




函数计算AgentRun知识库上线,智能体更懂你

阿里云函数计算AgentRun全新知识库功能重磅上线,助力智能体深入理解业务需求,实现精准响应与高效交互。
先说几个核心判断:
1. 知识库功能有效解决了传统智能体缺乏专业领域知识的痛点
2. 深度解析百炼与RAGFlow双知识库引擎的技术实现与配置方法
3. 提供三种灵活集成方式,全面满足不同开发场景需求
阿里云函数计算 AgentRun 正式推出全新知识库功能,为AI智能体注入更强的语义理解与上下文感知能力。通过深度集成百炼知识库与 RAGFlow 知识库,AgentRun 使开发者能够轻松构建具备领域知识的智能应用,真正实现“更懂用户、更贴场景、更高效响应”。
智能体为何需要知识库?
在传统智能体开发中,模型通常依赖通用训练数据,缺乏对特定业务、私有文档或实时信息的理解能力。这导致其在面对专业领域问题、企业内部知识或个性化需求时表现受限。
AgentRun 知识库功能正是为解决这一痛点而设计——它将外部知识源无缝接入智能体运行流程,通过检索增强生成(RAG)技术,让智能体在回答问题、执行任务时动态调用相关知识,大幅提升准确性、专业性与可信度。
双引擎支持:百炼+RAGFlow,覆盖多元知识形态
▍百炼知识库绑定
函数计算 AgentRun 可以绑定您账号下已创建的阿里云百炼知识库。
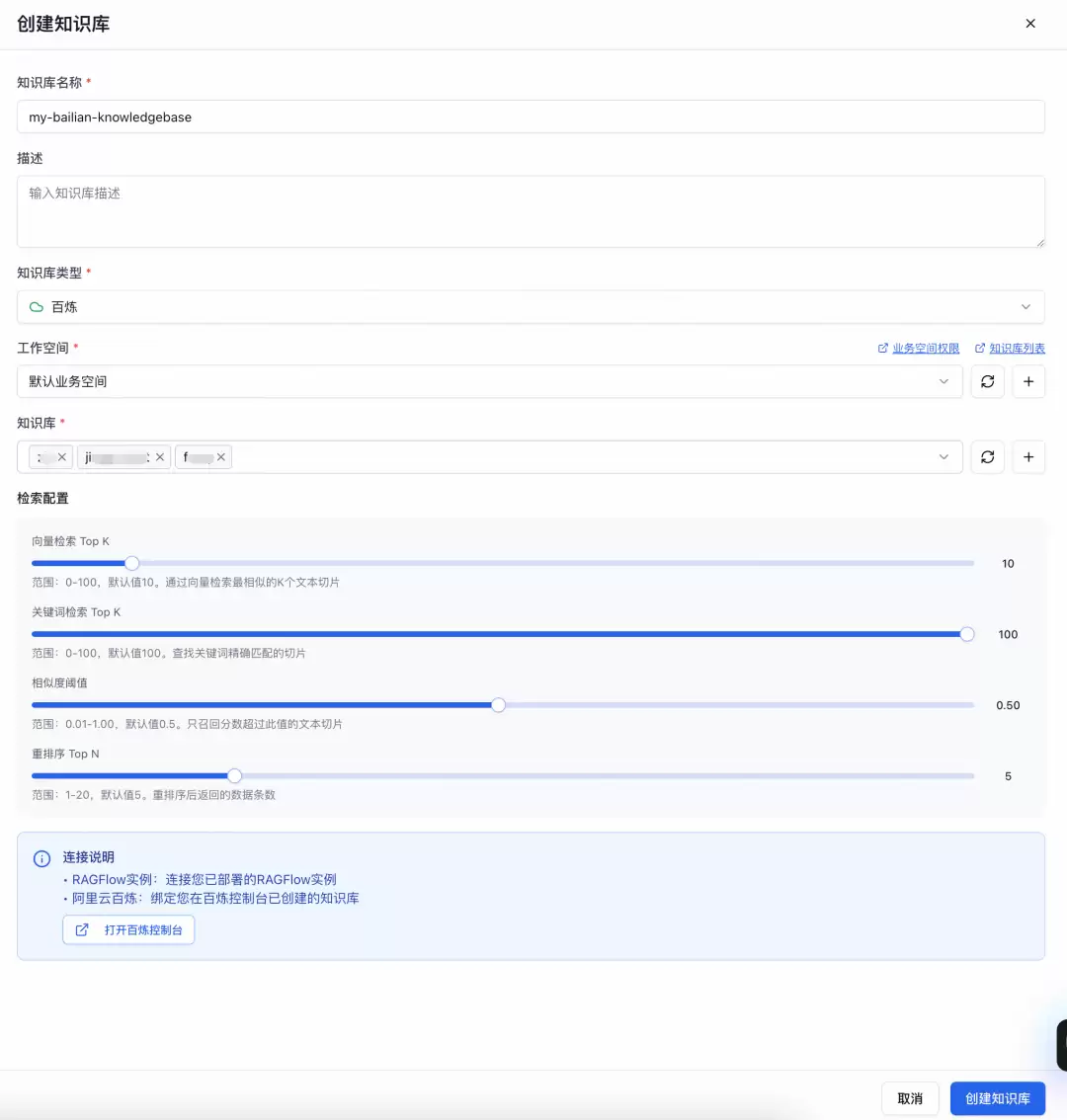
进入创建页面,输入知识库名称、描述,选择知识库类型为“百炼”,可多选绑定您账号下已在阿里云百炼控制台创建好的多个知识库。填写检索配置后,点击创建知识库,即可将您的阿里云百炼知识库绑定至AgentRun平台。
▍RAGFlow知识库绑定
函数计算 AgentRun 可以绑定您账号下已创建的RAGFlow知识库。如果您还没有RAGFlow知识库,可以在SAE上快速部署创建。
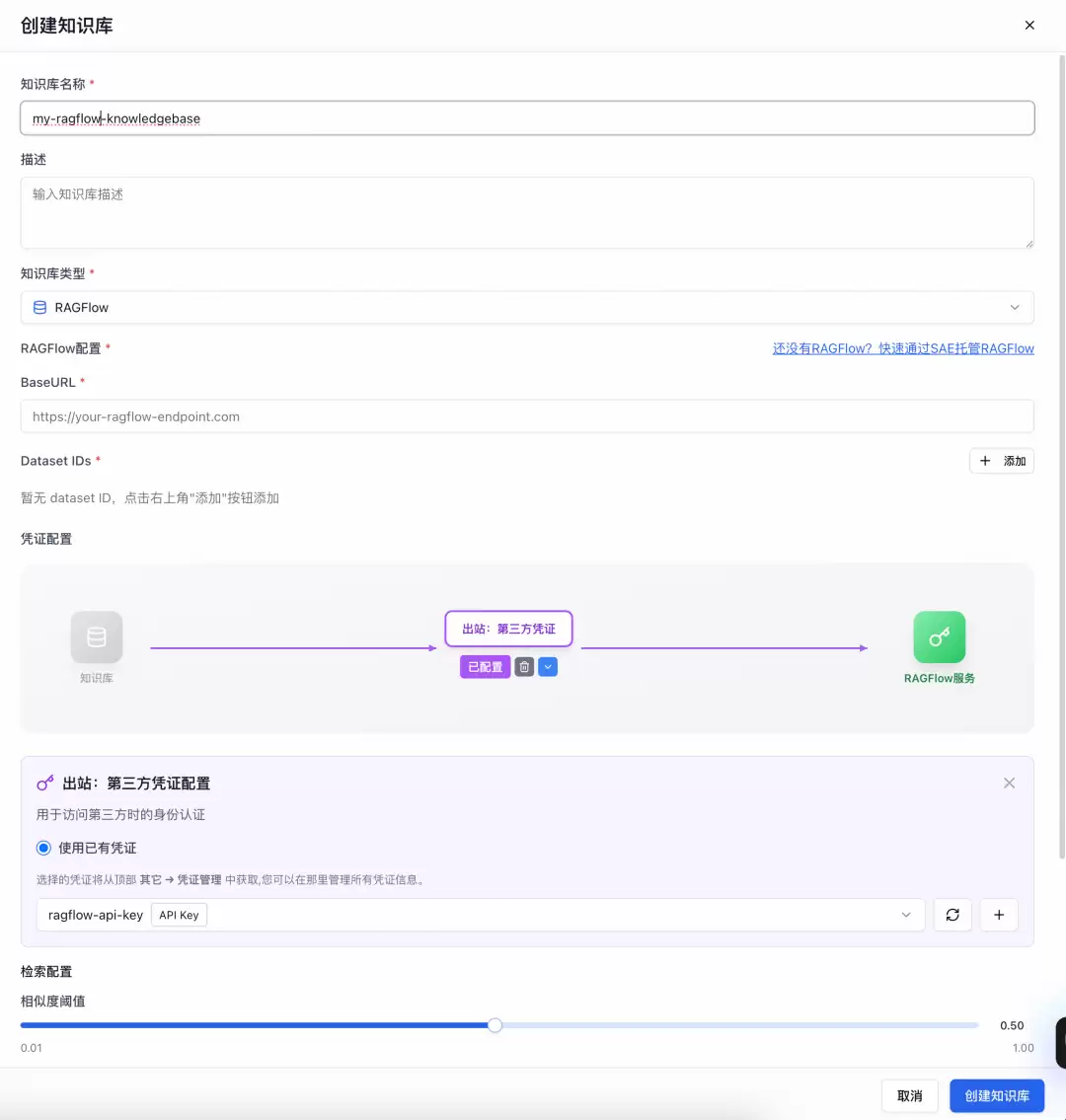
进入创建页面,输入知识库名称、描述,选择知识库类型为“RAGFlow”,填写您已部署RAGFlow的BaseURL、Dataset IDs和API-KEY(将其保存在凭证中)。填写检索配置后,点击创建知识库,即可将您自建的RAGFlow知识库绑定至AgentRun平台。
三大集成方式,灵活适配各类开发场景
函数计算 AgentRun 知识库功能支持快速创建集成、代码集成和MCP集成三种方式,满足不同技术栈和开发习惯。
▍快速创建Agent集成知识库功能
对于希望快速验证想法或加速产品迭代的团队,AgentRun提供了低代码、可视化的知识库绑定能力。开发者只需登录AgentRun控制台,选择已创建的百炼或RAGFlow知识库,将其关联到目标智能体,并配置简单的检索参数(如返回结果数量、相似度阈值等),即可完成集成——全程无需编写一行代码。
