




Agent框架上下文管理策略详解万字长文深度解析

在构建能够处理复杂、长流程任务的智能体(Agent)时,我们常常面临一个核心挑战:模型需要足够的历史信息来做出明智决策,但过长的上下文又会拖慢推理速度、稀释关键信息,甚至直接超出模型的处理上限。这就像要求一位专家同时处理堆积如山的文件,结果往往是遗漏关键细节或不堪重负。
如何让AI在漫长的“工作记忆”中保持专注与高效?这背后是一门被称为“上下文工程”的关键技术。本文将深入解析几种核心的上下文管理策略,揭示顶尖智能体框架如何巧妙解决这一难题。
0x01. 背景
(1)什么是上下文工程(Context Engineering)?
简而言之,上下文工程是在大型语言模型(LLM)固有约束下——例如有限的上下文窗口长度和注意力机制限制——进行的一场“内存优化”实践。其核心目标非常明确:利用最少、最精炼的token集合,最大化地“引导”出我们期望的模型输出。
为什么这项技术至关重要?因为智能体在运行过程中会持续产生新的数据,例如工具调用的结果、用户的反馈、中间的计算步骤。这些数据构成了模型的“短期工作记忆”,必须被有效管理。上下文工程,正是从这不断膨胀的信息流中,智能地筛选出哪些内容值得放入那个宝贵且有限的“内存条”(即上下文窗口)中。
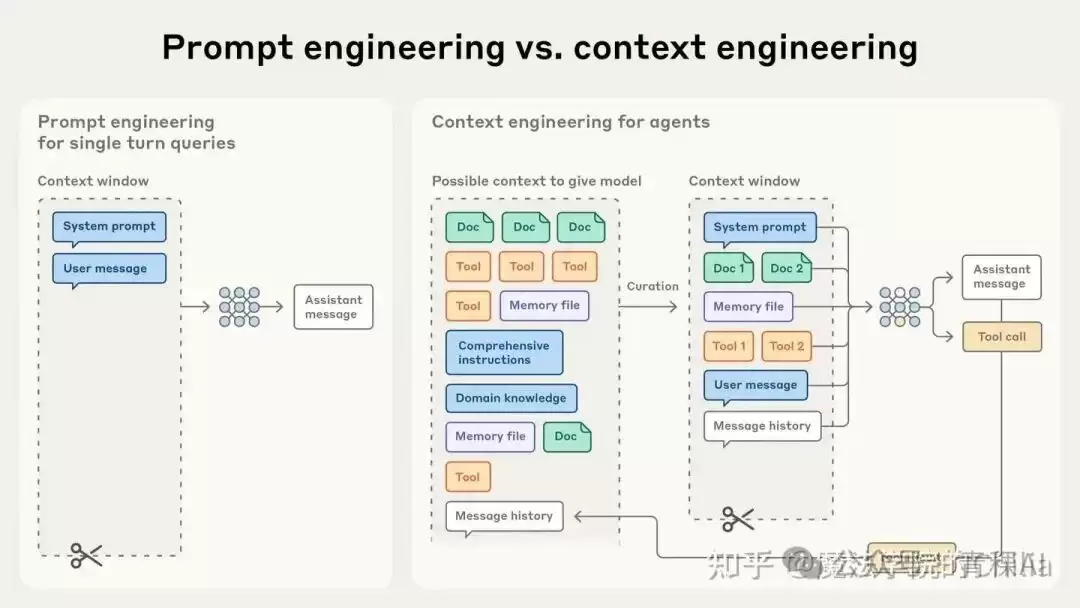
如果说早期的“提示词工程”是为单次问答设计一个完美的开场白,那么“上下文工程”就是为一场可能持续数小时、涉及多轮推理和工具调用的马拉松式对话,设计一套动态的、智能的内存管理方案。
(2)为什么上下文工程对构建强大智能体至关重要?
