




Coze搭建知识图谱:GraphRAG原理及实战讲解(一)

从基础RAG迈向图增强检索,解锁知识库构建新思路,攻克复杂场景下的检索难题。
之前我们已经系统讲解了Native RAG的基本原理与使用方法。借助各类平台搭建专属知识库,如今已不再是什么难事。
Native RAG的优势在于门槛较低,但其局限性也很明显——它无法在文本块之间建立关联,检索效果通常只能达到六七十分的水平,真要用于生产环境,心里还是没底。
所以,今天咱们开启一个新话题,深入探讨Graph RAG,看看它如何应对复杂的知识场景。
Native RAG回顾
先简单复习一下Native RAG的基本概念。
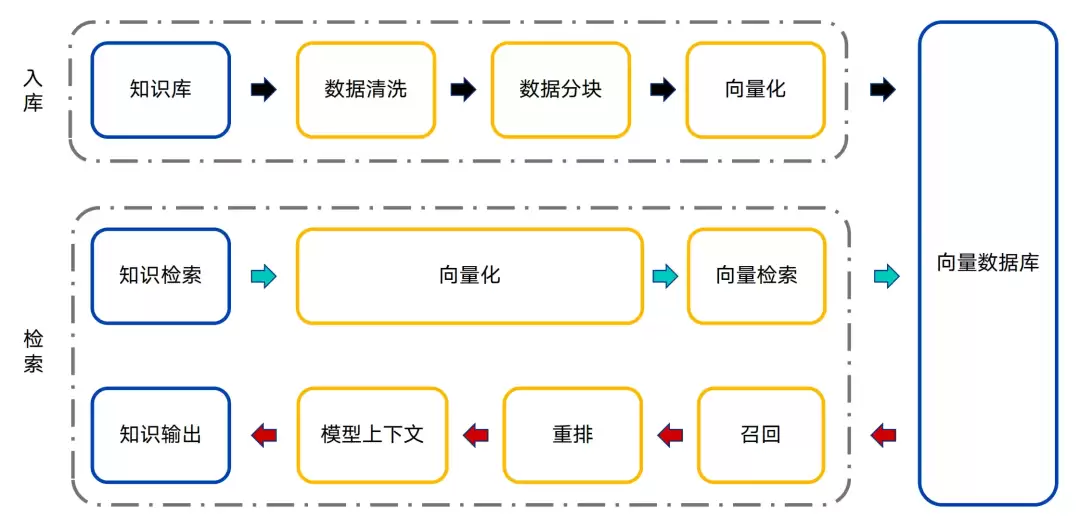
Native RAG包含两条核心流程:数据入库和信息检索。
- 入库流程主要涵盖
数据清洗、文本分块、向量化转换等步骤。 - 检索流程主要涉及
检索策略优化、多路召回、结果重排序、生成内容优化等环节。
Graph RAG是什么
Graph RAG是一种基于结构化分层思想的检索增强生成方法。
在构建知识库时,它会把知识转换成图结构,并存储到图数据库中。
图数据库通常不直接保存数据片段,而是保存数据实体,并在实体之间建立关联关系——这正是Graph RAG最关键的环节。
数据实体与数据关系
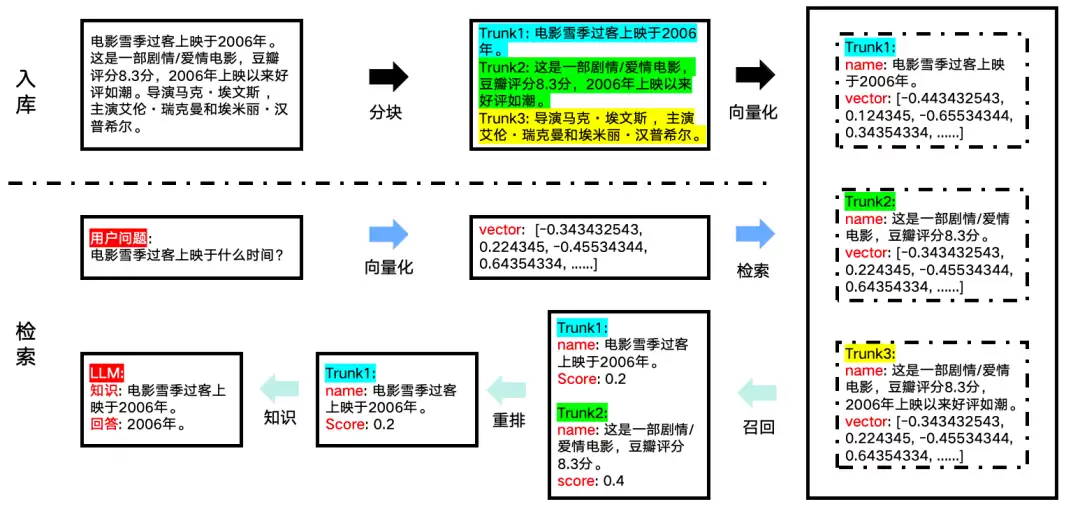
举个例子:
# 原文
电影《雪季过客》上映于2006年。这是一部剧情/爱情电影,豆瓣评分8.3分,2006年上映以来好评如潮。导演马克·埃文斯,主演艾伦·瑞克曼和埃米丽·汉普希尔。
# 实体通常是有意义的名词,如人名、地名、物品名等。
# 我们能提取的实体是:
雪季过客,2006年,剧情电影,爱情电影,豆瓣8.3分
马克·埃文斯,艾伦·瑞克曼,埃米丽·汉普希尔
# 实体关系用于描述两个实体之间的关联,通常是动词。
# 我们能得到的实体关系如下:
上映,分类,评分,导演,主演
# 最终得到一组实体与关系:
Trunk1:
(雪季过客)-[上映]->(2006年)
Trunk2:
(雪季过客)-[类型]->(剧情)
(雪季过客)-[类型]->(爱情)
(雪季过客)-[豆瓣评分]->(8.3分)
Trunk3:
(雪季过客)-[导演]->(马克·埃文斯)
(雪季过客)-[主演]->(艾伦·瑞克曼)
(雪季过客)-[主演]->(埃米丽·汉普希尔)
数据存入图数据库后,大致呈现如下形态:

检索时,就可以沿着实体之间的关系,轻松探索到关联知识。
Native RAG vs Graph RAG
现在假设我们拥有一批电影数据,数量大约几万部。
每部电影的数据结构如下:
采用Native RAG进行分块和向量化后,可以轻松召回对应的电影信息。
# 例子1
Q:雪季过客什么时候上映的?
A:2006年。
# 例子2
Q:雪季过客的导演是谁?
A:马克·埃文斯,他也担任了本片的编剧。
因为每部影片的基础信息都被作为一个Chunk存储在向量库里,所以回答这类简单问题基本没有压力。
但如果问题变成这样:
# 例子1
Q:雪季过客的导演还出品过哪些影片?
# 例子2
Q:今年一共上映了多少部日本电影?
由于知识库里缺少这类跨实体的关联数据,检索效果就会大打折扣,或者需要在工程层面做大量补偿才能勉强达到满意效果。
而Graph RAG处理这类问题就从容得多了。
Graph RAG的工作机制
Graph RAG的实现机制比Native RAG复杂不少,但总体也分为两大模块:数据构建和数据检索。
数据构建
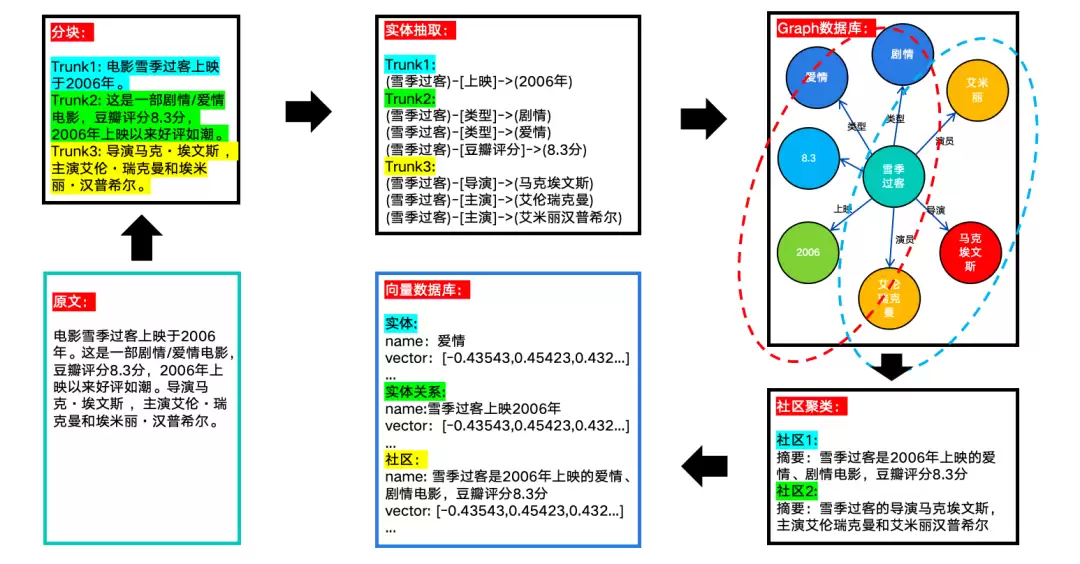
数据构建主要经过以下几个步骤:
| 步骤 | 说明 |
|---|---|
| 数据分块 | 与Native RAG相同,将复杂文章切分为长度适中的段落 |
| 实体抽取 | 使用大模型抽取实体和实体关联关系 |
| 实体入库 | 将实体与关系存储到图数据库 |
| 社区聚类 | 根据实体相关性进行社区聚类,并生成社区摘要 |
| 向量化 | 将实体、实体关系、社区信息存入向量数据库,便于语义检索 |
详细流程见下图:
数据检索
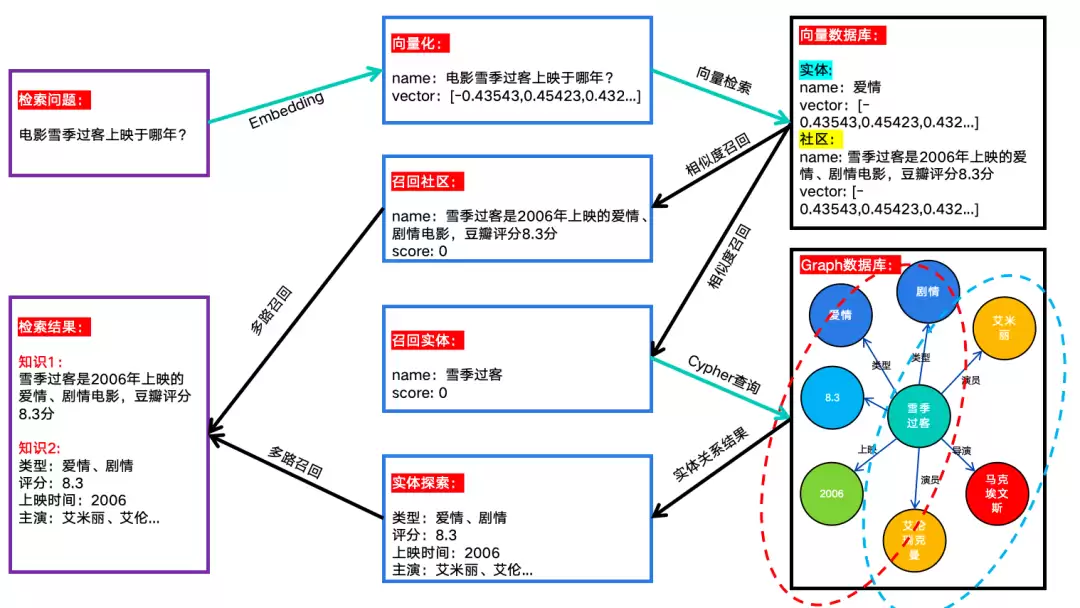
数据检索的策略多种多样,需要根据实际场景灵活调整,后续文章会专门介绍。这里先介绍两种常用方式:
全局搜索(Global Search):检索社区摘要信息并返回。本地搜索(Local Search):检索实体信息,并通过实体关系扩大搜索范围。
大致原理如下图:
体验Graph RAG
了解了基本原理,咱们就来实际操作体验一下。用Coze工作流搭建一个简易的Graph RAG。
图数据库
首先需要选择一款图数据库,这里我们选用Neo4j。
它支持本地部署和在线使用,可以先试用免费版。
创建实例后,点击Query即可连接到数据库,右侧可以编写Cypher查询语句来操作。
注意:创建实例时会生成数据库的账号和密码,请务必妥善保管,后续会用到。
Cypher
Cypher语句与SQL类似,可以对数据库进行增删改查。这里提供几个最简单的示例:
# 创建一个实体"电影",名字叫"拯救大兵瑞恩"
CREATE(m:电影{name:"拯救大兵瑞恩"})
# 创建另一个实体"人员",名字叫"汤姆·汉克斯"
CREATE(p:人员{name:"汤姆·汉克斯"})
# 创建一个关系:拯救大兵的主演是汤姆·汉克斯
CREATE(m)-[:主演]->(p)
# 找到所有电影和对应的主演,并返回
MATCH(m:电影)-[:主演]-(p:人员)
RETURN m.name, p.name
将以上语句复制到查询框中,就可以体验Graph RAG的基本操作。
用Coze工作流搭建电影知识图谱
完成后的基本功能示例如下:
# 示例1
紫日的导演还出品过其他什么电影?
# 示例2
有哪些日语电影?
# 示例3
紫日的基本介绍?
为了便于演示和理解,这里不引入向量数据库,而是直接构建查询语句来操作图数据库。
知识图谱构建
先用一个循环处理多条数据:
- 从远端获取电影数据
- 清洗数据,去除无用信息
- 调用大模型提取实体,并生成查询语句
- 调用接口将数据插入数据库
实体与实体关系提取
工作流本身并不复杂,核心在于如何提取实体。提示词需要根据不同的业务场景进行调整:
# 角色
实体提取大师
# 任务
1. 根据输入数据,尽可能全面地提取实体和实体关系,并建立实体之间的关联。
2. 实体必须从[实体列表]中选取,不得自行创造。
3. 实体关系必须从[实体关系列表]中选取,不得自行创造。
4. 实体具备属性,参考[实体属性表],不得自行创造属性。
5. 不要解释,不要额外输出其他内容,严格按照输出格式要求。
6. 最终转换为Cypher格式,方便直接插入Neo4j数据库。
# 实体列表
[影片, 语种...]
# 实体关系
[分类, 语言...]
# 实体列表与实体关系的映射
(影片)-[上映时间]->(年份)
...
# 实体属性表
(影片{name:"String", intro:"String"})
...
# 输出示例
MERGE(m:影片{name:"拯救大兵",intro:"故事发生在..."})
MERGE(l:语种{name:"英语"})
MERGE(m)-[n:语言]-[l]
...
调用Neo4j数据库
使用HTTP模块直接调用即可:
# $id 是你的数据库实例ID,在Neo4j实例页面可见
# $key 是你的账号密码base64
# $query 是你的实际查询语句
# 使用以下命令生成$key:echo -n "你的账号:你的密码" | base64
# 账号密码在创建Neo4j实例时已保存。
curl -X POST "https://$id.databases.neo4j.io/db/neo4j/query/v2" \
