




Google新数据集首次大规模捕捉用户未言明想法

当对话型AI的规模扩大到每天处理数十亿次交互时,一个值得关注的问题浮现出来:我们真的理解用户在想什么吗?
目前绝大多数研究都聚焦于用户“说了什么”,但那些“没说出来”的部分——用户的真实动机、隐含的期望、对回复的内心评价——几乎仍是一片未开发的领域。无论是WildChat还是LMSYS-Chat-1M这类主流对话数据集,都只把对话文本当作唯一可观测的信号。而用户出于“最少努力原则”和社交礼貌,写下的提示与其脑中的真实意图之间,天然存在信息损耗:表达要高效、得体、有目的性,但绝不会是内心活动的完整复刻。
现有的对齐方法,无论是偏好评分、点赞点踩还是基于消息文本的反馈,都很难回答一个根本问题:“用户到底对哪一部分不满意?为什么?”更别提捕捉用户在多轮对话中如何悄然调整自己的目标。这就引出了一个关键命题:
如何在真实的人机对话中,系统性地捕捉那些“未言明的思考”,并把它们当作新的数据维度来训练和评估AI助手?
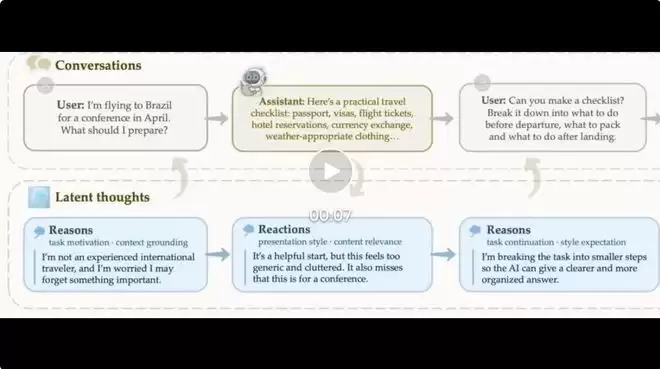
来自JHU、MIT和Google Research的一篇新研究,给出了一套值得关注的解法。他们推出的ThoughtTrace,是首个将真实多轮人机对话与用户“自我报告的思考”大规模配对的数据集。这里的“思考”分两类:用户发送提示前的reasons(动机、目标、上下文、对内容和风格的期待),以及读到AI回复后的reactions(满意度、对内容/风格/范围的具体不满)。这些第一人称的认知痕迹,正好填上了“可观测语句”与“真实用户意图”之间的那道鸿沟。
从规模上看,这套语料库的构成相当扎实:
- 1,058名用户
- 2,155段多轮对话
- 17,058次交互轮次
- 10,174条思考标注
- 覆盖20个不同的语言模型(包括GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro Preview等前沿模型,以及若干开源轻量模型)
基于这批数据,作者证明:引入“思考”信号,能将下一条用户消息预测的语义相似度从21.6提升至30.6(相对提升41.7%),并将基于Arena-Hard的对齐胜率拉高25.6%。这意味着,ThoughtTrace为后续的RL、DPO等训练范式提供了一种全新的、接近ground-truth级别的监督信号。

论文标题:ThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions
论文链接:https://arxiv.org/abs/2605.20087
方法概览
为了让用户在自然对话中诚实地外化自己的思考,研究团队通过Prolific招募参与者,设计了一套四步采集流程:首先签署知情同意书,明确自愿参与与随时可退出的权利;然后通过引导式教程学习聊天界面和标注方法,并通过简短测验;接着进入核心环节——参与者自行设定两个开放式任务,自由与AI多轮交流,并在每条用户消息上标注reason,在每条AI回复上标注reaction;最后完成任务后调查,描述实际完成了什么、对AI有什么期望,并填写个人背景问卷。
每条ThoughtTrace记录对应一段完整对话,按时间戳保存所有用户消息、AI回复以及附着其上的思考。reason来自7种类型之一,reaction来自5种类型之一,每条思考都带有自己的时间戳与文本内容,标注对AI完全不可见。
数据特性
作者从对话和思考两个维度刻画了ThoughtTrace的特性。
对话层面有三个值得关注的地方:
- 代表性的用户群:覆盖18至65+各年龄段、多种教育水平与职业身份,AI使用频率从“从未”到“每日多次”,符合频繁AI用户的人口画像。
- 长程、多元的对话:ThoughtTrace的中位数对话轮次为8轮,而WildChat与LMSYS-Chat-1M都只有2轮;话题分布跨越7个大类、36个细分子主题,没有单一类别占主导。
- 任务延伸主导:57.0%的用户消息属于“在已有任务上扩展、深化、迭代”,远超新请求(12.5%)、重试(2.9%)和变体(2.3%),且这种延伸模式随对话进展愈发显著。
思考层面则揭示了四个关键性质:
- 思考与消息显著不同:嵌入空间可视化与基于LLM的语义覆盖打分均显示,用户消息对其背后reason的覆盖度仅3.22(1–5分制),对前一轮reaction的覆盖度仅2.00——对话文本远不能完整复现用户内心活动。
- 思考对前沿LLM而言难以推断:让GPT-5.4、Gemini 3.1 Pro Preview、Claude Opus 4.6从对话上下文中推测用户的reason与reaction,三模型平均得分仅为2.93和2.54,介于“极少重叠”与“部分重叠”之间。
- 思考内容高度多元:7种reason涵盖Task Motivation & Goal(36.9%)、Task Continuation(21.4%)、Context Grounding & Constraints(13.1%)、Content Expectation(11.5%)、Task Reorientation(11.1%)、Style Expectation(5.0%)和Social and Others(1.0%);5种reaction包括Explicit Affirmation(72.2%)、Content Relevance(11.9%)、Presentation Style(6.4%)、Scope Fit(6.1%)、Partial Satisfaction(3.4%)。
- 思考随对话阶段动态变化:Task Motivation主导早期,Task Continuation在中后期占主导;Explicit Affirmation从早期67%上升至晚期79%,反映对话向令人满意的回答收敛。这种动态独立于话题或长度,仅与对话阶段和多轮关系相关。
实验结果
这些“内心思考”真的能用于下游建模吗?作者设计了两组关键实验。

