




试遍四个方向摸到3M模型天花板终成功

手撕 GPT 系列第 7 篇。前 6 篇我们跑通了训练,模型通过了 6/6 验收。这篇记录的是:当我们试图让模型变得更好时,发现了什么。
做实验最怕的不是失败,是失败了还不知道为什么。
这篇文章记录了我们在 3M 模型上做的四个实验——三个失败,一个成功。失败的比成功的更有价值。
v3.0.0 通过了全部验收测试,回答质量从 v1.0.0 的“部分答非所问”进化到了“能正确回答”。
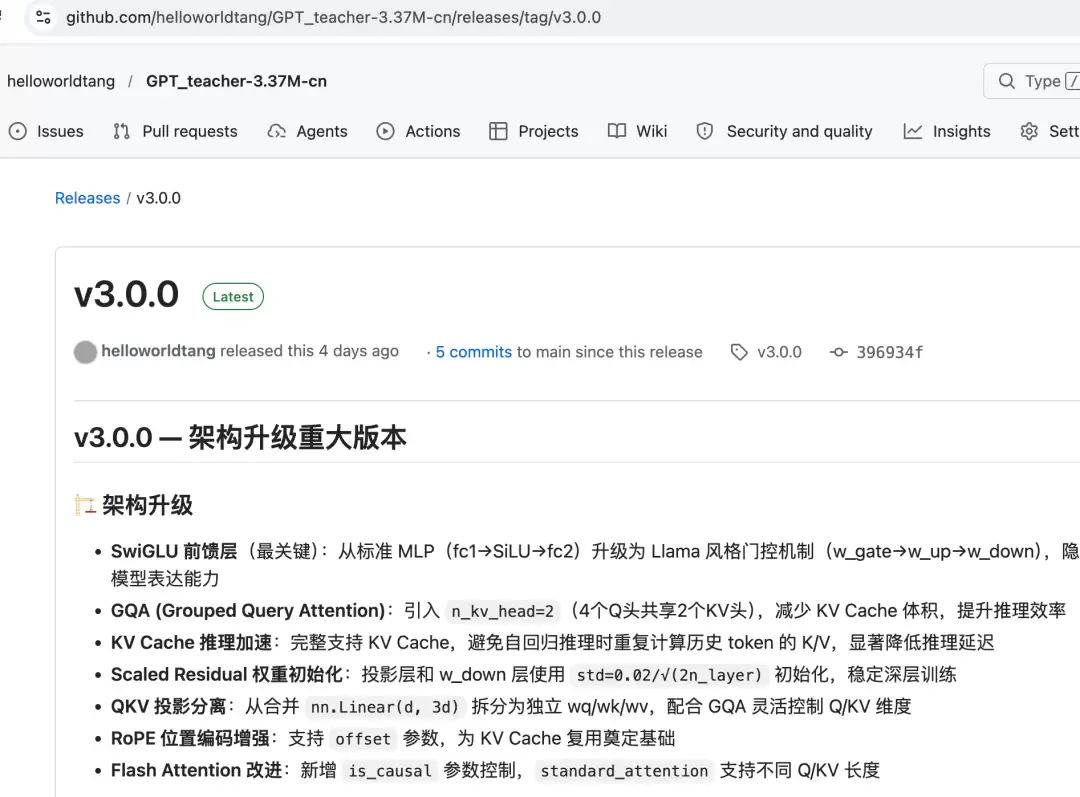
但两个问题还在:
1. 后半句幻觉 — “15乘以6”答案正确,但后面多了一句“减少模型体积并保持输入输出语义一致”——跟算术没有半毛钱关系

