




NVIDIA CompileIQ 自动调优指南 深度挖掘内核性能潜力

在性能工程实践中,开发者常面临一个核心挑战:如何为特定计算负载找到能释放极致性能的编译器优化选项?传统优化手段,如调整批处理大小、应用量化技术(包括FP8)、集成Flash Attention或实施内核融合,往往在达到某个瓶颈后便难以突破。当性能分析工具显示常规优化已无显著空间时,团队的优化工作似乎陷入了停滞。
然而,如果编译器本身也能成为一个可深度调优的参数呢?如今,这一设想已成为现实。随着NVIDIA CUDA 13.3的发布,CompileIQ这一由AI驱动的编译器自动调优框架正式亮相。它运用进化算法与遗传算法,为单个工作负载智能优化NVIDIA通用GPU编译器(NVCC/PTXAS)的代码生成策略。
问题的本质在于,NVIDIA GPU编译器对所有计算内核都应用一套统一的默认启发式规则——涵盖寄存器分配、指令调度、循环展开阈值等关键决策。这套规则旨在为海量多样化工作负载提供“普遍适用”的良好性能。但“普遍良好”与“为你的特定负载量身定制的最优解”之间,往往存在显著的性能差距。
在当今AI基础设施性能竞争白热化的环境下,这微小的差距已变得至关重要。开发定制CUDA内核、Triton内核或Helion内核的团队,正在为每一个百分点的吞吐量提升而全力以赴。在此之前,针对特定工作负载深入微调编译器底层的代码生成过程,几乎是一项不可能完成的任务。
90%的性能瓶颈与隐藏的优化机遇
要理解编译器级优化为何具有战略意义,首先需要洞察现代大语言模型(LLM)推理中GPU计算资源的真实分布。
在注意力推理内核中,前馈网络(FFN/MLP)块中的线性层(GEMM运算),加上查询(Q)、键(K)、值(V)及输出投影层的计算,合计消耗约70%的浮点运算资源。缩放点积注意力及其融合变体(如Flash Attention)则占据另外约25%的计算量。这两大类核心内核,共同构成了端到端推理超过90%的计算开销。
这种“计算热点”高度集中的现象并非AI推理独有。在众多高性能计算(HPC)和科学计算应用中,大部分执行时间都集中在少数关键代码段上。这意味着,对这些“热点”内核进行哪怕微小的性能提升——例如零点几个百分点——也能为整个应用程序带来可观的端到端加速效果。
CompileIQ:将编译器转化为性能调优杠杆
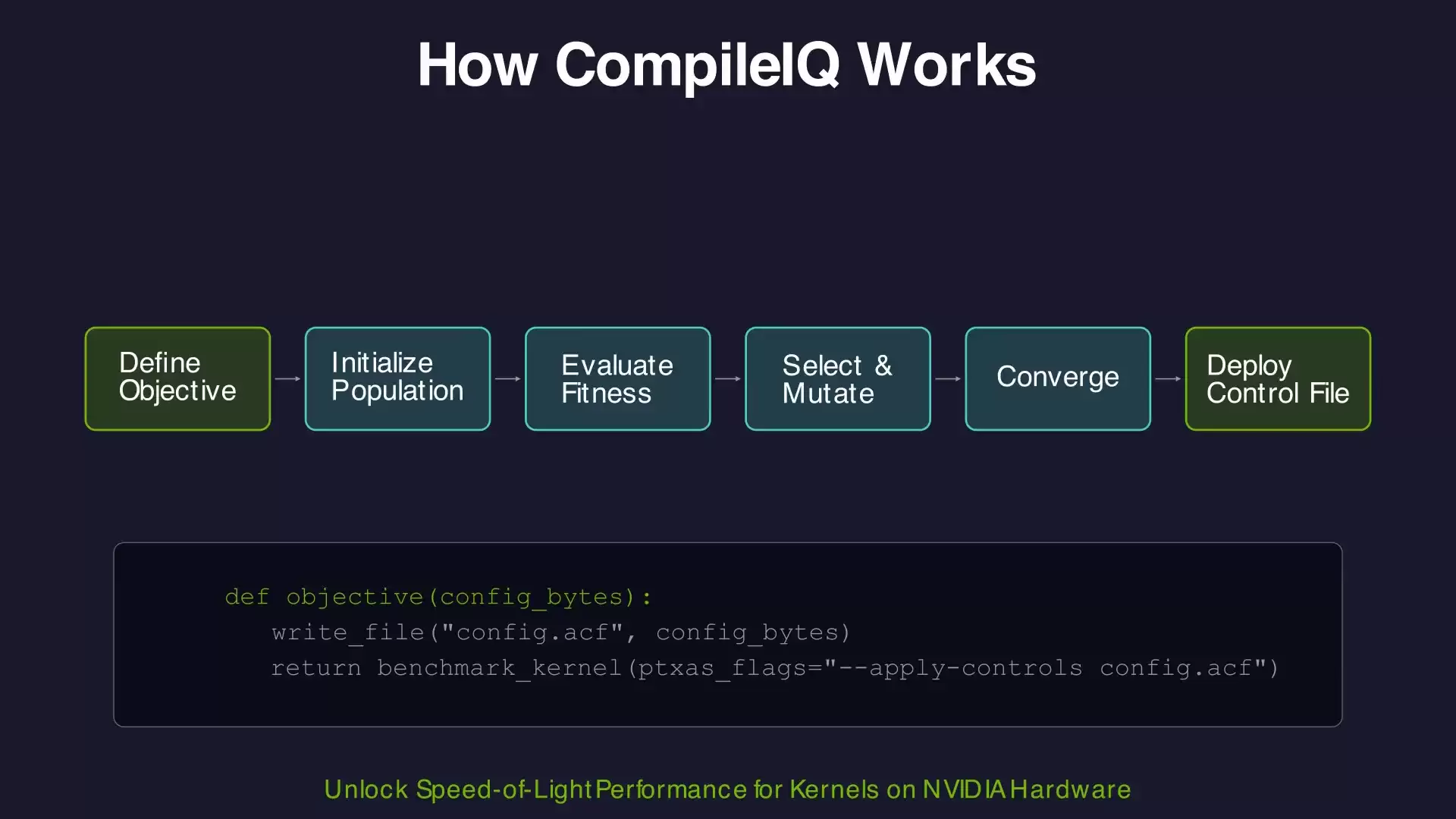
CompileIQ的核心创新在于彻底改变了优化范式。它摒弃了“一刀切”的通用编译器配置,转而针对每个最关键的内核,通过智能搜索生成独一无二的、量身定制的编译器内部配置。
其技术原理是探索一个极其丰富的编译器内部参数空间。这些参数——例如寄存器分配策略、指令调度算法、循环变换启发式等——通常并未通过公开的编译器命令行标志暴露。CompileIQ通过高效的进化搜索算法,自动探索这些参数的组合,并输出一个高级控制文件(ACF)。编译器通过--apply-controls标志读取此文件,从而生成专门为你的工作负载极致优化的内核二进制代码。