-H "Authorization: Basic $key" \
-H "Content-Type: application/json" \
-d '{
"statement": "$query",
"parameters": {}
}'
知识图谱检索
- 使用大模型识别用户意图,并将其拆解为Cypher查询语句。
- 实际查询数据。
- 根据查询结果和用户问题,总结答案。
实体检索提示词
# 角色
Neo4j数据检索助手
# 任务
1. 理解用户的问题,并将其转化为Cypher查询语句。
2. 从图数据库中尽可能全面地查询与用户问题相关的内容。
3. 不需要回答用户问题,也不需要解释。
4. 只需输出Cypher查询语句,方便后续直接调用Neo4j数据库。
5. 可用的实体列表、实体关系及映射关系参见下文。
6. 不要自行创造实体、实体关系或映射关系。
# 实体列表
[影片...]
# 实体关系
[分类...]
# 实体列表与实体关系的映射
(影片)-[上映时间]->(年份)
...
# 实体属性表
(影片{name:"String", intro:"String"})
...
# 输出示例
Q: 找到1994年安东尼导演的作品。
MATCH(m:影片)-[:上映时间]->(n:年份{name:1994}) WITH m MATCH(m)-[:导演]->(p:人员{name:"安东尼"}) RETURN p.name as name
结果预览
由于样例数据有限,检索结果仅供参考。要想获得理想效果,需要导入全量电影数据。
# 示例1
Q: 有哪些日本电影?
A: 有以下日本电影:《驾驶我的车》《世界奇妙物语 06秋之特别篇》《何时是读书天》《隐剑鬼爪》《哆啦A梦:大雄与风之使者》《宛如阿修罗》《星之声》《精灵宝可梦:水都的守护神 拉帝亚斯与拉帝欧斯》《GO!大暴走》《哆啦A梦:大雄与翼之勇者》《心动》《不夜城》《海上花》《烟花》。
# 示例2
Q: 谁出演过两部以上的电影作品?
A: 金城武出演过两部以上的电影作品。
# 示例3
Q: 金城武都演了哪些电影?
A: 金城武出演的电影有《心动》《不夜城》。
总结
今天大致了解了Graph RAG的基本工作原理和应用边界,并且亲手实践了一次。
目前的案例还比较简单,随着项目不断深入,我们也会持续演进和迭代工作流。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