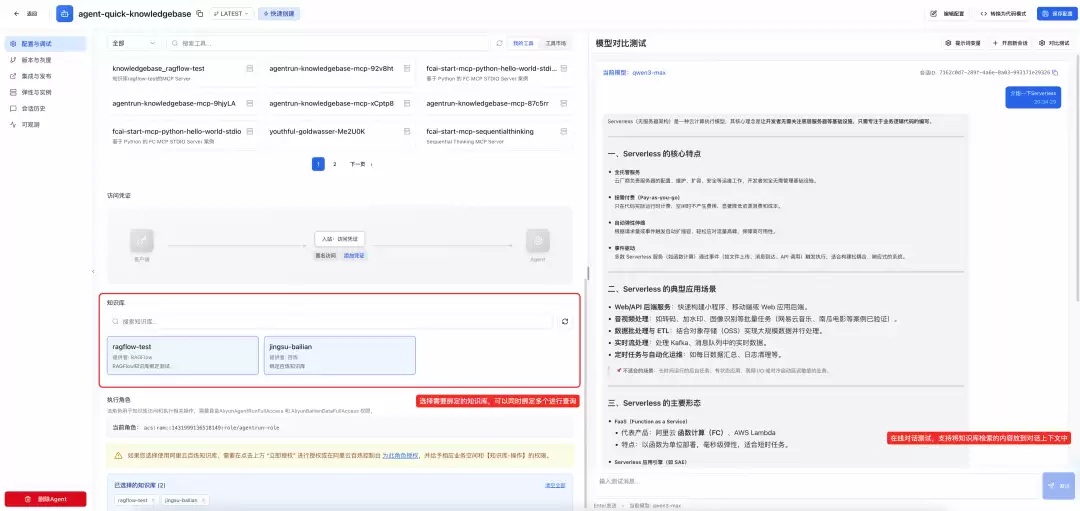
这一模式极大降低了技术门槛,让产品经理、运营人员甚至非技术背景的创新者也能参与智能体的构建与优化。无论是搭建内部知识问答机器人、客户自助服务助手,还是快速验证某个垂直领域的AI应用场景,都能在几分钟内完成部署并上线试用。
▍代码集成知识库查询能力
对于追求极致灵活性与控制力的开发者,AgentRun提供了原生代码级知识库接入能力。您可以在代码逻辑中调用AgentRun SDK的知识库检索接口,根据业务上下文动态发起检索请求,精准筛选并注入最相关的信息片段到智能体的推理流程中。您可以使用AgentRun SDK,调用以下封装的接口,进行单知识库查询或多知识库查询。
from agentrun.knowledgebase import KnowledgeBase
## 获取单知识库,进行查询
knowledgebase = KnowledgeBase.get_by_name("ragflow-test")
single_kb_retrieve_result = knowledgebase.retrieve("")
print(single_kb_retrieve_result)
## 获取多知识库,进行查询,支持跨供应商知识库类型检索
multi_kb_retrieve_result = KnowledgeBase.multi_retrieve(
query="",
knowledge_base_names=["ragflow-test", ""],
)
print(multi_kb_retrieve_result)
同样,您可以集成LangChain框架,将知识库的查询能力集成在工具或上下文中。
"""AgentRun 知识库智能体集成代码示例
使用前,请参考相关文档配置好相应认证信息和环境变量
"""
import json
import os
from typing import Any
from langchain.agents import create_agent
import pydash
from agentrun import Config
from agentrun.integration.langchain import model
from agentrun.integration.langchain import knowledgebase_toolset
from agentrun.integration.langgraph.agent_converter import AgentRunConverter
