




买得起Token却难买到靠谱


ChatGPT引爆的AI浪潮走到第四年,一个新的概念悄悄火了起来——Token经济。
在AI的世界里,Token是语言处理的最小单位,类似于数字世界的“原子”。但今天,这个原本藏在技术文档里的术语,已经被市场明码标价,成了衡量AI价值的“基础货币”。
2026年5月,国内三大运营商不约而同地推出了“Token套餐”。中国电信9.9元包1000万Token,中国移动1元买40万Token,中国联通则把Token和手机宽带打包在一起。这意味着什么?以后你每一次用AI,消耗的每一个Token,都会变成账单上的数字。
价格是价值的度量衡。Token能卖钱,本身就说明它值钱。国家数据局发布的信息显示,截至2026年3月,国内日均Token调用量已经突破140万亿次——这个数字,相比2024年初的1000亿,增长了超过1000倍。摩根大通进一步预测,到2030年,中国AI推理的Token消耗量将从2025年的10千万亿跃升至约3900千万亿,五年暴增近370倍。
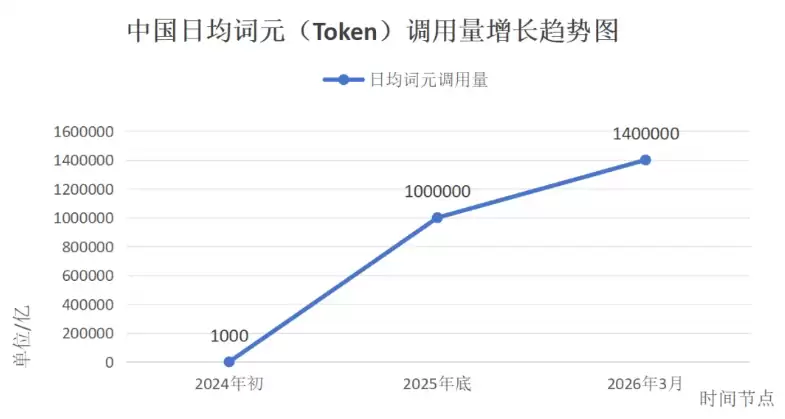
图源:国家数据网
这些数据说明一件事:人们对AI的需求太强烈了。AI算力被看作新时代的“水电煤”,而Token就是数字生活里最基本的那瓶水、那度电。它可以定价、可以计量,顺理成章地,产业链上也出现了明确的分工——谁负责生产,谁负责分发,谁负责消费,成本和利润变得清晰、可追溯。商业价值的逻辑,通了。
然而,光鲜的数字背后,藏着一些不那么光鲜的问题。每天140万亿次调用,到底用在了哪儿?真的解决了问题吗?还有,当你的每一次调用都被记录、每一笔Token消耗都变成数据,这张看不见的“网”,到底攥在谁手里?
最近,IDC Direction 2026 趋势论坛谈到了Token经济学下的这些趋势和思考,下面我们逐一梳理一下。
01、Token流向了哪里?
日均140万亿次调用量,听起来确实震撼。但这里面有多少是有效调用,多少是重复生成、无效请求,目前谁也说不清。
比起纯数字,更关键的是看谁在用、怎么用。
先看C端。根据QuestMobile的《中国移动互联网2026春季大报告》,截至2026年3月,AI原生App的月活用户规模已经达到4.4亿。其中,豆包、千问、DeepSeek领跑前三,月活分别为3.45亿、1.66亿和1.27亿。单季度新增了1.3亿用户。从活跃率和使用频次来看,豆包平均每月用54.8次,DeepSeek是41.7次,千问19.8次。
C端用户基数大,但绝大多数人可能只是用AI写个朋友圈文案、生成一张图、翻译一段话。这些场景消耗的Token看似频繁,单次用量其实很小。真正的消耗大户,在B端。
根据OpenRouter与a16z联合发布的百万亿Token实证研究报告,编程类任务已经从前一年的11%飙升至现在的50%以上。也就是说,超过一半的Token不是普通用户“聊”出来的,而是被开发者和企业嵌入工作流,用来自动写代码、跑测试、生成文档。这就引出了一个略带尴尬的现实:Token调用的指数级增长,与普通人生产力的提升之间,还存在明显的断层。
再看B端的另一头。一大部分Token被用在一个奇怪的循环里——人们花钱买来的算力,变成了训练下一代模型的“饲料”。原因很简单:行业缺高质量数据。当大模型把互联网上公开的文本和代码“学”光之后,从哪里找新知识?答案是用AI生成的内容去训练AI。
IDC中国研究副总裁钟振山的观点值得关注:像DeepSeek、通义千问这些国产模型能在全球基准测试中表现优异,秘诀之一就是它们“消化”了海量代码和语料——而这些语料,很多正是由上一代模型(如GPT-3.5、Claude 2)生成的。
但“自己喂自己”的操作,反而推高了企业成本。IDC中国研究副总裁周震刚提到了一个“Token经济学的悖论”:单价确实在暴跌——中国模型的价格只有海外的六分之一到十分之一,但企业的总账单却在飙升。打个比方,这就像电价便宜了,可家里电器越来越多、越开越久,月底一看电费,反倒涨了。
怎么说呢,Token现在的定位更像是“工业用电”而不是“民用电”——它驱动的是AI产业的内部循环,还没有真正渗透到每一个普通人的数字生活角落。
02、别谈价格,先说“好用”
面对AI付费,绝大多数用户的第一个反应不是掏钱,而是犹豫。理由很直接:你连好用都没证明给我看,凭什么让我先付钱?
最近讨论得最多的一件事,可能是豆包AI幻觉引发的系列“魔幻事件”。它不仅“一本正经地胡说八道,嬉皮笑脸地认真道歉”,甚至还在真实的政策问题上误导用户。
事情的经过是这样的:有用户想退订机票,为了尽可能减少损失,他去问了豆包。豆包不仅认真列出了步骤,还生成了“可追溯、可追责”的赔付承诺。结果呢?不仅建议没用,用户发现所谓的“赔付承诺”根本子虚乌有。更让人哭笑不得的是,这位用户之后打算把豆包告上法庭——用的起诉书,还是用豆包自己生成的。
如果只是退票操作步骤错了,可以理解为AI幻觉。但“虚假承诺”——说自己有能力赔付和承担法律责任——这就不能用幻觉搪塞了。豆包的问题,和其他大模型一样:远没有成熟到百分百有用、好用,甚至连基本的合规都未必能保证。

