




PPO算法详解 图解近端策略优化原理与计算步骤

在强化学习领域,如果要评选一款“通用型”算法,PPO(近端策略优化)无疑是首选。它之所以能广泛应用于游戏AI、机器人控制乃至大语言模型对齐任务,关键在于其卓越的稳定性——易于实现、训练过程可靠,并能同时处理离散与连续动作空间。
简而言之,PPO属于策略梯度算法系列,但它引入了一个关键约束:严格限制新旧策略之间的更新幅度。这种设计既保证了策略性能的稳步提升,又避免了因更新过大导致的训练振荡或策略崩溃。此外,PPO支持样本复用,显著提升了数据利用效率。

PPO 算法的网络结构
PPO的核心架构通常由两个神经网络组成,它们各司其职,协同完成学习任务。
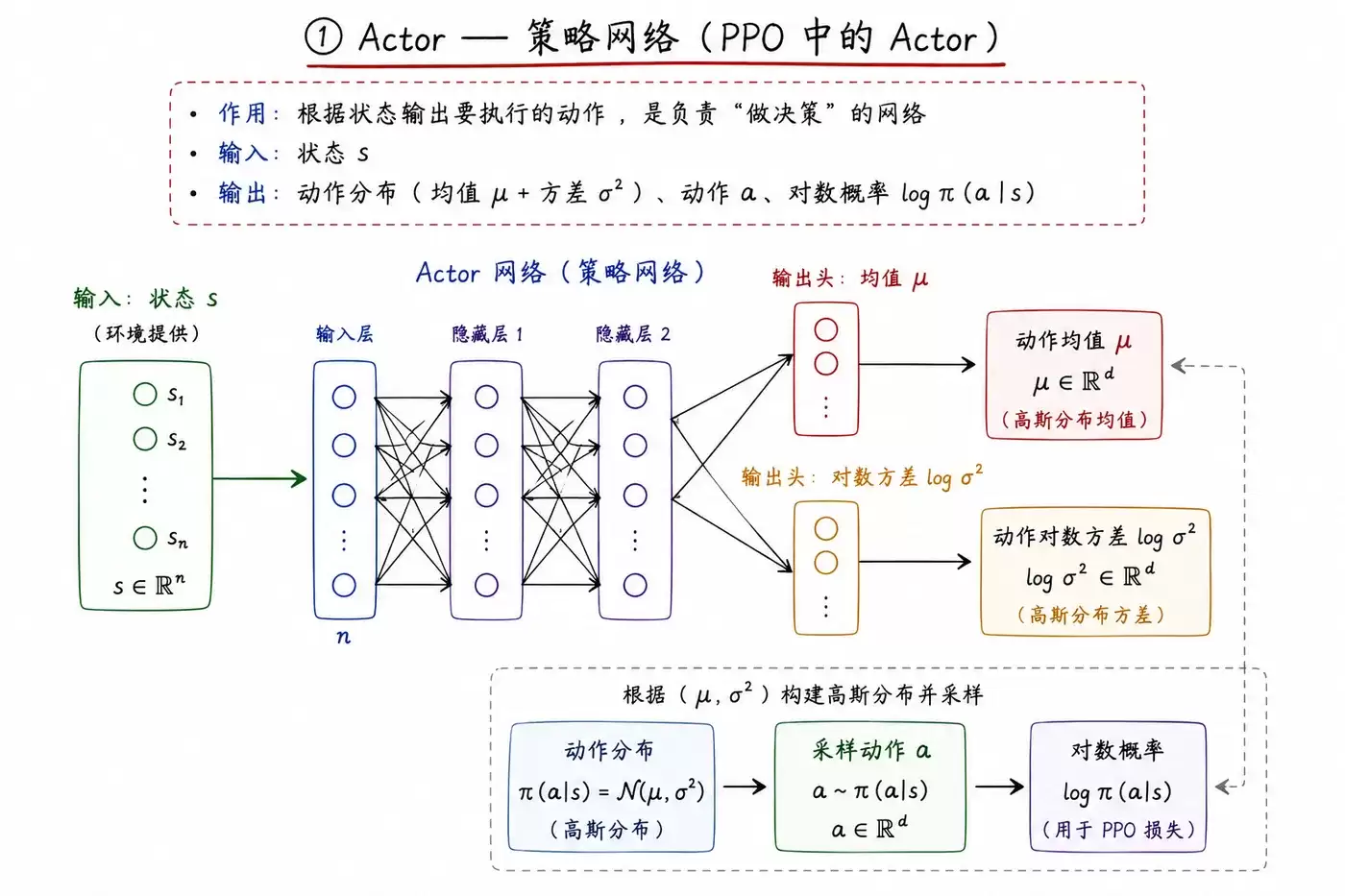
① Actor —— 策略网络
你可以将Actor网络视为系统的“决策中枢”。
- 输入: 当前的环境状态(State s)。
- 输出: 动作的概率分布(对于连续动作,输出均值和方差)、最终执行的动作a,以及该动作的对数概率 log π(a|s)。
- 核心作用: 根据当前感知的状态,决定智能体应采取的具体行为。它负责“执行”。
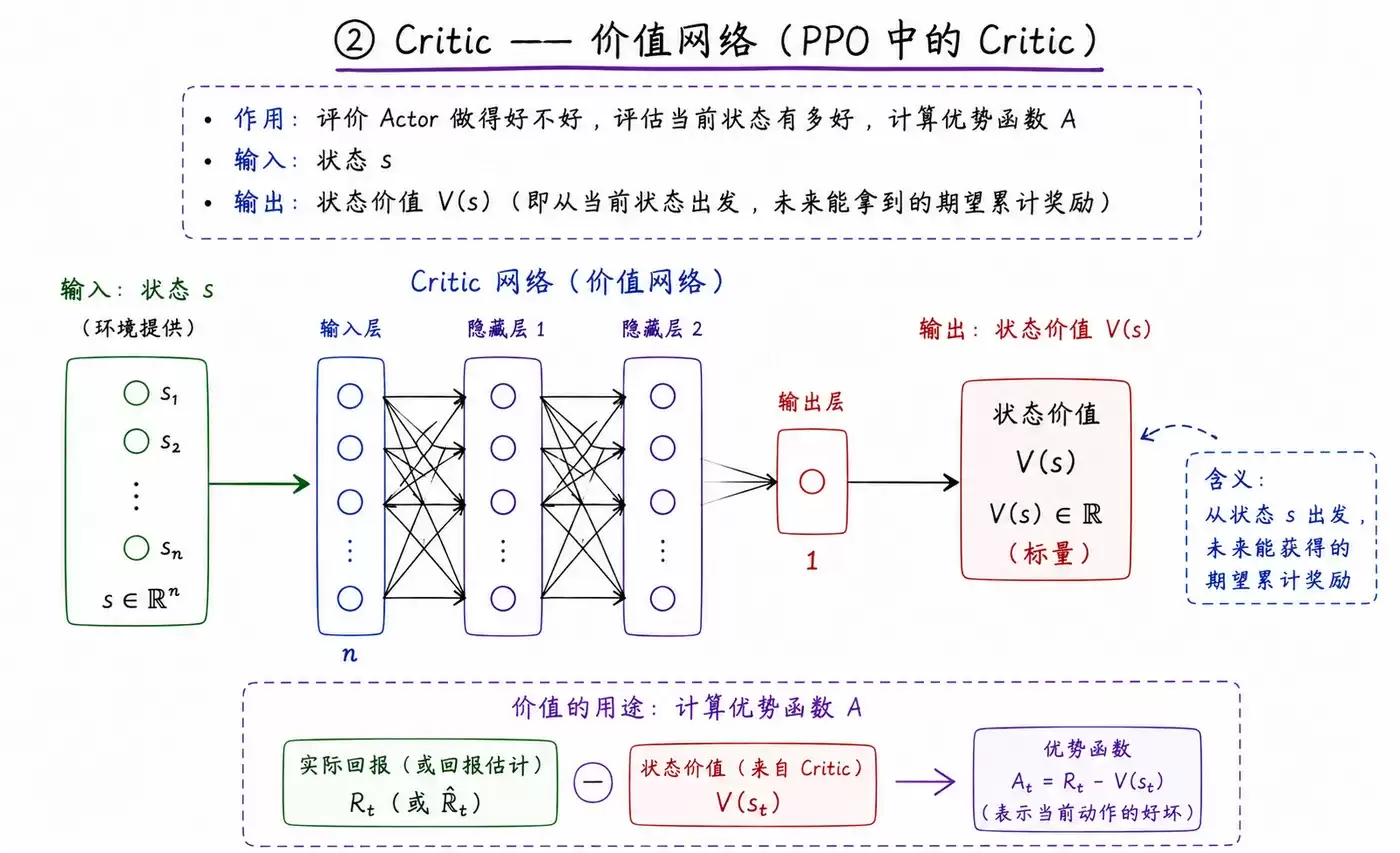
② Critic —— 价值网络
而Critic网络,则扮演着“评估专家”的角色。
- 输入: 同样是状态 s。
- 输出: 当前状态的价值估计 V(s)。这个数值评估了处于该状态的长期收益预期,即未来可能获得的累积奖励。