from agentrun.knowledgebase import KnowledgeBase
from agentrun.server import AgentRequest, AgentRunServer
from agentrun.server.model import ServerConfig
from agentrun.utils.log import logger
# 请替换为您已经创建的 模型 名称
AGENTRUN_MODEL_SERVICE = os.getenv("AGENTRUN_MODEL_SERVICE", "")
AGENTRUN_MODEL_NAME = os.getenv("AGENTRUN_MODEL_NAME", "")
KNOWLEDGE_BASES = os.getenv("AGENTRUN_KNOWLEDGE_BASES", "ragflow-test").split(",")
if AGENTRUN_MODEL_NAME.startswith("<") or not AGENTRUN_MODEL_NAME:
raise ValueError("请将 MODEL_NAME 替换为您已经创建的模型名称")
## 加载知识库工具,知识库可以以工具的方式供Agent进行调用
knowledgebase_tools = []
if KNOWLEDGE_BASES and not KNOWLEDGE_BASES[0].startswith("<"):
knowledgebase_tools = knowledgebase_toolset(
knowledge_base_names=KNOWLEDGE_BASES,
)
else:
logger.warning("KNOWLEDGE_BASES 未设置或未替换,跳过加载知识库工具。")
agent = create_agent(
model=model(AGENTRUN_MODEL_SERVICE, model=AGENTRUN_MODEL_NAME, config=Config(timeout=180)),
tools=[
*knowledgebase_tools, ## 通过工具集成知识库查询能力
],
system_prompt="你是一个 AgentRun 的 AI 专家,可以通过查询知识库文档来回答用户的问题。",
)
async def invoke_agent(request: AgentRequest):
messages = [
{"role": msg.role, "content": msg.content}