修Bug被Gemini追删代码致宕机修复报告现编
最近,一起堪称“教科书级别”的AI Agent IDE翻车事件在开发者社区引发热议。这起事故值得所有依赖AI编程工具的开发者,尤其是那些已经在生产环境中对AI Agent 授予较高权限的团队,进行深刻反思。 简单回顾:5月26日,一位开发者要求Gemini 3 5(运行在Agent IDE环境中)修

Notion AI运营指南:自动归纳用户反馈
其实,想在 Notion 中高效搞定用户反馈的自动归纳,并不复杂。下面这四种 AI 方法,基本覆盖了从单条处理到全局分析的常见场景。 如果你也在用 Notion 收集用户反馈——无论是问卷、邮件、客服记录,还是社群发言——但总觉得信息碎片化严重,难以提炼共性问题和核心诉求,那很可能是因为缺少一套结构

AI给出的答案为何总不符期望?原因解析
大模型能力强大,但提问方式不当会导致结果不理想。核心在于精准提问,通过角色设定、背景介绍、明确任务、实现路径和输出要求这五个关键步骤逐步细化问题,才能大幅提升AI回答的质量和精准度。

Anthropic新AI聊天机器人模型声称在多项测试中击败OpenAI GPT-4
2024年3月5日,人工智能领域迎来了一位重要参与者——由OpenAI前员工创立的Anthropic公司正式推出了Claude 3系列模型。这次发布极具分量:新模型不仅在性能上与Google和OpenAI的顶级产品并驾齐驱,部分指标甚至实现超越。要理解此次升级的真正价值,先关注几个关键变化。首先是多

Trae对Deno与Bun运行时的AI代码补全支持程度全面详解
如果你在使用 Trae 进行 AI 代码补全时发现,它对 Deno 或 Bun 运行时的提示不够精准——例如类型定义缺失、API 无法正确识别——那很可能不是代码本身有误,而是 Trae 的底层配置尚未适配。简而言之,Trae 对于非 Node js 运行时的标准库支持尚未实现“开箱即用”。下面我们








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
