




告别查文档蹲社区 用DeepSeek和Claude Code搭建Doris专属AI专家助手

你是否也曾遇到过这些场景?Doris 突然报出奇怪的错误,翻遍官方文档也找不到答案;SQL 查询执行缓慢,EXPLAIN 输出几百行,不知从何分析;想为表设计合理的分桶策略,却不清楚 Bucket 数量该设为多少;在社区群里提问半天无人回应,问题却十分紧急。
每次遇到这些问题,你是否也曾经想过:要是有个随叫随到的 Doris 专家该多好。
今天这篇文章,就是帮你实现这个愿望。
整体思路
我们要做的事情其实非常简单:
你(中文提问)
↓
DeepSeek(国内模型,成本低、稳定、能力强)
↓
Claude Code(开源智能体框架,负责调度工具、读取源码、执行操作)
↓
Apache Doris(本地源码 + 官方文档 + 实战知识库)
↓
专家级回答一句话概括:用 DeepSeek 作为大脑,用 Claude Code 作为手脚,将 Apache Doris 的完整知识体系注入其中,打造一个能够阅读源码、查询文档、编写 SQL、诊断问题的 AI 助手。
为什么是 DeepSeek + Claude Code 这个组合?
1. DeepSeek:国产性价比之王,完美适配 Doris 场景
- 极低成本:API 调用费用仅为 GPT-4 的 1/5、Claude 官方的 1/4,100 万 tokens 仅需约 15 元,日常咨询几乎零成本;
- 国内稳定可靠:纯国产节点部署,无需访问海外网站,延迟 50-100ms,无封号风险,数据不出境符合合规要求;
- 推理能力出色:擅长逻辑推理、代码调试、复杂 SQL 解析,对 Doris 的内核机制(如 Compaction、内存管理、副本调度)理解精准,远超通用模型;
- 长上下文支持:128K 超长窗口,能够直接加载 Doris 完整日志、建表语句、配置文件,无需分段,一次读取即可理解。
2. Claude 客户端:最佳交互入口,无缝对接 DeepSeek
Claude Code(客户端)不仅能作为对话界面,还能直接操作本地 Doris 集群、执行 SQL、读取日志、修改配置等。相比纯 DeepSeek 而言,方便了不少~
- 工具调度:读写文件、执行命令、搜索代码等
- 上下文管理:自动加载相关的源码和文档等
- 多轮推理:先理解问题 → 读取相关代码 → 定位根因 → 给出方案
- 操作集群:执行 SQL、读取日志、修改配置等
第一步:环境准备
1.1 安装 Claude Code
# macOS / Linux
npm install -g @anthropic-ai/claude-code
# 验证安装
claude --version1.2 获取 DeepSeek API Key
访问 platform.deepseek.com
注册账号,在「API Keys」页面创建一个 Key
充值 10 块钱即可使用好几个月
1.3 配置 Claude Code 使用 DeepSeek
修改 Claude 配置文件,将默认模型替换为 DeepSeek,国内连接稳定不掉线:
推荐:配置 settings.json
编辑 ~/.claude/settings.json,写入以下内容(推荐,永久生效)
{
"env": {
"ANTHROPIC_API_KEY": "sk-你的Key",
"ANTHROPIC_BASE_URL": "https://api.deepseek.com/anthropic",
"CLAUDE_CODE_SUBAGENT_MODEL": "deepseek-v4-flash"
