国冷原子干涉重力测量取得突破,提升国际竞争力。西欧遭遇异常热浪,英国气温两破百年纪录。

德赛西威AI Cube智能基座机器人正式发布
近日,机器人产业迎来一项重要进展:德赛西威正式推出面向机器人领域的AI计算终端——机器人智能基座AI Cube。该产品集成了高性能计算平台、中间件与算法框架,其突出亮点在于,成功将智能汽车领域成熟的车规级冗余技术迁移至机器人平台。凭借这一创新设计,AI Cube在2025高工人形机器人金球奖颁奖典礼








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
