




PDF解析难题解决方案:半年实践总结与高效方法分享

面对PDF文档分析需求,格式解析难题常常成为首要障碍。许多用户尝试将财务报告、学术论文等复杂文档交由AI处理,却因表格结构错乱、数学公式丢失、版式解析失败等问题,导致分析结果与预期严重偏离。
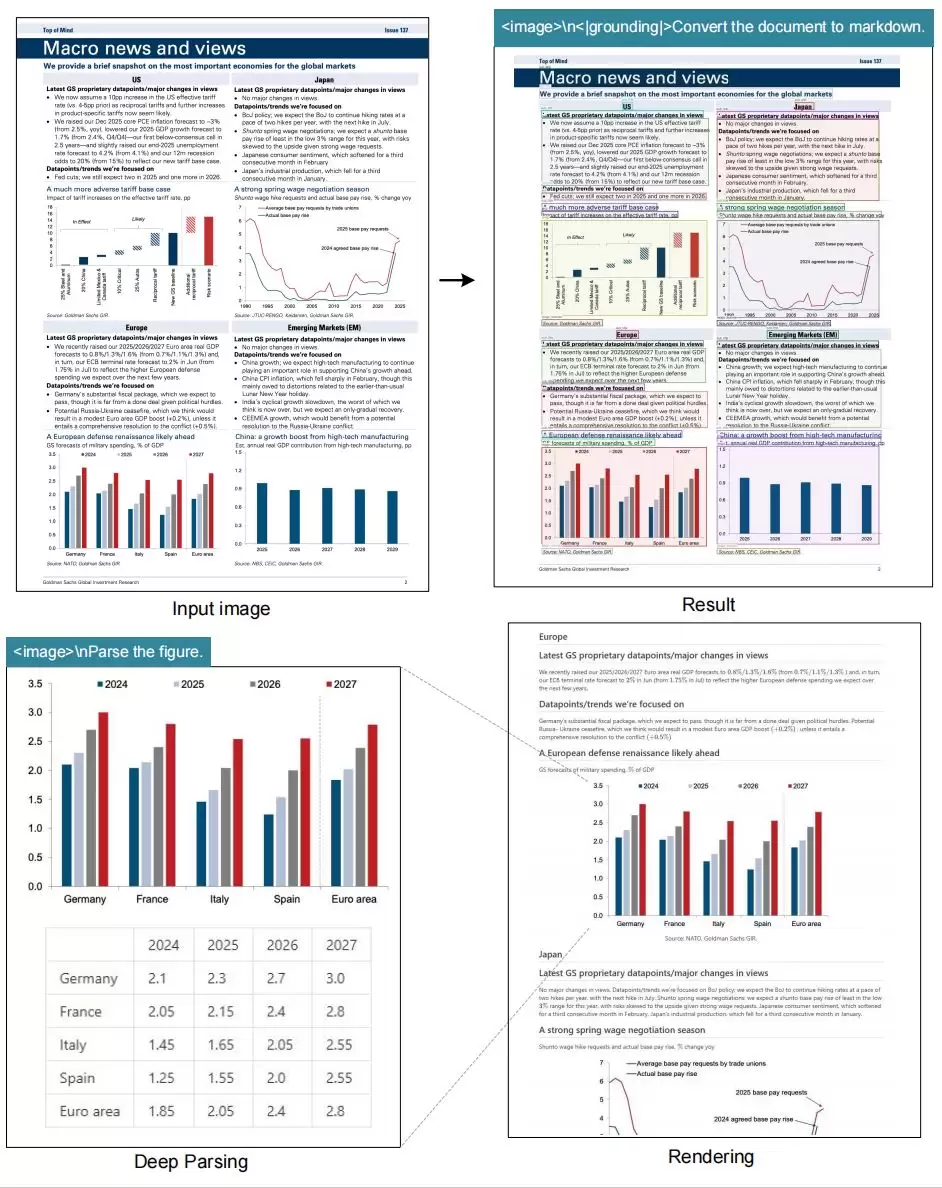
问题的核心通常不在于AI模型的理解能力,而在于文档预处理的第一步——PDF文件未能被准确“解码”。PDF格式固有的复杂性带来了多重挑战:直接复制粘贴对扫描件无效;传统文本提取工具极易破坏原始排版,导致多栏内容粘连、表格数据散乱、公式与插图信息丢失。更重要的是,要实现AI的深度理解,不仅需要提取文字,更需要还原文档的逻辑结构——识别标题层级、区分表格区域、标注注释说明。缺乏这些结构化信息,后续的智能分析便失去了可靠根基。
当前,专注于文档智能解析的多模态OCR模型已不断涌现,如DeepSeek-OCR、PaddleOCR-VL、MinerU等均在特定领域表现出色。然而,各方案宣传优势与实际部署间常存在差距:显存占用、推理速度、格式支持完备性等实际问题,让许多开发者难以抉择。
那么,如何根据实际场景选择最优的PDF解析方案?又如何将其集成为稳定高效的自动化流程?本文将为您系统梳理。
三大OCR方案核心优势与适用场景解析
首先必须明确,不存在适用于所有场景的“万能”解析器,关键在于精准匹配需求。
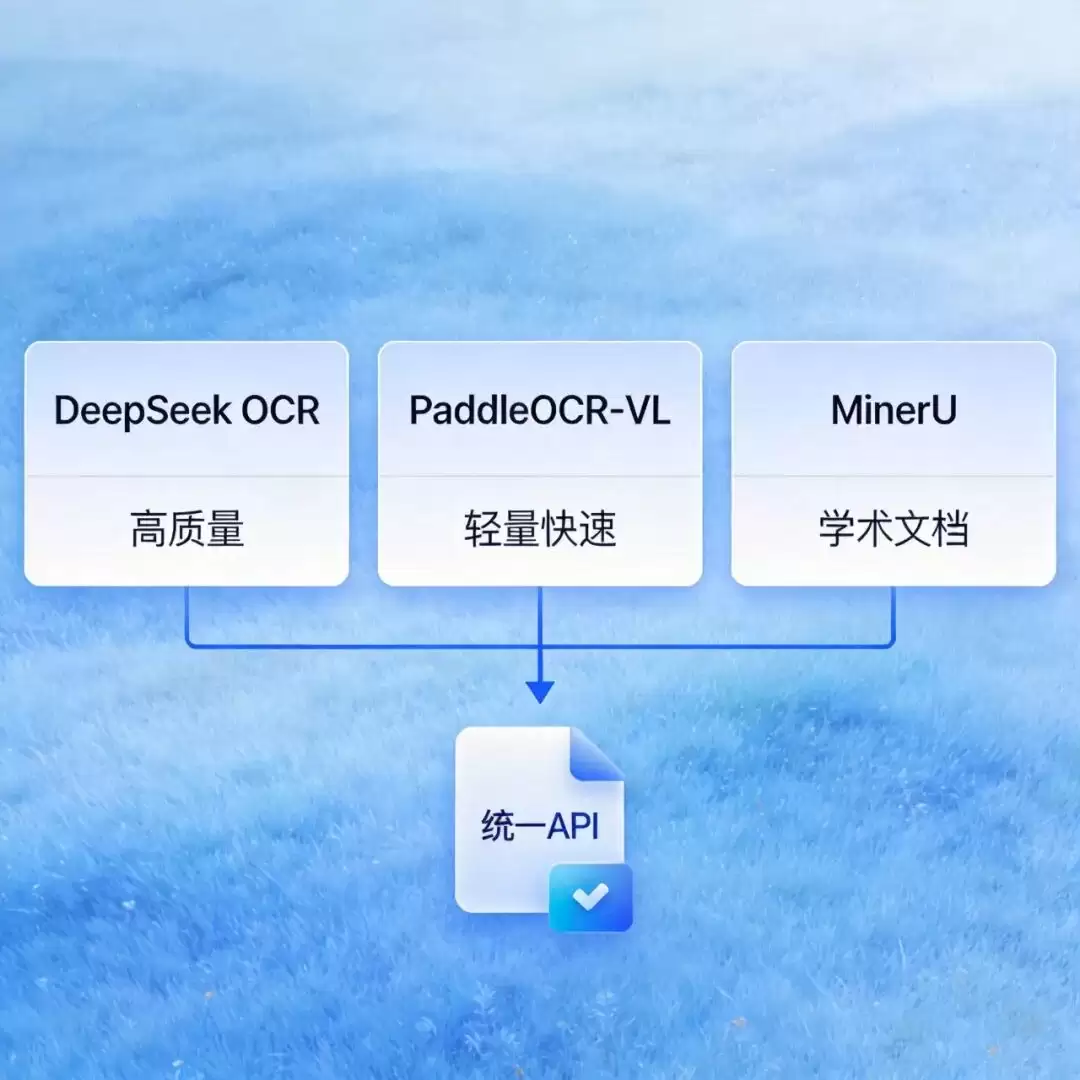
DeepSeek-OCR作为深度求索自研的OCR引擎,其核心优势在于对复杂版式的深度理解能力。它在处理图文混排、嵌套表格、数学公式及特殊符号时表现卓越。因此,对于解析精度要求极高的场景,如法律合同审查、学术文献解析、技术手册处理,该方案是更为可靠的选择。