可以这样比喻:你的NVIDIA编译器本身具备为你的内核生成更优代码的潜力,但它不知道哪一套内部“开关”组合能实现这一目标。CompileIQ的进化搜索引擎,正是自动寻找这套最优组合的“智能导航系统”。
对于已经用尽所有已知优化技巧的团队而言,CompileIQ提供了一个全新的、前所未有的性能调优维度——即编译器自身的微调。目前,该技术已被多家领先的AI实验室应用于其生产环境中最性能敏感的工作负载。
四步快速入门指南
CompileIQ作为一个Python软件包,其工作流程清晰简洁:安装、定义目标、配置、运行。
pip install compileiq该工具包内置了针对PTXAS和NVCC的预定义编译器搜索空间,可通过API自动加载,无需用户手动下载或配置底层参数。
开发者的核心任务是定义一个目标函数:即一个Python可调用对象,它接收一个候选编译器配置,使用该配置编译你的内核并执行基准测试,最后返回一个性能评分(如运行时间)。只要你能对内核进行基准测试,就能轻松集成CompileIQ。
以下是一个基础示例:
import subprocess
from compileiq.ciq import Search
from compileiq.types import SearchConfiguration
# 定义目标函数:使用ACF编译内核并测量运行时间
def objective(config_blob):
with open("config.acf", "wb") as f:
f.write(bytes.fromhex(config_blob))
result = subprocess.run(["ptxas", "-v", "-arch=sm_90a",
"--apply-controls", "config.acf",
"my_kernel.ptx"], capture_output=True, text=True)
return extract_runtime(result.stdout)
# 配置并运行进化搜索
config = SearchConfiguration(pool_size=32, cull_size=24, generations=20,
mutate_rate=0.1, problem_type="min",
num_objectives=1)
search = Search(config, objective)
best_acf = search.run()上述代码逻辑可分为三个明确部分:
- 定义目标:我们编写了
objective函数,它接收十六进制格式的配置数据config_blob,将其保存为ACF文件,调用编译器编译内核,并从中提取性能指标。 - 配置搜索:设置驱动进化搜索的关键参数,例如每代种群大小(
pool_size)、保留的精英个体数量(cull_size)、运行代数以及优化目标类型。 - 执行搜索并获取最佳配置。
搜索启动后,CompileIQ会初始化一个编译器配置种群,根据你的目标函数评估每一个配置的适应度,选择表现优异的个体,通过变异和交叉操作产生新一代候选,并在迭代中不断收敛,最终输出最优的ACF文件。你只需定义何为对工作负载“更好”,CompileIQ负责找到实现它的路径。
实战代码示例解析
