




RK3506开发板光照传感器数据读取教程:AI编程轻松实现

在上一篇文章中,我们介绍了如何在ELF-RK3506开发板上搭建基础的AI编程环境,但当时的测试场景较为简单,生成的代码并未涉及实际的硬件操作。本次,我们将进行一次更为深入的“硬核”挑战:不手动编写任何代码,完全依靠TRAE AI编程工具,生成能够直接读取和控制硬件外设的完整程序。我们以读取GY-30光照传感器数据为例,验证AI在嵌入式开发中的实际应用能力。
明确任务需求文档
一切从一份清晰、无歧义的需求文档开始。我们创建一个名为“功能需求.md”的Markdown文件,详细描述任务目标:
硬件配置:
1. ELF-RK3506开发板
2. GY-30光照传感器模块
3. 杜邦线若干
硬件连接与说明:
ELF-RK3506开发板的I2C2接口已正确连接GY-30传感器模块,传感器I2C地址为0x23。GY-30模块核心为BH1750FVI光照传感器,其详细通信协议可参考数据手册BH1750FVI.pdf。请特别注意手册中关于I2C时序、测量模式及数据转换系数的描述。
具体任务要求:
1. 编写一个运行于Linux控制台的测试程序。该程序需周期性地读取GY-30传感器的原始数据,并同时显示原始十六进制数据(用于调试)和转换后的光照强度值(单位:Lux)。输出格式为“光照: %d lux”,其中%d为计算后的光照值。同时,请根据以下常见场景的光照范围,在输出中增加对应的环境等级判断:
* 室内强光照射:约 1000~3000 lux
* 阴天室外:约 500~1000 lux
* 晴天室外阴影处:约 10000~20000 lux
* 普通办公室照明:约 300~500 lux
2. 在VSCode的tasks.json配置文件中,创建一个名为“Build”的交叉编译任务。使用指定的交叉编译工具链“~/gcc-arm-10.3-2021.07-x86_64-arm-none-linux-gnueabihf/bin/arm-none-linux-gnueabihf-gcc”,编译参数设置为“-o test_gy30 test_gy30.c”,其中test_gy30.c为源文件,test_gy30为生成的可执行文件。
3. 同样在tasks.json中,创建另一个名为“Deploy via SSH”的部署任务。该任务需通过SSH将编译生成的可执行文件拷贝至目标开发板(IP: 192.168.1.123,用户名: root,配置为无密码登录),并修改文件权限为777。此任务应独立执行,不依赖于上述编译任务。请注意JSON格式中可能需要的转义字符处理。本次的提示词(Prompt)比上次复杂许多,主要原因有两个:一是任务本身涉及硬件驱动、数据转换和远程部署,复杂度更高;二是为了引导TRAE生成更精准、可直接使用的代码,减少后续调试工作。
在需求描述中,我们首先明确了硬件连接细节和传感器具体型号,甚至提供了数据手册路径。这一步至关重要,因为不同的大语言模型对GY-30/BH1750的熟悉程度不同,清晰的指引可以避免模型产生“幻觉”,输出错误的I2C地址或忽略原始数据转换为Lux时需要除以1.2的关键系数。
任务1限定了输出格式,便于调试时观察原始数据。任务2是标准的交叉编译任务描述。任务3的部署任务则做了针对性优化:明确指定生成文件为tasks.json,避免歧义;指明该任务不依赖任务2,防止模型错误地建立任务依赖链;同时移除了自动运行程序的要求,因为本次程序为循环输出,若自动运行会导致终端看似“卡住”。