PaddleOCR-VL源自百度飞桨生态,是一个参数量仅0.9B的轻量级视觉语言模型。虽然模型体积小,但在公开基准测试中成绩突出,支持超过百种语言识别,具有推理速度快、显存占用低的显著特点,单张RTX 3090显卡即可流畅运行。如果您需要处理大批量文档,并优先考虑处理效率与硬件成本,此方案是目前性价比极高的选择。
MinerU则侧重于学术与商业文档的结构化优化,对论文、财报、教科书等格式严谨的文档解析效果优异,输出的结构化文本干净规整。如果您构建RAG知识库或进行文档分析的数据源主要为此类文档,MinerU值得优先考虑。
实际上,这三种方案并非互斥。更高效的策略是依据文档类型进行智能路由,构建一个统一的调度层,让不同模型各司其职。最终对上层应用提供一个标准化的调用接口,使用者无需关心底层技术细节,只需获取高质量的解析结果。
vLLM:提升本地部署推理效率的关键引擎
过去,在本地服务器部署大模型常给人留下部署复杂、推理迟缓的印象,严重影响实际应用体验。
推理速度是决定流程能否投入生产的关键瓶颈。若解析一份PDF需要耗时一分钟以上,则完全无法满足自动化工作流的要求。
vLLM框架正是为解决此痛点而生。作为当前主流的大模型推理加速方案,集成后可带来显著的性能提升,并支持批量文档的并发处理。其另一大优势在于提供标准的OpenAI API兼容接口——这意味着您在本地搭建的这套文档解析服务,可以被任何支持OpenAI协议的应用或框架(如LangChain、LlamaIndex)直接调用,极大降低了集成复杂度。
硬件门槛也较为亲民,一张消费级的RTX 3090显卡已具备部署条件,无需投入昂贵的专业计算设备。
解析输出:构建可用数据层的关键
一套完整的文档解析系统,其输出必须满足下游应用的需求。本方案通常为每份文档生成两种互补的数据格式:
一是可读性强的结构化Markdown。文档中的标题、段落、列表、表格、代码块及图片引用等信息均被准确识别并格式化,生成整洁、可直接输入给大模型进行内容总结、问答或分析的文本。