让我们通过几个可以立即运行的自包含示例来深入理解。CompileIQ的GitHub仓库提供了多个案例,此处我们解析其中两个。
首先是单目标优化示例。它虽与GPU计算无关,但清晰地演示了CompileIQ的基本使用原则。
from compileiq.ciq import Search
from compileiq.types import SearchConfiguration
import compileiq.search_spaces.base as ss
def objective(config):
score = config["x"] ** 2 + config["y"]
return score
def main():
dna_config = {
"x": ss.range(start=1.0, end=20.0, step=0.5),
"y": ss.choice([1, 2, 3]),
"z": ss.literal("this is a constant", knockout_prob=0.5),
}
main_config = SearchConfiguration(generations=5,
problem_type="min",
num_objectives=1,)
tuner = Search(objective_function=objective,
search_space=dna_config,
search_config=main_config,)
results = tuner.start()
print(f"Entire Results Dataframe:\n {results.get_results()}")
print(f"Best Result: {results.get_best_result()}")
if __name__ == "__main__":
main()目标函数很简单:计算x的平方加上y。配置字典dna_config定义了搜索空间:x为1.0到20.0之间的浮点数,步长0.5;y是离散值,只能取1、2或3;z是一个常量字符串,用于演示参数剔除概率。
搜索配置指定运行5代,优化目标为最小化函数值,且为单目标优化。运行后,由于代数较少且搜索具有随机性,可能未找到绝对最优解(x=1.0, y=1,得分2.0),但最佳结果(例如x=1.0, y=2,得分3.0)已非常接近。若将代数增加至15代,则几乎总能找到全局最优解。
接下来是一个测量真实GPU内核性能的示例。GitHub仓库中有一个使用NVCC编译归约内核的案例。其搜索空间配置为使用CUDA 13.3的NvccSearchSpace,优化类型为MIN(最小化运行时间)。目标函数会编译并运行内核,从输出中解析Time =后的数值,并在搜索空间中寻找使该值最小的编译器配置。
运行优化脚本后,典型输出如下:
$ python optimize_reduction.py --arch sm_120
Running baseline...
Baseline: 0.777 ms
Starting optimization (10 generations, pool=15)...