2. 零泛化 — 15 个验收外的问题,全部返回同一个错误答案“RoPE 是旋转位置编码...”——模型在复读训练数据
我们设了四个优化方向,逐一实验。
方向一:增大 seq_len
▪ 假设
seq_len=128 太短了,模型没空间学到“答完就停”的模式。增到 256 应该能缓解后半句幻觉。
做机器学习的人都有一种直觉:效果不好,是不是窗口太小了?开大一点嘛。一开始谁都是这么想的。
▪ 实验
同一个 3.37M 模型,同一份 600 条训练数据,只改一个变量:
配置 | seq_len | max_steps | 训练时间 |
|---|---|---|---|
默认 | 128 | 5000 | ~20 分钟 |
实验 | 256 | 8000 | 168 分钟 |
训练时间翻了 8 倍。因为注意力计算复杂度是 O(n²):序列长度翻倍 → 计算量约 4 倍 → 加上更多训练步数 → 总时间暴涨。
▪ 结果
验收测试先报了一个意外:太阳系那道题只输出了“八大行星:”就停了——因为中文冒号“:”被加到了停止词里,而答案“八大行星:水星...”本身就包含冒号。修复停止词后验收 6/6。
但真正的问题在验收外的 15 个新问题。用训练分布外的问法测试(“什么是深度学习?”“CPU和GPU有什么区别?”“地球到月球有多远?”):
- seq_len=128(默认):部分正确,部分答非所问,但没有乱码
- seq_len=256(实验):大部分出现乱码,如“什么是token?”回答“文本的最小处理单元,一个 toen。”(“toen”是“token”的乱码版)
▪ 结论
seq_len=256 的效果比 128 更差。
三个原因:
1. 模型容量是瓶颈 — 3.37M 参数的“脑容量”就那么大,给它更长的上下文窗口,它没有足够的参数去用好
2. 训练数据不够长 — 答案大多是 20-40 个 token,seq_len=256 的大半空间都是 padding,模型花大量容量学“怎么在空白区域不出错”
3. 投入产出比太差 — 8 倍的训练时间,换来更差的效果
这就好比给一个小学生塞了一本大学教材——书变厚了不代表他能学会更多。直觉这个东西,真是害人不浅。
方向二:数据飞轮
▪ 假设
模型对验收外问题全部答非所问,说明训练数据覆盖不够。补充更多 Q&A 对应该能提升泛化能力。
▪ 实验
用 best.pt 跑 15 个验收外问题,15 个全部返回同一个错误答案:“RoPE 是旋转位置编码...”
为这 15 个问题写标准答案,按 7 种前缀变体(“你知道”、“请问”、“帮我解释下”等)扩展到 105 条,追加到原有 600 条训练数据中。
▪ 结果
- 训练数据从 600→705 条,唯一答案从 12→27 个
- 验收测试 4/6,原有正确答案被“冲淡”
- 部分回答出现乱码
▪ 结论
3.37M 模型的知识容量上限约 12 个主题。新数据不仅没有带来新能力,反而挤掉了旧知识的记忆。
小模型的“脑容量”是有限的。27 个主题分 705 条数据,每个主题平均曝光次数减少了。新知识把旧知识挤掉了。
加数据不是越多越好,是要在模型容量内精打细算。这跟人类学习一个道理——你让一个人同时学 27 门课,每门课都学不好。
方向三:课程学习
▪ 假设
训练时先喂简单样本(短答案),再逐步加入复杂样本(长答案),应该能改善收敛。模仿人类“由易到难”的学习过程。