},
"permissions": {
"allow": ["Bash", "Edit", "Read", "LS", "Grep", "Glob"]
}
}备选:环境变量(macOS / Linux / WSL)
如果 settings.json 方式不生效,可在终端设置环境变量(建议写入 ~/.bashrc 或 ~/.zshrc 永久生效)
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_API_KEY="sk-你的Key"
# 可选:指定模型
export ANTHROPIC_MODEL="deepseek-v4-flash"第二步:准备 Doris 知识库
这是最关键的一步——AI 助手能有多「懂」Doris,取决于你喂给它什么。
我们不用任何现成的插件或技能包,直接从 Apache 官方仓库拉取源码和文档,让 Claude Code 就地取材。
2.1 拉取 Doris 源码
mkdir -p ~/DorisDev && cd ~/DorisDev
git clone https://github.com/apache/doris.git有了源码,助手就能:
- 搜索 FE / BE 的内部实现,理解每个模块的职责
- 根据报错信息反向搜索代码,定位问题根本原因
- 读懂执行计划的生成逻辑和算子实现
2.2 拉取 Doris 官方文档
cd ~/DorisDev
git clone https://github.com/apache/doris-website.git这是 Apache Doris 官方网站的完整源码,包含:
- 所有 SQL 语法参考(SELECT、CREATE TABLE、ALTER、IMPORT……)
- 各版本 Release Notes 和升级指南
- 最佳实践、FAQ、配置参数大全
2.3 写一个 CLAUDE.md,告诉 Claude Code 怎么用这些知识
在工作目录(~/DorisDev)下创建 CLAUDE.md:
# Doris 专家助手配置
## 知识库路径
- Doris 源码:~/DorisDev/doris
- Doris 文档:~/DorisDev/doris-website
## 工作原则
当用户提出 Doris 相关问题时,遵循以下流程:
1. **先查文档**:在 doris-website 中搜索相关的 SQL 语法、配置参数、版本说明
2. **再读源码**:如果文档不够,进入 doris 源码搜索相关模块的实现逻辑
3. **给出方案**:结合文档 + 源码的理解,给出可操作的解决方案
4. **提供 SQL**:如果涉及建表、查询、调优,给出可以直接执行的 SQL 语句
## 常见任务的检索策略
- 报错排查 → 先在源码中 grep 错误信息,再反向追踪调用链
- SQL 语法 → 在 doris-website/docs 中搜索对应语句的文档
- 性能调优 → 查文档中的「性能优化」章节 + 源码中的执行引擎实现
- 表设计 → 查文档中的「数据模型」和「分区分桶」章节 + 基于源码的优化
- 版本升级 → 查 Release Notes + 源码中的兼容性逻辑这相当于给 AI 配备了一套「操作手册」。每次提问,Claude Code 会先读取 CLAUDE.md,知道该去哪里查找答案。
2.4 (可选但强烈推荐)准备你的私有知识
在工作目录下创建 CLUSTER_INFO.md:
# 我的 Doris 使用笔记(仅案例)
## 集群信息
- 生产集群:3 FE + 5 BE,版本 4.0.5
