




ICML 2026视觉分割新突破 边看边改方法提升准确率9%

视觉分割任务看似直接:给定一张图像和一句描述,要求模型精确勾勒出目标物体的像素轮廓。然而在实际应用中,模型常常面临挑战。当目标定义模糊、被部分遮挡,或需要结合常识进行推理才能定位时,一次性生成准确的掩码就变得异常困难。
问题的症结何在?复旦大学与创智联合团队的最新研究RSAgent提出了一个深刻见解:现有方法所欠缺的,或许并非更强大的分割头,而是一个“验证与迭代优化”的闭环过程。他们提出的框架,使多模态大模型能够通过多轮工具调用,像人类一样“边观察边修正”,最终输出更可靠的掩码结果。这项创新工作已被ICML 2026接收。

实验数据证实了这一思路的有效性。在需要复杂推理的ReasonSeg测试集上,RSAgent的gIoU指标相比Seg-Zero-7B显著提升了9.0个百分点;在RefCOCOg数据集上也取得了81.5%的平均cIoU,展现了卓越的开放词汇分割性能。
开放语义分割的核心挑战
当前的多模态大语言模型(MLLM)已能流畅完成图像描述、问答和关系理解等任务。然而,现实世界的视觉系统需求更为深入。无论是交互式图像标注、机器人环境感知,还是设计辅助与工业质检,都要求模型能将语言指令精准地映射到图像的像素级区域。换言之,模型必须在“理解语义”与“生成精确掩码”之间建立稳定可靠的桥梁。
真正的难点在于“开放语义”的复杂性。用户指令往往不是简单的物体类别名称,而是包含模糊指代和推理需求的描述,例如“图片左侧被人拿起的物品”,或“识别湍急水流中用于保障个人安全的装备”。前者考验模型对空间关系的理解,后者则需要场景常识和功能推理。面对此类指令,若模型仅依赖单次前向预测,则难以验证其初始定位是否正确。
