




容联七陌多Agent大模型实现智能客服真人级对话

智能客服这几年备受用户诟病——答非所问、一问三不知几乎成为常态。即便技术不断迭代,外呼机器人能模拟真人发音,用户一听那股机械感,依然会迅速挂断或要求转人工。简单来说,过去的智能客服在语义理解和自然对话方面始终未能突破瓶颈。
然而,大模型技术的兴起为这一局面带来了转机。依托生成式技术与智能的“涌现”能力,智能客服开始接近人们理想中的形态。不过,新的问题也随之浮现:仅凭大模型就足够了吗?如何将其真正落地到客服场景中?落地后能具体实现哪些功能?又给行业带来了怎样的实质性变革?这些变化对企业与用户而言是否具备真实价值?
带着这些疑问,我们与容联七陌的产品负责人刘倩进行了深入交流。容联七陌深耕智能客服领域长达十年,曾服务作业帮、复兴健康、同仁堂、虎牙、多点、广汽能源、红旗、居然之家等知名品牌,业务覆盖教育、医疗、电商、制造、汽车等多个行业。今年8月,他们推出了行业首创的“新一代大模型智能客服解决方案”,让智能客服在意图识别、答案生成与情绪感知方面实现了质的飞跃。
以下是根据采访内容整理的对话精华,希望能帮助你更直观地了解大模型给智能客服带来的革命性变化,以及技术与应用如何相互交织、落地生根。
Q:大模型火热一年多,它究竟为智能客服领域带来了哪些实质性的改变?
A:变化与价值始终在持续探索中。对智能客服而言,核心在于将大模型的理解能力与生成能力真正融入对话产品。
举个简单的例子:以前网购时,智能客服的回答都是预设好的套路,回复冷冰冰,还经常答非所问。有了大模型之后,机器人能够自主生成话术,灵活接住用户的话头,回答自然流畅,仿佛在与真人聊天。此外,大模型可以应对用户各种不同的表达方式——无论是问法多样还是包含错别字,它都能做到真正理解。
因此,新一代智能客服会更加依赖原生大模型,用户所体验到的是自然、智能的交互感受,而非上一代那种简单预制、机械式的对话模式。
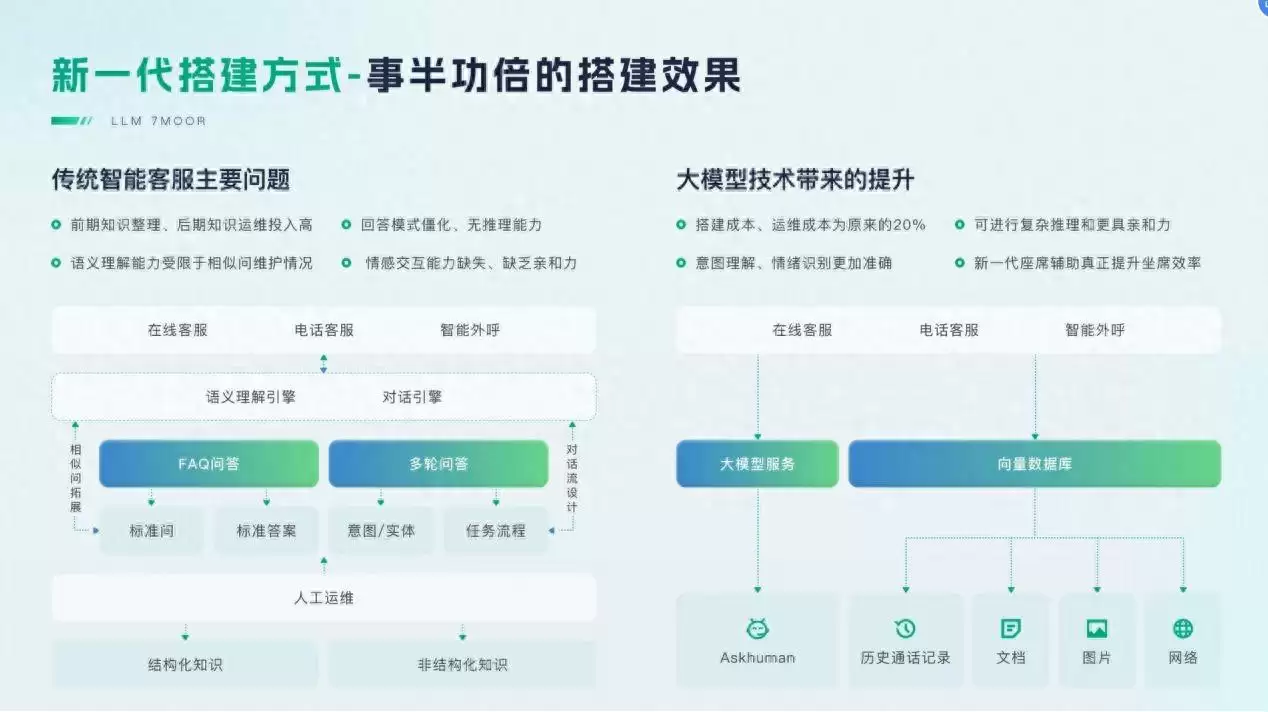
Q:与上一代相比,你如何评价这种基于原生大模型的智能客服?
