




跟着Karpathy构建AI第二大脑实现高效知识管理

跟随AI专家Karpathy的思路,构建一个真正可用的“第二大脑”,或许能彻底终结那些半途而废的知识管理项目。关键在于,让AI承担最繁琐的维护工作,解放你的精力。
这套方法论的核心可归纳为三点:首先,识别传统知识管理工具的真正痛点在于高昂的维护成本;其次,采纳Karpathy提出的三区划分法——素材区、知识区和规则文件;最后,通过Obsidian与Claude Code的极简组合,快速搭建并实现自动化运维。

简而言之,就是结合Karpathy的架构理念与Obsidian、Claude Code这两款工具,五分钟内搭建好框架,后续的整理、关联与维护全部交由AI智能处理。
此前,AI领域的顶尖研究者Karpathy在社交媒体上详细分享了他如何利用大语言模型维护个人知识库,引发了广泛关注。阅读他的分享后,第一感受并非惊叹于方案的巧妙,而是感到一丝共鸣——因为电脑里同样躺着数个早已荒废的知识库项目。从ima到NotebookLM,再到Obsidian,每一个都始于热情,最终却悄无声息地沉寂。
这种经历,相信许多致力于个人知识管理的人都曾有过。
项目烂尾的根源:难以承受的维护成本
过去我们常将此归咎于个人不够坚持。但深入思考后会发现,问题根源并非全在意志力。
使用ima这类一体化工具,记录和初步整理固然便捷,但知识往往被禁锢在其封闭生态内。一旦需要跨平台使用,或让其他AI助手读取你的积累,几乎难以实现。更换平台,意味着一切从零开始。
NotebookLM这类基于RAG(检索增强生成)的工具,在每次查询时表现智能,但其本质是实时检索你的原始文档。它不会主动将零散知识点串联成结构化体系,更无法在不同文档间自动发现潜在关联。使用完毕后,往往没有沉淀下实质性的、可复用的知识资产。
至于Obsidian,其革命性的双向链接功能是一把双刃剑。文件一旦重命名,相关链接便会断裂。一次笔记整理,常常伴随着大量断裂链接的修复工作,重复几次后,打开笔记库的意愿便消耗殆尽。
这些工具本身各具优势。核心矛盾在于:整理与维护所耗费的时间精力,常常超过了记录与思考本身。 试想,如果一个系统要求你每次使用后,都得花费大量时间进行“保洁”,你能坚持多久?坚持规律健身已属不易,更何况是持续为笔记做“家务”。
因此,许多人的“第二大脑”并非主动放弃,而是被日积月累、不堪重负的维护成本所拖垮。
Karpathy的解决方案:让AI成为知识库的维护者
作为OpenAI创始成员与前特斯拉AI总监,Karpathy的解决方案异常清晰:将维护工作交给AI,你只需专注于输入有价值的内容。