- 核心作用: 评估Actor决策的优劣,并计算出关键的“优势函数”(Advantage),用以指示特定动作相对于平均表现的优势或劣势程度。
网络更新
训练过程是这两个网络持续优化的循环。PPO遵循一个重要原则:采样时使用旧策略执行动作,网络更新时则用新策略计算旧动作的概率。新策略生成的动作需等到下一轮数据采集时才会被执行,这确保了训练数据的一致性。
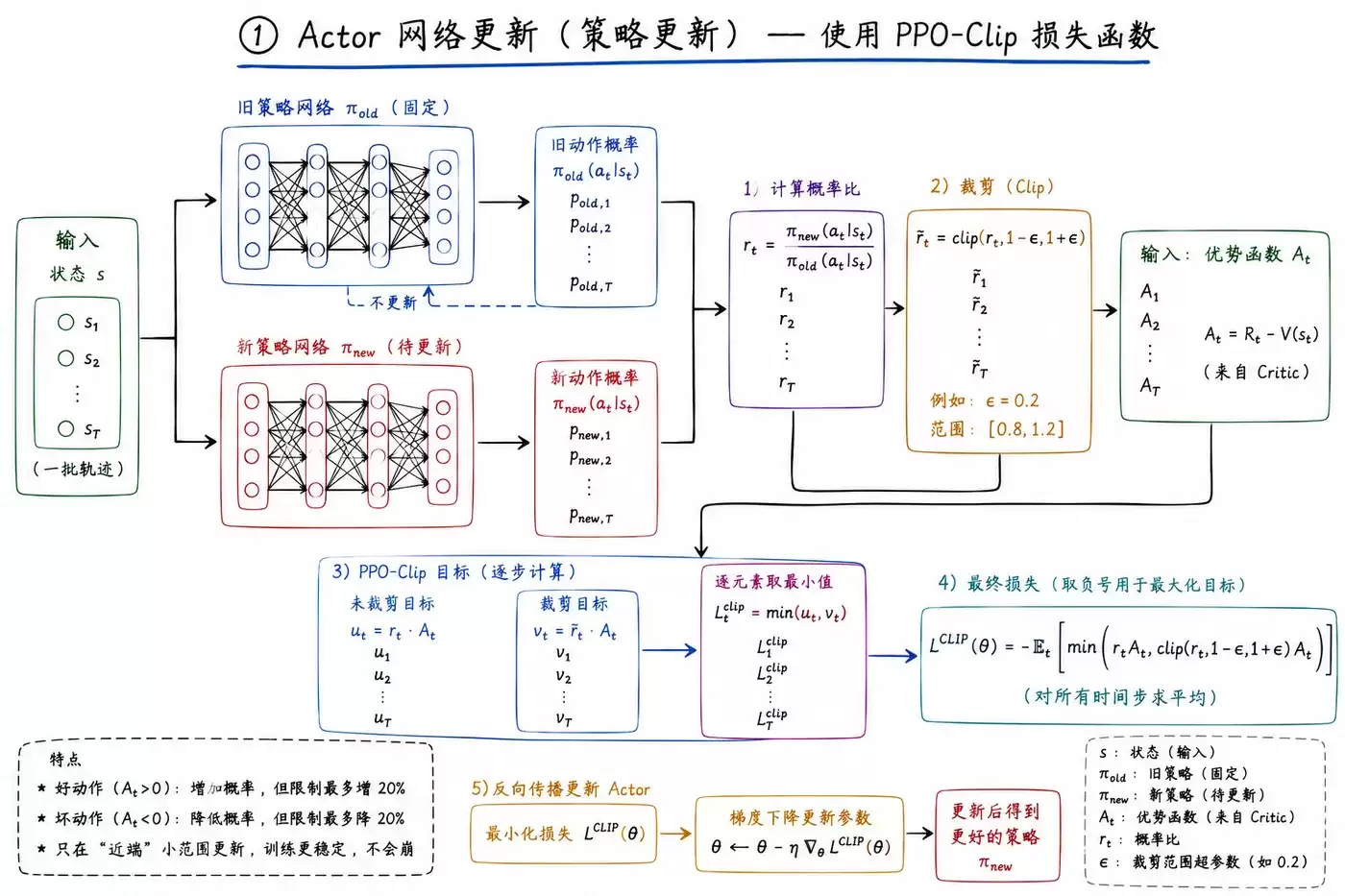
① Actor 网络更新(策略更新)
Actor的更新是PPO算法的核心,其目标是:增加高回报动作的概率,降低低回报动作的概率,同时将所有更新约束在一个安全的阈值内。
- 使用损失函数: PPO-Clip。
- 输入要素: 状态s、旧策略下动作的概率(π_old)、新策略下同一动作的概率(π_new)、以及Critic网络提供的优势函数A。
- 计算步骤:
- 计算新旧策略的概率比率 r = π_new / π_old。
- 将该比率r裁剪(clip)到预设的区间内,例如 [1-ε, 1+ε],当ε=0.2时,区间为[0.8, 1.2]。
- 计算最终损失:取 min( r * A, clip(r) * A )。这一步有效防止了因优势估计异常而导致的更新幅度失控。
- 通过反向传播算法更新Actor网络参数。
- 核心特点: 更新被限制在“近端”的小范围内,训练过程极其稳定,从根本上解决了传统策略梯度方法中常见的策略“崩溃”问题。
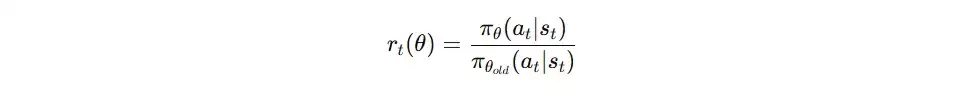