▪ 实验
对训练数据按答案长度排序,前 30% 训练步只用短答案子集,之后切回全量数据。
▪ 结果
- 验收测试 4/6
- Q2(RoPE 是什么)和 Q3(15×6)全部退化成“我是一个基于 Transformer 的小型 GPT 教学演示模型”——这是训练数据中最短的答案
▪ 结论
课程学习对 3.37M 这种超小模型不适用。
模型容量太小,早期学到的最短答案被“钉死”在权重里,后续用全量数据训练也无法纠正。大模型能用课程学习是因为它有足够的容量“忘掉”早期的过拟合,重新分配权重。小模型做不到。学了就是学了,改不了了。
方向四:多轮对话(成功)
▪ 假设
前三轮实验证明:任何改训练的方案都有回归风险。那就不改训练,只改推理和 UI。
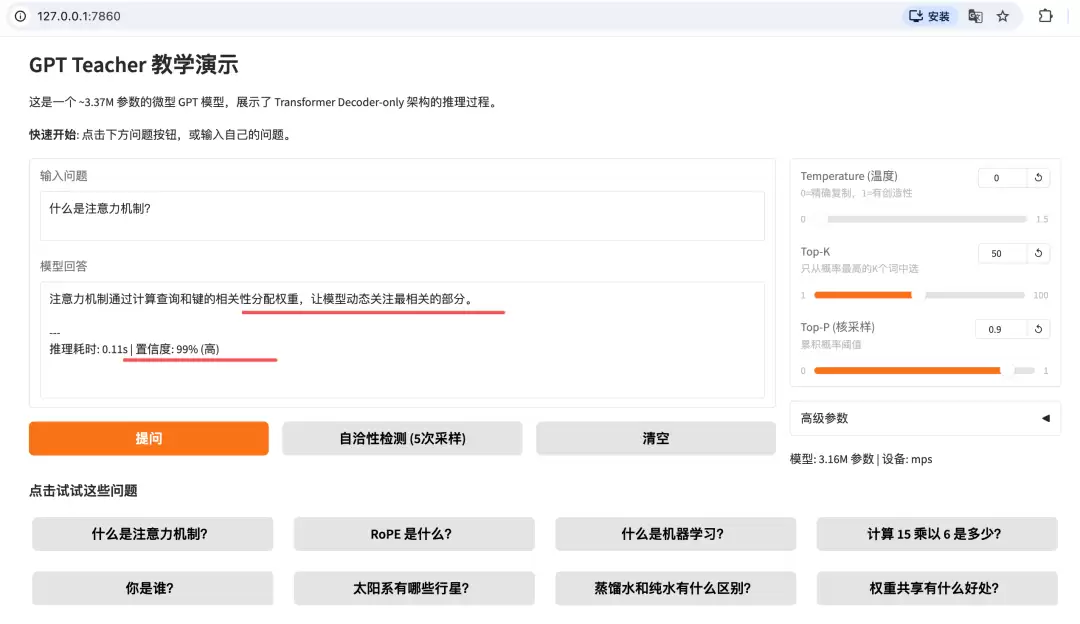
▪ 实验
- Web Demo 从单轮问答改为 ChatInterface
- 推理时将对话历史拼成
“用户:Q1助手:A1用户:Q2助手:”格式 generate函数完全不改,只改调用方式- 保留单轮模式(含置信度和自洽性检测)在折叠面板中
▪ 结果
- 验收测试 6/6 不受影响
- 多轮 prompt 拼接正确
- 零训练成本,纯推理层优化
▪ 结论
对超小模型,推理层面的优化比训练层面的优化更安全、更有效。不改训练就不会引入回归风险。
总结:四个实验指向同一个结论
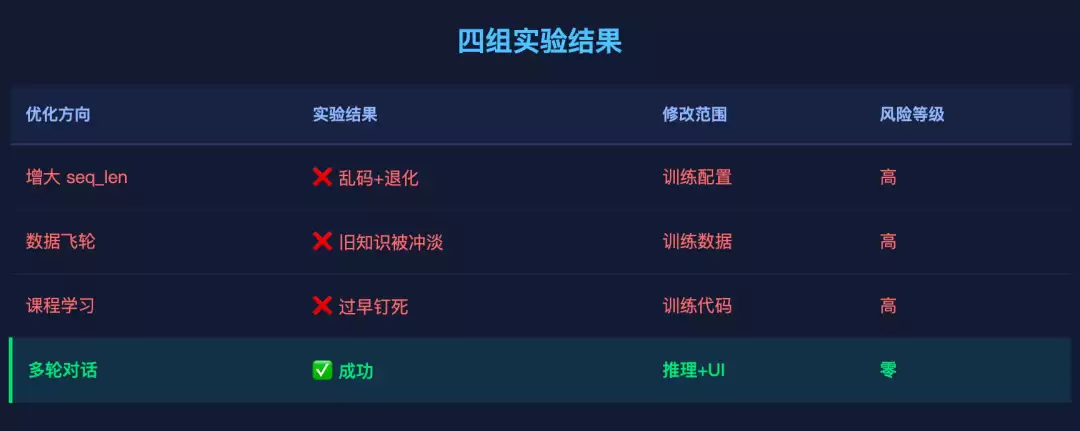
核心认知:
3.37M 参数的模型,瓶颈在模型容量本身,不在配置调优或数据量。任何增加“要学的东西”的改动(更长序列、更多主题、更复杂的训练策略)都会超出模型容量,导致整体退化。
唯一安全的优化路径:不改训练,只改推理和 UI。
▪ 三个反直觉的结论
- seq_len 不是瓶颈 — 128→256 训练时间翻 8 倍,效果反而变差
- 加数据不是越多越好 — 超过模型容量上限,新知识会挤掉旧知识
- “由易到难”不适用 — 小模型早期过拟合无法纠正,和大模型的行为完全不同
这不一定是你想听到的结论。但这是实验告诉我们的真相。
对小模型,知道天花板在哪里,比盲目调参更有价值。
⚠️ 踩坑提醒:
小模型调参的三个坑——
1. seq_len 开大不等于效果好,可能训 8 倍时间换来更差的输出
2. 加数据超过模型容量,新知识会挤掉旧知识
3. 课程学习在小模型上会过早锁死最短答案,大模型的经验不能照搬
你是不是也干过这种事?训练完发现效果不好,第一反应是“是不是数据不够”,第二反应是“是不是窗口太小”,第三反应是“是不是训练策略有问题”——三个方向全试了一遍,最后发现模型本身就那么大,怎么调都白搭。
下次碰到小模型效果不好,先问自己一个问题:我是不是在试图超越模型的天花板?
突然在想,是不是还有别的什么好办法。希望路过的大佬能给指点指点。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI编码工具Copilot与Cursor让开发效率翻倍
从Copilot到Cursor,AI编码工具将开发效率提升数倍,如CRUD接口开发从2小时缩短至30分钟。但其本质是统计模式匹配,生成代码需严格审查,避免安全漏洞与过度依赖。开发者仍需对代码质量负最终责任。