想象一下智能体的典型工作流程:每次调用工具(例如读取文件、执行命令)都会产生一段观察结果(Observation),这段结果会被追加到对话历史中。在生产环境中,一个智能体可能进行数百轮这样的交互。日积月累,历史记录会像滚雪球一样越来越庞大。
更棘手的是,工具返回的结果往往非常冗长。一次`grep`搜索可能返回数百行日志,一个`cat`命令可能输出整个配置文件。这些庞然大物不断拼接进上下文,很容易触及甚至超过模型的处理上限(例如128K到1M token)。
即便最新的模型宣称支持超长上下文,它们也和人类一样,会遭遇“注意力涣散”的问题。随着上下文长度增长,模型准确回忆信息的能力会下降,推理速度也会变慢。这种现象被称为“上下文腐败”。不同模型的性能衰减曲线各异,但无一例外,在远未达到其宣称的最大长度时,腐败就可能已经开始。
导致这种现象的原因是多方面的:
- 注意力分散:Transformer的注意力机制需要计算每个token与所有其他token的关系,形成n²级别的关联。当n(序列长度)巨大时,注意力被过度摊薄,关键信号容易被淹没。
- 训练数据偏差:模型在训练时接触到的长序列样本远少于短序列,因此对长距离依赖关系的建模经验不足。
- 技术妥协:像位置编码插值这类技术虽然能让模型适应更长的序列,但往往以牺牲一定的精度为代价。
0x02. 上下文工程的核心策略
既然指导原则是“用最精炼的token获得最佳输出”,那么实践中都有哪些具体的管理方式呢?
(1)上下文卸载与检索:将信息转移到文件系统中
最直接的思路是:既然上下文窗口有限,我们就不该把所有信息都塞进去。相反,应该把大部分信息“卸载”到外部存储(例如文件系统),只在需要时进行精确检索。这种思想催生了几种高效的工程实践。
最粗暴的方法是直接截断。但这样做风险极高:关键的错误信息可能藏在日志末尾,重要的数据可能就在被截掉的那几行里。更根本的问题是,我们无法预判哪个看似不起眼的观察结果,会在十步之后变得至关重要。因此,任何不可逆的压缩都是危险的。
(a) 将上下文卸载到文件系统(紧凑化)
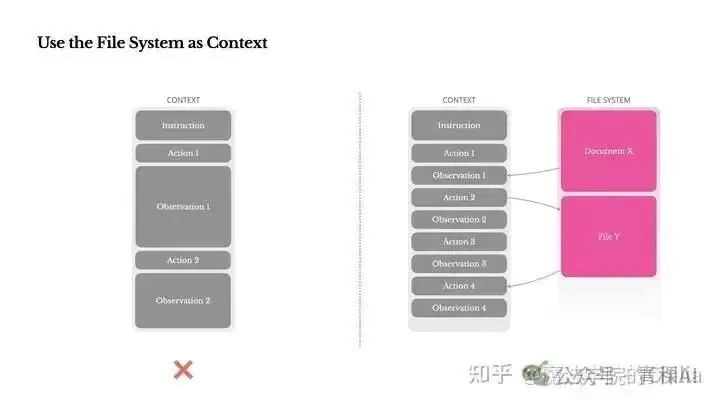
一些前沿框架提出了一个核心理念:将文件系统视为终极的、无限容量的上下文。文件系统天生具备持久化、可随机访问的特性,智能体可以像人类一样,通过路径、文件名来组织和召回信息。最关键的是,这种策略是“可逆压缩”。
举个例子:
- 智能体访问了一个网页,只需在上下文中保留URL,而将冗长的网页内容移除。需要时,重新请求这个URL即可。
- 处理一个文档时,只保留文件路径,省略具体内容。后续用`cat`或`tail`命令按需读取。
- 对于长输出,只记录其保存的路径,而非内容本身。
这种方式确保了信息并未真正丢失,只是被转移到了一个随时可以访问的“外部硬盘”里。同时,框架也鼓励智能体主动将中间结果写入文件。例如,将复杂查询的结果保存到`output.log`,然后在上下文中只留下一句:“结果已写入 /tmp/query_result.json”。后续可以通过`head`、`grep`等命令渐进式查看,既减少了上下文占用,又保留了信息的完整性。
(b) 检索:推理前检索 vs. “即时”检索
早期的智能体多依赖RAG(检索增强生成)这类“推理前检索”方式:预先将知识库向量化,在推理前检索相关片段。但像Manus、Claude Code这样的新锐框架,选择了一条不同的路:弱化甚至抛弃复杂的RAG,转而让LLM自己生成搜索命令,像人类一样主动探索文件系统或代码库,即“即时检索”。
为什么要弱化RAG? 根本原因在于其复杂性。RAG涉及文本分块、嵌入模型选择、相似度计算等多个环节,任何一个步骤的偏差都会影响最终效果。对于代码、非结构化数据(如PDF、图片),RAG的处理也往往不尽如人意。
从Claude Code等顶级框架的设计中,我们学到的是“保持简单”的哲学:把复杂的检索逻辑交给模型本身,框架只提供最基础的工具(如`grep`、`find`、`jq`)。