因此,现有技术路线的短板,可能并不在于“无法生成掩码”,而恰恰在于“缺乏一个确认与迭代优化的机制”。一旦初始定位出现偏差,或提示点落在背景区域,模型往往就失去了重新审视、调整策略的机会。RSAgent正是针对这一痛点,将分割任务从静态预测转变为动态交互过程。其核心思想是:赋予模型在开放语义任务中“先判断、再行动、观察反馈、后修正”的闭环能力。
解决方案:赋予MLLM推理与行动能力
RSAgent的关键设计在于,并非将MLLM直接改造为掩码解码器,而是使其成为能够调度各类视觉工具的智能体。在每一轮交互中,模型接收原始图像、文本指令以及历史观察结果,随后输出结构化的推理过程和工具调用指令。视觉工具(如分割模型)则返回局部视图、候选掩码或叠加效果图。模型基于这些反馈,决定是继续调用工具、调整提示,还是提交最终答案。
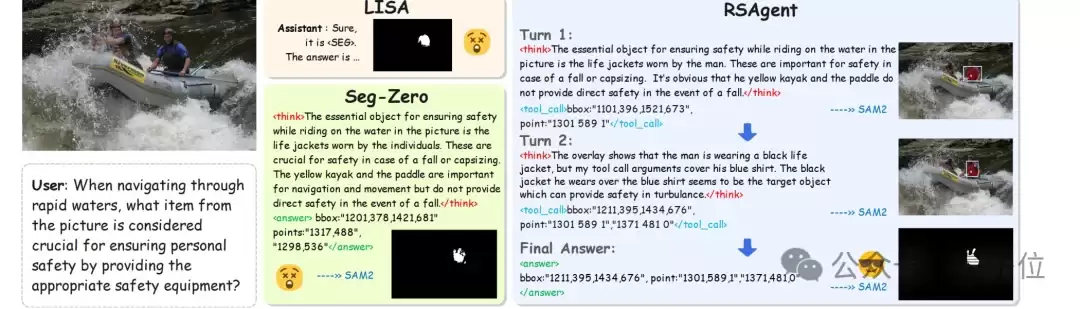
下图直观对比了LISA、Seg-Zero等单次预测方法与RSAgent多轮交互策略的区别。后者通过持续的定位、观察与修正,逐步逼近目标区域。
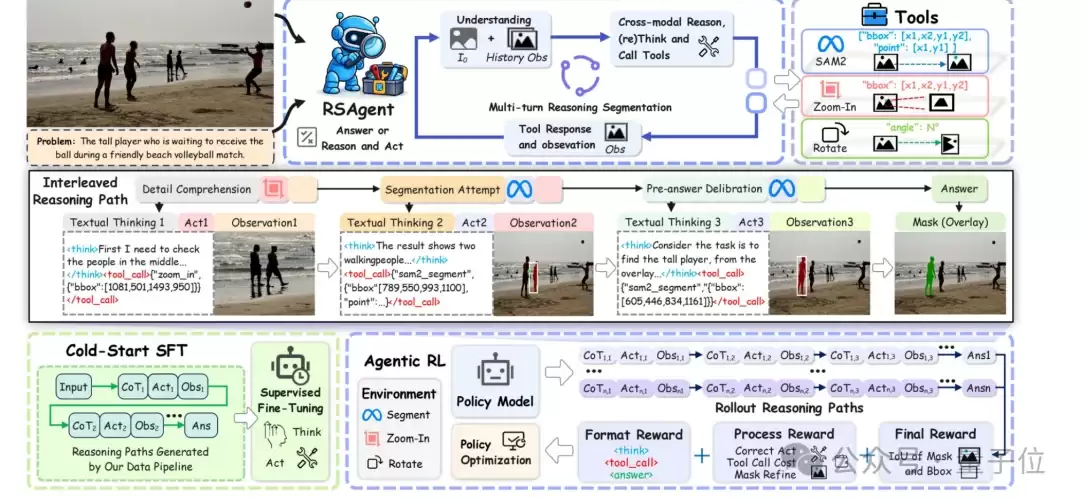
RSAgent的整体框架如下图所示,涵盖了多轮交互、工具调用、观察反馈,以及核心的训练策略:冷启动监督微调(cold-start SFT)和智能体强化学习(agentic RL)。
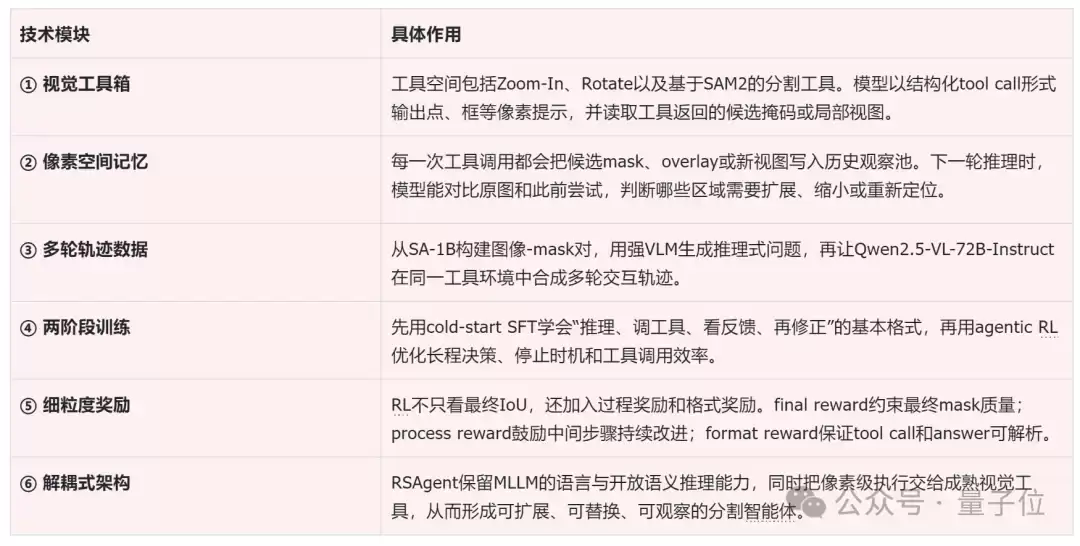
具体的技术模块及其功能,可参考下图分解:
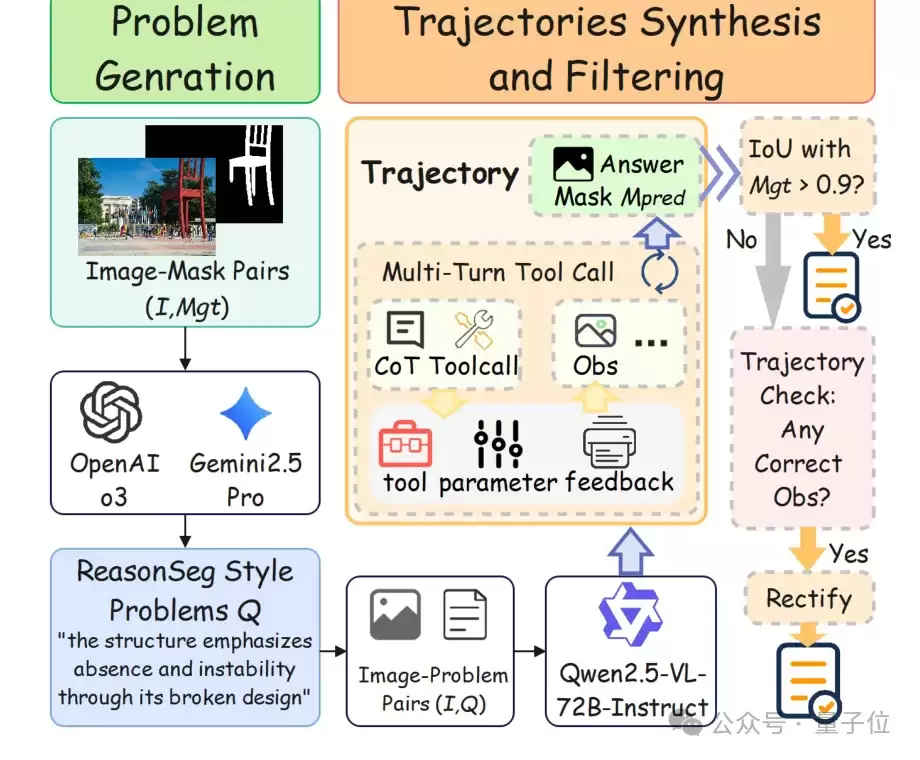
在数据构建层面,RSAgent通过自动化合成与严格筛选来构建高质量的训练轨迹。论文中用于冷启动SFT的数据包含了约5千条高质量的多轮推理轨迹;在RL阶段,则使用了约2千个强化学习示例,并额外加入了8千个RefCOCOg训练样本,使模型能在交互环境中学习回报更高的工具调用路径。下图展示了其数据生成与过滤流程。
