




AMD研究发现FP4训练不稳定根源并非随机性不足


在原生 FP4 硬件上实现端到端 9-10% 的训练加速
大模型训练的成本压力,一直是悬在行业头顶的达摩克利斯之剑。降低训练精度,是公认的破局关键。DeepSeek-V3 采用 FP8 训练,将成本压至 560 万美元,已经让业界看到了显著成效。
那么,一个很自然的问题随之而来:既然 FP8 可行,精度能否进一步下探到 FP4?理论上,FP4 的计算吞吐潜力是 FP8 的两倍。NVIDIA 的 Blackwell 和 AMD 的 MI350 系列,都已经在硬件层面原生支持了 FP4 运算。硬件似乎已准备就绪,但软件和算法侧却卡在了一个顽固的难题上:
用 FP4 从头训练大模型,过程极不稳定。
过去两年,LLM-FP4、NVFP4 预训练等研究陆续尝试,但鲜有方案能干净利落地在 4 比特精度下跑完全流程预训练,同时保持接近 FP8 的收敛质量。更棘手的是,崩溃的根源一直模糊不清,普遍分析认为,问题可能出在随机性不足上。
然而,最近由 AMD 联合宾夕法尼亚州立大学发布的一篇论文,碘伏了这一传统认知,为原生 FP4 训练提供了一个全新的、清晰的诊断。

- 论文标题:Pretraining large language models with MXFP4 on Native FP4 Hardware
- 论文链接:https://arxiv.org/abs/2605.09825
这项研究在 AMD Instinct MI355X GPU 上,使用 MXFP4 格式成功完成了 Llama 3.1-8B 模型的全流程预训练。最终,端到端的训练速度比 FP8 基线快了 9-10%,而 token 开销仅增加了 8-9%。这是目前首个在原生 FP4 硬件(非软件模拟)上完成大模型预训练的完整实验。
更重要的是,论文揭示了核心问题的本质:FP4 训练不稳定性的根源,并非随机性不足,而是结构性的微缩放误差沿着敏感的梯度路径被累积并放大了。
MXFP4 是什么
在深入拆解论文之前,有必要先理解 MXFP4 这一数据格式。
传统的整数量化通常为整个张量使用一个统一的缩放因子。MXFP4 的核心设计在于「微缩放」:它将一个张量切分成小块(例如每 32 个元素一组),为每个小块分配一个共享指数(采用 E8M0 格式),块内的每个元素则用 4 比特浮点数表示。其重建公式可以表述为:
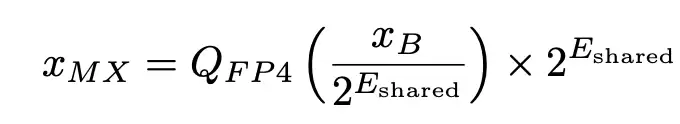
其中,E_shared 是块内的最大指数,Q_FP4 是经过最近舍入后得到的 4 比特浮点可表示值。
微缩放的优势在于,每个小块拥有独立的动态范围,从而避免了被全局异常值“绑架”。这使得 4 比特浮点数的表示质量,远优于朴素的全局量化方法。
但即便有了微缩放,FP4 训练依然不够稳定。
排查实验:不稳定的根源