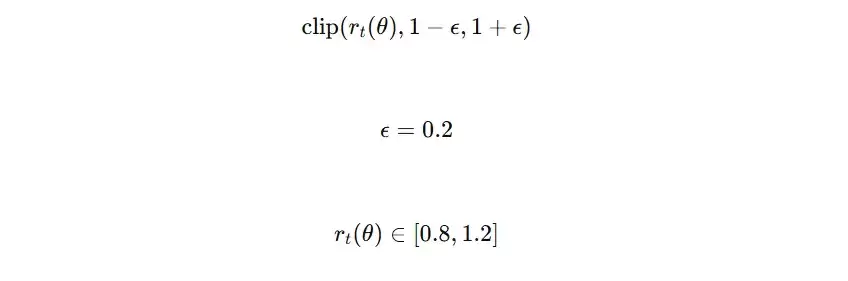
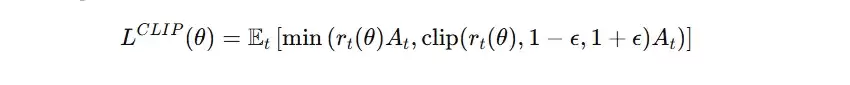
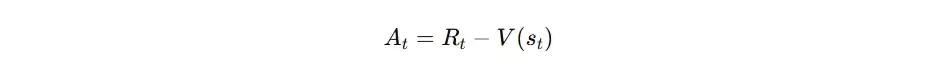
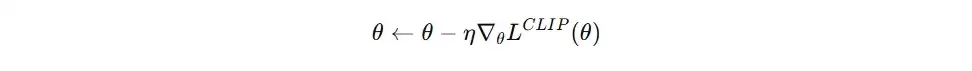
② Critic 网络更新(价值评估更新)
Critic网络的更新相对直接,目标是使其对状态价值的预测越来越精准。
- 使用损失函数: 均方误差(MSE)。
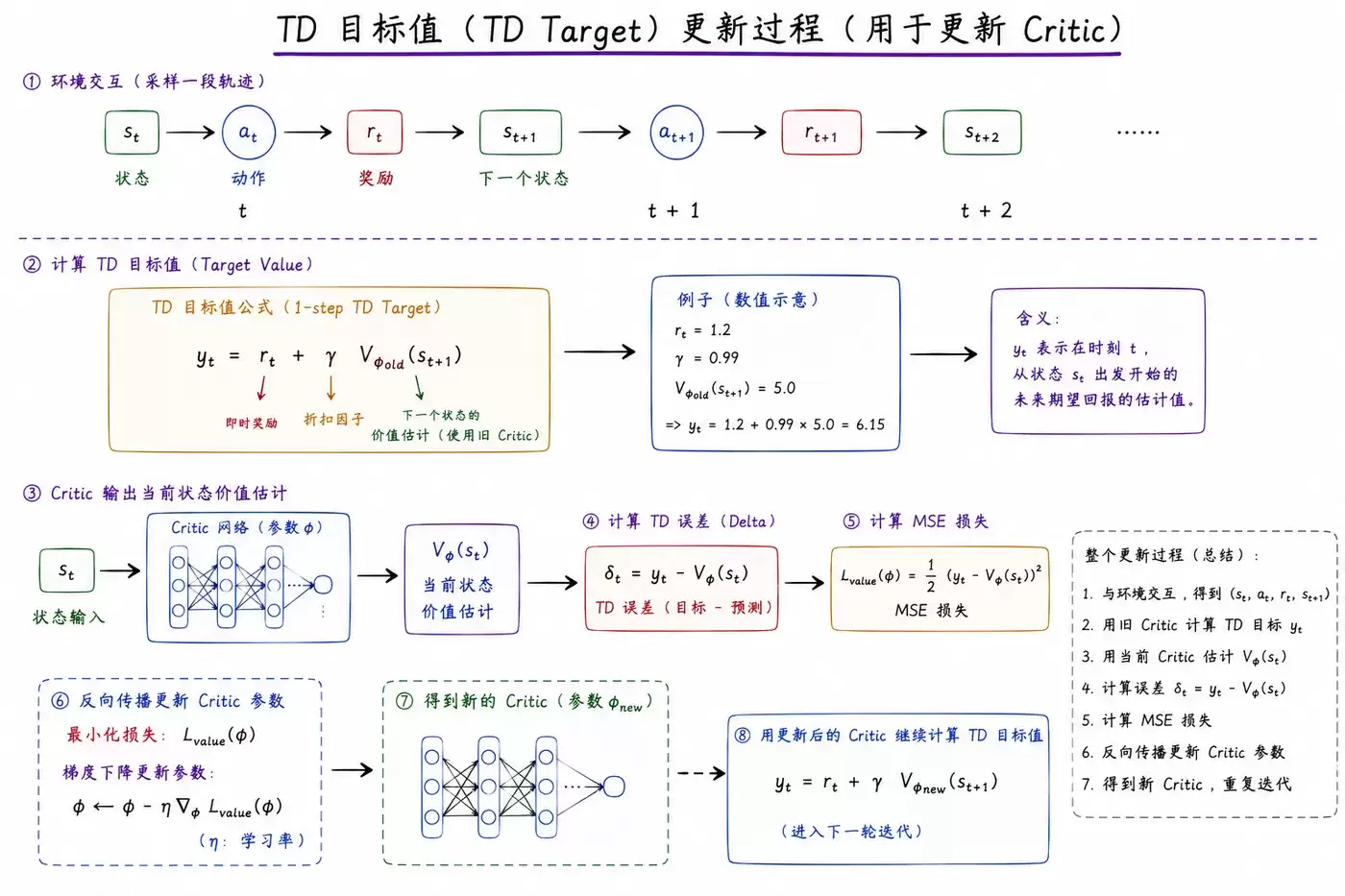
- 输入要素: 状态s,以及实际回报G或时序差分(TD)目标值。
- 计算过程: Critic网络输出对当前状态的估值V(s),计算该估值与目标回报之间的误差,然后使用MSE损失进行反向传播,从而更新Critic网络参数。
- 核心作用: 通过提供更准确的优势信号,来更有效地指导Actor网络的策略优化方向。
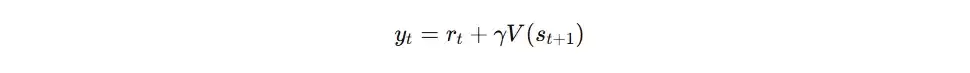
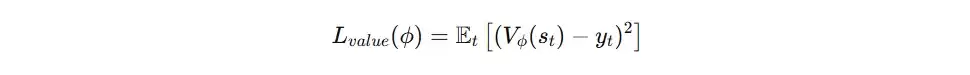
手动计算
要深入理解PPO算法,动手计算是关键。我们聚焦于两个核心环节:广义优势估计(GAE)和模型更新过程。
广义优势估计
优势函数A用于衡量特定动作相对于策略平均表现的优劣。GAE是一种高效的方法,它通过融合多步时序差分(TD)误差,得到更平滑、方差更低的优势估计值。
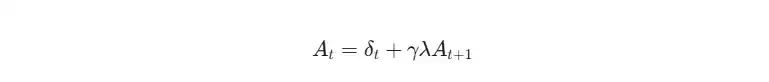