实践表明,提供给AI的任务描述越详尽、逻辑越清晰、边界条件越明确,获得正确、可用结果的概率就越高。
使用TRAE生成代码
接下来开始生成代码。为了确保生成过程的一致性和结果的可复现性,避免TRAE自动切换不同模型导致输出波动,我们手动将模式从“自动”切换为“豆包的Coder模型”。然后,只需将编写好的“功能需求.md”文件拖入TRAE的聊天输入框,并下达执行指令即可。
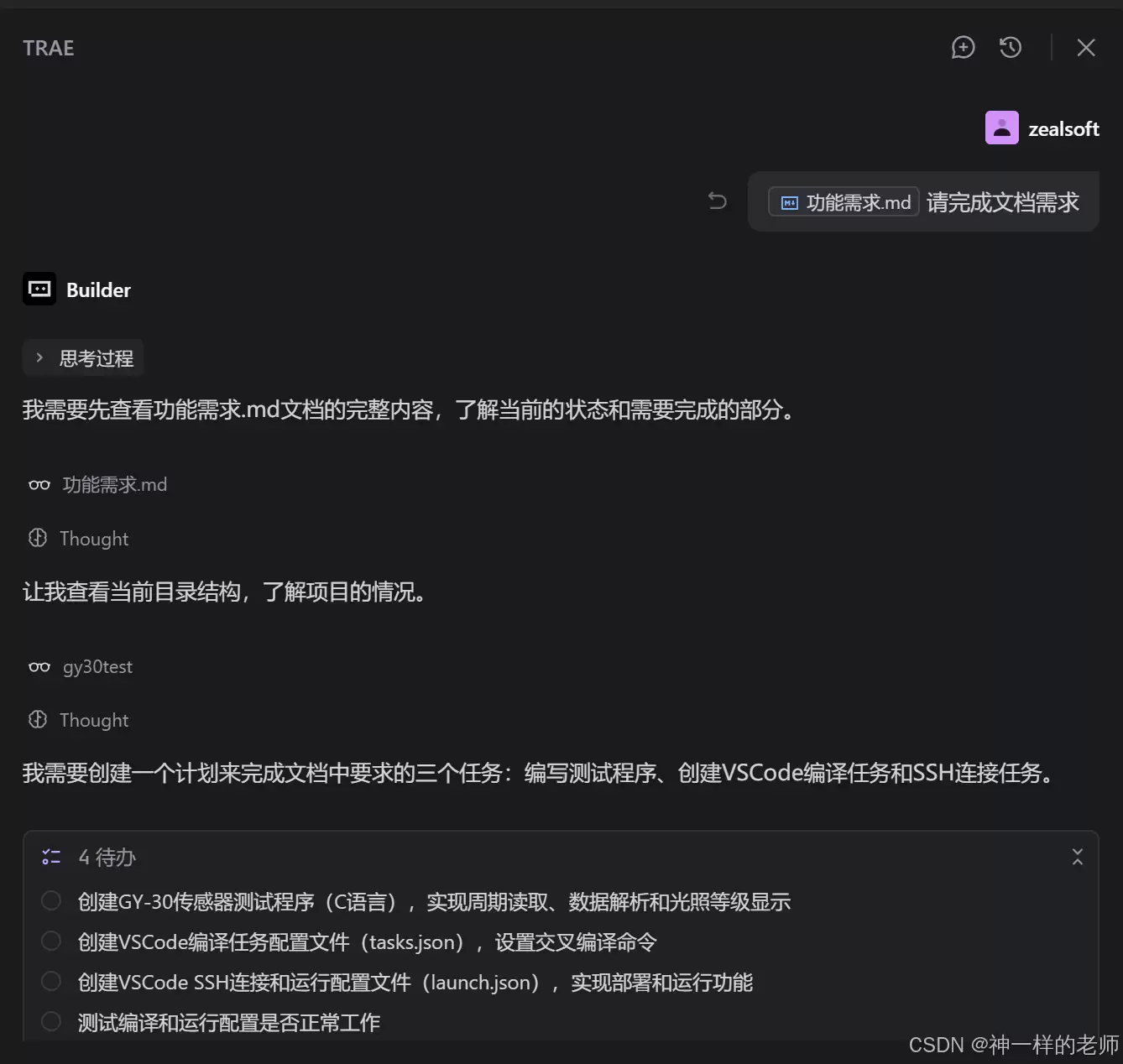
TRAE会自动解析文档内容,拆解任务步骤,并开始执行代码生成。过程中可能会有个别步骤需要人工确认,但整体流程非常迅速,很快便能输出完整的项目文件。
生成的C语言源代码 (test_gy30.c)
以下是TRAE生成的C语言源代码。可以看到,它完整实现了I2C设备打开、从机地址设置、传感器工作模式配置、数据读取、原始数据转换以及带环境等级判断的信息输出,完全符合需求。
#include
#include
#include
#include
#include
#include
#define I2C_DEVICE "/dev/i2c-2"
#define SENSOR_ADDR 0x23
#define CONTINUOUS_HIGH_RES_MODE 0x10
int main() {
int i2c_fd = open(I2C_DEVICE, O_RDWR);
if (i2c_fd < 0) {
perror("无法打开I2C设备");
return 1;
}
if (ioctl(i2c_fd, I2C_SLA VE, SENSOR_ADDR) < 0) {
perror("无法设置I2C从设备地址");
close(i2c_fd);
return 1;
}
unsigned char mode_cmd = CONTINUOUS_HIGH_RES_MODE;
if (write(i2c_fd, &mode_cmd, 1) != 1) {
perror("无法设置传感器模式");
close(i2c_fd);
return 1;
}
usleep(180000);
printf("GY-30传感器测试程序已启动\n");
printf("按Ctrl+C退出\n\n");
while (1) {
unsigned char buf[2];
if (read(i2c_fd, buf, 2) != 2) {
perror("读取传感器数据失败");
break;
}
printf("原始数据: buf[0]=0x%02X, buf[1]=0x%02X\n", buf[0], buf[1]);
int lux = (buf[0] << 8) | buf[1];
lux = (int)(lux / 1.2);
printf("光照: %d lux\n", lux);
if (lux >= 10000 && lux <= 20000) {
printf("光照等级: 晴天室外阴影处\n");
} else if (lux >= 1000 && lux <= 3000) {
printf("光照等级: 室内强光照射\n");
} else if (lux >= 500 && lux <= 1000) {
printf("光照等级: 阴天室外\n");
} else if (lux >= 300 && lux <= 500) {
printf("光照等级: 普通办公室照明\n");