二是细粒度的结构化JSON数据。每个内容元素(文本块、表格、图片、公式)都被赋予唯一ID、页面坐标边界和类型标签,实现元素级分离。这种格式特别适合接入RAG(检索增强生成)系统,便于实现精准的向量检索、内容定位和来源追溯。
Markdown格式服务于直接的内容理解与交互,JSON格式支撑复杂的检索与分析应用,两者结合足以覆盖绝大多数企业级文档处理场景。
如何无缝集成至现有AI工作流?
解析能力本身并非终点,能否融入现有技术栈才是价值所在。
本方案支持通过MCP(Model Context Protocol)等协议对外提供服务,可轻松与LangChain、AutoGen等主流AI智能体框架集成。这意味着您的AI助手将获得强大的“文档阅读”能力。无论是业务合同、年度审计报告还是产品说明书,上传后即可自动完成解析、信息提取与结构化,随后直接进行智能问答、合规性检查或数据汇总,实现端到端的自动化处理。
文档智能理解在企业中有广泛的应用场景,例如关键信息抽取、自动合规审核、财务报表对比分析等。许多以往依赖人工完成的重复性文档处理工作,在此流程搭建完成后,均可交由AI高效、准确地完成。
总结与实施展望
客观而言,PDF解析在单一技术点上已相对成熟,但将多种优势方案有机整合、打通端到端生产流程的实践指南,目前仍较为缺乏。
一个经过验证的稳健组合策略是:采用DeepSeek-OCR保障高难度文档的解析质量,利用PaddleOCR-VL应对海量文档的批处理吞吐需求,选用MinerU优化学术及财报类文档的结构化输出,再通过vLLM进行统一的推理加速,最终通过标准化API对外提供稳定服务。
硬件方面,一张RTX 3090显卡可作为可行的起步配置,这已是被多项实践验证过的方案。
如果您正在构建企业级RAG知识库、设计智能文档处理流水线,或希望为您的AI应用赋予深度理解PDF文件的能力,那么这套整合方案提供了明确的技术路径,值得深入评估与实施。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