研究团队设计了一套逐步排查的控制实验来定位问题。
一次完整的 Transformer 线性层计算,涉及三个通用矩阵乘法操作:
- Fprop(前向传播):计算 Y = XW^T,产出激活值。
- Dgrad(激活梯度):计算 ∇X = ∇Y · W,将梯度回传给输入。
- Wgrad(权重梯度):计算 ∇W = (∇Y)^T · X,产出用于更新权重的梯度。
研究团队保持其他所有因素不变,逐步将这三个操作从 FP8 替换为 MXFP4,观察每一步对模型收敛的影响。所有实验均在 AMD Instinct MI355X 上使用原生 FP4 Tensor Core 执行,不依赖任何软件模拟。
训练任务采用 MLPerf 标准设置,在 C4 数据集上预训练 Llama 3.1-8B,收敛目标为验证集困惑度达到 3.3。
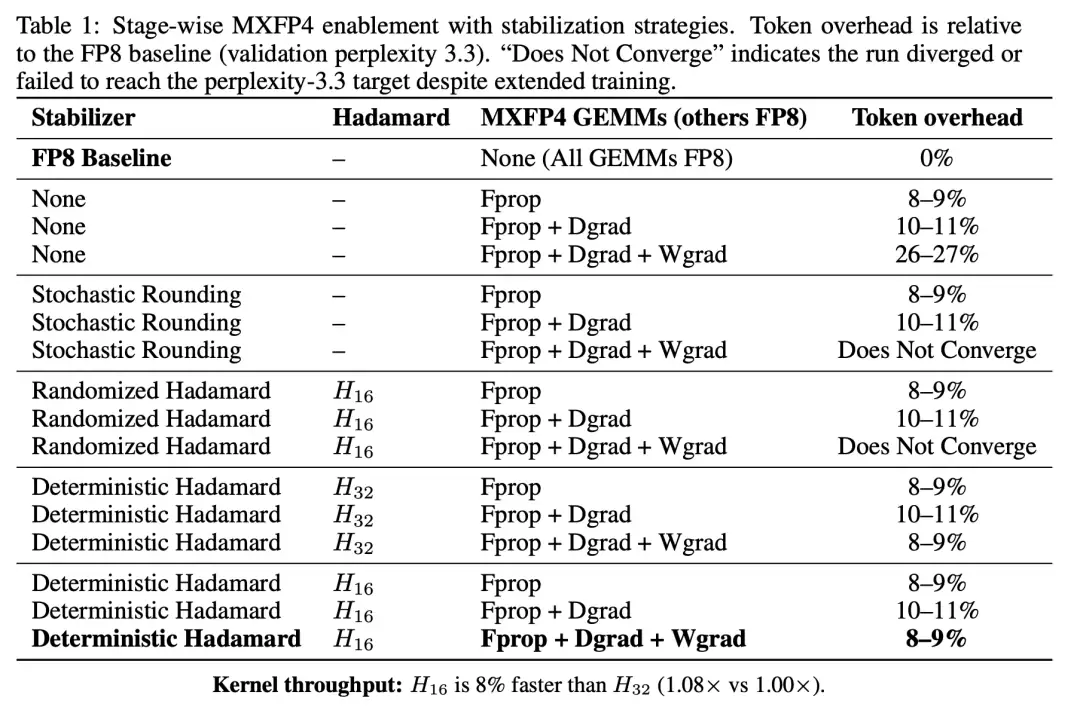
实验结果显示,前两步(Fprop 和 Dgrad)替换为 MXFP4 仅带来了温和的额外 token 开销。然而,一旦将 Wgrad 也替换为 MXFP4,开销便急剧跃升至 26-27%。
Wgrad 是 FP4 训练的瓶颈所在。前向传播和激活梯度对 FP4 量化表现出相当的容忍度,但权重梯度一旦被量化到 4 比特,收敛质量便出现显著退化。
业界此前的普遍直觉是,FP4 量化误差本质上是噪声问题,因此可以通过注入随机性来“平滑”误差分布。两种常见策略是:
- 随机舍入:在量化时引入随机性,使舍入误差的期望值为零。
- 随机 Hadamard 旋转:在量化前,使用带有随机符号翻转的 Hadamard 变换来打散数据分布。
然而,当 Wgrad 被量化后,这两种随机性策略不仅未能稳定训练,反而直接导致了训练不收敛。随机性非但没有起到帮助作用,反而在关键的梯度路径上引入了更多有效的量化误差。
相比之下,确定性的 Hadamard 旋转一举将全流程的 token 开销从 26-27% 压缩回 8-9%,训练轨迹紧密跟踪 FP8 基线。
这是一个极具诊断价值的结果。随机和确定性的 Hadamard 旋转都是正交变换,理论上都能打散异常值的能量分布,对量化误差的缓解效果应该类似。但它们在 Wgrad 场景下的表现却截然相反,这揭示了问题的本质:
FP4 训练的不稳定性,是由 MXFP4 微缩放在敏感梯度路径上产生的结构性误差所驱动的。随机性策略之所以失败,是因为它们在每一步引入了不同的误差模式,而这些变化的误差模式沿着梯度路径累积,反而放大了不稳定性。确定性旋转之所以有效,恰恰是因为它在每一步施加了相同的变换,使得误差模式保持一致,从而避免了误差的灾难性累积。
端到端效率:训练步吞吐 +20%,综合加速 9-10%
在应用确定性 Hadamard 旋转并启用全流程 MXFP4 之后,效率数据如下:

训练步吞吐提升了 20%,扣除多出的 8-9% token 开销后,端到端的综合加速仍能达到 9-10%。
考虑到这是将精度从 8 比特直接削减到 4 比特,这样的收敛质量和加速幅度都相当可观。
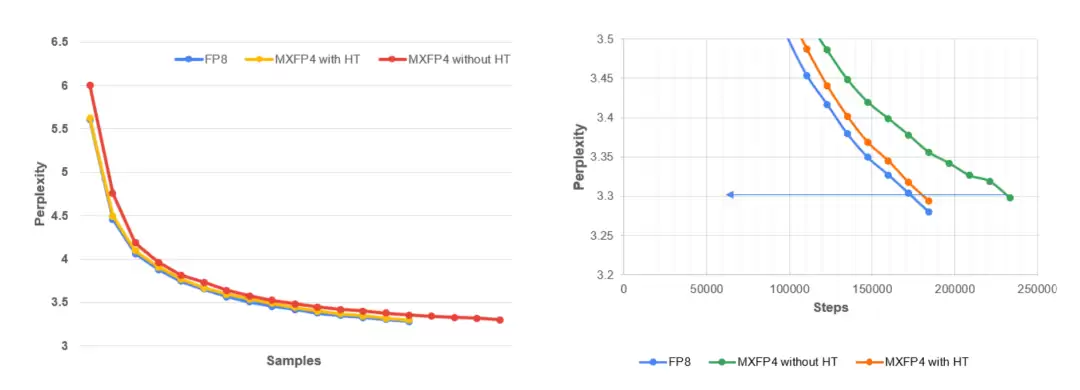
左图展示了在 C4 数据集上进行 MLPerf 预训练时,Llama 3.1–8B 的验证困惑度随训练 token 数变化的曲线。结果显示,MXFP4 + 确定性 Hadamard 与 FP8 基线的表现非常接近,而未进行稳定化处理的全流程 MXFP4 则收敛更慢,稳定性也更差。右图是训练后期的局部放大视图,MLPerf 的目标困惑度为 3.3。可以清晰看到,与未稳定化的 MXFP4 运行相比,采用确定性 Hadamard 旋转的方案能够与 FP8 基线保持更紧密的一致性。
需要特别指出的是,论文作者明确强调了一项重要限制:这套 FP4 训练方案(在 MLPerf C4 数据集 + Llama 3.1-8B 上)的效果已得到验证,但不能直接假设它能无缝迁移到所有模型、数据集和训练方法。FP4 训练的行为可能是高度依赖于具体设置的,针对不同场景的稳定策略需要重新验证。
结语
将这篇论文置于更广阔的产业脉络中审视,至少有三层意义。
第一层,它回答了一个根本性的“为什么”。过去的 FP4 训练研究大多聚焦于“如何让它不崩溃”,而这篇论文首次给出了清晰的因果诊断:崩溃源于 Wgrad 路径上的结构性微缩放误差,而非随机性不足。这个诊断本身具有方法论价值,它指引后续研究者在遇到低精度训练不稳定性时,应优先排查结构性误差源,而非盲目增加随机性。
第二层,它将 FP4 从“推理专属”推向了“训练可用”。此前的行业共识是 FP4 仅适合推理量化,训练至少需要 FP8。NVIDIA 在 Blackwell 架构上主推 FP4 推理而非训练,也反映了这一判断。这篇论文在原生 FP4 硬件上跑通了全流程预训练,意味着 MI355X 和 Blackwell 上那些为推理准备的 FP4 算力,理论上也可以用于训练。如果 FP4 训练在更大模型和更多场景中得到验证,现有硬件的可用训练算力将有望直接翻倍。
第三层,它基于 OCP 开放标准。MXFP4 是 OCP Microscaling 格式标准的一部分,其背后有 AMD、NVIDIA、Intel、Meta、Microsoft、Arm、Qualcomm 七家公司的联合支持。基于开放标准意味着这套方法在不同厂商的硬件上具备可移植性,不会被锁定在单一生态中。
从 FP16 到 FP8,DeepSeek-V3 已经证明精度减半可以大幅降低训练成本。从 FP8 到 FP4,这篇论文迈出了关键的第一步。精度每削减一次,整个大模型训练的经济性都在发生深刻转变。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