可以说,RSAgent的创新之处不仅在于“调用了工具”,更在于将推理、工具使用、反馈与奖励机制整合为一个统一的训练体系。模型不仅要理解目标是什么,还要学会自适应地决定何时缩放视图、在何处提供提示、如何进行分割以及何时停止,最终将开放的语义理解转化为准确的像素级掩码。
具体到单次交互循环,可分解为四个步骤:
- 观察(Observation):读取图像与历史交互结果;
- 思考(Thought):用自然语言分析当前候选区域是否满足指令要求;
- 行动(Action):选择合适工具并给出像素级提示(如点或框);
- 反馈(Feedback):接收工具输出并写入上下文,供下一轮决策参考。
这一循环使模型摆脱了对单次判断的绝对依赖,拥有了逐步验证的机制。这对于处理关系型(如“左边的”)、属性型(如“红色的”)或需要隐含推理(如“能用来救生的”)的指令尤其有效。当目标物体较小、被遮挡,或需要根据动作和相对位置来判定时,RSAgent可先进行粗定位,再查看局部区域,然后根据候选掩码的偏差重新指定提示点,从而提供了一个可审查的中间过程。
在训练策略上,冷启动SFT解决了“能否按规范工作”的问题,让模型掌握工具调用的语法和基本的反思流程;而智能体RL则解决了“如何做得更好”的问题,通过奖励信号来优化多轮决策路径。两者结合,使得RSAgent既能稳定输出结构化结果,也能在复杂的开放语义样本上学习更优的决策序列。
实验结果:在ReasonSeg与RefCOCOg基准上取得领先
研究团队以Qwen2.5-VL-7B-Instruct为基础模型,SAM2-large作为分割工具,在RefCOCO系列和ReasonSeg基准上进行了系统评估。他们对比了传统视觉语言分割器、单次预测的MLLM分割方法、显式思维链/强化学习方法以及多轮工具调用智能体等多种方案。