for msg in request.messages
]
# 很多细节,包括知识库检索结果注入,都在这里处理
# 完整代码可参考AgentRun官方示例
注意:如果您选择了RAGFlow知识库,需要确保您的Agent运行环境和RAGFlow的BaseURL地址处于同一网络环境下,否则AgentRun SDK将无法调用RAGFlow的API实现查询能力。
通过代码集成,AgentRun赋予开发者“全栈可控”的能力——既享受函数计算的弹性与免运维优势,又保留对智能体认知过程的深度掌控,真正实现“知识为我所用,逻辑由我定义”。
▍MCP集成:将知识库检索作为Agent的工具调用
AgentRun知识库率先实现“Agentic RAG”(智能体RAG)模式——将传统静态检索升级为动态、可编程的智能体工具调用。具体而言,用户可一键将知识库发布为MCP,使其成为大语言模型(LLM)可主动调用的工具之一。在此模式下,LLM不再被动接收上下文,而是具备“工具使用能力”,在推理过程中自主判断何时调用RAG、数据库查询、库存检查等工具,并基于返回结果进行多步推理与任务分解。这种机制使RAG从单一检索功能转变为智能体工具箱中的灵活组件,与其他工具并列协作,显著提升复杂任务的处理能力。其工作方式更贴近人类“思考—行动—反思”的认知流程:模型先分析问题,制定计划,再按需调用多个工具获取信息,最终整合结果生成答案。
进入工具管理,在工具市场可以搜索到“AgentRun知识库MCP”工具模板,点击安装后,填写知识库名称和类型,即可将知识库的查询能力一键发布成MCP工具给大模型进行调用。
创建完毕后,点击工具详情,即可看到集成调用的工具地址。
基于MCP工具标准协议,AgentRun支持以标准化方式对接知识库服务,实现跨平台、跨模型的上下文注入能力,保障架构的开放性与可扩展性。
结语:从“能回答”到“真理解”,智能体正在拥有“知识之眼”
AgentRun知识库功能的上线,不仅是一次技术能力的升级,更标志着智能体发展迈入新阶段——从依赖通用语料的“泛化应答”,转向基于专属知识的“情境理解”。当智能体能够随时调用企业文档、行业规范、用户历史甚至实时数据,它便不再只是一个语言模型的接口,而成为一个具备领域认知、上下文记忆与决策依据的数字协作者。
未来,随着知识库的持续进化——支持多模态内容、动态更新、跨源推理——AgentRun将进一步降低构建“有知识、有逻辑、有温度”智能体的门槛。
可以确定的是,真正的智能,不在于模型有多大,而在于是否“懂你所需、知你所问、信你所依”。
AgentRun,正让每一个智能体,学会思考,更学会理解。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