} else if (lux < 300) {
printf("光照等级: 较暗环境\n");
} else {
printf("光照等级: 极强光照\n");
}
printf("\n");
sleep(1);
}
close(i2c_fd);
return 0;
} 生成的VSCode任务配置文件 (tasks.json)
TRAE同时生成了对应的VSCode tasks.json配置文件,其中包含了构建(Build)和部署(Deploy via SSH)两个独立任务。
{
"version": "2.0.0",
"tasks": [
{
"label": "Build",
"type": "shell",
"command": "~/gcc-arm-10.3-2021.07-x86_64-arm-none-linux-gnueabihf/bin/arm-none-linux-gnueabihf-gcc",
"args": [
"-o",
"test_gy30",
"test_gy30.c"
],
"group": {
"kind": "build",
"isDefault": true
},
"problemMatcher": ["$msCompile"]
},
{
"label": "Deploy via SSH",
"type": "shell",
"command": "bash",
"args": [
"-c",
"scp test_gy30 root@192.168.1.123:/root/ && ssh root@192.168.1.123 'chmod 777 /root/test_gy30'"
],
"problemMatcher": [],
"dependsOn": [],
"dependsOrder": "sequence"
}
]
}需要注意的是,在生成的“Deploy via SSH”任务中,虽然我们提示了注意JSON转义字符,但其命令字符串的拼接方式在部分环境下可能仍需调整。不过,这可以通过运行测试时发现的错误,反馈给TRAE进行自动修正,体现了AI编程工具交互式迭代的优势。
实际运行与测试结果
将生成的程序通过交叉编译、部署到ELF-RK3506开发板并运行,下面是一段真实的终端输出截图:
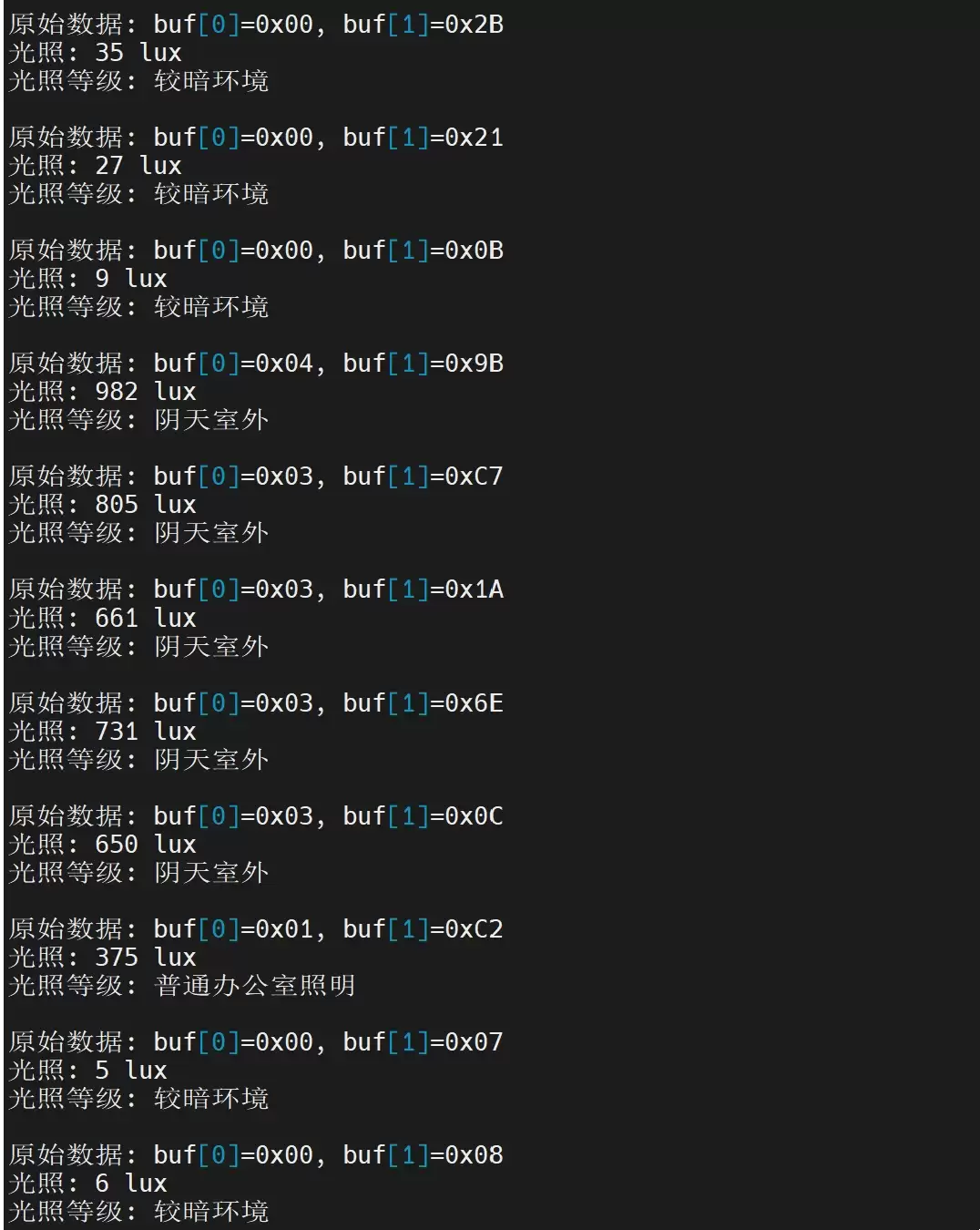
从输出结果可以清晰看到,程序成功运行。它输出了原始的I2C十六进制数据(便于硬件调试),正确计算出了以Lux为单位的光照强度值,并能根据预设的阈值范围准确判断当前的光照环境等级(如“室内强光照射”)。用手遮挡传感器或改变环境光线,输出数值会随之灵敏、准确地变化,充分证明了AI生成的传感器驱动和数据读取逻辑是完全正确且可用的。
总结与展望
本次实践再次强有力地证明,利用AI工具辅助乃至主导嵌入式系统开发,已经是一条非常切实可行的技术路径。尽管嵌入式开发涉及底层硬件、操作系统、外设驱动等多重复杂层面,但只要开发者能够提供清晰、准确、无歧义的需求描述,现代的AI编程工具完全有能力生成高质量、可直接编译运行的代码。这为嵌入式开发者,特别是初学者、教育者以及需要快速进行原型验证和概念验证(PoC)的团队,开辟了一条高效的新途径。我们强烈推荐各位开发者亲自尝试,探索AI在您具体的嵌入式或物联网(IoT)项目中的巨大潜力。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