“即时”检索的优势在于其灵活性和渐进性。智能体可以根据当前需求,动态生成复杂的Bash命令(如使用精细的正则表达式进行`ripgrep`搜索),无需将海量数据加载进上下文。这模仿了人类的认知方式——我们并非记住所有信息,但知道在需要时如何去查找。这种方式不受预建索引的限制,始终能反映最新状态,并且在调试等场景下,可以像人类一样层层深入,逐步定位问题。
(2)上下文摘要
“他们沉回了来时的大地。而他们的孩子则被留了下来,对黄金时代—— 时间出现前的那个时代,只剩模糊的记忆。” ——《人之涛》,刘宇昆
当上下文窗口即将耗尽,且无法再进行“可逆”的紧凑化时,就不得不采用最后的手段:摘要化。这是一种有损压缩,将漫长的对话历史浓缩成一段概要,从而释放空间。
这必然会导致信息的模糊和丢失——模型再也无法访问某一行精确的代码或某个工具输出的完整内容。因此,摘要化只能是迫不得已时的最后选择。而且,它必须设计成“可恢复”的。
具体的做法是,在生成摘要前,先将完整的对话历史转储到一个持久化文件(如JSONL格式)中。这个文件就像一个“黑匣子”,保存了所有原始信息。当智能体在后续对话中发现摘要里缺少关键细节时,可以通过`grep`或`Read`工具主动去这个历史文件中检索,找回丢失的片段。同时,为了保持对话的连贯性,通常还会保留最近几次完整的工具调用和结果,让模型知道自己从哪里中断,避免因上下文重置而“失忆”。

那么,如何选择策略呢?一个基本原则是:优先使用可逆的紧凑化(如写入文件,只留路径)。只有当紧凑化无法进行,且上下文确实即将溢出时,再启用带完整备份的摘要化。两者结合,理论上能让智能体在有限的上下文窗口内,处理无限长的任务流程。
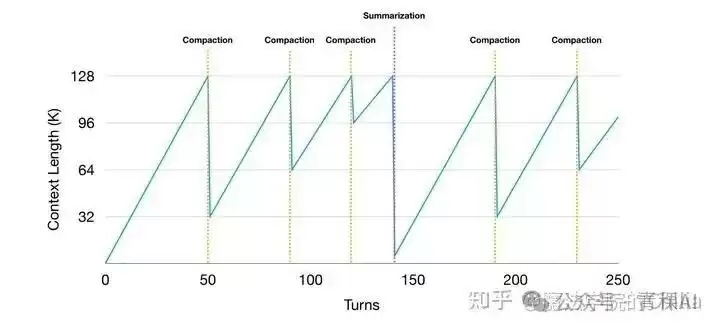
以Claude Code为例,其压缩机制会在两种情况下触发:一是系统监控到token使用量接近上限时自动触发;二是用户手动输入`/compact`命令。压缩后,旧的对话历史被一段结构化的摘要所替代,摘要会清晰列出之前的核心请求、关键技术概念、涉及的文件、遇到的问题及解决方案等。而所有原始对话,则被完整地保存到了本地的JSONL文件中,以备随时查阅。

(3)上下文隔离(多智能体架构)
面对一个庞大复杂的任务,另一个思路是“分而治之”:由主智能体协调多个专门化的子智能体来并行或串行处理子任务。
每个子智能体都运行在自己独立的、干净的上下文窗口中,拥有独立的系统指令和工具权限。主智能体根据任务描述,决定将任务委托给哪个子智能体。这种架构带来了多重好处:
- 节省主上下文:子智能体深入的探索和产生的冗长输出都局限在其自身上下文中,不会污染主对话。它只向主智能体返回精简的摘要或结果。
- 权限控制:可以严格限制子智能体的工具权限。例如,可以创建一个只拥有读取权限的“探索者”智能体,专门用于安全地分析代码库。
- 领域专业化:为不同任务定制专门的系统提示词,提升任务完成质量。例如,有的子智能体擅长代码规划,有的擅长具体修改。
- 节约成本:可以将简单的子任务路由到更快、更便宜的模型上执行,而让主智能体或处理复杂任务的子智能体使用更强大(也更昂贵)的模型。
这种架构对上下文管理的核心贡献在于“隔离”。每个子智能体的“内存”是独立的,主对话的上下文不会被其繁杂的中间过程所拖累。例如,让一个子智能体去运行会产生大量日志的测试任务,详细的输出留在子上下文中,主对话只接收最终的成功/失败状态和关键错误信息。
子智能体的运行模式可以分为前台(阻塞式)和后台(非阻塞式),调用关系可以是并行(同时分析多个模块)或链式(一个接一个顺序执行)。Claude Code的设计体现了极简主义:当需要分解任务时,主智能体简单地生成自己的一个“克隆”作为子智能体去执行,子智能体完成后将结果以工具响应的形式返回。同时,主智能体内部维护一个TODO列表,始终聚焦于最终目标。

(4)上下文缓存
什么是 KV Cache?