TD误差(td_delta)是计算基础:
td_delta = 即时奖励 + 折扣因子×下一个状态价值 - 当前状态价值GAE优势(advantage)通过递归方式计算:
advantage = 当前TD误差 + 衰减系数 × 下一步的advantage举例说明,假设我们有三步的TD误差序列:`[10, 5, -10]`,设定衰减系数(γ * λ)为0.81。我们从最后一步开始向前递推计算:
t=2: advantage = -10 + 0.81×0 = -10
t=1: advantage = 5 + 0.81×(-10) = -3.1
t=0: advantage = 10 + 0.81×(-3.1) = 7.489
最终得到的GAE优势序列为:[7.489, -3.1, -10]模型更新(update)
下面我们模拟一个简化的更新流程。假设参数设置如下:折扣因子γ=0.9,GAE参数λ=0.9,裁剪范围ε=0.2(对应区间[0.8, 1.2])。
我们拥有两条样本数据:
state0 = [1.0, 0.0, 1.0, 0.0, 0.0, 0.0], action0 = 0
state1 = [0.9, 0.1, 0.8, 0.2, 0.5, 0.1], action1 = 2
对应的优势函数值为:advantage = [-0.82, -2.0]1. 计算新旧概率比(ratio)
首先,需要获取旧策略和新策略分别产生这些动作的概率。假设通过模型前向传播得到对数概率:
旧策略:old_log_prob0 ≈ -0.357, old_log_prob1 ≈ -2.303
新策略:new_log_prob0 ≈ -0.094, new_log_prob1 ≈ -3.000计算概率比(通过对数概率差取指数得到):
ratio0 = exp( (-0.094) - (-0.357) ) = exp(0.263) ≈ 1.30
ratio1 = exp( (-3.000) - (-2.303) ) = exp(-0.697) ≈ 0.50可见,ratio0=1.30超出了裁剪上限1.2,ratio1=0.50则低于裁剪下限0.8。
2. 计算PPO Clip策略损失(policy_loss)
针对第一条样本(ratio0=1.30, adv0=-0.82):
未裁剪部分:1.30 * (-0.82) = -1.066
裁剪后部分:clip(1.30→1.2) * (-0.82) = -0.984
取两者中较小的:min(-1.066, -0.984) = -1.066针对第二条样本(ratio1=0.50, adv1=-2.0):
未裁剪部分:0.50 * (-2.0) = -1.0
裁剪后部分:clip(0.50→0.8) * (-2.0) = -1.6
取两者中较小的:min(-1.0, -1.6) = -1.6策略损失是这些值的负平均值(因为优化器通常以最小化损失为目标):
policy_loss = - [ (-1.066) + (-1.6) ] / 2 = - [ -2.666 / 2 ] = 1.3333. 计算价值损失(value_loss)