A:传统智能客服的问题非常典型。
第一,被吐槽“弱智”——语义理解能力不足,用户提出需求后,机器答非所问的概率很高。上一代采用关键词、BERT等机制,需要大量人工标注数据,标注越多理解效果越好。但一旦标注不足,理解能力就会大幅下降,最终导致答非所问。
第二,用户体验差,缺乏情感表达。用户带有情绪,但上一代客服的回答是预制的,无论用户多么生气,回复都是固定模板。能否打动用户、解决实际问题,完全取决于当初设计问答的人。
第三,复杂任务处理非常呆板。例如预订会议室,上一代需要借助流程画布——先问时间、再问参会人、然后调用接口,一步步按照设定执行。一旦用户话题超出设定范围,机器人就会直接表示无法回答,最终导致转人工的比例居高不下。
第四,成本高昂。上一代需要专门配备机器人训练师,穷举业务问题与标准答案,每个问题还要提供至少30个相似句。复杂业务还需梳理知识图谱。训练周期通常为3个月到半年,才能达到80%的解决率。企业为此需要安排专人,成本不小。
大模型问世后,新一代智能客服逐一解决了这些痛点:冷启动阶段无需标注数据,只需维护好业务知识即可获得不错的效果——回复更具人性化,能接住话题,也能理解情绪。例如用户一开口就带着怒气,大模型会先进行安抚,再给出解决方案。对话流畅度高,情绪价值也充分体现。
流程类场景也是如此,比如预订会议室,大模型不再需要固定流程和穷举话题。它拥有强大的推理能力,结合提示词工程,能够自主思考——已获取哪些信息,还欠缺哪些,然后引导用户补充完整。即便用户中途切换话题,对话也能顺畅延续。
成本方面,不再需要专门的机器训练师,企业成本降低了,回答准确率反而更高。我们测试过一个保险客户,对方提供了10万字的测试资料(保险条款、规则制度等),整理出几千个知识点。用上一代智能客服,仅整理资料最少需一周时间,且只能达到40%的解决率,后续还需不断标注。而采用大模型自动清理知识点,1天内即可完成,测试解决率达到100%,上线后也达到了92%(即未转人工的比例)。
Q:容联七陌率先推出了新一代大模型智能客服方案,具体产品功能与亮点是什么?
A:我们在既有产品基础上,推出了4款基于原生大模型的产品:
- LLM文本机器人——负责接待网站、公众号、APP等IM渠道的客户需求;
- LLM智能外呼 & LLM智能呼入——应用于呼叫中心场景;
- LLM座席助手——辅助人工客服,如生成回复话术、自动撰写服务小结、创建智能工单等。

方案的最大亮点正是前面提到的原生大模型的理解能力与情绪感知能力。关键还在于采用了“多Agent”的产品架构。Agent即智能体,它构建在大模型之上,能够模拟独立思考、灵活调用工具。为什么要用多个Agent?举个例子:我们合作过一家教育行业的头部企业,客服工作分为三类——简单寒暄、回答通用问题(如APP头像如何修改)、VIP业务(权益介绍、使用、续费)。这三种任务类型各不相同,但又混合出现。每个业务场景匹配一个单独的Agent,让这个Agent去感知、思考、行动,完成单一任务,效果更佳。因此,复杂任务需要多个Agent协同,准确率才能提升。
Q:具体如何提升准确率?比如大模型存在幻觉问题,怎样确保回复的准确性?又该如何判断什么场景应由大模型自动回复,什么场景应转人工?