零代码基础用AI做小游戏:Claude Code写逻辑WorkBuddy美画面惊喜之旅
零代码基础者借助ClaudeCode搭建游戏逻辑,再使用腾讯WorkBuddy优化画面,成功制作出“切小猪”微信小游戏。ClaudeCode精准实现物理效果与机制,WorkBuddy一次性完成表情动态、切果汁飞溅、连击特效等八大视觉优化,使游戏从单调变为丰富流畅,证明不会代码也能借助AI完成游戏开发。

智能小说生成器重塑创作模式与表达人类情感的未来
下午的咖啡馆里,阳光透过落地窗洒进来,邻桌一位年轻作家正和同伴兴致勃勃地聊着AI写作工具。这样的场景,如今已经越来越常见了。从最初的新奇尝试,到如今实实在在地进入创作流程,AI小说创作应用正在悄然改变着写作这件事的面貌,成为众多写作者提升效率的得力助手。 无论你是刚踏入写作领域的新人,还是已积累多年

WizyChat智能对话AI企业高效沟通解决方案
如果你正在寻找一款能够快速上线、无需编写代码的AI客服工具,那么WizyChat值得列入你的候选名单。简单来说,它是一款可定制的GPT聊天机器人——只需将你的网站、帮助中心、常见问题页面或在线商店的数据导入,它就能自动学习并生成针对性的精准回复。整个配置过程只需几分钟,支持超过95种语言,定价灵活且

AI引领表格软件革命,你准备好迎接未来了吗
在数字化浪潮全面袭来的今天,人工智能对表格软件的影响早已不是简单的“锦上添花”,而是带来了一场实实在在的变革。回想一年前,许多人还在Excel中手动拖拽、反复核对,面对复杂的数据分析任务常感到无从下手。如今,AI驱动的表格工具让这一切发生了质变——那么,这种体验究竟有多不同? 先看一组数据:超过70








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