他公开了一份详细的规则文档,将个人知识库清晰地划分为三个功能区域:
第一区是素材区(raw/)。 所有阅读的文章、零散的灵感、任何原始资料,都可以直接存入此区。此区域为只读,AI不会改动原始材料,确保了源文件的完整性。
第二区是知识区(wiki/)。 这是由AI自动生成并维护的Wiki页面集合。每个核心概念都拥有独立的页面,并且页面之间会自动建立智能链接。这部分完全交由AI管理。
第三区是规则文件(claude.md)。 这是整个系统的“宪法”,它明确指导AI如何组织知识、打标签、处理信息冲突。相当于你为AI助手撰写的一份详尽操作手册。
日常操作被简化为三类:录入新素材、查询已有知识、定期执行系统健康检查与修复。
此设计的精妙之处在于明确的分工:人类负责创造性输入(贡献素材与灵感),AI负责系统性的整理、链接与维护。那些曾经令人望而却步的琐碎工作——打标签、建立关联、修复断链、更新分类——全部变成了AI的自动化日常任务。
极速搭建方案:Obsidian + Claude Code
所需工具仅有两款:Obsidian 和 Claude Code。
Obsidian 充当“前端展示器”——你在此浏览AI整理好的Wiki页面,并通过图谱视图直观洞察知识网络。Claude Code 则作为“后端执行引擎”——它负责读取原始素材、创建知识页面、维护链接、执行健康检查等所有后台任务。
搭建过程简单到只需三步:
- 在 Obsidian 中新建一个知识库(即新建一个文件夹)。
- 用 Claude Code 打开这个文件夹。
- 将 Karpathy 公开的规则文档(其Gist链接内容)粘贴给 Claude Code。
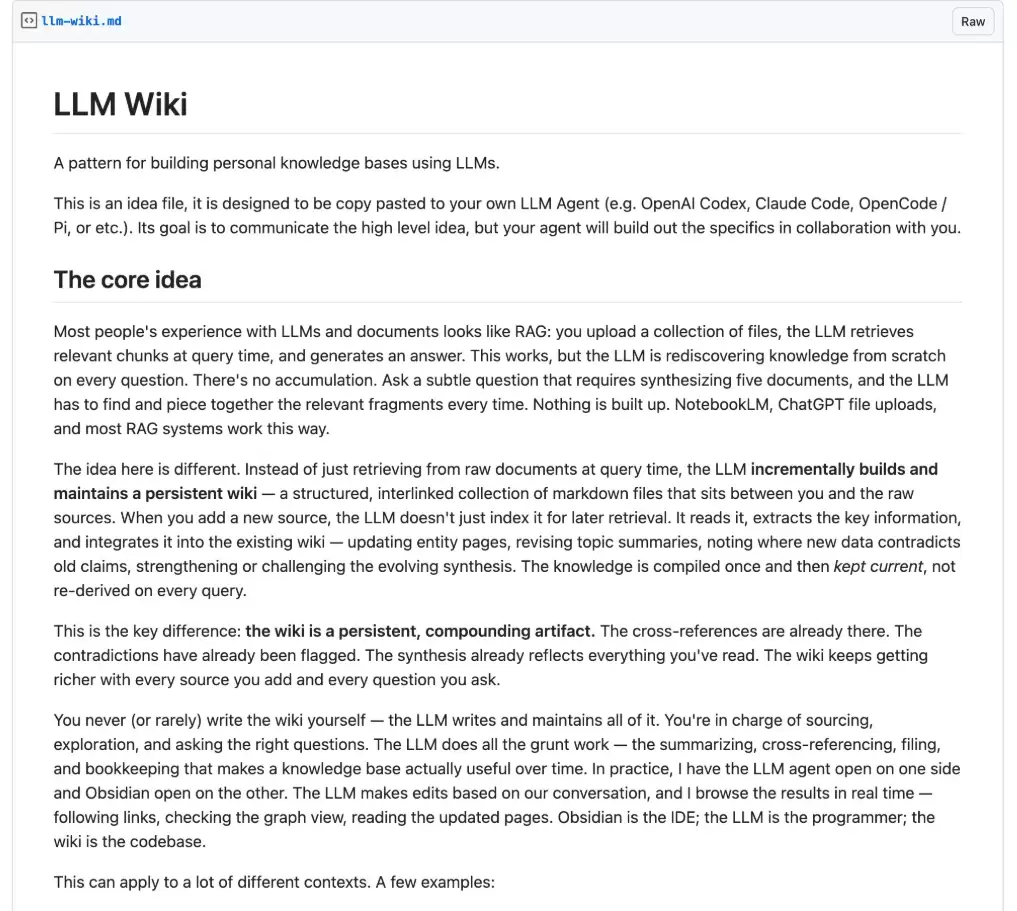
Claude Code 运行约一至两分钟后,便会自动创建完整的目录结构:raw/ 文件夹存放原始素材,wiki/ 文件夹存放整理后的知识页面,同时生成 index.md(索引)、log.md(操作日志)和 overview.md(概览)等核心文件。
这里有一个关键细节:它构建的不仅是一套空文件夹,更是一套完整的操作规范。每个页面该如何撰写、使用何种格式、如何打标签、怎样互相链接,所有这些规则都内置于规则文件中。这意味着,无论未来存入何种素材,AI都会依据同一套高标准进行整理。一致性由规则保障,而非依赖人的记忆。

至此,一个空的Wiki骨架便搭建完成。接下来,才是见证它“活”起来的时刻。
首次录入体验:超越预期的智能自动化
框架搭建完成后,尝试向素材区投入第一篇文章,然后对 Claude Code 简单发出指令:“请帮我录入。”