下图表明,RSAgent在RefCOCO系列(RES)和ReasonSeg基准上均取得了领先的性能表现。
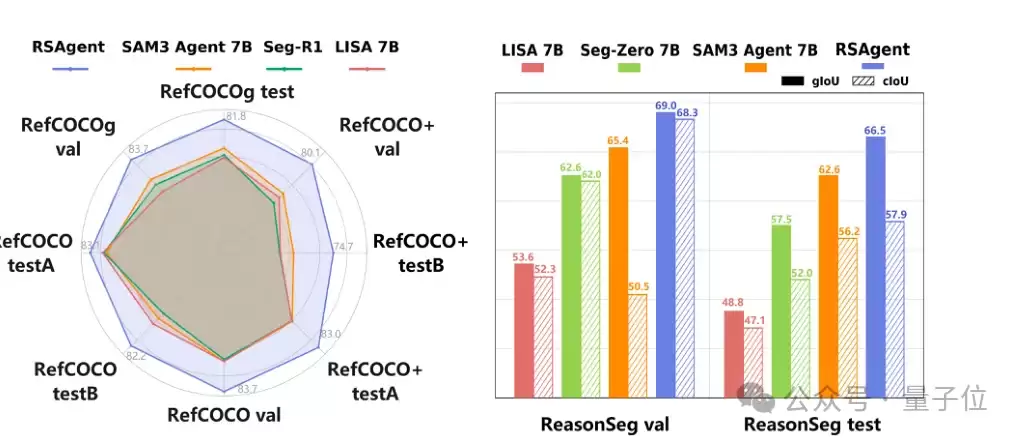
具体的评测数据如下:
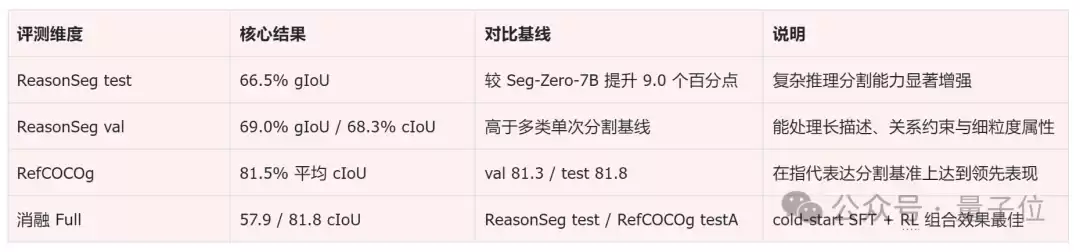
在ReasonSeg测试集上,RSAgent达到了66.5%的gIoU,相比Seg-Zero-7B的57.5%提升了9.0个百分点;在RefCOCOg上,平均cIoU达到约81.5%。这对于依赖开放语义推理的目标分割任务而言,意味着模型不仅能理解复杂描述,还能更稳健地将理解转化为准确的掩码。
消融实验进一步揭示,性能提升并非源于单一模块。未经训练的智能体在ReasonSeg测试集上cIoU仅为30.1;加入冷启动SFT后提升至55.4;仅使用RL为54.3;而完整的SFT+RL组合则达到了57.9。这清晰地表明,先让模型学会规范的工具调用,再通过强化学习优化长程决策,是RSAgent成功的关键。
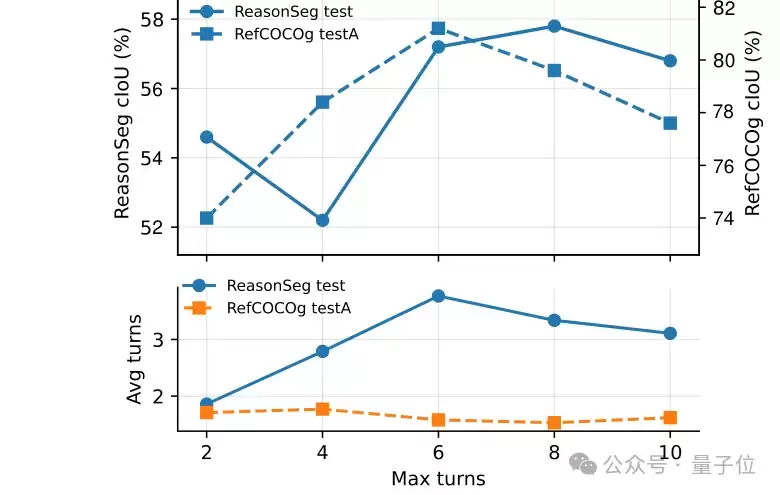
下图展示了最大工具调用轮数的消融实验结果。适当增加交互轮数可以提升表现,但过长的上下文可能带来冗余和不稳定。
奖励函数的设计同样至关重要。实验发现,移除最终掩码质量奖励(final reward)、过程奖励(process reward)或格式奖励(format reward)都会导致性能下降。其中,去掉最终质量奖励后,ReasonSeg测试集上的cIoU从57.9大幅降至48.3,说明生成高质量的最终掩码仍是核心目标。而过程奖励则能鼓励模型在中间步骤持续改进,而不是盲目增加工具调用次数。
迈向可验证的像素级行动空间
