




RAG技术还有发展前景吗DeepSeekV4百万上下文解析

百万级上下文长度,这一技术指标终于从实验室的演示品走向了实际应用。DeepSeek V4不仅实现了这一目标,更关键的是,它将处理成本大幅降低至上一代模型的十分之一。这意味着,将整部《红楼梦》原文、所有脂砚斋批注、数篇相关学术论文以及一个完整的代码项目库,全部输入给模型,并让它精准定位你所需的信息,已从一种技术炫技转变为可日常使用的实用功能。
支持超长上下文本身并非新鲜事,Gemini和Claude等模型也早有宣称。但DeepSeek V4真正的突破在于成本控制:它将处理百万tokens的推理成本压缩到了V3.2版本的十分之一。具体而言,其KV缓存仅需原来的10%,而处理单个token所需的计算量(FLOPs)更是降低了73%,降至原来的27%。成本门槛的急剧降低,才是技术从“理论上可行”迈向“实际好用”的关键转折点。
传统处理方案的局限性
在V4问世之前,处理超长文本主要依赖两种路径,但它们都存在明显的缺陷。
第一种是直接扩展上下文窗口。 这种方法简单粗暴地增加模型可处理的序列长度。但随之而来的问题是:KV缓存会随着序列长度线性增长,导致模型在推理后期,每生成一个新token都需要“背负”前面所有token的记忆负担,计算开销呈指数级上升。Gemini 1M和Claude的扩展上下文功能本质上采用了这种思路,成本高昂,难以实现规模化商业应用。
第二种是检索增强生成(RAG)。 既然无法一次性处理全部信息,便退而求其次,先从外部知识库中检索出最相关的文档片段,再输入给模型。这几乎是当前企业级AI应用的标准解决方案。然而,RAG存在一个根本性的天花板:其最终效果的上限完全受制于检索系统的质量。你永远无法确保,检索返回的那几个片段是否真正包含了解决问题所需的全部关键信息。
这两条路径都非完美解决方案。核心矛盾始终存在:如何让模型获取完整信息,同时又不让计算成本失控?
DeepSeek V4 的解决方案:压缩注意力机制,而非压缩信息本身
V4的答案颇具巧思:它没有选择压缩输入的原始信息,而是创新性地设计了一套混合注意力架构,对模型内部的“注意力”计算过程进行高效压缩。
第一种策略称为CSA(压缩稀疏注意力)。 其思路非常直接:并非所有历史token都需要被完整、平等地记忆。具体实现是,先将每4个token的KV缓存压缩合并成1个,形成一个高度概括的“压缩版”记忆库;随后,通过稀疏注意力机制,从这个压缩后的记忆库中精准筛选出最相关的部分进行后续计算。这相当于先进行信息浓缩,再进行精准提取,通过两道工序显著降低计算量。
第二种策略称为HCA(重度压缩注意力)。 这种方式更为激进,每128个token才被压缩成1个。但在压缩之后,它不再进行精细的筛选,而是对压缩后的整体信息进行全量的注意力计算。这适用于那些只需要了解大致背景、无需深究细节的远距离上下文信息。
V4的聪明之处在于,它并非在两种策略中二选一,而是让它们交替协作:CSA负责那些需要精细分析和处理的网络层,HCA则接管那些可以进行粗略处理的层。此外,模型还引入了一个滑动窗口注意力分支,专门用于处理局部紧密的依赖关系。三个分支协同工作,共同构成了V4高效且完整的注意力解决方案。
实际效果如何?数据最具说服力。在处理长达100万token的上下文时,DeepSeek V4-Pro模型处理单token所需的计算量仅为V3.2的27%,KV缓存更是只需10%。而更小尺寸的V4-Flash版本表现更为惊人:计算量只有V3.2的10%,KV缓存仅需7%。效率提升是实实在在、可量化的。
性能实测:开源模型首次在关键领域比肩闭源巨头
仅有架构创新是不够的,实际性能表现才是最终的试金石。
在知识问答能力方面,V4在SimpleQA Verified基准测试中取得了57.9%的准确率,这比所有其他开源模型高出20个百分点以上。当然,与Gemini 3.1 Pro的75.6%相比仍有差距,但差距正在显著缩小。
在长上下文核心能力评测上,V4-Pro-Max在百万token级别的MRCR信息检索任务中,取得了83.5%的MMR得分,成功超越了Gemini 3.1 Pro的76.3%,尽管仍略低于Claude Opus 4.6的92.9%。
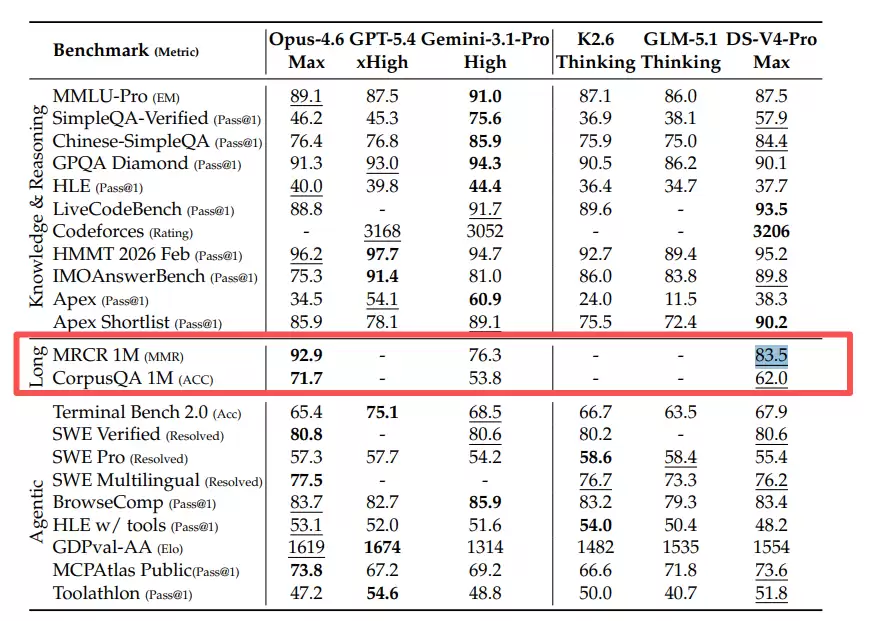
更值得关注的是V4-Flash的表现。它的总参数量仅为284B(激活参数量13B),比V3.2模型小得多,但在大多数基准测试上已经超越了V3.2-Base版本。这有力地证明,性能的提升主要源于架构设计带来的效率飞跃,而非简单地堆砌模型参数。
对RAG技术生态的深远影响
一个随之而来的关键问题是:检索增强生成(RAG)技术还有未来吗?