- 测试集群:1 FE + 1 BE,版本 4.1.0
## 常见问题记录
- 导入超时通常是因为 tablet 数量过多导致 compaction 积压
- Join 大表时优先考虑 Broadcast Join
## 常用配置
- enable_vectorized_engine = true
- parallel_fragment_exec_instance_num = 8这样助手给出的建议将基于你的实际环境,而非泛泛之谈。
第三步:实战演示
配置完成后,打开终端,进入 Doris 源码目录,直接提问即可。
场景一:报错排查
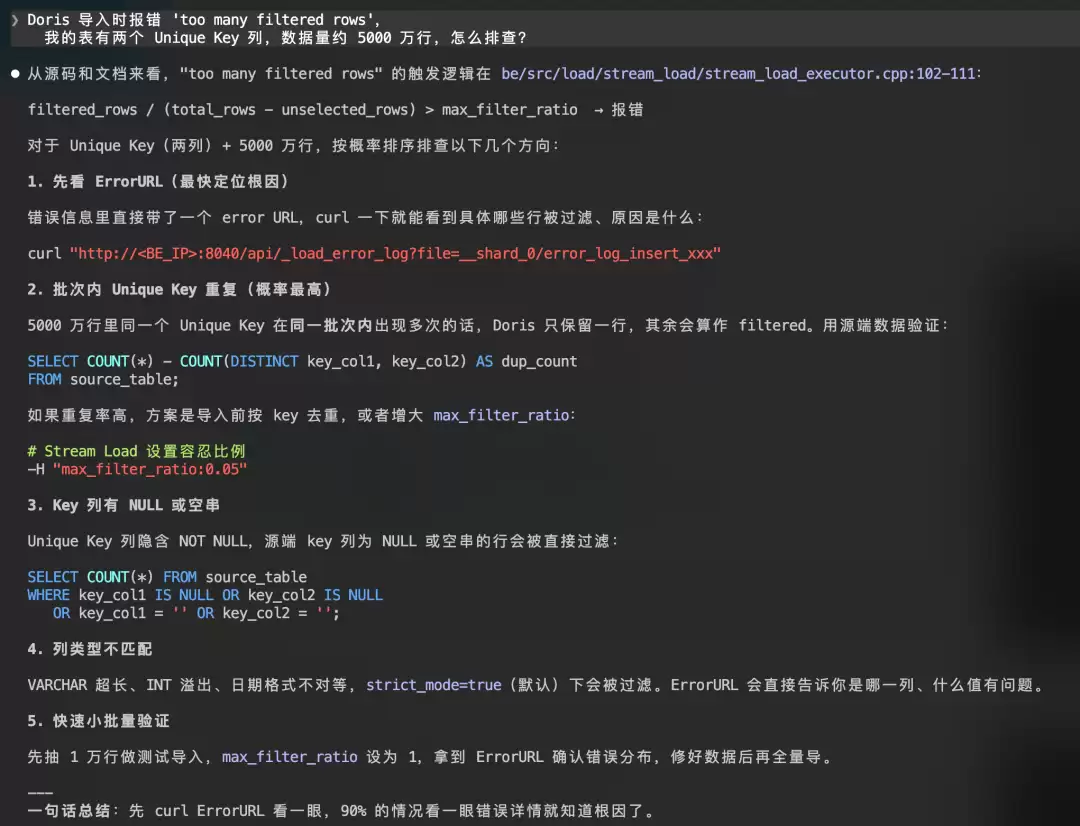
cd ~/DorisDev/doris
claude "Doris 导入时报错 'too many filtered rows',我的表有两个 Unique Key 列,数据量约 5000 万行,怎么排查?"助手会:
- 搜索源码中的
too many filtered rows错误信息 - 定位到 BE 端的数据过滤逻辑
- 解释错误原因:Unique Key 模型在 Merge 阶段发现同一 Key 的多条数据,Filter 了不符合条件的行
- 给出排查方向:检查源数据是否有重复 Key、调整
max_filter_ratio - 提供 SQL 帮你验证数据质量
场景二:SQL 优化
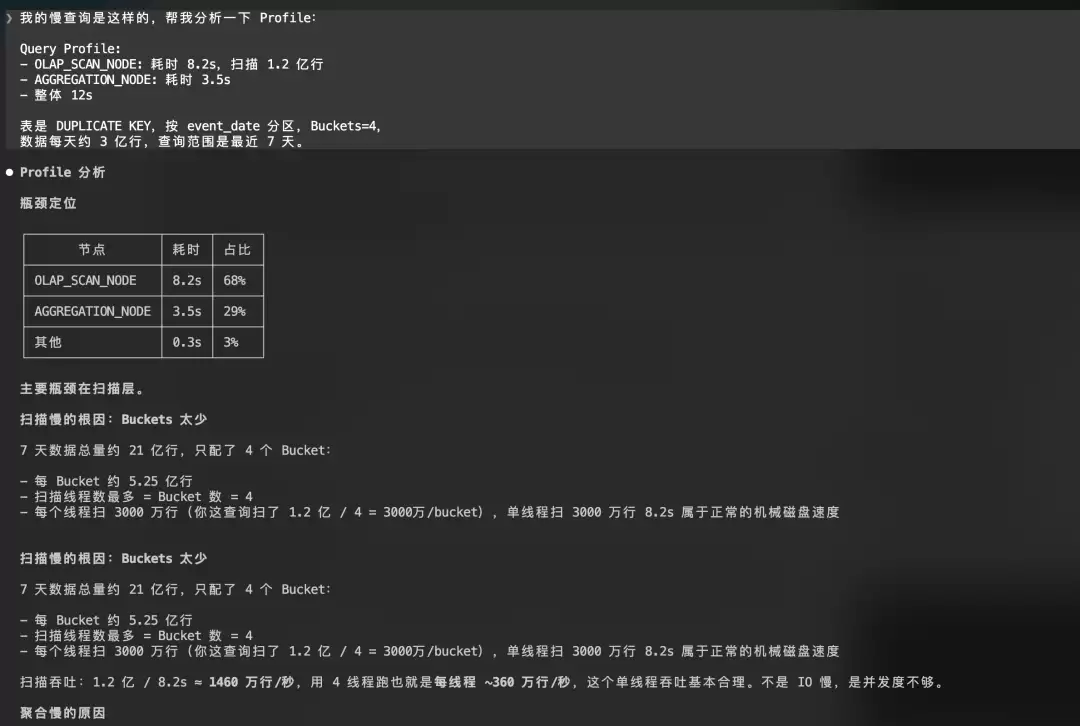
claude "我的慢查询是这样的,帮我分析一下 Profile:
Query Profile:
- OLAP_SCAN_NODE: 耗时 8.2s,扫描 1.2 亿行
- AGGREGATION_NODE: 耗时 3.5s
- 整体 12s
表是 DUPLICATE KEY,按 event_date 分区,Buckets=4,数据每天约 3 亿行,查询范围是最近 7 天。"助手会:
- 分析扫描量:1.2 亿行分布在 4 个 Bucket 上,每个约 3000 万行
- 指出问题:7 天 x 3 亿 = 21 亿行,4 个 Bucket 过少,扫描并行度不足
- 建议:Bucket 数量增加到 32-64
- 检查分区裁剪是否生效
- 给出优化后的建表语句
第四步:进阶玩法
4.1 接入企业内部文档
如果你的团队有 Confluence、语雀或飞书文档记录 Doris 使用经验,可以通过 MCP Server 接入:
// .claude/mcp.json
{
"mcpServers": {
"yuque": {
"command": "npx",
"args": ["-y", "@anthropic/mcp-server-yuque"],
"env": {
"YUQUE_TOKEN": "your-token"
}
}
}
}这样助手能够同时检索源码、官方文档和你们的内部知识库。
4.2 连接到你的 Doris 集群
通过 MCP 直接让助手执行只读查询,验证它的诊断结论:
{
"mcpServers": {
"doris-readonly": {
"command": "npx",
"args": ["-y", "mcp-server-mysql"],
"env": {
"MYSQL_HOST": "your-doris-fe",
"MYSQL_PORT": "9030",
"MYSQL_USER": "readonly_user",
"MYSQL_PASSWORD": "xxx"
}
}
}