RSAgent的价值,远不止于刷新多个基准测试的指标。更重要的是,它展示了一条从“视觉问答”迈向“视觉行动”的可行路径:模型能够围绕文本目标,持续观察、调用工具、接受反馈、修正假设,并将最终判断精准地落实到图像像素上。
这种能力对于构建下一代交互式视觉系统具有广泛的实用意义:
- 在数据标注领域,它有望大幅降低人工反复试错的成本,提升标注效率;
- 对于机器人感知与操作,它让机器人能在执行抓取或移动前重新确认目标区域,提升任务的安全性与可靠性;
- 在设计编辑与内容生产中,它可以将自然语言创作意图转化为更稳定、可编辑的像素区域,辅助创意工作;
- 面对科学图像分析与医疗影像,它则提供了一个可回溯、可复核的中间推理过程,增强了结果的可解释性与可信度。
从更宏观的技术趋势来看,RSAgent成功地将开放语义理解、工具调用和像素级执行连接了起来。它证明,多模态大模型不必仅仅停留在“回答关于图像的问题”,而是可以进一步在视觉空间中主动探索、试错和自我修正。这个方向,将视觉智能体推进到了更接近真实任务需求的形态。
总而言之,RSAgent证明了多模态大模型有能力从“结合文本与图像内容”的层面,进一步走向“在像素空间中推理、行动和自我修正”的新阶段,为通用视觉智能体的发展提供了重要思路。
这项研究由复旦大学、上海创智学院、上海交通大学等单位的团队合作完成。论文共同第一作者为何星旗与张钰杰。何星旗为复旦大学一年级硕士生,研究方向为视觉语言模型推理与强化学习;张钰杰为上海创智学院与复旦大学联合培养博士生,主要研究方向包括视觉语言模型推理、强化学习与大语言模型。
论文地址:https://arxiv.org/abs/2512.24023
项目代码:https://github.com/Nicola777-ai/RSAgent

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