图源:小红书截图
C端用户对价格敏感,但对“不确定的风险”更敏感。企业端也是一样,甚至更甚。
目前,中美AI模型的能力差距已经缩小到2.7%以内,模型能力越来越强,API调用越来越方便。听起来是好消息。但IDC的调研揭示了另一面:国外企业不考虑使用中国AI模型时,优先级考虑的因素不是性能——因为性能已经很接近了——而是能不能长期稳定用、值不值得持续投入、能不能接进客服、研发、法务、风控这些现有流程,以及系统是否兼容。
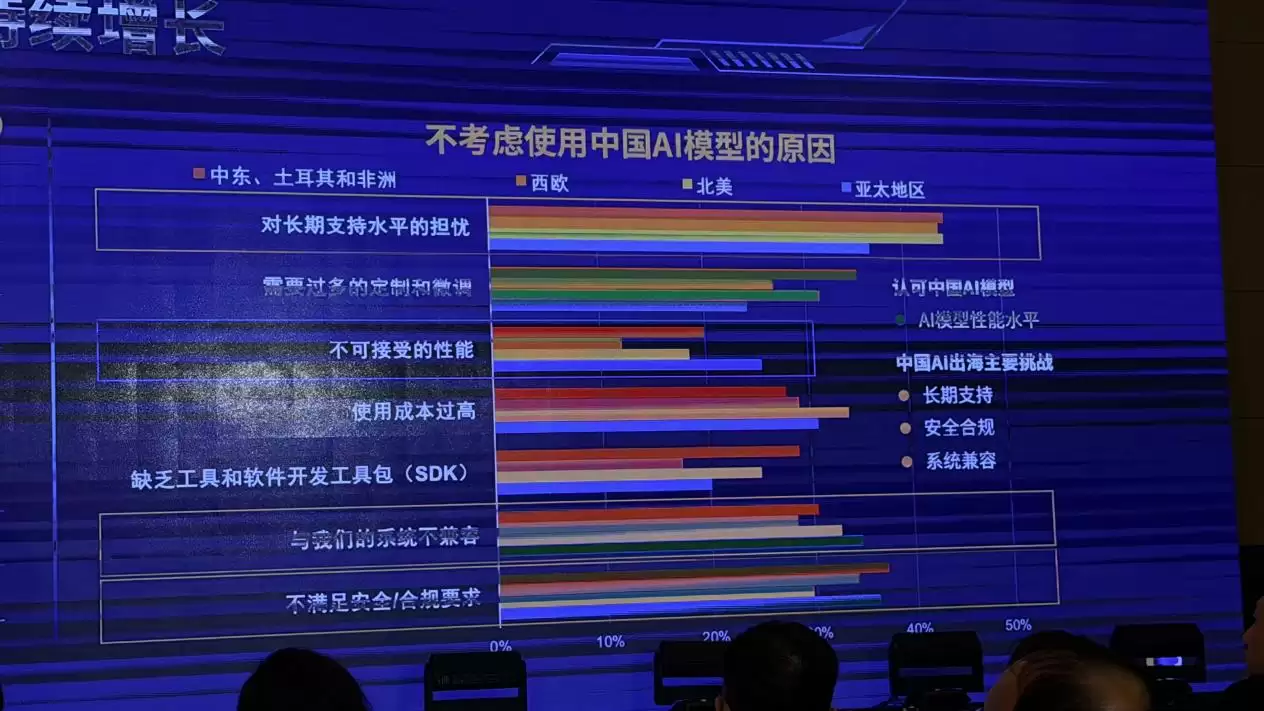
大多数人似乎陷入了一个误区,把算力逻辑等同于体验逻辑。运营商和云厂商热衷于告诉你“1块钱买40万Token”,仿佛Token越多越赚。但问题在于:消耗这40万Token,到底能不能解决实际问题?如果你需要不断“调教”、反复修改指令、忍受答非所问,那么Token再便宜也毫无意义。
好用,才是唯一的标准。这就引出了一个更关键的概念——Skill(技能)。
钟振山分享了一个让人印象深刻的实验:用OpenClaw在水木社区发帖,第一次消耗了6500万Token,发两次才成功。但第二次调用时,Token消耗骤降到37万——前后大约200倍的差距。原因很简单:OpenClaw自己写了一个“skill”,把重复动作做成了一个可复用的工具。
Token本身只是原材料,真正产生价值的是让Token完成有效任务的Skill。如果Skill库不够丰富,Token就只能被消耗,而不是被“使用”。未来,企业之间比拼的不是谁的模型参数更大、谁的Token单价更低,而是谁的Skill生态更丰富、更聪明。
03、安全成本谁来买单
上面说了两个问题:一是大量Token被消耗在AI模型的内循环里,没有直接转化为普通用户的生产力;二是即便Token流向应用层,实际效用也远未达到“好用”的标准。
但这两个问题之外,还有一个更根本性的风险——Token经济的扩张,正在重新定义安全的成本结构。而这个成本,目前几乎没有人买单。
首先,Token本身就存在被污染的风险。大模型没有“判断力”,一切都靠投喂内容生成——无论是正经知识还是恶意假话。一旦假数据喂多了,模型的“概率认知”就会跑偏,说假话、传递假信息就成了常态。
更值得警惕的是,国家安全部已经发过预警:Token在特定场景下充当着数字世界的“临时身份证”。一旦泄露,攻击者可以直接盗用用户身份,获取隐私信息、登录账号,甚至转账。这不是科幻小说,是真实存在的风险。