答案是:RAG不会消失,但它的角色和定位将发生根本性的转变。
当百万token上下文的处理成本降至可日常承受的水平时,大量原本必须依赖检索才能处理的场景,现在完全可以将整个文档库直接输入模型上下文。DeepSeek自身的测试数据显示,在信息搜索场景中,采用智能体搜索(Agentic Search)模式——即让模型直接在超长上下文中进行查找和分析——其效果胜率比传统RAG方案高出61.7%。
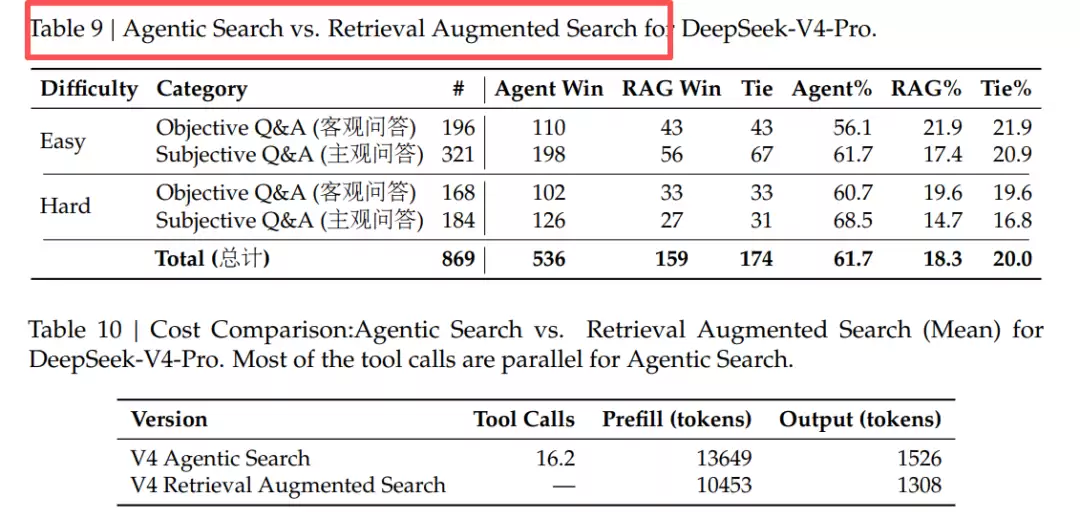
但这并不意味着RAG会彻底失去价值。在那些需要对比多个独立信息源(例如不同产品的参数对比、综合性的内容推荐)的任务上,RAG依然具备其独特优势。更重要的是,当需要处理的数据规模远超百万token,例如面对企业级的海量历史文档库时,“先检索、后处理”的范式仍然是唯一可行的技术路径。
真正受到冲击的,是过去那个因成本限制而存在的“尴尬中间地带”:那些长度适中、过去不得不被切分成碎片进行检索处理的文档,如今可以被完整地、原汁原味地交给模型进行端到端深度分析。
对开发者与产品应用的现实意义
任何技术突破最终都要落实到应用层面。成本的大幅降低将直接引发以下几类应用场景的质变:
首先,长文档深度分析将从“高端定制”变为“标准配置”。 法律合同审查、学术论文解读、长篇企业财报分析……这些以往需要人工分段处理、再拼接整合结果的场景,现在有望实现端到端的一次性、连贯性深度处理,极大提升效率和准确性。
其次,代码智能助手(Code Agent)将变得更加实用和强大。 DeepSeek内部测试表明,V4-Pro-Max在真实研发任务上的通过率达到了67%,已非常接近Claude Opus 4.5的70%。在一项针对85名内部开发者的调研中,超过半数(52%)的开发者表示愿意将其作为主力代码辅助模型使用。
最后,复杂的多步骤、长链条任务成为可能。 百万token的上下文容量,结合完整的对话历史保留能力,意味着AI智能体可以在极长的多轮对话中始终保持连贯的思维链条和记忆。它不会再像过去那样,每轮对话都近乎“重启”,丢失之前的推理和规划过程。这对于需要复杂规划、多步骤拆解和长期状态维持的智能体应用而言,无疑是一次巨大的能力解放。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