}4.3 日常巡检自动化
在 Claude Code 中设置定时任务:
# 每天上午 9 点检查集群健康状态
claude "检查 Doris 集群昨天的运行情况:
1. 查看 FE 审计日志有无异常
2. 检查 BE 节点磁盘使用率
3. 检查 Compaction 积压情况
4. 汇总生成昨天的运行日报"常见问题
Q:DeepSeek 的能力跟 Claude 原生模型比差多少?
A:在 Doris 这个领域,差距几乎可以忽略。因为核心竞争力在于「能够读取源码和文档」,而非模型的通用能力。DeepSeek V4 的代码理解和中文表达能力完全胜任。
Q:我的数据安全吗?
A:代码和文档在本地,提问内容经过 DeepSeek API。如果你的数据安全要求极高,可以使用本地部署的 DeepSeek 模型,完全离线运行。
Q:没有任何编程基础能用吗?
A:安装和配置部分需要基本的命令行操作,跟着本文一步步做即可。使用阶段只需要用中文描述问题,不需要编写代码。
Q:能替代真正的专家吗?
A:它能解决 80% 的常见问题,但遇到非常深层的 Bug(比如向量化引擎的边界情况),还是需要社区专家介入。它更像是你的「第一道防线」,帮你快速过滤掉大部分问题。
动手试试吧。有问题欢迎在评论区交流。
```
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI PPT自动生成解决方案提升效率与设计质量
一、如何利用做ppt自动生成ai提升工作效率 在当代快节奏的职场环境中,如何高效地打造一份既专业又美观的演示文稿,成为众多从业者共同面对的难题。传统手工制作方式耗时费力,尤其在处理庞大数据与复杂信息时,常令人感到力不从心。幸运的是,AI技术的介入正深刻改变这一局面。借助AI自动生成PPT,已成为提升

掌握高效处理AI文件的多种实用方法与步骤
高效使用 ai格式文件的实用技巧 在数字设计行业中, ai格式文件作为Adobe Illustrator的原生格式,能完美保留矢量图形与设计元素。无论你是需要创建新图形,还是编辑已有文件,掌握如何高效处理 ai文件都能大幅提升工作效率。以下方法将帮助你轻松应对 ai格式文件的各类需求。 方法一:使用

Excel筛选大于2000数据的技巧与效率提升方法
```html 快速筛选大于2000的数据 在Excel中处理数据时,我们常常需要从大量数值里快速锁定那些大于2000的条目。这个操作听起来基础,但选对方法后工作效率能直接翻倍。下面介绍几种实操性很强的Excel数据筛选技巧,学完就能直接用。 方法一:使用自动筛选功能 首先选中你的数据区域,然后点击

批量提取多个Excel表格同一单元格数据提升工作效率
提取多个Excel表格的同一单元格数据 许多人在处理大量Excel表格时,常常被“从每个工作表中提取固定位置的数据”这一难题困扰。例如,每月需要汇总几十份销售报表中的B3单元格,或是从不同部门的预算表中抓取C5单元格的值。实际上,解决方法并不少,今天我们就来介绍几种常用技巧,帮助你摆脱重复劳动的烦恼

掌握表格数据套用,提升工作效率必备
```html Excel表格数据套用全攻略:如何将一个表格的数据快速应用到另一个表格 在日常数据处理工作中,经常需要把一个表格的数据“搬”到另一个表格里——可能是为了合并信息,也可能是为了快速更新报表。虽然听起来简单,但不同场景下的Excel表格数据套用方法其实差别挺大。下面梳理几种常用方式,从零








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