实验一:Thoughts Predict User Beha vior
让LLM在“仅有对话历史”与“历史+用户思考标注”两种条件下预测用户的下一条消息,评估三个前沿模型,并用随机抽取的另一个模型作为评判者打分(0–100分的语义相似度)。
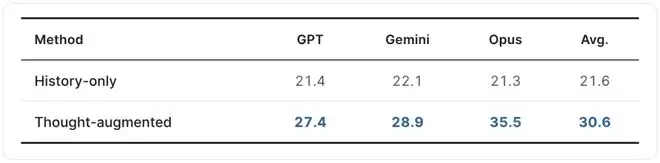
结果一目了然:仅仅向模型提供用户的内心思考,平均预测分数从21.6跃升到30.6,相对提升41.7%。其中Opus 4.6的提升尤为显著,单独拉升了14.2个点。这说明ThoughtTrace中的reason与reaction提供了对话历史所不具备的、能够预示用户未来行为的可执行信号——这对构建高保真用户模拟器、面向用户主动协助的智能体都有直接价值。
实验二:Thoughts Improve Model Alignment
作者直接利用ThoughtTrace的reaction标签定位“用户实际不满意的回复”,再用对应的思考内容指引模型重写,形成thought-guided rewrites;将其与原始消息配对,在Qwen3.5-4B上进行DPO训练,于Arena-Hard上评估。
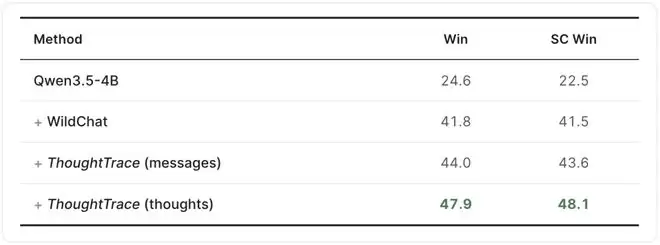
相较基础模型,思考引导版本在风格控制胜率上提升25.6%;相较WildChat基线,提升6.6%;同样在ThoughtTrace上,思考引导比消息引导高4.5%,表明思考承载着比消息更丰富的不满与修正信号。
更值得关注的是,思考能从同一批对话中识别出1,000条不满意实例,而仅依赖消息只能挖出450条,前者是后者的2.2倍。这意味着思考天然提供了更密集的监督——不仅告诉我们“哪一条回答用户不满意”,还直接说明“应当如何修正”,把响应识别和响应修正两件事统一进了同一条监督信号。
结语
作者将thoughts定位为人机交互研究的一种新数据模态:它捕捉用户的潜在认知,难以从语句中复原,跨越多种内容形态,并随对话阶段动态变化。无论是用户行为预测、模型对齐,还是未来的奖励建模、On-Policy Distillation等在线学习范式,思考都提供了消息文本所无法替代的细粒度信号。
ThoughtTrace由此打开了三条新的研究方向:(1)用户建模——系统研究人机交互中的动态心理过程;(2)模型训练——把思考作为新的监督信号,用于训练真正理解用户潜在目标与偏好的助手;(3)评估——构建以思考为中心的基准,把评估从表面语句推进到潜在意图与主观体验。
正如论文所言,ThoughtTrace将用户思考确立为研究人机交互背后认知动力学的一种基础信号,也为构建真正理解用户“潜在目标、偏好与需求”的下一代AI助手,铺设了一条新的研究路径。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