假设Critic网络对两个状态的估值为:V(s0) = -3.18, V(s1) = 0.0。目标回报(TD目标)假设为:td_target0 = -1.0, td_target1 = 0.0。
使用均方误差计算价值损失:
loss0 = (-3.18 - (-1.0))^2 = (-2.18)^2 = 4.75
loss1 = (0.0 - 0.0)^2 = 0
value_loss = (4.75 + 0) / 2 = 2.375手算最终结果
ratio0 = 1.30, ratio1 = 0.50
policy_loss = 1.333
value_loss = 2.375
通过这样一个从理论推导到手动计算的全过程,PPO如何通过裁剪机制实现稳定更新,以及Actor和Critic网络如何协同优化,便一目了然。这正是PPO算法能够成为工业级强化学习首选方案的深层原因。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

豆包与腾讯元宝办公场景对比评测
豆包AI在中文文档处理和公式生成方面表现更佳,而腾讯元宝则强于微信生态协同、Excel直连分析和PPT美化。两者均无法本地自动执行任务。选择取决于具体办公需求:文档写作与润色可优先考虑豆包;Excel数据分析与PPT处理更适合元宝;若工作高度依赖微信,则元宝优势明显。自动化需借助第三方工具实现。

ShareGPT团队协作应用指南:AI对话标注与场景讨论实践