? Generation:10/10|█| [elapsed: 09:29 · eta: 00:00] , ? best_score=0.7700,
Baseline: 0.777 ms
Optimized: 0.770 ms
Speedup: 1.01x
Config saved: reduction_best_config.bin
Usage: nvcc --apply-controls reduction_best_config.bin -arch=sm_120 ...通过搜索获得了约1%的性能提升。要应用这个优化配置,只需在后续编译命令中使用--apply-controls选项并指定生成的ACF文件即可。
多目标优化与知识产权安全保障
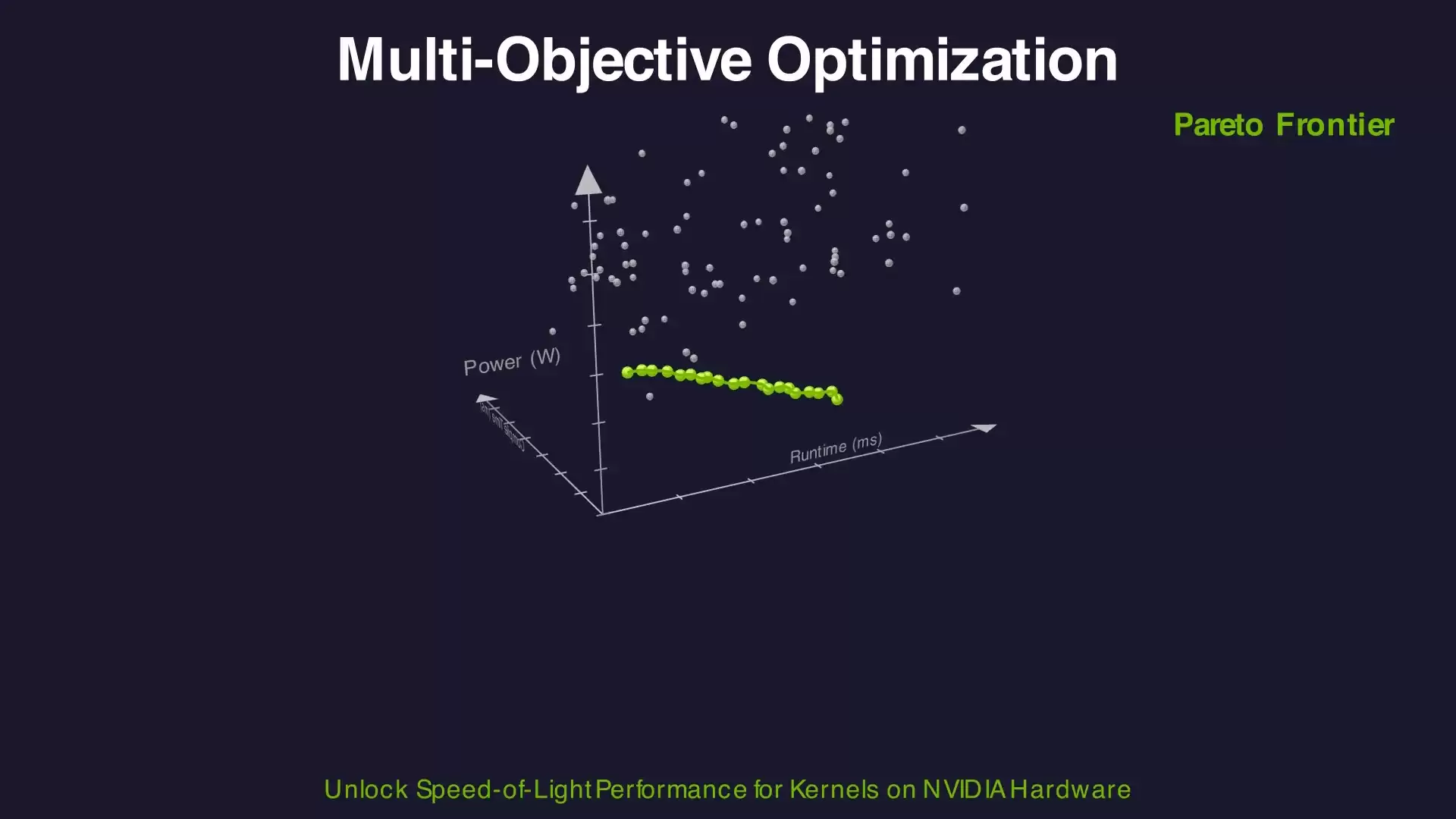
多数自动调优工具仅针对单一指标(通常是运行时间)进行优化。CompileIQ更进一步,原生支持多目标优化,能够同时探索运行时间、编译时间、功耗等多个相互竞争的目标之间的最佳权衡。
这一特性至关重要,因为“绝对最快”并非总是唯一诉求。受功耗预算约束的数据中心,可能愿意接受运行时间的轻微增加,以换取功耗的显著降低。持续集成/持续部署(CI/CD)流水线可能优先考虑更短的编译时间以加速迭代。嵌入式部署则需要综合权衡性能、功耗和二进制大小。
CompileIQ的进化引擎会计算出一个帕累托前沿,即一组“非支配解”。在这些配置中,任何单一目标的改进都会导致至少一个其他目标的恶化。团队可以根据自身的业务约束,从这个前沿中选择最合适的权衡点,而非被限制在单一的优化维度上。
此能力极大地拓展了CompileIQ的适用场景,使其远超LLM推理范畴。在任何使用NVIDIA编译器的领域——包括科学模拟、自动驾驶、医学成像、推荐系统等——CompileIQ都能深入探索优化空间,发现默认启发式规则所遗漏的高效配置。
在知识产权保护方面,CompileIQ的设计确保了用户和编译器双方的安全。复杂的编译器内部细节被封装在搜索空间定义和生成的ACF中,用户无需接触。用户的工作负载基准测试始终在本地执行,只有最终生成的、不包含源代码的ACF文件被输出。ACF文件可以安全地纳入版本控制系统,并在团队或不同部署环境间共享,无需担心源代码泄露。
实际效能与生产环境应用
CompileIQ已在针对GPU和CPU目标的生产工作负载中得到验证。例如,相关技术报告展示了在TritonBench和Helion内核上实现高达15%的性能提升。
值得注意的是,这些增益是在已经被开发者认为“充分优化”的内核基线之上实现的。性能改进直接源于CompileIQ发现了默认编译器启发式规则永远不会主动选择的内部配置组合。
目前,多家顶尖AI实验室已在其最性能关键的推理和训练工作负载中投入生产使用。CompileIQ生成的ACF文件具有完全的可重现性和可移植性:只要基准测试环境和底层编译器版本一致,相同的ACF能在不同机器上生成完全相同的优化后二进制文件。团队可以将ACF与内核源代码一同提交至版本控制系统,使得编译器优化成为软件开发流程中可版本化、可评审、可复现的一环。