豆包与腾讯元宝办公场景对比评测
豆包AI在中文文档处理和公式生成方面表现更佳,而腾讯元宝则强于微信生态协同、Excel直连分析和PPT美化。两者均无法本地自动执行任务。选择取决于具体办公需求:文档写作与润色可优先考虑豆包;Excel数据分析与PPT处理更适合元宝;若工作高度依赖微信,则元宝优势明显。自动化需借助第三方工具实现。

ShareGPT团队协作应用指南:AI对话标注与场景讨论实践
ShareGPT通过共享链接和结构化导出功能,支持团队高效协作处理AI对话内容。团队可利用永久链接统一标注基础,避免版本混乱;也可导出JSON或Markdown文件至外部工具进行结构化批注;或通过API对接内部系统实现自动化流程管理。此外,共享链接还能作为异步讨论的稳定锚点,确保讨论聚焦于原始对话。

人工智能需人性引领,中国技术如何塑造未来技能发展
世界技能组织官员麦科马克指出,人工智能影响深远,但需由人类引领并注入人性内核。她在中国体验机器人技术时赞叹其灵敏与趣味,认为这折射出中国技能发展的活力。人工智能将重塑技能需求,而人类的创造力、伦理判断等独特价值愈发重要,未来将呈现人机协同、以人类为主导的新图。

千问长文档摘要功能详解:万字文稿一键总结参数设置指南
面对动辄上万字的长文档,如何快速、精准地提炼核心信息,是职场人士、研究者和学生普遍面临的难题。如果生成的摘要总是遗漏重点、结构松散或篇幅失控,很可能是因为方法不当。本文将详细拆解一套高效、实用的长文档摘要操作流程,帮助你系统性地提升信息提炼能力,让总结工作既高效又专业。 一、设定明确的字数与结构约束

宇树科技应用落地进展如何?官方回应首度披露
宇树科技冲刺科创板,上市申请将于2026年6月1日接受审议。作为“预先审阅”案例,审核效率较高。监管重点关注人形机器人应用落地问题。目前四足机器人在工业巡检等领域相对成熟,正逐步推广;人形机器人在工业与家庭场景的应用多处于早期验证阶段。业内认为,中短期需求主要来自科研与商业。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