ShareGPT通过共享链接和结构化导出功能,支持团队高效协作处理AI对话内容。团队可利用永久链接统一标注基础,避免版本混乱;也可导出JSON或Markdown文件至外部工具进行结构化批注;或通过API对接内部系统实现自动化流程管理。此外,共享链接还能作为异步讨论的稳定锚点,确保讨论聚焦于原始对话。

人工智能需人性引领,中国技术如何塑造未来技能发展
世界技能组织官员麦科马克指出,人工智能影响深远,但需由人类引领并注入人性内核。她在中国体验机器人技术时赞叹其灵敏与趣味,认为这折射出中国技能发展的活力。人工智能将重塑技能需求,而人类的创造力、伦理判断等独特价值愈发重要,未来将呈现人机协同、以人类为主导的新图。

千问长文档摘要功能详解:万字文稿一键总结参数设置指南
面对动辄上万字的长文档,如何快速、精准地提炼核心信息,是职场人士、研究者和学生普遍面临的难题。如果生成的摘要总是遗漏重点、结构松散或篇幅失控,很可能是因为方法不当。本文将详细拆解一套高效、实用的长文档摘要操作流程,帮助你系统性地提升信息提炼能力,让总结工作既高效又专业。 一、设定明确的字数与结构约束

宇树科技应用落地进展如何?官方回应首度披露
宇树科技冲刺科创板,上市申请将于2026年6月1日接受审议。作为“预先审阅”案例,审核效率较高。监管重点关注人形机器人应用落地问题。目前四足机器人在工业巡检等领域相对成熟,正逐步推广;人形机器人在工业与家庭场景的应用多处于早期验证阶段。业内认为,中短期需求主要来自科研与商业。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