立即开始行动
目前,CompileIQ已为PTXAS(PTX汇编器)和NVCC(NVIDIA CUDA编译器)提供了开箱即用的编译器搜索空间。识别出你应用中影响最大的性能热点内核——GEMM和注意力内核通常是绝佳的起点——编写一个能够准确衡量关键性能指标(如延迟、吞吐量)的基准测试,然后即可运行CompileIQ进行探索。
需要明确的是,CompileIQ并非能将编写拙劣的代码自动转化为高性能代码的魔术工具。要从中获得最大价值,你需要从一个已经过良好优化、性能表现不错的代码基线开始。这样,最终的编译器启发式微调才能带你突破最后的瓶颈,触及性能巅峰。
但是,如果你的团队已经用尽了所有已知的优化手段,那么CompileIQ将赋予你们一个全新的、强大的性能杠杆——即编译器自身的深度优化能力。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

朗玛信息股价下跌3.16%后市走势分析及投资机会探讨
今日A股市场整体走势偏弱,朗玛信息(股票代码300288)股价同步调整,截至收盘下跌3 16%,全天成交额4783 73万元,换手率为1 77%,公司总市值约为35 21亿元。股价的短期波动,引发了投资者对其核心投资逻辑与未来潜在机会的深入探讨。 异动深度解析:AI医疗战略的机遇与挑战 朗玛信息是市

Kimi联网搜索排除干扰技巧 精准限定提示词方法
在Kimi里搜索“2026年北京积分落户政策细则”,如果跳出来的总是房产中介的软文、培训机构的广告或者各种自媒体猜测,那说明默认的联网检索没有经过过滤。想要获得干净、权威的结果,必须主动使用结构化的提示词进行限定。 用结构化提示词锁定权威信源 这一步是关键,直接决定了你看到的信息是来自官方发布渠道,

Qoder编辑器自动保存功能设置与基础配置教程
为避免代码丢失,Qoder编辑器需手动开启自动保存功能。全局设置中可开启开关并选择触发条件,如按时间间隔或窗口失去焦点时保存。还可为特定项目单独配置,覆盖全局设置。若功能失效,需检查文件位置是否只读、用户权限是否足够,并避免直接编辑受保护的系统文件。

人工智能驱动外贸增长 机器人出海成新趋势
当前,全球人工智能产业浪潮澎湃,这股技术变革之风不仅深刻重塑着全球产业格局,也正为中国外贸增长注入全新的动力。一个清晰可见的趋势是,以算力服务、智能硬件为代表的“高含智量”产品与服务,已成为国际出口市场上的新焦点与增长点。 在广东汕头,一项名为“来数加工”的创新政策试点,正成功地将无形的计算能力转化

Nocera成立控股公司融资3亿美元 加速布局AI与数据中心市场
科技产业的竞争格局正迎来新一轮深刻变革。近日,纳斯达克上市公司Nocera, Inc (股票代码:NCRA)正式宣布启动一项全面的企业转型与品牌升级计划。其核心举措是成立全新的控股实体——Nocera控股公司,旨在系统性地布局人工智能、AI基础设施、数据中心、机器人技术、生物科技以及区块链与数字资产








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