A:第一,多Agent架构本身就提升了准确率。第二,提示词工程——我们根据客户实际业务抽象出大量提示词,进一步提升了工程层面的准确率。
至于判断机制:如果只是简单知识点或推理,直接由大模型回复。复杂推理场景我们设计了三个功能模块:
- 知识词典——补充保险条款等细节知识点,让大模型能够进行推理;
- 最佳实践——为大模型提供一些示例参考,进一步提升推理效果;
- 二次复核——复核大模型生成的回答是否准确、能否解决问题、是否包含违禁词等。这也是对幻觉的检验机制。一旦发现问题,配套策略是立即转人工或进入Ask Human Help托管模式。
此外,我们还专门让大模型自动学习人工客服的服务记录,这也是提升效果的重要举措。
Q:新一代大模型智能客服在不同行业与场景中的落地效果如何?
A:目前已在多个业务场景中落地测试:
第一,售前营销套电场景。某家居家装公司用大模型机器人替代了传统流程式机器人。大模型能够自然接住用户话题,先进行互动再委婉请求用户留下资料,留资率从21%提升至32.91%。
第二,外呼邀约场景。同样是这家公司,利用外呼机器人对留资客户进行回访邀约。传统外呼需要大量人力训练流程、话术、意图,准确率不高、话术固定。大模型外呼机器人能根据上下文语义判断客户意向等级、自动生成小结标签,客户意向度提高了23%,信息抓取准确度提高了46%。
第三,客服场景。某大型企业内部的HRSSC服务,员工提问涉及大量公司规定、社保、公积金等,知识来源复杂且具有时效性。如果全部由HR人工答疑,其他工作将难以兼顾。采用大模型智能客服后,HRSSC解决率高达97%。
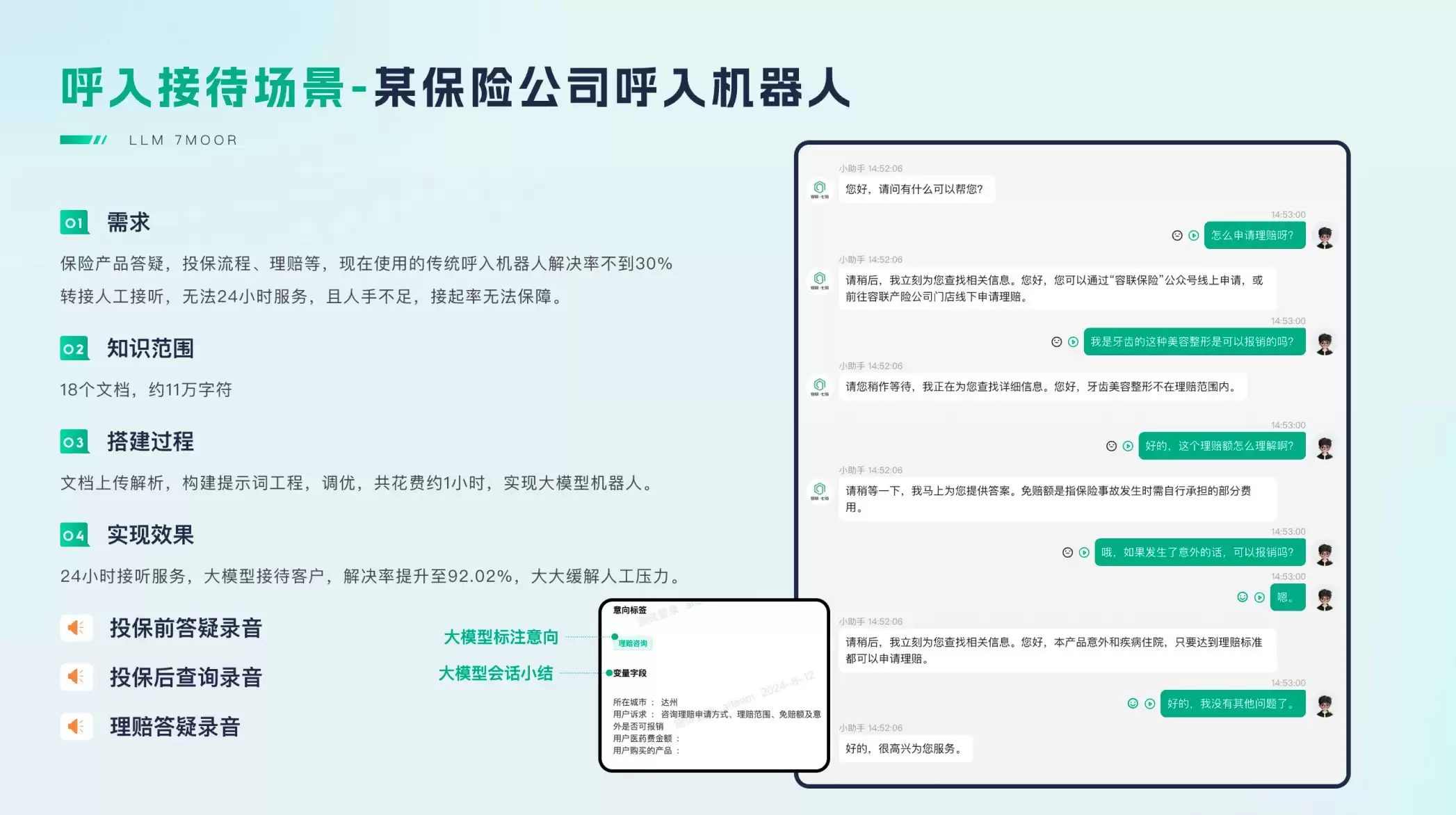
第四,呼入接待场景。某保险公司使用传统呼入机器人答疑理赔等,解决率不到30%,转人工后无法提供24小时服务,人手也严重不足。引入大模型智能客服后,实现了全天候接听,解决率提升至92.02%,人工压力得到显著缓解。
Q:这个方案是标准化产品吗?如何满足不同客户的个性化需求?