随后发生的过程,确实超出了预期。
它并非简单生成一段摘要。而是先深度理解全文,然后开始智能拆解——提取文章中的每一个核心概念,并为它们分别创建独立的主题页面:
- 一个关于“第二大脑”的主题页,深入分析了其常见的失败原因。
- 一个关于“LLM Wiki”的主题页,详细拆解了三层架构与三种操作模式。
- 一个关于 Karpathy 本人的介绍页。
- Obsidian 和 Claude Code 也各自拥有了专属页面,明确了它们在此方案中的角色定位。
- 甚至从素材中提炼出了三个潜在的写作选题创意页。
- 还有一个受众画像页,描述了可能对此类内容最感兴趣的人群特征。
仅凭一篇文章,就在wiki区催生出了十几个互相关联的智能页面。所有页面之间都自动建立了双向链接。点击“LLM Wiki”页面,可以看到它链接到Karpathy、Claude Code、Obsidian;反之,点击Karpathy的页面,又能链接回LLM Wiki和原始素材。
而这一切,仅源于一句“帮我录入”的指令。
更有趣的是,当投入第二篇素材后。新生成的页面开始与之前的页面自动产生连接——两篇看似不相关的文章,因为共同提及的概念而被AI智能关联。在Obsidian的图谱视图中,知识点之间开始出现交叉连线。这些连接并非事先预设,完全是AI自主发现并建立的。
仅两篇素材,便能观察到知识网络的初步雏形。可以想象,当投入五十篇、一百篇高质量素材后,这张知识图谱将会变得何等丰富与深邃。
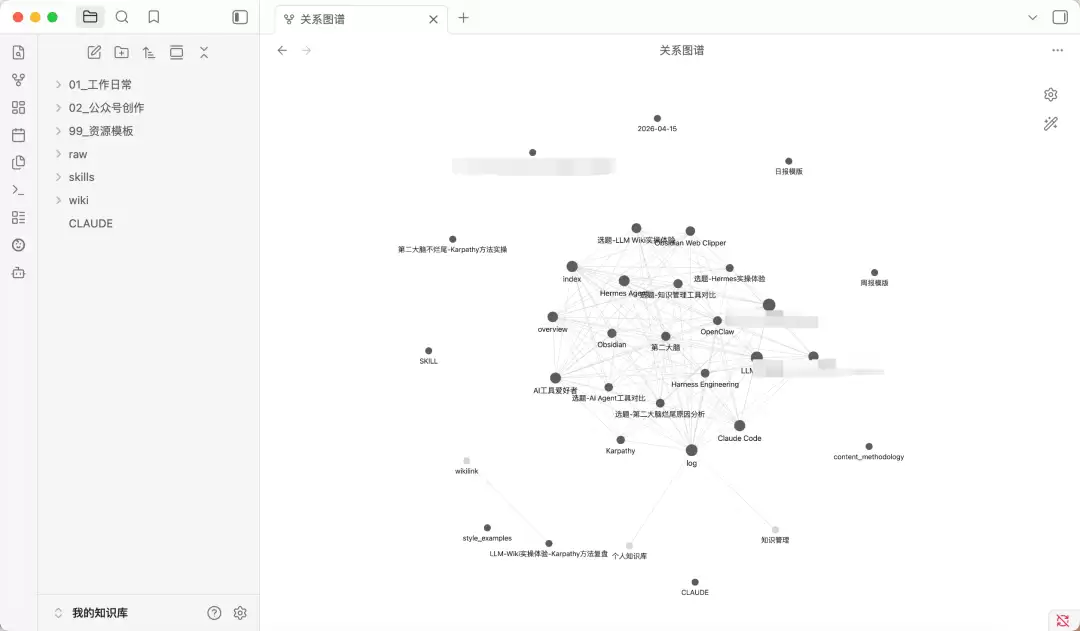
这种跨素材的智能交叉引用,若由人工完成,需要对所有旧内容了如指掌。但对AI而言,这几乎不费吹灰之力。
当你打开Obsidian的图谱视图,便会立刻理解这套方案与传统笔记的本质区别。你看到的不是一堆孤立文件的集合,而是一张动态生长、彼此紧密关联的知识网络。每个节点都与其他节点存在智能联系,而这些关系,是AI替你洞察和构建的。
健康检查功能:为知识库聘请“专属管家”
传统的“第二大脑”为何最终走向沉寂?往往因为标签陈旧无人更新,链接断裂懒得修复,结构需要优化时已无心力。久而久之,信息的信噪比持续降低,直至失去打开的欲望。
Karpathy的方案中,有一个至关重要的操作称为“健康检查”,专门应对此问题。
你只需对Claude Code说一句“请检查一下wiki的健康状况”,它便会全面扫描知识区,找出所有“亚健康”迹象:是否存在页面间观点互相矛盾?有没有无人引用的“孤儿页面”?是否存在被频繁提及但尚未建立独立页面的重要概念?是否有已被新信息推翻的旧内容仍然留存?