Transformer模型在生成每个token时,都需要基于之前所有token计算出的Key和Value向量。KV Cache就是将这些中间计算结果缓存起来。当新的请求包含相同的前缀时,可以直接复用缓存,避免重复计算,这能极大提升生成效率并降低成本。
名词解释:Prefill(预填充)
预填充是模型在生成第一个输出token之前,对所有输入token进行并行处理的阶段。在此阶段,模型计算每个输入token的Key和Value向量,构建用于后续解码的KV Cache。
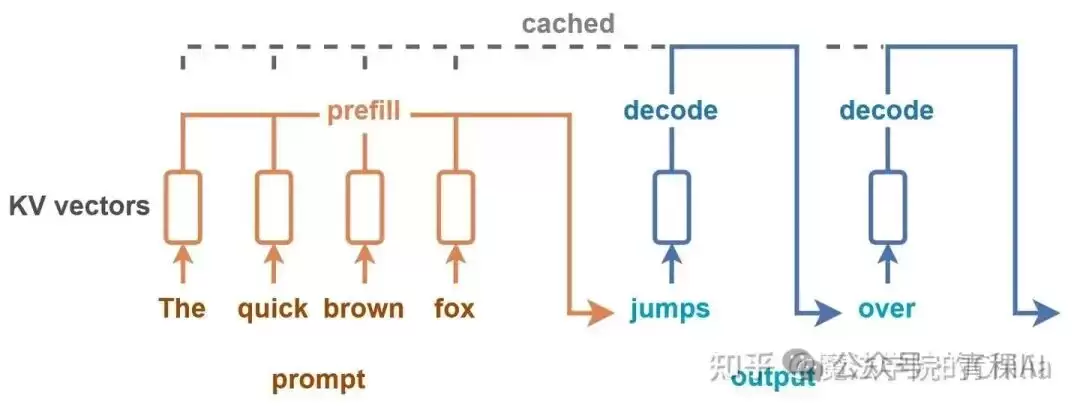
为什么缓存对智能体至关重要?
智能体的工作流是多轮工具调用的循环,导致输入上下文很长,而每轮的输出相对较短。统计显示,智能体的输入输出token比可能高达100:1。这意味着每次推理的大部分计算都花在了处理历史上下文上。如果没有缓存,每一轮都要从头计算所有历史token,延迟和成本都将难以承受。
KV Cache通过复用相同前缀的计算结果来解决这个问题。只要请求的前缀与缓存内容完全一致,就能命中缓存,大幅降低首字延迟和调用成本。以Claude Sonnet模型为例,命中缓存的输入token成本仅为未缓存情况的十分之一。
KV缓存的工程实践
缓存命中的关键在于请求前缀的绝对稳定性。哪怕多一个空格、换行符,或者JSON键的顺序不同,都会导致缓存失效。因此,核心设计原则是:上下文只追加,不修改。避免在系统提示开头插入时间戳、会话ID等可变内容。如果需要修正历史,就添加新的消息,而不是修改旧消息。同时,要确保序列化(如JSON转换)的确定性,保证相同内容总是产生相同的字符串。
以Claude Code为例,它支持自动缓存和手动缓存两种模式。自动缓存通过API请求中的`cache_control`字段开启,系统会自动将最后一个可缓存的内容块作为断点。手动缓存则允许开发者对极其稳定的内容(如系统提示、工具定义)设置显式缓存断点,确保其被优先缓存。两者结合,可以最大程度地提升缓存命中率,为长对话智能体提供性能和成本的双重保障。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