A:我们依然采用SaaS模式的标准化产品——因为企业进行私有化部署大模型,成本往往难以承受。产品设计上采用灵活可配置的SaaS模式,同时设置了许多低代码模板,方便客户根据自身业务进行搭建。不同行业与场景的客户可以直接使用我们推出的4款新产品,也可以通过灵活配置Agent来满足个性化业务需求。
Q:市面上有多款大模型智能客服产品,同样基于大模型技术,为什么“智能”效果差异显著?决定因素有哪些?
A:并非拥有大模型就一定“智能”。通用大模型能否真正用起来,产品应用层面非常关键。容联七陌能够实现“智能”,与采用多Agent模型架构以及客服领域的深厚经验密不可分。这种经验包括:如何让大模型理解客户业务场景、如何设计功能模块来解决问题、如何让大模型越用越智能——这是技术与行业应用的深度融合。
我们也看到很多同行在探索,但大模型往往只是作为某种功能辅助——比如提升会话小结效率、优化训练师工作效率。本质上是用大模型来辅助上一代智能客服,并未从根本上解决痛点。这也是为什么我们强调原生大模型——它的体验与效率与上一代完全不在同一个层级。
Q:智能客服领域都在研究大模型Agent的落地路径,竞争壁垒在哪里?容联七陌的优势是什么?
A:容联七陌从2023年底就确定了大模型Agent路径,是国内智能客服行业最早一批确立方向的企业。前面提到的多Agent、提示词工程、功能设计等,体现了产品技术竞争力。
举个例子,我们独创的Ask Human Help托管模式:用大模型机器人全程接待,告别直接转人工。传统人机协同中,转人工是用户能够明显感知的,而且人工回答后就没法再转回机器,客户体验与人工成本都不理想。但在Ask Human Help模式下,用户使用自然语言交流,感知不到对面是机器人。当大模型无法回答时,转给人工客服,人工只需回答转进来的这一条消息,然后立即再转回大模型。这样一来,人工客服的工作量从“会话级别”降低到“消息级别”,每个客户的服务时长可能从平均10分钟缩短到1分钟以内。同等数量的人工客服可以接待更多客户,客户体验更好,效率也更高——企业与客户实现双赢。
此外,容联七陌深耕客服领域十年,在解决方案的各个环节做了大量设计与优化,能够充分贴合各行业客户的客服场景。比如将客服系统与人力、工单等业务系统进行集成。因此,我们的Agent解决方案并非单一产品,而是一整套涵盖售前、售中、售后的完整方案。多年的行业服务经验,让我们对客户的痛点和实施落地的难点都有了深入了解,从方案设计、实施、培训到服务都能做到全面跟进。
Q:围绕智能客服Agent,未来容联七陌还将在哪些方向进行探索?
A:我们会继续增强产品的智能性与问题解决能力,持续提升大模型的准确率。同时关注多模态技术发展,比如ASR、TTS、音色克隆等,将大模型的不同技术应用到智能客服产品中。市场应用方面,目前智能客服已覆盖多个行业,期待新一代大模型智能客服能够应用到更广泛的行业与场景,助力更多企业降本增效,提升客户服务与营销体验。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