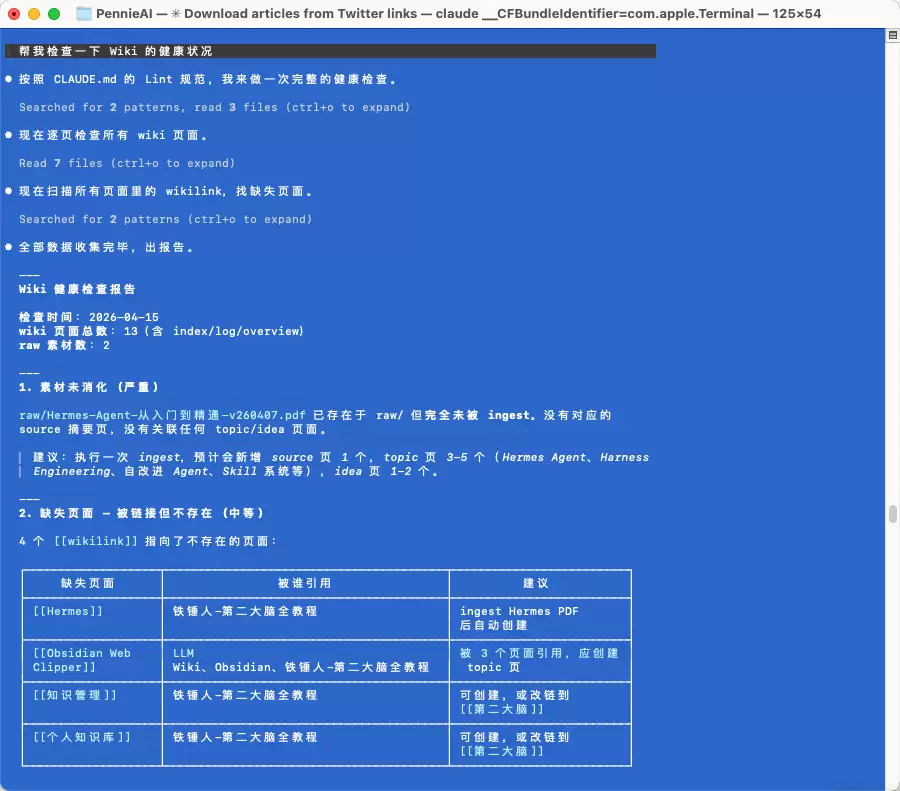
检查完毕后,它会生成一份详细的诊断报告。经你确认,它便能自动修复其中大部分问题。
你甚至可以设置每周自动执行一次健康检查。这相当于为你的知识库聘请了一位永不疲倦、细致入微的“专属管家”。
可以说,这才是整套方案真正改变游戏规则之处。搭建容易,录入也不难,但实现维护的全面自动化,才是根治知识管理“烂尾病”的核心。以前的第二大脑死于维护,而现在,维护工作已无需你亲力亲为。
超越效率提升:思维模式的根本转变
如果仅用它来记笔记,可能只发挥了其十分之一的潜力。
更具价值的用法,是将其作为所有AI工具的“个性化背景知识库”。知识区中的索引文件记录了所有页面的标题与摘要。你可以将此文件提供给任何AI助手,它便能基于你长期积累的、个性化的知识体系来回答问题。与AI对话不再需要每次都从零开始提供上下文,它能直接理解你的知识背景与偏好。
你还可以在其中存放互联网上无法搜到的独家内容——你个人的思考碎片、项目复盘、对特定问题的判断逻辑。这些才是你最独特、最具价值的知识资产。当AI能够持续学习这些内容,它会越来越像一个真正懂你、理解你思维模式的合作伙伴。
使用一段时间后,最大的改变可能不仅是效率的提升,更是心态的彻底转变。
这是第一次真切感受到,“第二大脑”不是在持续消耗我的精力,而是在真正地为我创造精力、节省心力。
你需要做的唯一决策是:判断一篇文章或一段信息是否值得录入系统。剩下的所有事情——分类、关联、摘要、维护——都交给了AI智能体。
当维护不再是沉重的负担,你就不会抗拒向系统中添加内容。不抗拒,才能持续。持续,才会产生强大的知识复利效应。
如何判断自己是否需要这套系统
坦诚而言,这套系统并非零门槛。它需要你能够使用Claude Code,并且在素材积累的初期,知识网络会显得相对单薄。
但不妨换个角度思考:如果不搭建这样一个系统呢?结果可能是,每次与AI对话仍需从头交代背景,读过的好文章90%在关闭标签后便彻底遗忘,每隔几个月又心血来潮尝试新的笔记方法,然后再次陷入“开始-废弃”的循环。
如果你愿意尝试,只有一个核心建议:切勿追求一步到位。 先新建一个空的仓库,录入最近读过的、你认为最有价值的三篇文章即可。当你亲眼看到知识图谱开始出现结构,自然会产生添加更多内容的动力。
知识库是越用越厚的。每增加一篇优质素材,后续所有的查询和输出质量都会提升一点点。这是一个清晰可见的正反馈循环。
现在,就可以新建一个仓库,贴入规则文档,录入你的第一篇文章。整个过程大约只需五分钟,之后,你便拥有一个能够自我成长、自动维护的鲜活知识库了。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