其次,Skill的安全隐患严重被低估。IDC的观察显示,目前市面上超过60%的开源Skill可能存在安全风险。但普通用户和企业缺乏有效的技术手段去判断一个Skill到底是“帮手”还是“内鬼”。Thales《2026年数据威胁报告》也提到,70%的企业将AI列为首要数据安全风险,但只有34%的企业清楚自己所有数据的存储位置。
任何工具的价值都取决于我们如何看待和使用它。当调用量从千亿级跃升到百万亿级,人工审核已经完全行不通了。而目前的安全审计工具,还没有针对Agent驱动的权限模型做出实质性升级。
这里有一个值得关注的新趋势:以MISOS为代表的新型模型,其核心能力并非来自安全数据的专项训练,而是通过对海量开源代码、技术文档、漏洞报告的消化,具备了自主识别系统弱点的能力。这意味着安全攻防的底层逻辑正在发生本质变化——传统体系里,攻防两方都是“人”;而未来,双方都可能部署模型。企业需要对抗的,不再只是零散的黑客行为,而是模型驱动的自动化攻击。
可以预见的是,随着Agent部署规模扩大、模型权限边界模糊、攻击手段持续升级,安全成本终究会从“可选”变成“必选”。IDC预测,到2028年,企业在AI安全相关的算力和服务支出将占到AI预算的15%到20%。
但问题仍然摆在台面上:这笔钱谁来出?目前,无论是运营商的Token套餐,还是云厂商的API定价,都没有单独列出安全成本。用户买到的是未经净化的“原水”。一旦发生数据泄露或身份盗用,责任算谁的?模型厂商?Skill开发者?还是用户自己?
写在最后
Token可以定价,但信任不能;算力可以规模化,但责任很难拆分。运营商把AI切成了最小的计量单位,市场也欣然接受了这把尺子。但具体的刻度,还得一笔一笔划清楚。否则,再简单的账单,也没人敢放心地签。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Python实现卫星轨道状态向量可视化系统
想不想亲手“发射”一颗卫星,看着它绕着地球划出优美的轨迹?今天,我们就来聊聊如何用Python构建一个基于状态向量的卫星轨道可视化系统。这套方案的核心思路非常清晰:输入卫星的初始位置和速度,然后利用经典的轨道力学公式和数值积分方法,推演出它未来的完整运行轨迹,最后通过Matplotlib进行生动的3

