




谷歌多模态向量模型上线文字搜图片与图片搜视频功能

谷歌最近扔下了一颗重磅技术冲击波:首个原生多模态向量模型 Gemini Embedding 2 正式亮相。这可不是一次简单的升级,它真正实现了将文字、图片、视频、音频乃至文档,全部塞进同一个“理解空间”里。这意味着什么?意味着机器对世界的感知方式,正在从割裂走向统一。
Gemini Embedding 2上线,统一图文音视频向量空间
基于强大的Gemini架构,这个新模型已经通过Gemini API和Vertex AI开放了预览。它最核心的突破,就在于打破了模态之间的壁垒。过去,处理不同格式的数据往往需要不同的模型和流程,而现在,无论是文本、图像、视频、音频还是PDF文档,Gemini Embedding 2都能将它们映射到同一个高维向量空间中,并且能跨越上百种语言捕捉背后的语义意图。
这种“大一统”的设计,带来的直接好处就是简化。以往需要多套系统拼接的复杂流程,现在可以一站式搞定。无论是构建更精准的检索增强生成(RAG)系统,还是进行跨媒体的语义搜索、情感分析,甚至是海量多模态数据的聚类管理,效率和效果都得到了显著提升。
五大模态全面打通,支持交错输入
得益于Gemini与生俱来的多模态理解基因,新模型在各项输入规格上都相当能打:
- 文本:一口气处理8192个Token的长上下文不在话下。
- 图像:单次请求最多能“吃下”6张图片,支持常见的PNG和JPEG格式。
- 视频:能理解长达2分钟的视频片段,MP4和MOV格式都兼容。
- 音频:这一点尤其值得关注——它支持原生音频数据直接输入,完全绕过了先转成文字再处理的中间步骤,保留了声音中文字无法承载的丰富信息。
- 文档:可以直接“阅读”并嵌入最多6页的PDF文件内容。
更厉害的是,它原生支持“混搭”输入。开发者可以在一次请求中,同时传入一张产品图片、一段用户评价音频和几行说明文字。模型能够精准捕捉这些不同类型数据之间复杂而微妙的关联,从而对现实世界中混杂的信息实现更贴近人类的理解。
引入套娃表示学习,灵活调整输出维度
技术层面,Gemini Embedding 2用上了一个聪明的“套娃”技术——套娃表示学习(MRL)。简单来说,它就像一套可以伸缩的俄罗斯套娃,信息被嵌套存储在不同维度里。
这种设计给了开发者极大的灵活性。模型的默认输出维度是3072维,但你可以根据实际需求,像调节音量一样向下缩放维度,比如降到1536维或768维。这样一来,就能在模型的表现力和存储、计算成本之间,找到一个最适合自己业务场景的甜蜜点。当然,为了追求最高质量,官方还是首推3072、1536或768这三个维度。
设立多模态性能新基准
性能上,Gemini Embedding 2来势汹汹。在文本、图像和视频相关的标准测试任务中,它已经超越了现有的领先模型。而它新引入的原生音频处理能力,更是直接为“多模态”这个词设立了新的深度标准。这等于为开发者提供了一个更强大、更通用的基础工具,去应对日益多样化的嵌入需求。
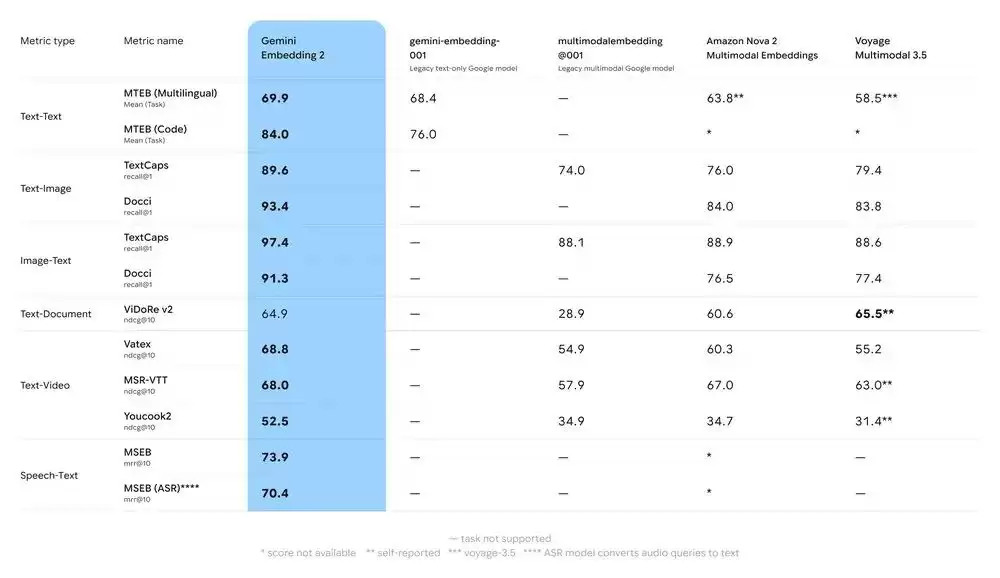
如今,嵌入技术早已是谷歌众多产品体验的隐形引擎,同时在RAG的上下文工程、大规模数据治理以及经典搜索分析等场景中也扮演着核心角色。据悉,一些早期合作伙伴已经开始利用Gemini Embedding 2,开发更具想象力的高价值多模态应用了。
开发与生态支持
对于开发者而言,接入门槛相当友好。通过Gemini API或Vertex AI就能快速用上。谷歌提供了Python SDK(google.genai),几行代码就能在单次调用中完成文本、图片和音频的联合嵌入处理:
from google import genai
from google.genai import types
client = genai.Client()
with open("example.png", "rb") as f:
image_bytes = f.read()
with open("sample.mp3", "rb") as f:
audio_bytes = f.read()
# 同时嵌入文本、图片和音频
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
],
)
print(result.embeddings)
上面的代码逻辑很清晰:初始化客户端,指定预览版模型,然后在内容列表里依次传入文本字符串、以及转为字节流的图片和音频文件,模型就会直接吐出一个融合了多模态信息的向量结果。
生态兼容性方面也无需担心。除了官方提供的交互式Colab笔记本,主流的开发框架和向量数据库,像LangChain、LlamaIndex、Haystack,以及Wea viate、QDrant、ChromaDB和Vector Search等,都已经做好了支持。这意味着你可以很平滑地将它集成到现有的技术栈中,快速启动项目。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