豆包与腾讯元宝办公场景对比评测
豆包AI在中文文档处理和公式生成方面表现更佳,而腾讯元宝则强于微信生态协同、Excel直连分析和PPT美化。两者均无法本地自动执行任务。选择取决于具体办公需求:文档写作与润色可优先考虑豆包;Excel数据分析与PPT处理更适合元宝;若工作高度依赖微信,则元宝优势明显。自动化需借助第三方工具实现。

ShareGPT团队协作应用指南:AI对话标注与场景讨论实践
ShareGPT通过共享链接和结构化导出功能,支持团队高效协作处理AI对话内容。团队可利用永久链接统一标注基础,避免版本混乱;也可导出JSON或Markdown文件至外部工具进行结构化批注;或通过API对接内部系统实现自动化流程管理。此外,共享链接还能作为异步讨论的稳定锚点,确保讨论聚焦于原始对话。

人工智能需人性引领,中国技术如何塑造未来技能发展
世界技能组织官员麦科马克指出,人工智能影响深远,但需由人类引领并注入人性内核。她在中国体验机器人技术时赞叹其灵敏与趣味,认为这折射出中国技能发展的活力。人工智能将重塑技能需求,而人类的创造力、伦理判断等独特价值愈发重要,未来将呈现人机协同、以人类为主导的新图。

千问长文档摘要功能详解:万字文稿一键总结参数设置指南
面对动辄上万字的长文档,如何快速、精准地提炼核心信息,是职场人士、研究者和学生普遍面临的难题。如果生成的摘要总是遗漏重点、结构松散或篇幅失控,很可能是因为方法不当。本文将详细拆解一套高效、实用的长文档摘要操作流程,帮助你系统性地提升信息提炼能力,让总结工作既高效又专业。 一、设定明确的字数与结构约束

宇树科技应用落地进展如何?官方回应首度披露
宇树科技冲刺科创板,上市申请将于2026年6月1日接受审议。作为“预先审阅”案例,审核效率较高。监管重点关注人形机器人应用落地问题。目前四足机器人在工业巡检等领域相对成熟,正逐步推广;人形机器人在工业与家庭场景的应用多处于早期验证阶段。业内认为,中短期需求主要来自科研与商业。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