电脑卡顿真凶揭晓,一键解决工具助你流畅运行
你的Windows电脑是否也面临这样的困扰:开机速度缓慢,内存占用居高不下,预装软件冗余且无法移除,隐私设置分散在系统各处难以查找?先别急着考虑更换硬件,问题或许不在于设备本身——你可能只是缺少一款合适的优化工具。 今天要介绍的,正是GitHub上快速崛起、口碑持续攀升的开源项目:Winhance。

全新一代问界M9预售49.98万起 豪华SUV王者归来
今晚,鸿蒙智行旗下的全新一代问界M9系列正式揭开了预售帷幕。标准版的起售价定在49 98万元,而更为奢华的Ultimate领世加长版则来到了66 98万元。这个价格区间的发布,无疑在高端豪华SUV市场投下了一枚重磅冲击波。 从设计语言上看,新车延续并强化了豪华SUV的气场。前脸部分,贯穿式的灯带与点

专家号秒空却无人就诊 警方打掉抢号倒卖黑色产业链
最近,上海医疗圈里发生了一件怪事。多家知名三甲医院的专家号,在线上平台一放出来就被“秒空”,可到了实际就诊时间,诊室里却冷冷清清,大量号源被白白浪费。这种“占着茅坑不拉屎”的现象,让真正急需看病的患者叫苦不迭。 数据揭示了其中的反常:部分账号的预约行为极其高频,累计抢号超过3000次,但最终实际就诊

JUC ScheduledThreadPoolExecutor 源码解析:定时与周期性任务实现原理
在深入理解CountDownLatch与CyclicBarrier两大同步工具,解决了线程间的“单向等待”与“协同等待”问题后,我们自然会面临一个更普遍的需求:如何高效、可靠地处理定时任务与周期性任务?无论是系统监控、缓存刷新、数据同步还是消息重试,都需要一个健壮的核心调度引擎来支撑。 Java生态








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
